TVM 学习指南(个人版)
Posted just_sort
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TVM 学习指南(个人版)相关的知识,希望对你有一定的参考价值。
0x0. 前言
最近粗略的看完了天奇大佬的MLC课程(顺便修了一些语法和拼写错误,也算是做了微弱的贡献hh),对TVM的近期发展有了一些新的认识。之前天奇大佬在《新一代深度学习编译技术变革和展望》一文中(链接:https://zhuanlan.zhihu.com/p/446935289)讲解了TVM Unify也即统一多层抽象的概念。这里的统一多层抽象具体包括AutoTensorization用来解决硬件指令声明和张量程序对接,TVM FFI(PackedFunc)机制使得我们可以灵活地引入任意的算子库和运行库函数并且在各个编译模块和自定义模块里面相互调用。TensorIR负责张量级别程序和硬件张量指令的整合。Relax (Relax Next) 引入relay的进一步迭代,直接引入first class symbolic shape的支持 (摘抄自《新一代深度学习编译技术变革和展望》一文)。然后这些抽象可以相互交互和联合优化来构造深度学习模型对应的最终部署形式。我个人感觉TVM Unify类似于MLIR的Dialect,但是这几个抽象的直接交互能力相比于MLIR的逐级lower我感觉是更直观方便的,毕竟是Python First(这个只是我最近看MLC课程的一个感觉)。对这部分内容感兴趣的读者请查看天奇大佬的TVM Unify介绍原文以及MLC课程。
这篇文章我将结合TVM Unify相关的抽象以及之前的一些积累重新梳理一下TVM的整体流程。我会从前端,中端(图优化Pass机制),代码生成(Schedule),Runtime,开发工具几个角度来介绍一遍。我对TVM的代码并没有做到精细的阅读,所以本文将尽量避免涉及到底层C++代码的细枝末节,而是从较为宏观的视角来讲清楚目前TVM的架构。本篇文章的所有参考资料以及idea主要来自我维护的这个仓库(https://github.com/BBuf/tvm_mlir_learn)里面搜集的TVM的相关资料,TVM官方doc以及源码,MLC课程。上面这个仓库基本收集了TVM中文社区里面的大部分高质量博客或者专题,对TVM感兴趣的小伙伴可以自行下载或者收藏,更欢迎点个star。
写作不易,这篇文章对你有用的话也请点个赞👍。文章有错误也请指出,我动态修改。之后的计划应该会学习TVM如何和硬件的指令对接。
0x1. 前端
TVM为了向上兼容所有的机器学习框架如PyTorch,TensorFlow,ONNX等引入了Relay IR,机器学习模型在进入TVM之后首先会被转换为Relay IR。同时TVM为了向下兼容所有的硬件,引入了Tensor IR简称TIR,模型在被编译为指定硬件的源代码之前都会被Lower为TIR。另外,TVM社区正在开发新一代中间表示Relax(也被称为下一代Relay,目前还没有upstream主分支:https://github.com/tlc-pack/relax/tree/relax/python/tvm/relax),Relax是实现前言里面提到的TVM Unify关键的一环。TVM前端的架构可以粗略的表示为:
