极智Paper | 性能数据炸裂的多模态模型BEiT-3:Image as a Forign Language
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了极智Paper | 性能数据炸裂的多模态模型BEiT-3:Image as a Forign Language相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文解读一下 性能数据炸裂的多模态模型 BEiT-3:Image as a Forign Language。
介绍一个在 视觉 和 视觉-语言任务上具有 state-of-the-art 迁移能力的多模态模型 BEiT-3,BEiT-3 主要从三个方面来促进大融合:(1) backbone architecture;(2) pretraining task;(3) model scaling up。在 BEiT-3 中有意思的是把图片 images 都用语言的形式 “Imglish” 来表示,配合文本 texts “English” 和 图片-文本对 “parallel sentences” 。BEiT-3 在多种任务如视觉任务(目标检测、图像分割、图像分类问题)、多模态任务(图像理解、图像问答等任务) 中都有优秀的表现,迫不及待上图了:
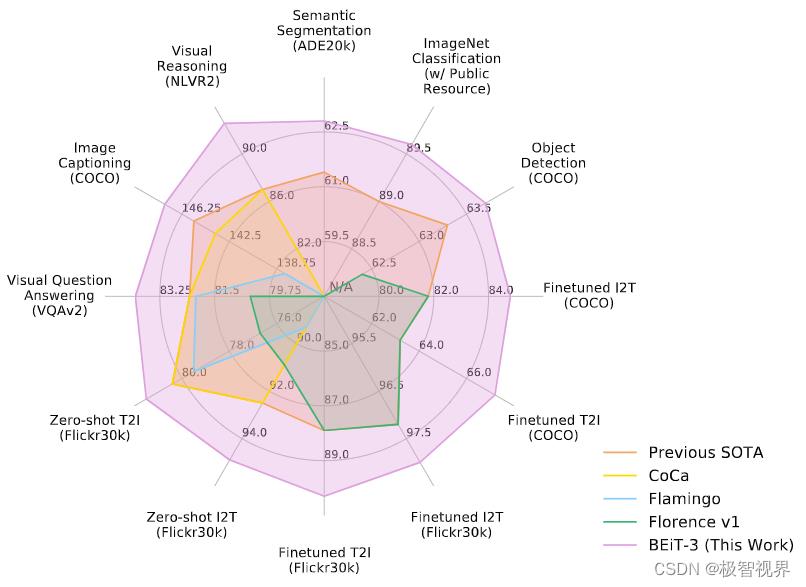
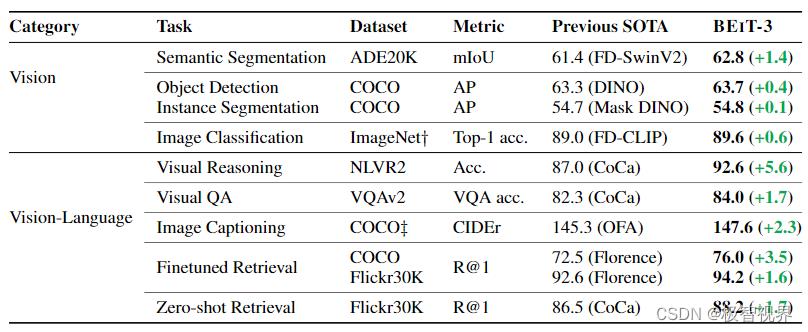
文章目录
1. 简介
近年来涌现了很多融合了多模态预训练的大模型,涉及语言、视觉和多模态领域。通过对大量数据进行大规模预训练,完事后可以很容易将大模型迁移到下游的各种任务中 (downstream tasks)。基于此,作者提出关于 视觉-语言预训练收敛趋势的三要素:
(1) 对于通常的视觉-语言建模,由于下游任务性质不同,需要有不同的方法来调整 transformer。例如,双编码器架构适用于高效检索,编码器-解码器网络适用于生成任务,融合编码器架构适用于图像-文本编码。然而,大多数基础大模型在应用于不同的下游任务时,需要手动转换 end-task 格式。此外,参数不能够有效地跨模态共享,也是一个缺陷。在 BEiT-3 中使用 Multiway transformer 进行通用建模,各种下游任务可以共享一个统一的架构,模块化的网络还综合考虑了特定模态编码和跨模态融合。
