Fuzzy SyStem2020 | 论文阅读《Optimize TSK Fuzzy Systems for Regression Problems》
Posted Curious*
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Fuzzy SyStem2020 | 论文阅读《Optimize TSK Fuzzy Systems for Regression Problems》相关的知识,希望对你有一定的参考价值。
TSK模糊系统优化算法----MGDB
paper: https://ieeexplore.ieee.org/document/8930057/references#references
code: https://github.com/drwuHUST/MBGD_RDA
1、Motivation
本文针对回归问题,将TSK模糊系统与神经网络常用优化方法进行结合,引入了Drpout、正则化以及AdaBound方法,并将其修正为适合回归问题优化的新方法,同时也解决了TSK模糊系统不能应用于不同大小数据集、泛化能力差的缺点。
1、将三种强大的神经网络优化技术,即MBGD、正则化和AdaBound,扩展到TSK模糊系统。
2、提出了三种新的技术( (DropRule, DropMF,
and DropMembership),专门用于训练TSK模糊系统。
3、最终的算法,正则化MBGD,DropRule和AdaBound(MBGD-RDA),在10个不同大小的应用领域的真实数据集上显示了优越的性能。
2、Overviw of the TSK Fuzzy System Optimize
2.1 Selct Optimize direction
TSK模糊系统广泛应用于各行各业,同时也取得了很多的成就,本文主要集中于TSK模糊系统在回归问题上的应用。同时在TSK模糊系统优化方面,许多学者也做出了努力,但优化方法依旧集中于以下三个方面:1、进化算法,通过遗传迭代的方式筛选出最优的后代,从而保证全局最优。2、梯度下降,通过反向传播机制修正权重,目前已在神经模糊系统中有所应用。3、梯度下降和最小二乘估计,在基于模糊推理的自适应网络(ANFIS)中提出,先验参数由梯度下降优化,后验参数由最小二乘法估计,相比梯度下降更好更快。但以上方法均存在不能应用于大数据的问题,大数据不仅数据维度大、数据量也大,类型多样,速度快。本文中,则将大数据进行降维,采用主成分分析降维数据,主要处理数据体积大的问题。
由于进化算法需要对每个个体进行计算和迭代,所需内存以及计算代价较大,梯度下降和最小二乘法又容易出现过拟合问题,因此,在优化方法上,我们选择了梯度下降。
2.2 梯度下降优化措施
梯度下降主要可以分为batch gradient descent、 stochastic gradient descent、mini-batch gradient descent。其中batch gradient descent对于大数据可能存在内存不足,甚至不能执行的问题,stochastic gradient descent稳定性较差,而mini-batch gradient descent解决了以上两个问题,并在深度学习领域得到了验证。经过Mamdani neuro-fuzzy systems上的对比,将其应用于模糊系统是较好的。
在梯度下降过程中,学习率是很重要的,目前尚未有人使用性能较好的AdaBound对TSK模糊系统进行学习。
正则化操作常用于解决提升模型泛化性和减少过拟合问题。而近些年提出的新方法DropOut、 DropConnect也能提升模型的泛化性以及降低模型的过拟合,并在深度学习领域也进行了验证,在TSK模糊系统上应用较少。
3、MGDB-RDA算法介绍
3.1 Framework
算法如下:


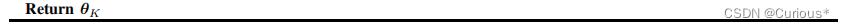

其中,算法的返回值是值误差最小,但不一定是最优的值。可以通过迭代数结果比较得到最佳的返回值。
3.2 Algorithm introduction
1、对于TSK模糊系统,我们在前面的文章中已经提过,并详细解释,具体可看TSK模糊系统。在隶属度函数上本文只考虑 Gaussian MF。
2、我们采用L2正则化来定义损失函数,增加惩罚项。这里xn和yn分别表示输入输出的标签,y(xn)表示预测结果,其他参数如下
3、Mini-Batch Gradient Descent (MBGD)
对于(7)中的损失函数,其梯度计算公式如下:

后面较为复杂,看原文

4、DropRule是指在训练过程中随机丢弃一些规则,但在测试中使用所有规则。激励水平则设置为(0,1)。TSK模糊系统的输出则会再次被激励水平的加权平均值计算。而激励水平指的是各个模糊规则结果对于最终结果的贡献,具体如图:

具体原理为通过随机删除一些规则,我们强制每个规则使用随机选择的规则子集,因此每个规则都应该最大化自己的建模能力,而不是过于依赖其他规则。这可能有助于提高最终的TSK模糊系统的泛化性。
4、AdaBound由于其限制自适应学习率的上下界,因此,学习率的极端情况并不会出现,同时随着迭代次数的增加,AdaBound会使得学习率不断收敛为一个常数。本文所使用的下界和上界为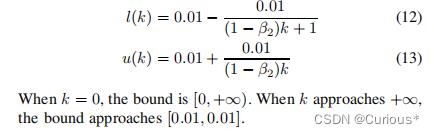
4、Experients
4.1 dataset
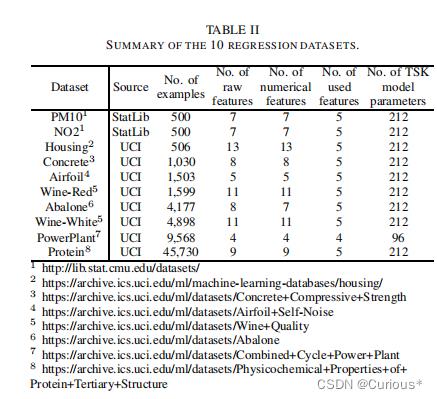
我们将最大输入维数限制为5个:如果一个数据集有超过5个特征,那么就使用主成分分析将它们减少为5个特征。 算法对比:岭回归算法,岭回归系数为0.05
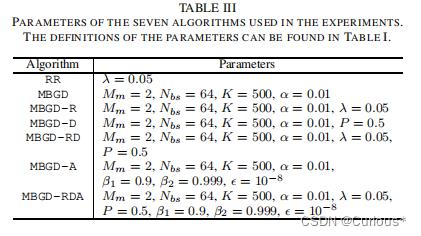
算法对比:岭回归算法,岭回归系数为0.05
MBDG,小批量梯度下降算法: batchsize = 64,学习率0.01
MBDG和正则化,入=0.05
MBDG和DropRule P=0.5,一半的模糊规则随机为0
MBDG和DropRule和正则化,其他参数如上
MBDG和AdaBound ,其中α=0.01,β1=0.9,β2=0.999,∈=10^-8
MBGD 和DropRule和正则化和AdaBound
训练样本和测试样本73分。
计算代价:
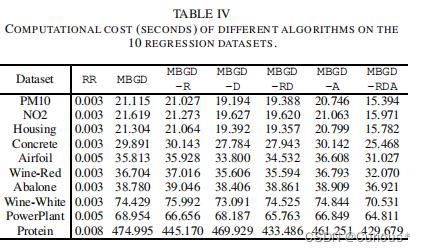
剩余包括参数灵敏性实验、ANFIS对比、Adam对比等等,均用图片展示,移步原文。
以上是关于Fuzzy SyStem2020 | 论文阅读《Optimize TSK Fuzzy Systems for Regression Problems》的主要内容,如果未能解决你的问题,请参考以下文章