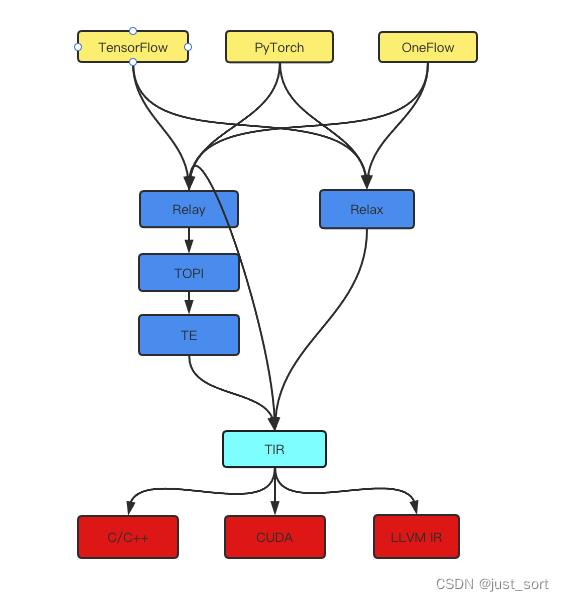
接下来我们分别介绍一下 Relay,TIR,Relax这几种不同的前端表示。
0x1.1 Tensor IR(TIR)
由于无论是Relay还是新一代的Relax中间表示,它们最后都会被Lower到TIR(离硬件最近的IR),所以我们这里先介绍一下TIR。TIR的代码被封装在tvm.tir中,一个TIR可以被编译成目标硬件的源代码或者中间表示例如C++源码,CUDA源码,LLVM IR等等。那么TIR是如何被编译为目标硬件的代码呢?这是因为TIR的数据结构其实是一个AST(抽象语法树),然后这个语法树可以表示变量的声明,初始化,变量的计算,函数调用以及控制流(如if-else条件判断,循环等等)等等。所以只要我们遍历一下TIR对应的AST就可以实现一对一的将其翻译到目标硬件了。可以借助这个图来理解:
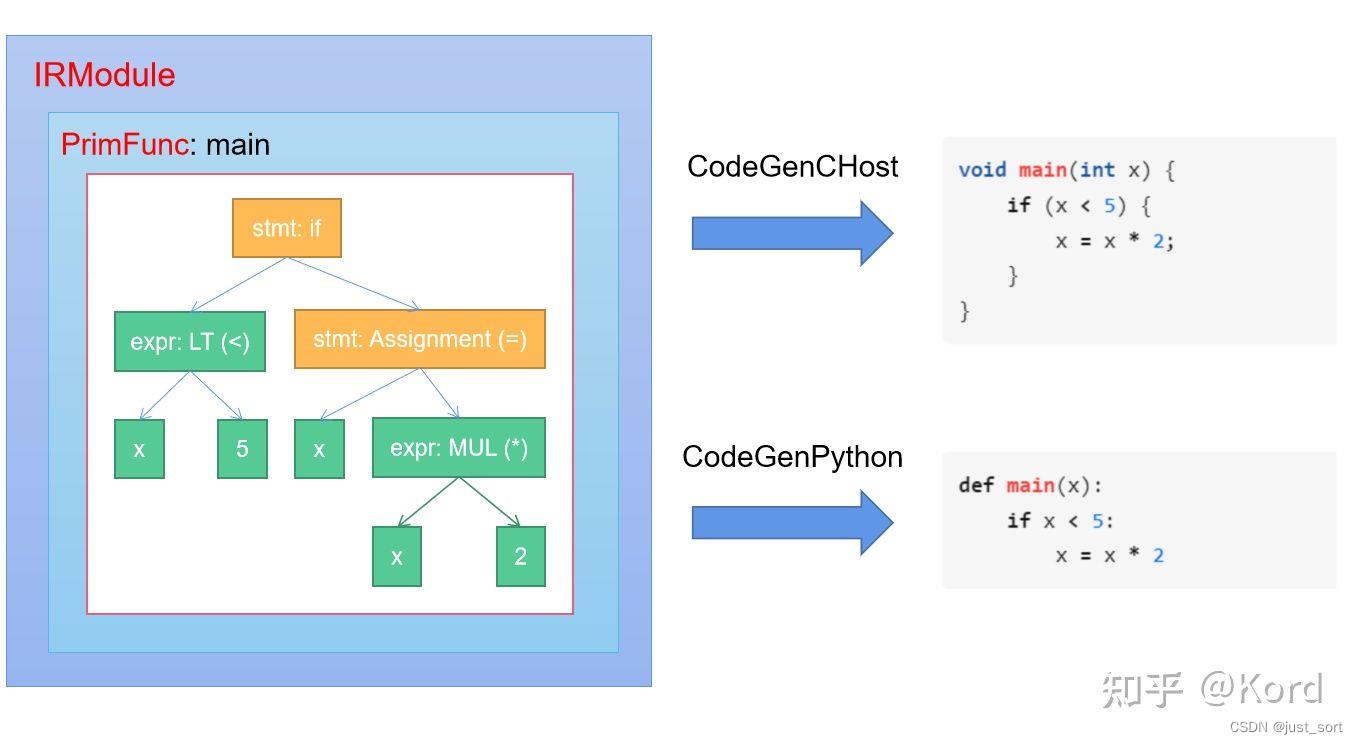
在上图中有几个细节需要解释。首先是IRModule,IRModule 是在机器学习编译中保存元张量函数(也即PrimFunc)集合的容器对象,它是TVM进行编译的最小完整单元。TVM不同的前端表示最终都会被封装到IRModule中进行编译,在Linux下IRModule就是一个.so动态链接库。然后PrimFunc叫作元张量函数,它内部封装了一个完整的TIR AST。当IRModule被编译之后,每个PrimFunc都对应了这个动态库的一个函数入口,因此一个IRModule可以有很多个PrimFunc。然后上面的Codegen实际上就是对TIR AST进行中序遍历然后一对一的将AST Node翻译为相应的TIR Node对应的数据结构并发送给回调函数VisitExpr_ 和 VisitStmt。VisitExpr_ 用于处理 Expression Node,而 VisitStmt 用于处理 Statement Node。后续在介绍Codegen的时候我们再仔细探索一下这个转换流程。
这里还需要说明的一点是,在0.8之前的TVM要声明一个TIR AST依赖于对Tensor Expression的编译。现在TVM基于Python AST实现了一种新的特定领域的方言让我们可以直接使用Python来编写TIR AST。我们这里举一个例子:
@tvm.script.ir_module
class MyModule:
@T.prim_func
def mm_relu(A: T.Buffer[(128, 128), "float32"],
B: T.Buffer[(128, 128), "float32"],
C: T.Buffer[(128, 128), "float32"]):
T.func_attr("global_symbol": "mm_relu", "tir.noalias": True)
Y = T.alloc_buffer((128, 128), dtype="float32")
for i, j, k in T.grid(128, 128, 128):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
vk = T.axis.reduce(128, k)