(2) 基于掩码数据建模的预训练任务已经成功应用于文本、图像、图像-文本对等各种模式。当前的视觉-语言基础模型通常用多任务处理其他预训练目标,如图像-文本匹配时,render scaling-up 低效且不友好。相反,BEiT-3 只使用一个预处理任务 mask-then-predict,来训练一个通用的多模态基础模型。通过将图片视作一种特别的外语 Imglish,这样可以以相同的方式处理文本和图像,从而消除建模的差异。所以这个时候的图像-文本对,其实就是一个句子对 “parallel sentences”。这种简单而有效的方法可以学习强大的迁移表征,能够在视觉和视觉-语言任务中实现 state-of-the-art 的性能。
(3) 模型规模和数据规模的普遍扩大提高了基础模型的泛化质量,这使我们可以将其转移到其他下游任务。作者遵循了这个规律,将模型规模扩大到数十亿个参数,同时也扩大了预训练数据集的大小,但没有使用任何私人数据,用的训练数据都是公开的,即使这样,BEiT-3在很大程度上优于依赖于私有数据集的最先进的模型。此外将image视为imglish,可以直接重用为大规模语言模型预训练开发的 pipeline,从而提高扩展性。
基于此,作者预训练了一个通用多模态基础模型 BEiT-3,通过对图像、文本及图像-文本对数据掩码建模来预训练 multiway transformer。自监督学习的目标是喂损坏的/残缺的输入,而能够还原原始 tokens,所以做法就是在预训练过程中,随机掩膜掉一定比例的 text tokens 或 image patches。
2. 方法
如下图,BEiT-3 使用共享的多路 transformer 网络,通过对单模态和多模态进行掩膜数据建模进行预训练。
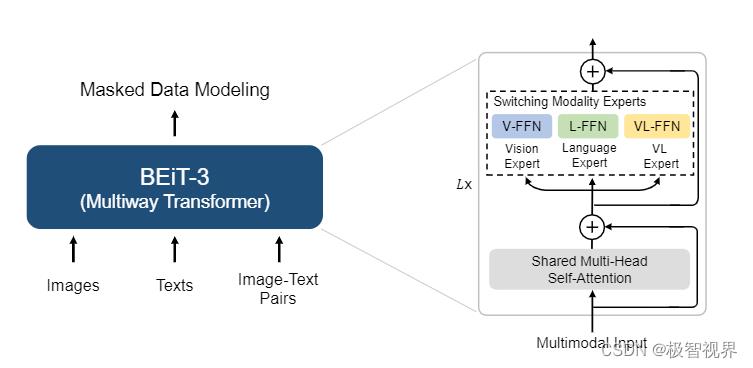
2.1 Backbone Network: Multiway Transformers
