Keras CIFAR-10分类 LeNet-5篇
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras CIFAR-10分类 LeNet-5篇相关的知识,希望对你有一定的参考价值。
Keras CIFAR-10分类 LeNet-5篇
文章目录
除了用pytorch可以进行图像分类之外,我们也可以利用tensorflow来进行图像分类,其中利用tensorflow的后端keras更是尤为简单,接下来我们就利用keras对CIFAR10数据集进行分类。
keras介绍

keras是python深度学习中常用的一个学习框架,它有着极其强大的功能,基本能用于常用的各个模型。
keras具有的特性
1、相同的代码可以在cpu和gpu上切换;
2、在模型定义上,可以用函数式API,也可以用Sequential类;
3、支持任意网络架构,如多输入多输出;
4、能够使用卷积网络、循环网络及其组合。
keras与后端引擎
Keras 是一个模型级的库,在开发中只用做高层次的操作,不处于张量计算,微积分计算等低级操作。但是keras最终处理数据时数据都是以张量形式呈现,不处理张量操作的keras是如何解决张量运算的呢?
keras依赖于专门处理张量的后端引擎,关于张量运算方面都是通过后端引擎完成的。这也就是为什么下载keras时需要下载TensorFlow 或者Theano的原因。而TensorFlow 、Theano、以及CNTK都属于处理数值张量的后端引擎。

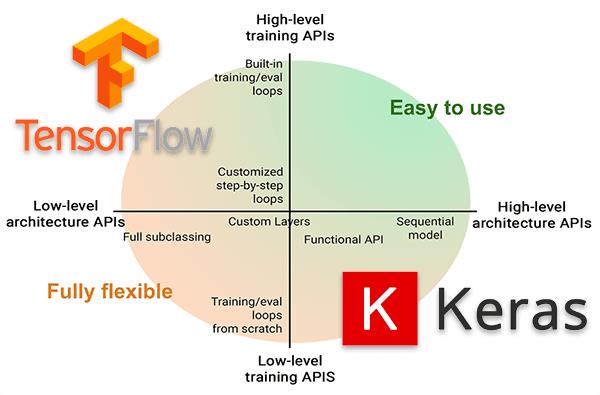
keras设计原则
- 用户友好:Keras是为人类而不是天顶星人设计的API。用户的使用体验始终是我们考虑的首要和中心内容。Keras遵循减少认知困难的最佳实践:Keras提供一致而简洁的API, 能够极大减少一般应用下用户的工作量,同时,Keras提供清晰和具有实践意义的bug反馈。
- 模块性:模型可理解为一个层的序列或数据的运算图,完全可配置的模块可以用最少的代价自由组合在一起。具体而言,网络层、损失函数、优化器、初始化策略、激活函数、正则化方法都是独立的模块,你可以使用它们来构建自己的模型。
- 易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可。创建新模块的便利性使得Keras更适合于先进的研究工作。
- 与Python协作:Keras没有单独的模型配置文件类型(作为对比,caffe有),模型由python代码描述,使其更紧凑和更易debug,并提供了扩展的便利性。
安装keras
安装也是很简单的,我们直接安装keras即可,如果需要tensorflow,就还需要安装tensorflow
pip install keras
导入库
import keras
from keras.models import Sequential
from keras.datasets import cifar10
from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense, Activation
from keras.optimizers import adam_v2
from keras.utils.vis_utils import plot_model
from keras.utils.np_utils import to_categorical
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
import numpy as np
import os
import shutil
import matplotlib
matplotlib.style.use('ggplot')
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
控制GPU显存(可选)
这个是tensorflow来控制选择的GPU,因为存在多卡的时候可以指定GPU,其次还可以控制GPU的显存
这段语句就是动态显存,动态分配显存
config.gpu_options.allow_growth = True
这段语句就是说明,我们使用的最大显存不能超过50%
config.gpu_options.per_process_gpu_memory_fraction = 0.5
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 忽略低级别的警告
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
# The GPU id to use, usually either "0" or "1"
os.environ["CUDA_VISIBLE_DEVICES"]="0"
config = tf.compat.v1.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.5
config.gpu_options.allow_growth = True
session = tf.compat.v1.Session(config=config)
加载 CIFAR-10 数据集
CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( arplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练圄片和 10000 张测试图片。
与 MNIST 数据集中目比, CIFAR-10 具有以下不同点:
- CIFAR-10 是 3 通道的彩色 RGB 图像,而 MNIST 是灰度图像。
- CIFAR-10 的图片尺寸为 32×32, 而 MNIST 的图片尺寸为 28×28,比 MNIST 稍大。
- 相比于手写字符, CIFAR-10 含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、 特征都不尽相同,这为识别带来很大困难。

num_classes = 10 # 有多少个类别
(x_train, y_train), (x_val, y_val) = cifar10.load_data()
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170500096/170498071 [==============================] - 5s 0us/step
170508288/170498071 [==============================] - 5s 0us/step
print("训练集的维度大小:",x_train.shape)
print("验证集的维度大小:",x_val.shape)
训练集的维度大小: (50000, 32, 32, 3)
验证集的维度大小: (10000, 32, 32, 3)
可视化数据
x_train = x_train.astype('float32')/255
x_val = x_val.astype('float32')/255
class_names = ['airplane','automobile','bird','cat','deer',
'dog','frog','horse','ship','truck']
fig = plt.figure(figsize=(20,5))
for i in range(num_classes):
ax = fig.add_subplot(2, 5, 1 + i, xticks=[], yticks=[])
idx = np.where(y_train[:]==i)[0] # 取得类别样本
features_idx = x_train[idx,::] # 取得图片
img_num = np.random.randint(features_idx.shape[0]) # 随机挑选图片
im = features_idx[img_num,::]
ax.set_title(class_names[i])
plt.imshow(im)
plt.show()

数据预处理
# 将向量转化为二分类矩阵,也就是one-hot编码
y_train = to_categorical(y_train, num_classes)
y_val = to_categorical(y_val, num_classes)
output_dir = './output' # 输出目录
if os.path.exists(output_dir) is False:
os.mkdir(output_dir)
# shutil.rmtree(output_dir)
# print('%s文件夹已存在,但是没关系,我们删掉了' % output_dir)
# os.mkdir(output_dir)
print('%s已创建' % output_dir)
print('%s文件夹已存在' % output_dir)
model_name = 'lenet5'
./output文件夹已存在
LeNet5网络
手写字体识别模型LeNet5诞生于1994年,是最早的卷积神经网络之一。LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。
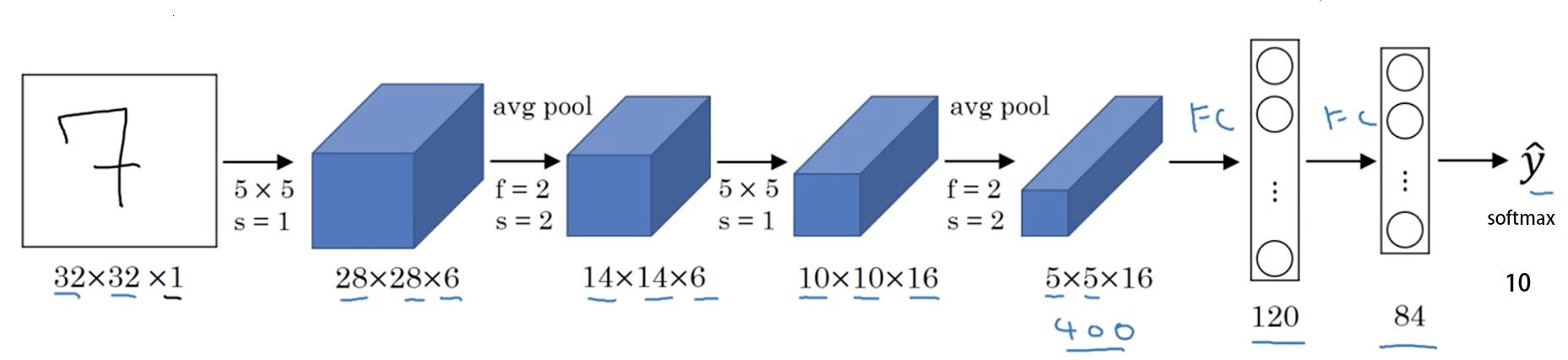
LeNet-5 一些性质:
-
如果输入层不算神经网络的层数,那么 LeNet-5 是一个 7 层的网络。(有些地方也可能把 卷积和池化 当作一个 layer)(LeNet-5 名字中的“5”也可以理解为整个网络中含可训练参数的层数为 5。)
-
LeNet-5 大约有 60,000 个参数。
-
随着网络越来越深,图像的高度和宽度在缩小,与此同时,图像的 channel 数量一直在增加。
-
现在常用的 LeNet-5 结构和 Yann LeCun 教授在 1998 年论文中提出的结构在某些地方有区别,比如激活函数的使用,现在一般使用 ReLU 作为激活函数,输出层一般选择 softmax。
input_shape = (32,32,3)
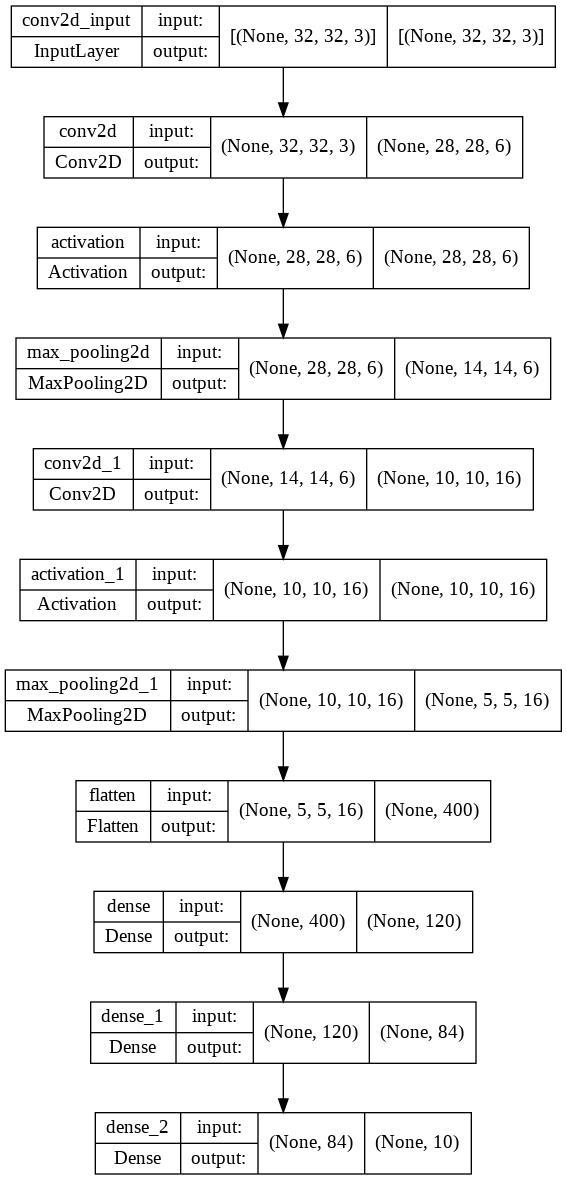
def LeNet5():
model = Sequential()
model.add(Conv2D(input_shape = input_shape, filters = 6, kernel_size = (5,5), strides = 1, padding = 'valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2),strides=(2,2)))
model.add(Conv2D(filters= 16,kernel_size=(5,5),strides = 1, padding='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2),strides=(2,2)))
model.add(Flatten())
model.add(Dense(120,activation='relu'))