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
它实现的功能对应的numpy代码为:
def lnumpy_mm_relu(A: np.ndarray, B: np.ndarray, C: np.ndarray):
Y = np.empty((128, 128), dtype="float32")
for i in range(128):
for j in range(128):
for k in range(128):
if k == 0:
Y[i, j] = 0
Y[i, j] = Y[i, j] + A[i, k] * B[k, j]
for i in range(128):
for j in range(128):
C[i, j] = max(Y[i, j], 0)
其中,@tvm.script.ir_module表示被修饰的MyModule是一个待编译的IRModule,而@T.prim_func表示被修饰的main函数是元张量函数(PrimFunc),这个函数内部定义的就是TIR AST。
0x1.2 了解tvm.ir基础设施
继续讲Relay IR以及Relax之前我们先了解一下tvm.ir这个抽象,无论是TIR还是Relay/Relax IR它们都对应了IRModule这个统一的最小编译单元,同时它们也对应的有一套共用的IR基础设置,具体实现在https://github.com/apache/tvm/tree/main/include/tvm/ir和https://github.com/apache/tvm/tree/main/src/ir目录下。
对于IR来说,Type和Expr是尤为关键的两个概念。Type包含基础的数据类型如Int,Float,Double等等,也包含一些自定义的复杂类型比如函数类型,Tensor类型等。而对于Expr来说,既包含可以直接映射到Low-level IR的PrimExpr,又包含RelayExpr。
我们可以在https://github.com/apache/tvm/blob/main/include/tvm/ir/type.h中看到对PrimTypeNode的定义:
/*!
* \\brief Primitive data types used in the low-level IR.
*
* PrimType represents POD-values and handles that are
* not automatically managed by the runtime.
*
* \\sa PrimType
*/
class PrimTypeNode : public TypeNode
public:
/*!
* \\brief The corresponding dtype field.
*/
runtime::DataType dtype;
...
;
可以看到PrimType可以直接对应到Low-level IR的基础数据类型。我们还可以找到FuncTypeNode的定义:
/*!
* \\brief Function type.
*
* We support polymorphic function type.
* This can be roughly viewed as template function in C++.