使用 多路transformer 作为骨干模型来编码不同的模态,每个多路 transformer 模块由一个共享的自注意力模块和一组用于不同模态的前馈网络组成,根据每个输入 token 的模态,路由给不同的 experts。此外,前三层的视觉-语言的 experts 是为融合编码器所设计的。如下图是更加详细的模型布局 layouts。
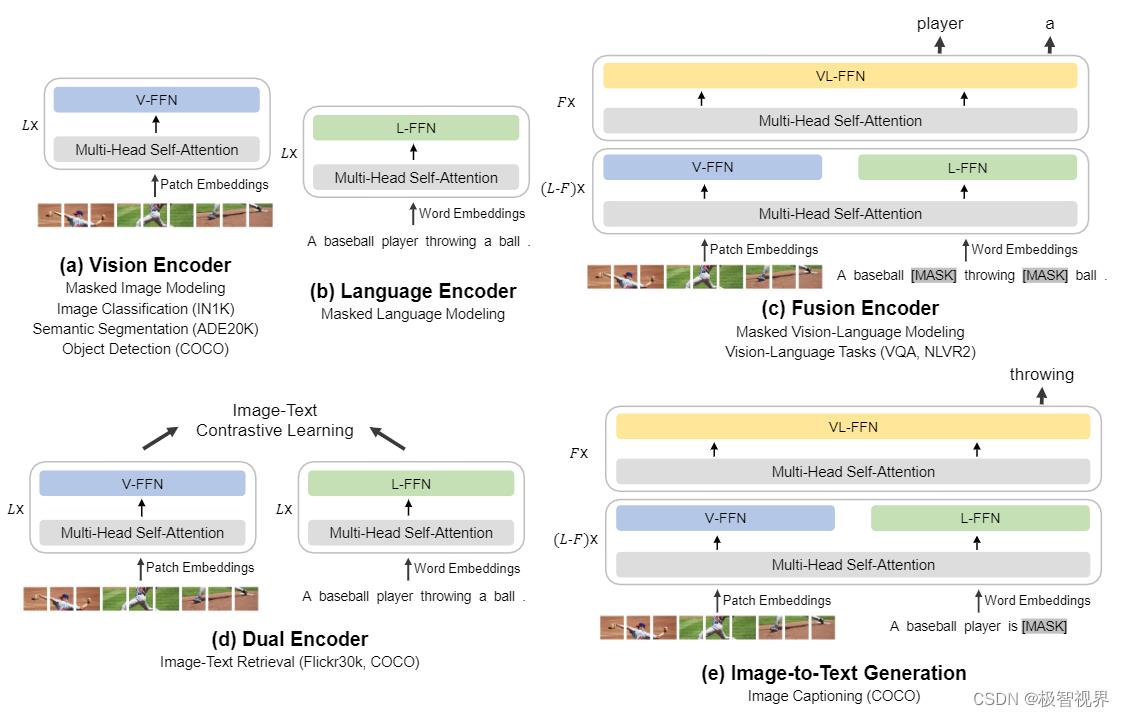
使用一组 experts 可以促进模型捕捉更多特定模态的信息,共享的自注意模块是为了对齐不同模态,以及深度融合多模态任务。统一的架构赋能 BEit-3,使其能够支持广泛的下游任务。例如,BEiT-3 可以用作各种视觉任务的 backbone,包括图像分类、目标检测、实例分割和语义分割。你还可以将它微调为一个有效的图像-文本检索的双编码器以及一个多模态理解和生成任务的融合模型。统一的 mask-then-predict 任务不仅用于学习表征,而且还用于学习不同模态的对齐。
2.2 Pretraining Task: Masked Data Modeling
作者通过在对统一的单模态和多模态掩膜数据建模的基础上预训练 BEiT-3。在预训练过程中,随机屏蔽一定比例的 text tokens 或 image patches,通过训练模型来恢复掩膜 tokens。具体的,文本数据通过 SentencePiece 进行标记,而图像数据通过 BEiT v2 提出的 tokenizer 进行标记。预训练时随机屏蔽 15% 的单模态文本标记和 50% 的图像-文本对标记,而对于图像,使用 BEiT 中那样的 block-wise 块级掩膜策略来屏蔽 40% 的图像 patches。
作者只使用一个预训练任务,这样使训练过程很容易扩展 scaling-up。相比之下,以往的视觉-语言模型通常采用多种预训练任务,如图像-文本比对、图像-文本匹配、word-patch/region 对齐。这样的方法证明了一个更加小的预训练 batchsize 仍然可以用于 mask-then-predict 任务。相比之下,基于对比的模型通常需要非常大的 batchsize 进行预训练,这将带来更多的工程挑战,如 GPU 内存成本太高。