model.add(Dense(84,activation='relu'))
# final layer with 10 neurons to classify the instances
model.add(Dense(num_classes, activation = 'softmax'))
return model
model = LeNet5()
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 6) 456
activation (Activation) (None, 28, 28, 6) 0
max_pooling2d (MaxPooling2D (None, 14, 14, 6) 0
)
conv2d_1 (Conv2D) (None, 10, 10, 16) 2416
activation_1 (Activation) (None, 10, 10, 16) 0
max_pooling2d_1 (MaxPooling (None, 5, 5, 16) 0
2D)
flatten (Flatten) (None, 400) 0
dense (Dense) (None, 120) 48120
dense_1 (Dense) (None, 84) 10164
dense_2 (Dense) (None, 10) 850
=================================================================
Total params: 62,006
Trainable params: 62,006
Non-trainable params: 0
_________________________________________________________________
model_img = output_dir + '/cifar10_%s.png'%(model_name) # 模型结构图保存路径
plot_model(model, to_file=model_img, show_shapes=True) # 模型结构保存为一张图片
print('%s已保存' % model_img)
./output/cifar10_lenet5.png已保存
开始训练模型
首先我们可以设置我们的迭代次数和batch_size
epochs = 20 # 迭代次数
batch_size = 128 # 批大小
这一部分是设置在训练的时候的一些参数
- 首先保存最好的模型,先定义我们的model path
- 设置save_best_only=True,也就是代表只保存一遍
- monitor='val_loss’代表的是监视val_loss,着重观察val_loss,只选取最小的val_loss的模型进行保存,当然这个我们也可以换成val_acc也是可以的
checkpoint = ModelCheckpoint(output_dir + '/best_%s_simple.h5'%model_name, # model filename
monitor='val_loss', # quantity to monitor
verbose=0, # verbosity - 0 or 1
save_best_only= True, # The latest best model will not be overwritten
mode='auto') # The decision to overwrite model is made
# automatically depending on the quantity to monitor
接下来我们就可以定义我们的优化器和损失函数了,keras很简单,并且定义我们需要计算的metrics为准确率即可
adam = adam_v2.Adam(lr = 0.0001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
最后我们使用内置的fit函数,并且加上我们所需要的超参数,就可以完成我们的训练了。
history = model.fit(x_train,y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_val,y_val),
shuffle=True,
callbacks=[checkpoint])
Epoch 1/20
391/391 [==============================] - 9s 11ms/step - loss: 2.0973 - accuracy: 0.2302 - val_loss: 1.9195 - val_accuracy: 0.3087
Epoch 2/20
391/391 [==============================] - 2s 5ms/step - loss: 1.8325 - accuracy: 0.3456 - val_loss: 1.7620 - val_accuracy: 0.3747
Epoch 3/20
391/391 [==============================] - 2s 5ms/step - loss: 1.7122 - accuracy: 0.3885 - val_loss: 1.6722 - val_accuracy: 0.3945
Epoch 4/20
391/391 [==============================] - 2s 5ms/step - loss: 1.6389 - accuracy: 0.4133 - val_loss: 1.6102 - val_accuracy: 0.4213