*
* \\sa FuncType, TypeVar, TypeConstraint
*/
class FuncTypeNode : public TypeNode
public:
/*! \\brief type type of arguments */
Array<Type> arg_types;
/*! \\brief The type of return value. */
Type ret_type;
// The following fields are used in polymorphic(template) functions
// For normal functions, the following two fields will be empty.
/*! \\brief The type parameters of the function */
Array<TypeVar> type_params;
/*!
* \\brief potential constraint the type need to obey
* \\note this field is reserved for futher purposes.
*/
Array<TypeConstraint> type_constraints;
...
;
从注释可以看到FuncType类似C++的模板函数,记录了函数的参数类型和返回值类型以及模板参数,约束等信息。然后我们还可以关注一下和深度学习模型结合得很紧密的TensorTypeNode类型。
/*!
* \\brief This is the most commonly used type in relay.
* TensorType have a fixed dimension, data type.
*
* The elements of shape can be either IntImm(constant integer),
* or any symbolic integer expression.
* The symbolic integer allows generic shape inference in certain cases.
* \\sa TensorType
*/
class TensorTypeNode : public BaseTensorTypeNode
public:
/*!
* \\brief The shape of the tensor,
* represented by PrimExpr(tvm::Expr).
*/
Array<PrimExpr> shape;
/*! \\brief The content data type */
DataType dtype;
...
我们从TensorTypeNode的定义可以看到shape也是TensorType的一部分,所以TVM在做类型推断的时候也包含了Shape的推断。也正是因为在IR中Shape是Type的一部分(比如Tensor[(m, n)]和Tensor[(m, 4)]是不同的Type)导致TVM对动态Shape的支持非常困难,因为Expr的类型推断是不支持动态Shape的。这里需要提一下,Relax通过引入一个新的Type叫作DynTensor较好的解决了动态Shape的表示问题,DynTensor包含的信息是Dtype和Shape的纬度,但Shape本身的表达式是独立存储的。也就是Tensor[(m, n)]和Tensor[(_, _)]都是同一个Type, 但是Tensor[(_, _)]和Tensor[(_, _, _)]是不同的Type,这样就从原生上支持了动态Shape。我们从https://github.com/tlc-pack/relax/blob/95035621177fa0be4adfb55c766f030563e515a5/include/tvm/relax/type.h#L78这里可以看到DynTensor的定义:
class DynTensorTypeNode : public BaseTensorTypeNode
public:
/*!
* \\brief The number of dimensions of the tensor, use -1 to denote tensor with unknwon number of
* dimensions.
*/
int ndim; //现在直接定义ndim而不是shape
/*! \\brief The content data type, use void to denote the dtype is unknown. */
DataType dtype;
...
;
我们紧接着看一下Expr的定义(https://github.com/apache/tvm/blob/main/include/tvm/ir/expr.h),Expr分成PrimExpr以及RelayExpr。其中PrimExpr保存了一个runtime时候的Dtype,然后
/*!
* \\brief Base node of all primitive expressions.
*
* A primitive expression deals with low-level
* POD data types and handles without
* doing life-cycle management for objects.
*
* PrimExpr is used in the low-level code
* optimizations and integer analysis.
*
* \\sa PrimExpr
*/
class PrimExprNode : public BaseExprNode
public:
// runtime::DataType(dtype) 在编译时和运行时提供粗粒度类型信息。
// 它动态地内置在 PrimExpr 表达式构造中,可用于快速类型检查。
// 当 PrimExpr 对应于 i32 等 POD 值类型时,dtype 足以决定 PrimExpr 的 Type。
// 当 dtype 为 DataType::Handle() 时,表达式可以对应更细粒度的 Type,我们可以通过lazy类型推断得到类型。
DataType dtype;
例如表示一个整数的Expr就可以通过继承PrimExprNode来实现,IntImm表示的是整数字面值表达式,所以它记录了一个int类型的value成员。
// PrimExprs that are useful as runtime containers.
//
/*!
* \\brief Constant integer literals in the program.
* \\sa IntImm
*/
class IntImmNode : public PrimExprNode
public:
/*! \\brief the Internal value. */
int64_t value;
...
