Spark优化-开启动态资源分配
Posted Pushkin.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark优化-开启动态资源分配相关的知识,希望对你有一定的参考价值。
文章目录
Spark-开启动态资源分配
1:为什么要开启动态资源分配
⽤户提交Spark应⽤到Yarn上时,可以通过spark-submit的num-executors参数显示地指定executor个数,随后, ApplicationMaster会为这些executor申请资源,每个executor作为⼀个Container在Yarn上运⾏。 Spark调度器会把Task按照合适的策略分配到executor上执⾏。所有任务执⾏完后,executor被杀死,应⽤结束。在job运⾏的过程中,⽆论executor是否领取到任务,都会⼀直占有着资源不释放。很显然,这在任务量⼩且显示指定⼤量executor的情况下会很容易造成资源浪费。
2 如何在cloudera(CDH)平台开启动态资源分配
第⼀步:确认spark-defaults.conf中添加了如下配置:
spark.shuffle.service.enabled true //启⽤External shuffle Service服务
spark.shuffle.service.port 7337 //Shuffle Service服务端⼝,必须和yarn-site中的⼀致
spark.dynamicAllocation.enabled true //开启动态资源分配
spark.dynamicAllocation.minExecutors 1 //每个Application最⼩分配的executor数
spark.dynamicAllocation.maxExecutors 30 //每个Application最⼤并发分配的executor数
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
第⼆步:进⼊yarn的配置⻚⾯,然后搜索yarn-site.xml