Epoch 5/20
391/391 [==============================] - 2s 6ms/step - loss: 1.5868 - accuracy: 0.4346 - val_loss: 1.5666 - val_accuracy: 0.4372
Epoch 6/20
391/391 [==============================] - 2s 6ms/step - loss: 1.5509 - accuracy: 0.4447 - val_loss: 1.5366 - val_accuracy: 0.4478
Epoch 7/20
391/391 [==============================] - 2s 6ms/step - loss: 1.5196 - accuracy: 0.4567 - val_loss: 1.5111 - val_accuracy: 0.4571
Epoch 8/20
391/391 [==============================] - 2s 6ms/step - loss: 1.5010 - accuracy: 0.4622 - val_loss: 1.4935 - val_accuracy: 0.4661
Epoch 9/20
391/391 [==============================] - 3s 9ms/step - loss: 1.4773 - accuracy: 0.4713 - val_loss: 1.4778 - val_accuracy: 0.4707
Epoch 10/20
391/391 [==============================] - 4s 10ms/step - loss: 1.4592 - accuracy: 0.4787 - val_loss: 1.4574 - val_accuracy: 0.4768
Epoch 11/20
391/391 [==============================] - 4s 10ms/step - loss: 1.4432 - accuracy: 0.4848 - val_loss: 1.4589 - val_accuracy: 0.4809
Epoch 12/20
391/391 [==============================] - 4s 9ms/step - loss: 1.4294 - accuracy: 0.4915 - val_loss: 1.4403 - val_accuracy: 0.4906
Epoch 13/20
391/391 [==============================] - 2s 6ms/step - loss: 1.4145 - accuracy: 0.4967 - val_loss: 1.4243 - val_accuracy: 0.4906
Epoch 14/20
391/391 [==============================] - 2s 6ms/step - loss: 1.4036 - accuracy: 0.5007 - val_loss: 1.4118 - val_accuracy: 0.4917
Epoch 15/20
391/391 [==============================] - 2s 6ms/step - loss: 1.3900 - accuracy: 0.5056 - val_loss: 1.4012 - val_accuracy: 0.4980
Epoch 16/20
391/391 [==============================] - 2s 5ms/step - loss: 1.3819 - accuracy: 0.5093 - val_loss: 1.4063 - val_accuracy: 0.4965
Epoch 17/20
391/391 [==============================] - 2s 6ms/step - loss: 1.3704 - accuracy: 0.5132 - val_loss: 1.3891 - val_accuracy: 0.5048
Epoch 18/20
391/391 [==============================] - 2s 6ms/step - loss: 1.3597 - accuracy: 0.5175 - val_loss: 1.3790 - val_accuracy: 0.5063
Epoch 19/20
391/391 [==============================] - 2s 6ms/step - loss: 1.3496 - accuracy: 0.5220 - val_loss: 1.3744 - val_accuracy: 0.5078
Epoch 20/20
391/391 [==============================] - 2s 5ms/step - loss: 1.3429 - accuracy: 0.5228 - val_loss: 1.3719 - val_accuracy: 0.5062
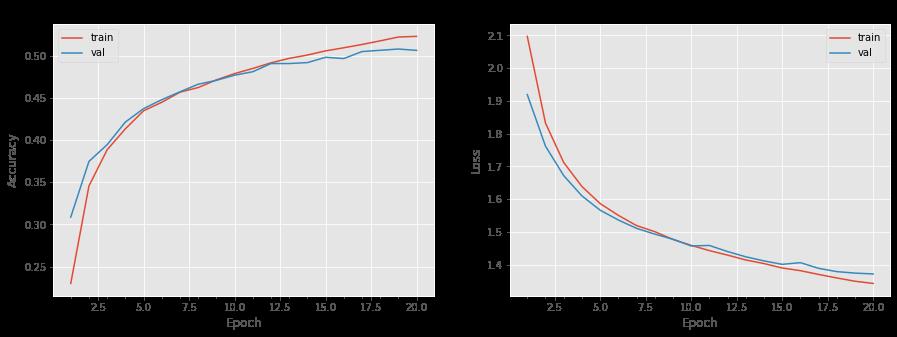
可视化准确率、损失函数
def plot_model_history(model_history):
fig, axs = plt.subplots(1,2,figsize=(15,5))
