深度学习之模型优化模型剪枝模型量化知识蒸馏概述
Posted 大气层煮月亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之模型优化模型剪枝模型量化知识蒸馏概述相关的知识,希望对你有一定的参考价值。
前言
模型部署优化这个方向其实比较宽泛。从模型完成训练,到最终将模型部署到实际硬件上,整个流程中会涉及到很多不同层面的工作,每一个环节对技术点的要求也不尽相同。但本质的工作无疑是通过减小模型大小,提高推理速度等,使得模型能够成功部署在各个硬件之中去并且实时有效的运作。那么模型的部署优化有哪些方式呢?显而易见答案就在标题之中。
【深度学习之模型优化】模型剪枝、模型量化、知识蒸馏概述
模型剪枝技术概述
1. 什么是模型剪枝
深度学习网络模型从卷积层到全连接层存在着大量冗余的参数,大量神经元激活值趋近于0,将这些神经元去除后可以表现出同样的模型表达能力,这种情况被称为过参数化,而对应的技术则被称为模型剪枝。
模型剪枝是一个新概念吗?并不是,其实我们从学习深度学习的第一天起就接触过,Dropout和DropConnect代表着非常经典的模型剪枝技术,看下图。
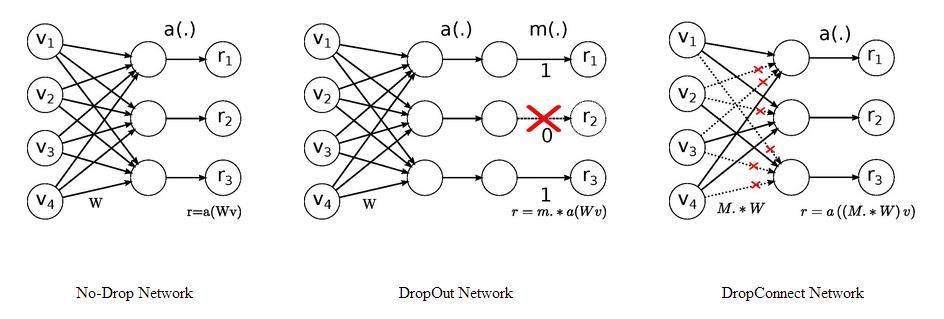
Dropout中随机的将一些神经元的输出置零,这就是神经元剪枝。DropConnect则随机的将一些神经元之间的连接置零,使得权重连接矩阵变得稀疏,这便是权重连接剪枝。它们就是最细粒度的剪枝技术,只是这个操作仅仅发生在训练中,对最终的模型不产生影响,因此没有被称为模型剪枝技术。
当然,模型剪枝不仅仅只有对神经元的剪枝和对权重连接的剪枝,根据粒度的不同,至少可以粗分为4个粒度。

细粒度剪枝(fine-grained):即对连接或者神经元进行剪枝,它是粒度最小的剪枝。
向量剪枝(vector-level):它相对于细粒度剪枝粒度更大,属于对卷积核内部(intra-kernel)的剪枝。
核剪枝(kernel-level):即去除某个卷积核,它将丢弃对输入通道中对应计算通道的响应。
滤波器剪枝(Filter-level):对整个卷积核组进行剪枝,会造成推理过程中输出特征通道数的改变。
细粒度剪枝(fine-grained),向量剪枝(vector-level),核剪枝(kernel-level)方法在参数量与模型性能之间取得了一定的平衡,但是网络的拓扑结构本身发生了变化,需要专门的算法设计来支持这种稀疏的运算,被称之为非结构化剪枝。
而滤波器剪枝(Filter-level)只改变了网络中的滤波器组和特征通道数目,所获得的模型不需要专门的算法设计就能够运行,被称为结构化剪枝。除此之外还有对整个网络层的剪枝,它可以被看作是滤波器剪枝(Filter-level)的变种,即所有的滤波器都丢弃。
2. 模型剪枝的必要性
既然冗余性是存在的,那么剪枝自然有它的必要性,下面以Google的研究来说明这个问题。
Google在《To prune, or not to prune: exploring the efficacy of pruning for model compression》[1]中探讨了具有同等参数量的稀疏大模型和稠密小模型的性能对比,在图像和语音任务上表明稀疏大模型普遍有更好的性能。
它们对Inception V3模型进行了实验,在参数的稀疏性分别为0%,50%,75%,87.5%时,模型中非零参数分别是原始模型的1,0.5,0.25,0.128倍进行了实验。实验结果表明在稀疏性为50%时,Inception V3模型的性能几乎不变。稀疏性为87.5%时,在ImageNet上的分类指标下降为2%。
