DataFrame(11):数据转换——map()函数的使用
Posted 程序员超时空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataFrame(11):数据转换——map()函数的使用相关的知识,希望对你有一定的参考价值。
1、map()函数
1)map()函数作用
将序列中的每一个元素,输入函数,最后将映射后的每个值返回合并,得到一个迭代器。
2)map()函数原理图
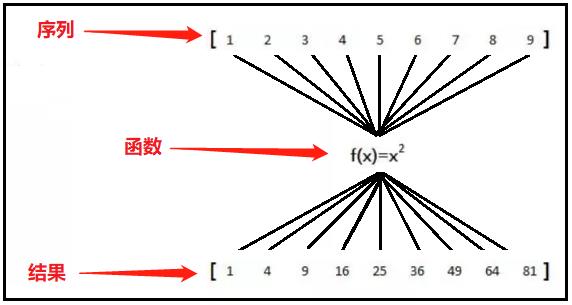
原理解释:
上图有一个列表,元素分别是从1-9。map()函数的作用就是,依次从这个列表中取出每一个元素,然后放到f(x)函数中,最终得到一个通过函数映射后的结果。
3)map()内置函数和Series的map()方法
① map作为python内置函数的用法
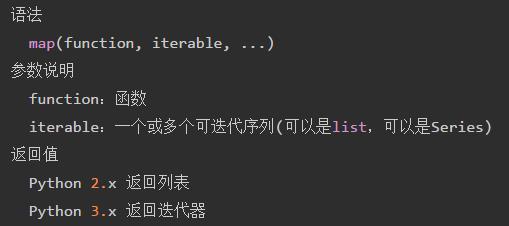
说明:依次取出序列(iterable)中的每一个元素,放到函数(function)中,最终得到一个迭代器,我们可以使用list或者for循环得到其中的元素。
② Series的map()方法
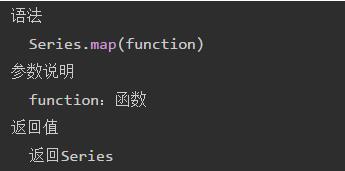
说明:依次取出序列(Series)中的每一个元素,放到函数(function)中,最终得到一个Series结果。
2、map()函数实例
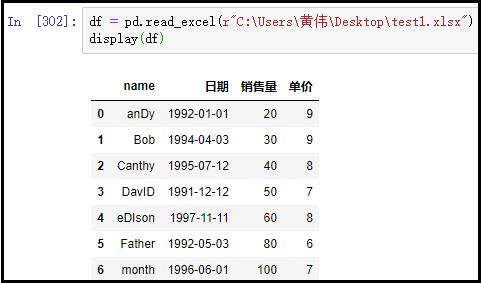
1)原始数据文件链接如下
df = pd.read_excel(r"C:Users黄伟Desktop est1.xlsx")
display(df)
结果如下:
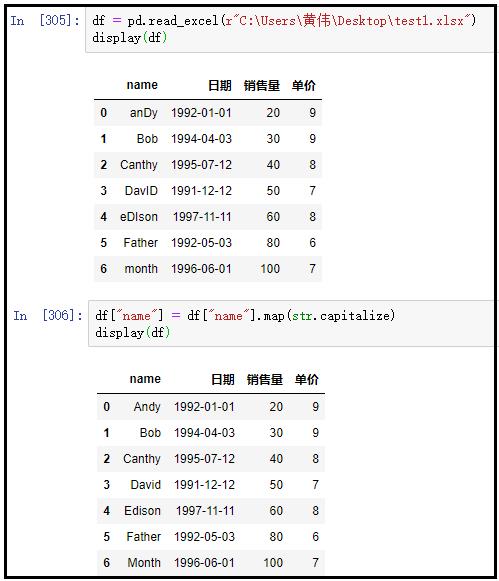
① 将姓名转换为首字母大写,其余字母小写
df = pd.read_excel(r"C:Users黄伟Desktop est1.xlsx")
display(df)
df["name"] = df["name"].map(str.capitalize)
display(df)
结果如下:
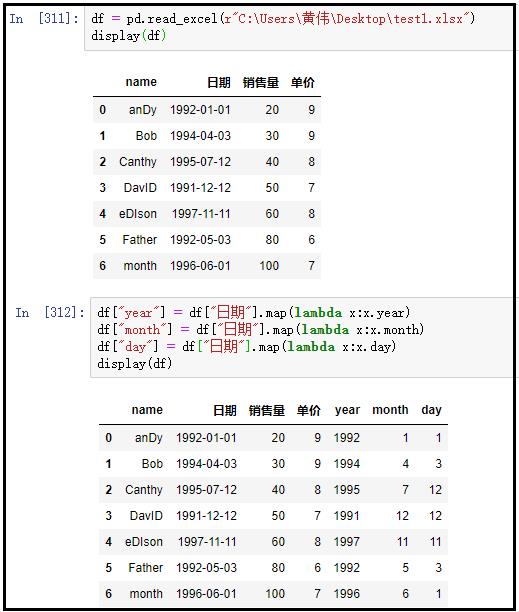
② 提取日期中的年、月、日
df = pd.read_excel(r"C:Users黄伟Desktop est1.xlsx")
display(df)
# 注意:这里的日期列,是时间格式
df["year"] = df["日期"].map(lambda x:x.year)
df["month"] = df["日期"].map(lambda x:x.month)
df["day"] = df["日期"].map(lambda x:x.day)
display(df)
结果如下:
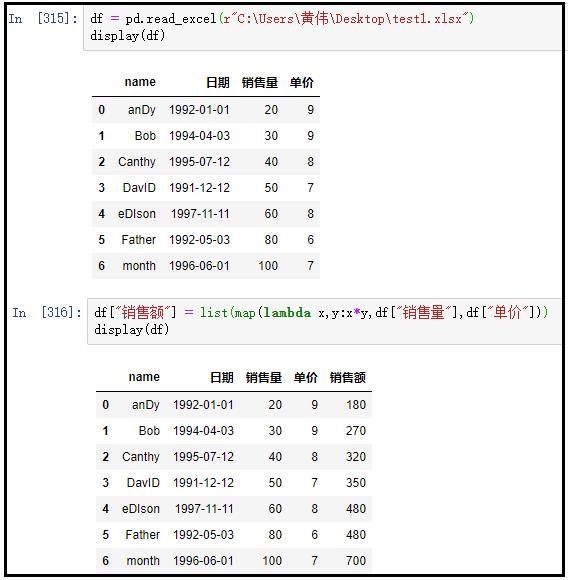
③ 求每个人的销售额:销售量*单价
df = pd.read_excel(r"C:Users黄伟Desktop est1.xlsx")
display(df)
df["销售额"] = list(map(lambda x,y:x*y,df["销售量"],df["单价"]))
display(df)
结果如下:
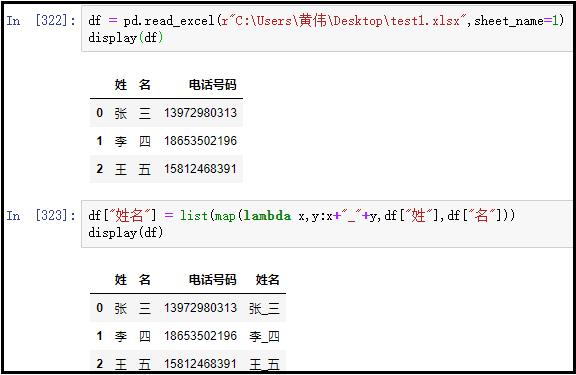
④ 合并两列
df = pd.read_excel(r"C:Users黄伟Desktop est1.xlsx",sheet_name=1)
display(df)
df["姓名"] = list(map(lambda x,y:x+"_"+y,df["姓"],df["名"]))
display(df)
结果如下:
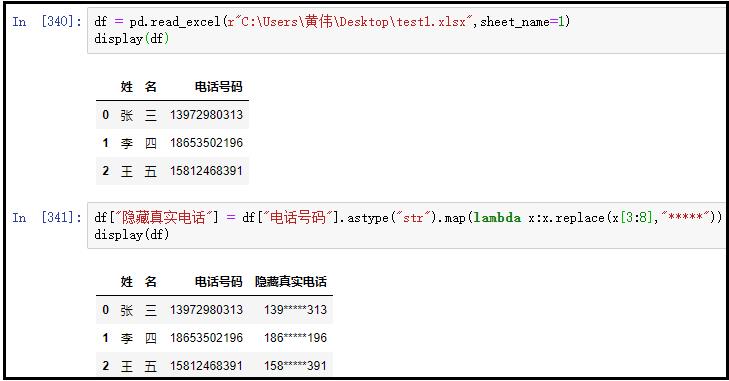
⑤ 将电话号码中间4-8位替换为*
df = pd.read_excel(r"C:Users黄伟Desktop est1.xlsx",sheet_name=1)
display(df)
df["隐藏真实电话"] = df["电话号码"].astype("str").map(lambda x:x.replace(x[3:8],"*****"))
display(df)
结果如下:
以上是关于DataFrame(11):数据转换——map()函数的使用的主要内容,如果未能解决你的问题,请参考以下文章