2.3 Scaling up: BEiT-3 Pretraining
Backbone Network
BEiT-3 是 following ViT-giant 构建的巨型基础模型,该模型由一个 40 层的多路 transformer 组成,其中 hidden size 为 1408,intermediate size 为 6144,attention heads 为 16。每一层都包含视觉 experts 和 语言 experts,视觉-语言 experts 也被集成在前三个多路 transformer 层,而自注意模块在不同的模态中是共享的。BEiT-3 总共包含 1.9 亿个参数,其中视觉 experts 参数 692M,语言 experts 参数 692M,视觉-语言 experts 参数 52M,共享的自注意模块参数 317M。需要注意的是,当模型用作视觉编码器时,只有与视觉相关的参数会被激活。
Pretraining Data
BEiT-3 使用了如下表所示的单模态和多模态数据集进行了预训练。
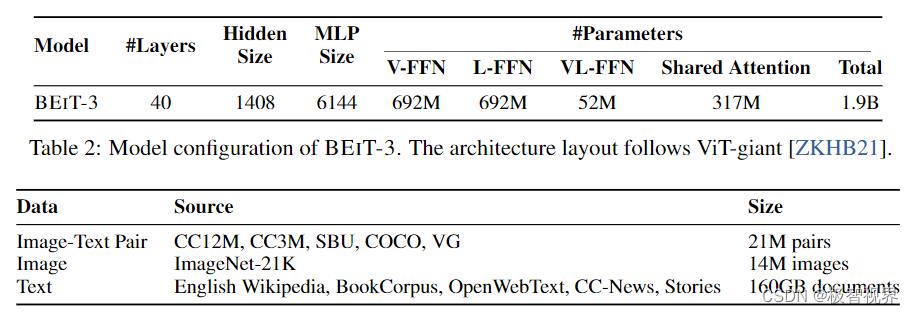
对于多模态数据,从五个公共数据集中收集了大约 15M 的图像和 21M 的图像-文本对,这五个数据集是:Conceptual 12M (CC12M)、Conceptual Captions (CC3M)、SBUCaptions (SBU)、COCO and Visual Genome (VG)。对于单模态数据,使用来自 ImageNet-21K 的 14M 的图像,和来自 EnglishWikipedia、BookCorpus、OpenWebText3、CC-News、Stories的 160GB 的文本语料库。
Pretraining Settings
预训练 BEiT-3 总共有 1M steps,每批次包含 6144 个样本,其中图像 2048个,文本 2048个,图像-文本对 2048个。batchsize 比 对比模型要小很多,BEiT-3 使用 14x14 的 patch size,输入图片分辨率为 224x224。使用与 BEiT 相同的图像增强策略,包括随机调整大小的裁剪、水平翻转和颜色抖动。