;
RelayExpr的定义如下:
/*!
* \\brief 所有非Prim Expr的基础节点
*
* RelayExpr 支持张量类型、函数和 ADT 作为
* 一等公民。 对象对应的生命周期
* 由语言隐式管理。
*
* \\sa RelayExpr
*/
class RelayExprNode : public BaseExprNode
public:
/*!
* \\brief 存储类型推断(类型检查)的结果。
*
* \\note 这可以在类型推断之前未定义。 该值在序列化期间被丢弃。
*/
mutable Type checked_type_ = Type(nullptr);
/*!
* \\return The checked_type
*/
inline const Type& checked_type() const;
/*!
* \\brief 检查 Expr 的推断(检查)类型是否由 TTypeNode 支持并返回。
*
* \\note 如果这个 Expr 的节点类型不是 TTypeNode,这个函数会抛出一个错误。
*
* \\return 对应的 TTypeNode 指针。
* \\tparam 我们寻找的特定 TypeNode。
*/
template <typename TTypeNode>
inline const TTypeNode* type_as() const;
...
;
总的来说,无论是高级别的Relay,Relax还是低级别的TIR,它们最终都是由这里的Expr和Type为基础来表达的。因为对于Relay和TIR来讲,它们的op定义都是继承自RelayExprNode:https://github.com/apache/tvm/blob/main/include/tvm/ir/op.h#L58。除了对Op名字,类型以及参数,属性等定义外还有一个特殊的参数support_level,从注释上看应该是用来解释当前Op的等级,值越小表示这种Op类型等级越高(暂不清楚具体的作用)。
// TODO(tvm-team): migrate low-level intrinsics to use Op
/*!
* \\brief Primitive Op(builtin intrinsics)
*
* This data structure stores the meta-data
* about primitive operators that can be invoked via Call.
*
* Low-level IR intrinsics(such as libc.expf) are also
* implemented via Op.
*
* \\sa Op
*/
class OpNode : public RelayExprNode
public:
/*! \\brief name of the operator */
String name;
/*! \\brief the type of the operator */
mutable FuncType op_type;
/*!
* \\brief detailed description of the operator
* This can be used to generate docstring automatically for the operator.
*/
String description;
/* \\brief Information of input arguments to the operator */
Array<AttrFieldInfo> arguments;
/*!
* \\brief The type key of the attribute field
* This can be empty, in which case it defaults to anything.
*/
String attrs_type_key;
/*!
* \\brief attribute type index,
* this field varies in each run and is not exposed to frontend.
*/
uint32_t attrs_type_index0;
/*!
* \\brief number of input arguments to the operator,
* -1 means it is variable length
*/
int32_t num_inputs = -1;
/*!
* \\brief support level of the operator,
* The lower the more priority it contains.
* This is in analogies to BLAS levels.
*/
int32_t support_level = 10;
...
;
最后我们看一下IRModule的定义,https://github.com/apache/tvm/blob/main/include/tvm/ir/module.h#L56。我们说过IRModule是TVM编译的最小单元,我们可以从它的定义中发现它就是一系列BaseFunc(在下一节Relay的介绍中我们会讲到它的实现)的映射。
/*!
* \\brief IRModule that holds functions and type definitions.
*
* IRModule is the basic unit for all IR transformations across the stack.
*
* Many operations require access to the global IRModule.
* We pass the IRModule by value in a functional style as an explicit argument,
* but we mutate the Module while optimizing programs.
* \\sa IRModule
*/
class IRModuleNode : public Object
public:
/*! \\brief A map from ids to all global functions. */
Map<GlobalVar, BaseFunc> functions;
/*! \\brief A map from global type vars to ADT type data. */
Map<GlobalTypeVar, TypeData> type_definitions;
/*! \\brief The source map for the module. */
parser::SourceMap source_map;
/* \\brief Additional attributes storing meta-data about the module. */
DictAttrs attrs;
...
