Python ML实战-工业蒸汽量预测01-赛题理解
Posted Pushkin.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python ML实战-工业蒸汽量预测01-赛题理解相关的知识,希望对你有一定的参考价值。

文章目录
1. 赛题背景
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。

2. 赛题目标
经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
3. 数据说明
你可以在阿里云天池官网天池大赛中找到“工业蒸汽量预测”赛题,下载数据。

数据分成训练数据(train.txt)和测试数据(test.txt),其中字段 ”V0” - “V37”,这38个字段是作为特征变量,”target”作为目标变量。选手利用训练数据训练出模型,预测测试数据的目标变量,排名结果依据预测结果的MSE(mean square error)。
训练集预览:

4. 结果提交
选手需要提交测试数据的预测结果(txt格式,只有1列预测结果)。
5. 结果评估
预测结果以MSE (mean square error)作为评判标准。
计算公式如下:
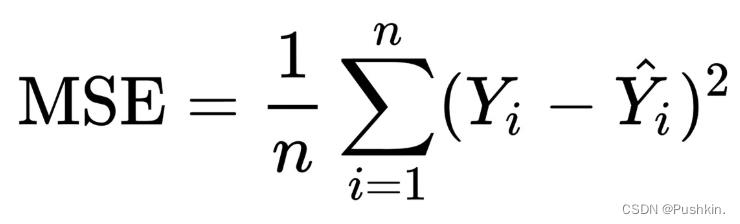
MSE是衡量“平均误差”的一种较为方便的方法。MSE值越小,说明预测模型描述实验数据具有越高的准确度。在sklearn中可以直接调用mean_squared_error()函数计算MSE,调用方法如下:
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, t_predict)
6. 赛题模型
在赛题分析中,很重要的一点就是根据赛题特点和明确问题的类型,并选择合适的模型。在机器学习中,根据问题类型的不同,常用的模型包括回归预测模型和分类预测模型。
6.1 回归预测模型
回归预测模型的预测结果是一个连续值域上的任意值,回归可以具有实值或离散的输入变量。我们通常把多个输入变量的回归问题称为多元回归问题,输入变量按时间排序的回归问题称为时间序列预测问题。
6.2 分类预测模型
分类预测模型的分类问题要求将实例分为两个或多个类中的一个,并具有实值或离散的输入变量。其中,两个类别的问题通常被称为二类分类问题或二元分类问题,多于两个类别的问题通常被称为多类别分类问题。
6.3 解题思路
在本赛题中,需要根据提供的V0-V37供38个特征变量来预测蒸汽量的数值,其预测值为连续型数值变量,故此问题为回归预测求解。
以上是关于Python ML实战-工业蒸汽量预测01-赛题理解的主要内容,如果未能解决你的问题,请参考以下文章