使用一个 64K 词汇量的 SentencePiece tokenizer 对文本数据进行标记。使用 AdamW 优化器,参数设置为 β1=0.9、β2=0.98、ε=1e-6 进行优化。使用余弦学习速率衰减调度器,峰值学习率为 1e-3,线性预热为 10K steps。权重衰减为 0.05,随机深度率为 0.1。另外,使用 BEiT 初始化来稳定 transformer 的训练。
3. 实验
3.1 视觉-语言下游任务
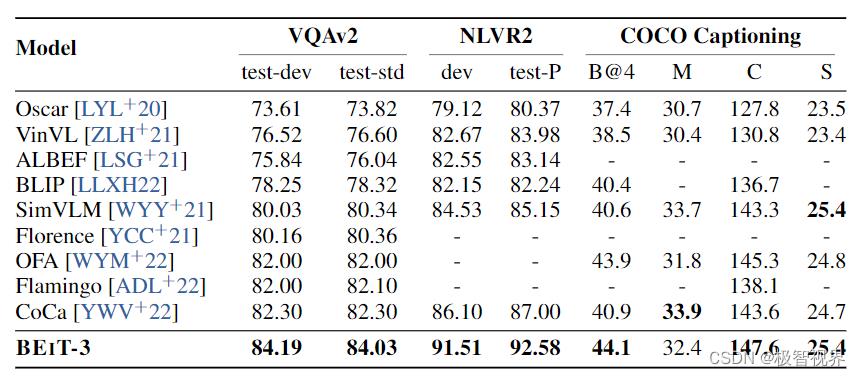
视觉问答、视觉推理、图像字幕生成任务结果:
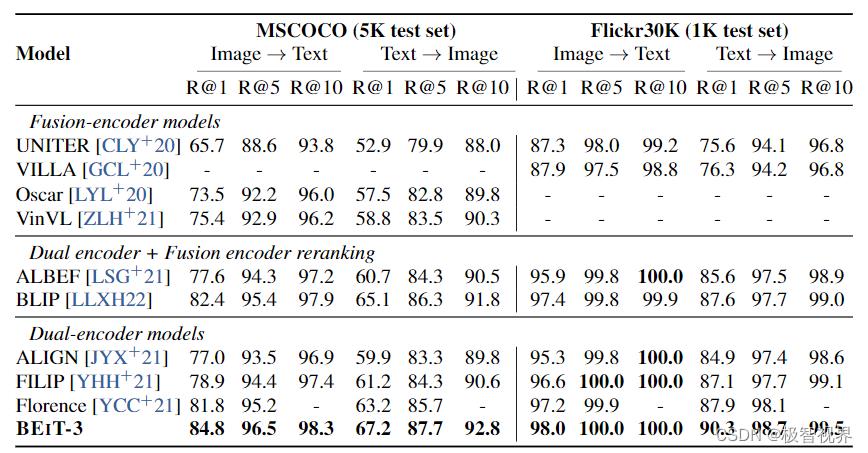
在 COCO和 Flickr30K 上对图像到文本检测和文本到图像检索的 finetune 结果:
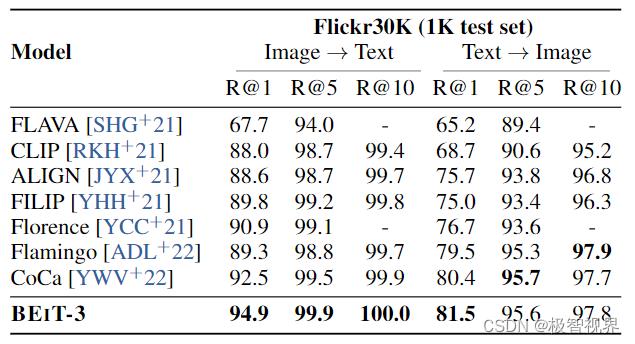
在 Flickr30K 上对图像到文本检索和文本到图像检索的 zero-shot 结果:
COCO benchmark 上的目标检测和实例分割结果:
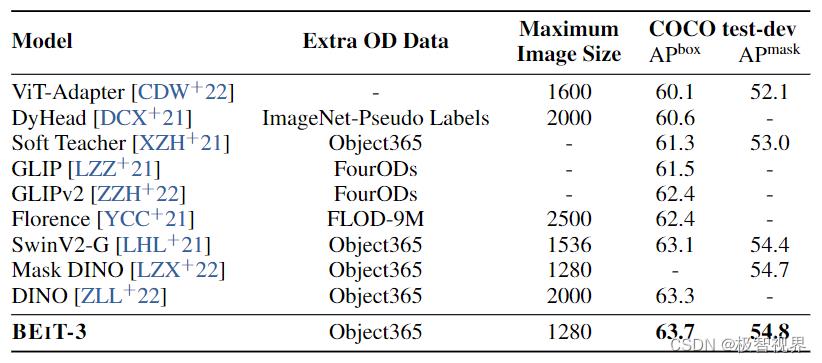
ADE20K 上的语义分割结果:
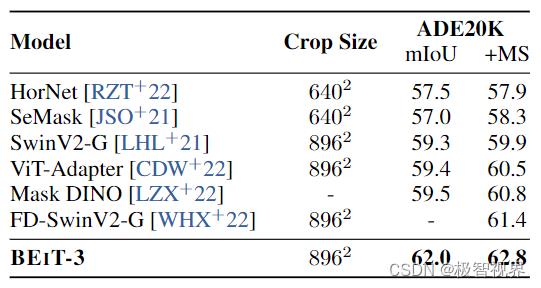
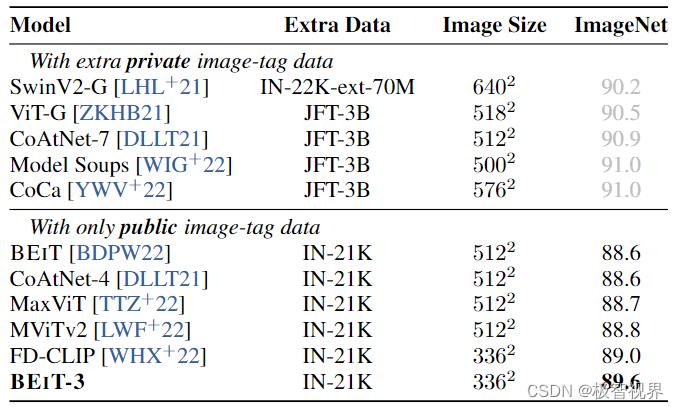
3.2 视觉下游任务
ImageNet-1K 上的 Top-1 精度:
4. 参考
[1]. Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks.
好了,以上解读了 性能数据炸裂的多模态模型 BEiT-3:Image as a Forign Language。希望我的分享能对你的学习有一点帮助。
【公众号传送】

搜索关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于极智Paper | 性能数据炸裂的多模态模型BEiT-3:Image as a Forign Language的主要内容,如果未能解决你的问题,请参考以下文章