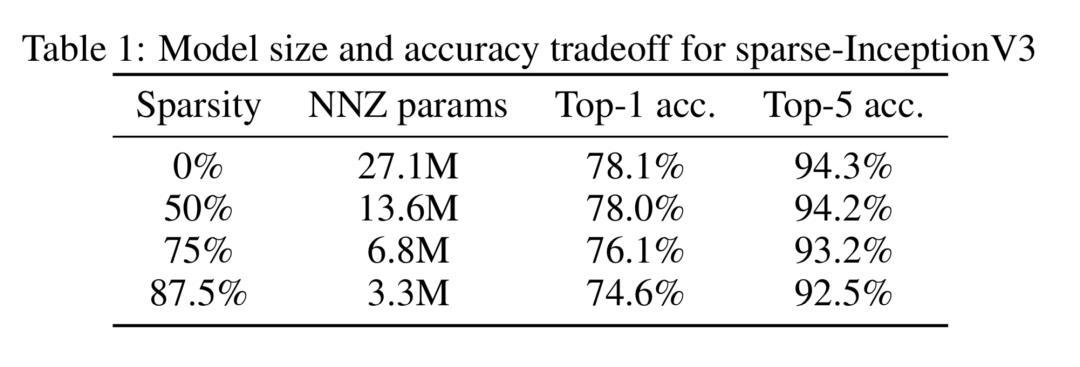
因此,我们完全可以相信,模型剪枝是有效的而且是必要的,剩下的问题就是怎么去找到冗余的参数进行剪枝。
模型量化技术概述
1. 什么是模型量化
我们知道为了保证较高的精度,大部分的科学运算都是采用浮点型进行计算,常见的是32位浮点型和64位浮点型,即float32和double64。
对于深度学习模型来说,乘加计算量是非常大的,往往需要GPU等专用的计算平台才能实现实时运算,这对于端上产品来说是不可接受的,而模型量化是一个有效降低计算量的方法。
量化,即将网络的权值,激活值等从高精度转化成低精度的操作过程,例如将32位浮点数转化成8位整型数int8,同时我们期望转换后的模型准确率与转化前相近。
2. 模型量化的优势
模型量化可以带来几方面的优势,如下。
(1) 更小的模型尺寸。以8bit量化为例,与32bit浮点数相比,我们可以将模型的体积降低为原来的四分之一,这对于模型的存储和更新来说都更有优势。
(2) 更低的功耗。移动8bit数据与移动32bit浮点型数据相比,前者比后者高4倍的效率,而在一定程度上内存的使用量与功耗是成正比的。
(3) 更快的计算速度。相对于浮点数,大多数处理器都支持8bit数据的更快处理,如果是二值量化,则更有优势。
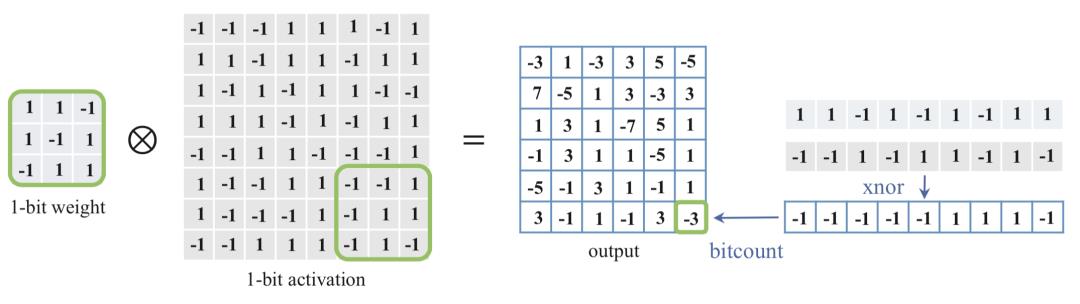
上图展示的是一个二值权重和激活值矩阵的运算,卷积过程中的乘加都可以转换为异或操作,并行程度更高,运算速度因此也更快。
因此,在工业界对模型量化有着非常强烈的需求。
模型压缩中知识蒸馏技术概述
1. 什么是知识蒸馏
一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而可以实现模型压缩与加速,就是知识蒸馏与迁移学习在模型优化中的应用。
Hinton等人最早在文章“Distilling the knowledge in a neural network”[1]中提出了知识蒸馏这个概念,其核心思想是一旦复杂网络模型训练完成,便可以用另一种训练方法从复杂模型中提取出来更小的模型,因此知识蒸馏框架通常包含了一个大模型(被称为teacher模型),和一个小模型(被称为student模型)。
2. 为什么要进行知识蒸馏
以计算机视觉模型的训练为例,我们经常用在ImageNet上训练的模型作为预训练模型,之所以可以这样做,是因为深度学习模型在网络浅层学习的知识是图像的色彩和边缘等底层信息,某一个数据集学习到的信息也可以应用于其他领域。
那实际上知识蒸馏或者说迁移学习的必要性在哪里?
(1) 数据分布差异。深度学习模型的训练场景和测试场景往往有分布差异,以自动驾驶领域为例,大部分数据集的采集都是基于白天,光照良好的天气条件下,在这样的数据集上训练的模型,当将其用于黑夜,风雪等场景时,很有可能会无法正常工作,从而使得模型的实用性能非常受限。因此,必须考虑模型从源域到目标域的迁移能力。
(2) 受限的数据规模。数据的标注成本是非常高的,导致很多任务只能用少量的标注进行模型的训练。以医学领域为典型代表,数据集的规模并不大,因此在真正专用的模型训练之前往往需要先在通用任务上进行预训练。
(3) 通用与垂直领域。虽然我们可以训练许多通用的模型,但是真实需求是非常垂直或者说个性化的,比如ImageNet存在1000类,但是我们可能只需要用到其中若干类。此时就可以基于1000类ImageNet模型进行知识迁移,而不需要完全从头开始训练。
因此,在工业界对知识蒸馏和迁移学习也有着非常强烈的需求。
以上是关于深度学习之模型优化模型剪枝模型量化知识蒸馏概述的主要内容,如果未能解决你的问题,请参考以下文章