其中type_definitions是对ADT的定义,本文不关注Relay中函数式编程的概念,所以不展开ADT以及Let Binding部分的概念和源码,感兴趣的朋友可以参考张伟大佬的这篇文章或者官方文档对Relay的介绍学习一下:https://zhuanlan.zhihu.com/p/446976730 。后面在介绍Relax IR的时候我们会看到,实际上Relax相比于Relay就类似于TensorFlow的静态图到PyTorch动态图的过度,更加强调数据流图的概念而非函数式编程的概念,我个人感觉也是为了易用性考虑吧。
0x1.3 Relay IR
接下来我们简单介绍一下Relay IR。首先Relay IR目前仍然是TVM和其它深度学习框架对接的主要方式,我之前在《【从零开始学TVM】三,基于ONNX模型结构了解TVM的前端》文章中以ONNX为例介绍了模型是如何转换为Relay IR的,然后这个Relay IR会被进一步封装为IRModule给TVM编译。
从源码角度来看,Relay的基类Expr就是tvm.ir基础设施中定义的RelayIR(https://github.com/apache/tvm/blob/main/include/tvm/relay/expr.h#L54)。
namespace relay
using Expr = tvm::RelayExpr;
using ExprNode = tvm::RelayExprNode;
using BaseFunc = tvm::BaseFunc;
using BaseFuncNode = tvm::BaseFuncNode;
using GlobalVar = tvm::GlobalVar;
using GlobalVarNode = tvm::GlobalVarNode;
using tvm::PrettyPrint;
然后Relay还定义了ConstantExpr,TupleExpr,VarExpr,CallNodeExpr,LetNodeExpr,IfNodeExpr等多种Expr。我们可以看一下ConstantExprNode的定义,类定义中声明了数据data并定义了tensor_type方法返回data的类型,然后is_scalar函数用来判断这个常量是否为标量。
*!
* \\brief Constant tensor type.
*/
class ConstantNode : public ExprNode
public:
/*! \\brief The data of the tensor */
runtime::NDArray data;
/*! \\return The corresponding tensor type of the data */
TensorType tensor_type() const;
/*! \\return Whether it is scalar(rank-0 tensor) */
bool is_scalar() const return data->ndim == 0;
...
;
然后我们再看一下VarNode的定义,Var就是Relay里面的变量,它的定义如下:
/*! \\brief Container for Var */
class VarNode : public ExprNode
public:
/*!
* \\brief The unique identifier of the Var.
*
* vid will be preserved for the same Var during type inference
* and other rewritings, while the VarNode might be recreated
* to attach additional information.
* This property can be used to keep track of parameter Var
* information across passes.
*/
Id vid;
/*!
* \\brief type annotaion of the variable.
* This field records user provided type annotation of the Var.
* This field is optional and can be None.
*/
Type type_annotation;
/*! \\return The name hint of the variable */
const String& name_hint() const return vid->name_hint;
;
首先Id vid表示的就是变量的名称,可以理解为一个字符串,比如我们在可视化Relay IR时看到的以@开头的全局变量以及%开头的局部变量。这里的type_annotation表示变量的类型注释,这个字段是可选的。接下来我们再看一个FunctionNode的定义,FunctionNode就是IRModule中的BaseFunc在Relay里面的具体实现了:
/*!
* \\brief Relay Function container
* \\sa Function
*/
class FunctionNode : public BaseFuncNode
public:
/*! \\brief Function parameters */
tvm::Array<Var> params;
/*!
* \\brief
* The expression which represents the computation of the function,
* the expression may reference the parameters, and the type of it
* or sub-expressions may reference the type variables.
*/
Expr body;
/*! \\brief User annotated return type of the function. */
Type ret_type;
/*!
* \\brief Type parameters of the function.
* Enables the function to vary its type based on these.
* This corresponds to template paramaters in c++'s terminology.
*
* \\note This can be usually empty for non-polymorphic functions.