# summarize history for accuracy
axs[0].plot(range(1,len(model_history.history['accuracy'])+1),model_history.history['accuracy'])
axs[0].plot(range(1,len(model_history.history['val_accuracy'])+1),model_history.history['val_accuracy'])
axs[0].set_title('Model Accuracy')
axs[0].set_ylabel('Accuracy')
axs[0].set_xlabel('Epoch')
axs[0].set_xticks(np.arange(1,len(model_history.history['accuracy'])+1),len(model_history.history['accuracy'])/10)
axs[0].legend(['train', 'val'], loc='best')
# summarize history for loss
axs[1].plot(range(1,len(model_history.history['loss'])+1),model_history.history['loss'])
axs[1].plot(range(1,len(model_history.history['val_loss'])+1),model_history.history['val_loss'])
axs[1].set_title('Model Loss')
axs[1].set_ylabel('Loss')
axs[1].set_xlabel('Epoch')
axs[1].set_xticks(np.arange(1,len(model_history.history['loss'])+1),len(model_history.history['loss'])/10)
axs[1].legend(['train', 'val'], loc='best')
plt.show()
plot_model_history(history)
保存模型
model_path = output_dir + '/keras_cifar10_%s_model.h5'%(model_name)
model.save(model_path)
print('%s已保存' % model_path)
./output/keras_cifar10_lenet5_model.h5已保存
预测结果
# 取验证集里面的图片拿来预测看看
name = 0: 'airplane', 1: 'automobile', 2: 'bird', 3: 'cat', 4: 'deer',
5: 'dog', 6: 'frog', 7: 'horse', 8: 'ship', 9: 'truck'
n = 20 # 取多少张图片
x_test = x_val[:n]
y_test = y_val[:n]
# 预测
y_predict = model.predict(x_test, batch_size=n)
# 绘制预测结果
plt.figure(figsize=(18, 3)) # 指定画布大小
for i in range(n):
plt.subplot(2, 10, i + 1)
plt.axis('off') # 取消x,y轴坐标
plt.imshow(x_test[i]) # 显示图片
if y_test[i].argmax() == y_predict[i].argmax():
# 预测正确,用绿色标题
plt.title('%s,%s' % (name[y_test[i].argmax()], name[y_predict[i].argmax()]), color='green')
else:
# 预测错误,用红色标题
plt.title('%s,%s' % (name[y_test[i].argmax()], name[y_predict[i].argmax()]), color='red')
predict_img = output_dir + '/predict_%s.png'%(model_name)
print('%s已保存' % predict_img)
plt.savefig(predict_img) # 保存预测图片
plt.show() # 显示画布
./output/predict_lenet5.png已保存

loss,acc = model.evaluate(x_test,y_test)
print('evaluate loss:%f acc:%f' % (loss, acc))
1/1 [==============================] - 0s 21ms/step - loss: 1.0860 - accuracy: 0.6000
evaluate loss:1.085981 acc:0.600000
loss,acc = model.evaluate(x_val,y_val)
print('evaluate loss:%f acc:%f' % (loss, acc))
313/313 [==============================] - 1s 3ms/step - loss: 1.3719 - accuracy: 0.5062
evaluate loss:1.371894 acc:0.506200
数据增强
除了用原图片进行训练之外,我们
以上是关于Keras CIFAR-10分类 LeNet-5篇的主要内容,如果未能解决你的问题,请参考以下文章