*/
tvm::Array<TypeVar> type_params;
FunctionNode的定义中有函数参数,函数体以及返回值类型和参数类型。其它类型的Relay表达式定义我们就不看了,感兴趣的读者可以直接在https://github.com/apache/tvm/tree/main/include/tvm/relay阅读。
接下来我们解析一下Relay中的Op定义,上一节tvm.ir基础设施中我们已经提到无论是Relay还是TIR的Op都定义为一种RelayExpr,也就是OpNode的定义。我们这里看一个Relay定义的bias_add Op的例子来加深理解。
首先,我们为BiasAdd Op定一个属性类型记录它所有的属性,https://github.com/apache/tvm/blob/main/include/tvm/relay/attrs/nn.h#L35-L48,属性定义时我们还可以给属性设置描述和默认值:
/*!
* \\brief Add a 1D Tensor to an axis of a data.
*
* \\note bias_add is a special add operator that is in nn
* and enables automatic derivation of bias's shape.
* You can directly use add for more generalized case.
*/
struct BiasAddAttrs : public tvm::AttrsNode<BiasAddAttrs>
int axis;
TVM_DECLARE_ATTRS(BiasAddAttrs, "relay.attrs.BiasAddAttrs")
TVM_ATTR_FIELD(axis).describe("The axis to add the bias").set_default(1);
;
第二步,我们给Biass Add Op定义类型推断函数(https://github.com/apache/tvm/blob/main/src/relay/op/nn/nn.cc#L52):
bool BiasAddRel(const Array<Type>& types, int num_inputs, const Attrs& attrs,
const TypeReporter& reporter)
ICHECK_EQ(types.size(), 3);
const auto* data = types[0].as<TensorTypeNode>();
if (data == nullptr) return false;
const BiasAddAttrs* param = attrs.as<BiasAddAttrs>();
ICHECK(param != nullptr);
int axis = param->axis;
if (axis < 0)
axis = data->shape.size() + axis;
if (axis >= static_cast<int>(data->shape.size()) || axis < 0)
reporter->GetDiagCtx().EmitFatal(Diagnostic::Error(reporter->GetSpan())
<< "The axis in bias_add must be in range for the shape; "
<< "attempted to access index " << param->axis << " of "
<< PrettyPrint(data->shape));
return false;
// assign output type
reporter->Assign(types[1], TensorType(data->shape[axis], data->dtype));
reporter->Assign(types[2], types[0]);
return true;
假设这里指定的操作是 c = nn.bias_add(a , b),这里的逻辑就是根据输入a的类型推断b和c的类型并重写(Assign)。
第三步,我们把nn.BiasAdd Op注册到全局表中(https://github.com/apache/tvm/blob/main/src/relay/op/nn/nn.cc#L88-L103):
RELAY_REGISTER_OP("nn.bias_add")
.describe(R"code(Add bias to an axis of the input.
)code" TVM_ADD_FILELINE)
.set_attrs_type<BiasAddAttrs>()
.set_num_inputs(2)
.add_argument("data", "nD Tensor", "Input data.")
.add_argument("bias", "1D Tensor", "Bias.")
.set_support_level(1)
.add_type_rel("BiasAdd", BiasAddRel)
.set_attr<TOpPattern>("TOpPattern", kBroadcast)
.set_attr<FTVMCompute>("FTVMCompute", [](const Attrs& attrs, const Array<te::Tensor>& inputs,
const Type& out_type)
const auto* param = attrs.as<BiasAddAttrs>();
return tvm::Array<tvm::te::Tensor>topi::nn::bias_add(inputs[0], inputs[1], param->axis);
);
注意到这里的op name/describe/num_inputs/arguments/support_level是对应了OpNode类的成员,然后OpNode还有一个attrs_type_key和attrs_type_index成员对应的就是BiasAddAttrs了。然后我们再看一下这个FTVMCompute这个用来描述Op计算逻辑的额外属性,它使用Op的输入,属性参数以及输出类型来确定这个Op的计算逻辑。
到这里可能你还有一个疑问,我们知道TVM的核心是计算和调度分离,Relay Op的调度逻辑是怎么注册的呢?
TVM没有为每个Relay OP注册compute和schedule,而是为其注册fcompute和fschedule,然后根据输入和属性参数,输出类型等生成对应的compute和schedul,这种compute和schedule的组合对应了OpImplementation( 以上是关于TVM 学习指南(个人版)的主要内容,如果未能解决你的问题,请参考以下文章https://github.com/apache/tvm/blob/main