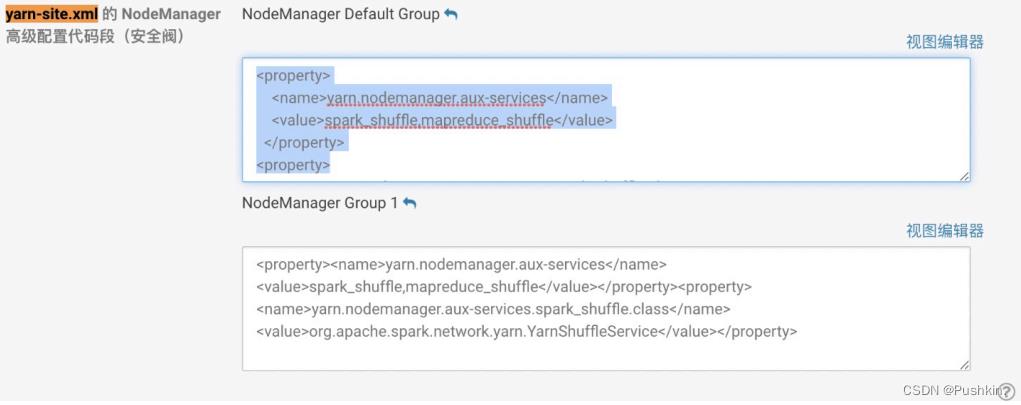
第三步:找到yarn-site.xml 的 NodeManager ⾼级配置代码段(安全阀)
然后添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>spark_shuffle,mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
第四步:重启yarn
3. 动态资源分配的原理
3.1 Executor⽣命周期
⾸先,先简单分析下Spark静态资源分配中Executor的⽣命周期,以spark-shell中的wordcount为例,执⾏命令如下:
# 以yarn模式执⾏,并指定executor个数为1
$ spark-shell --master=yarn --num-executors=1
spark-shell \\
--master yarn-client \\
--executor-memory 1G \\
--num-executors 10
# 提交Job1 wordcount
scala> sc.textFile("file:///etc/hosts").flatMap(line => line.split("
")).map(word => (word,1)).reduceByKey(_ + _).count()
# 提交Job2 wordcount
scala> sc.textFile("file:///etc/profile").flatMap(line => line.split("
")).map(word => (word,1)).reduceByKey(_ + _).count()
# Ctrl+C Kill JVM
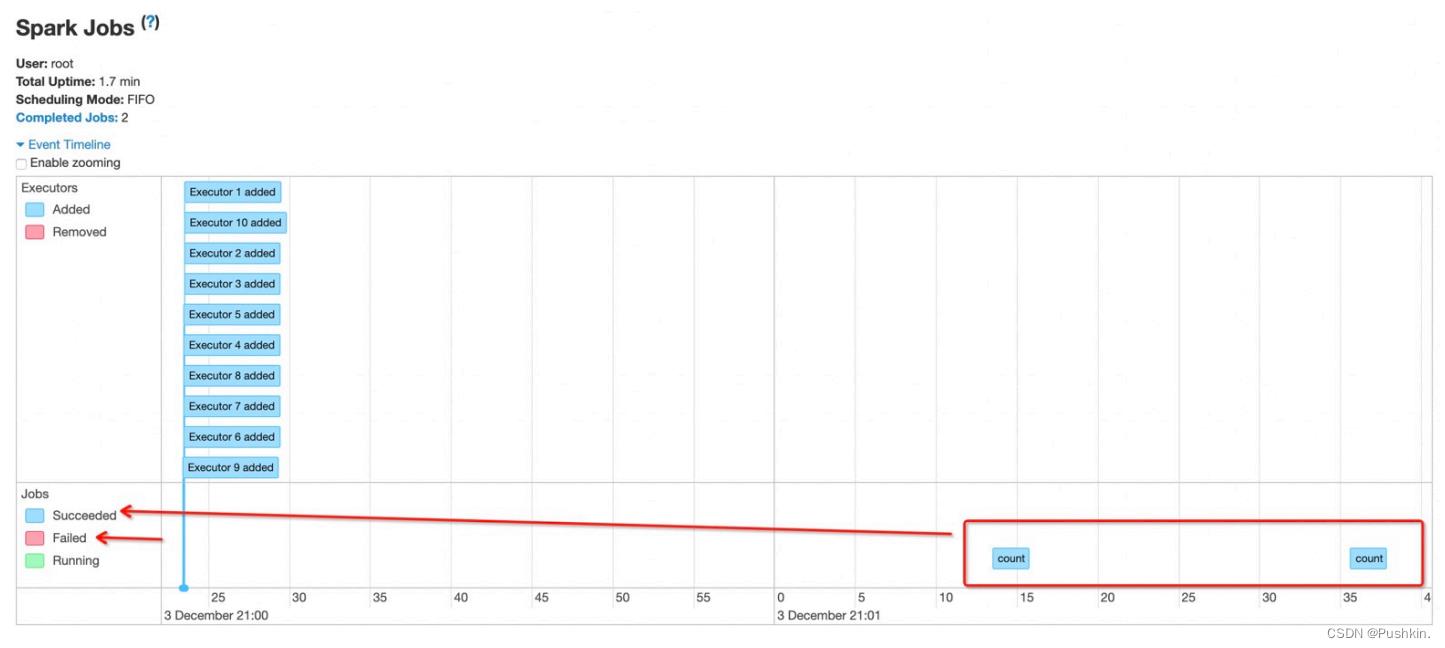
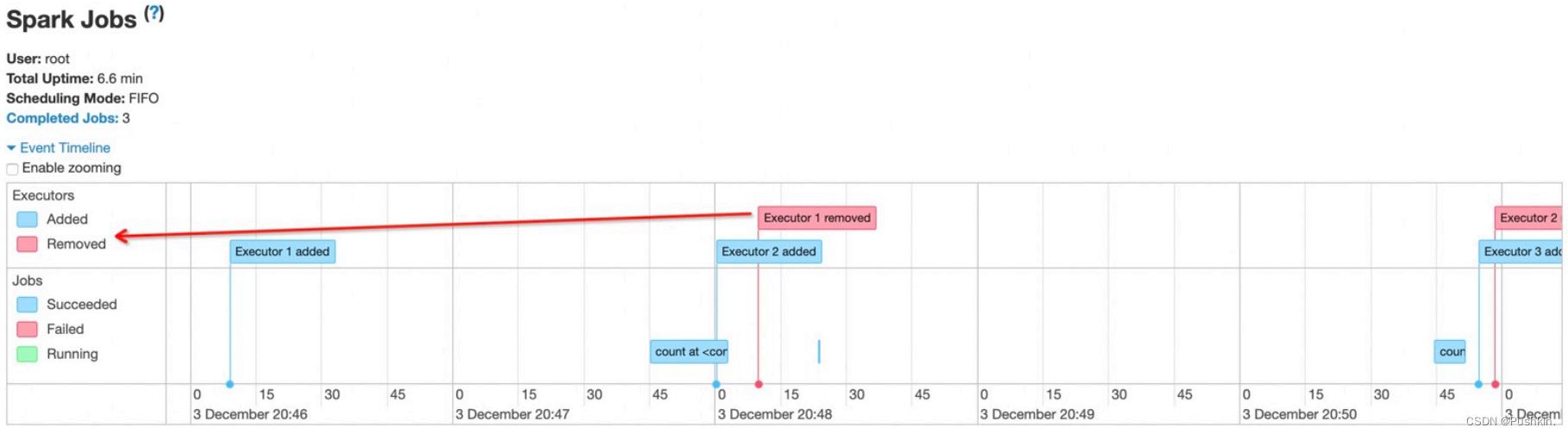
上述的Spark应⽤中,以yarn模式启动spark-shell,并顺序执⾏两次wordcount,最后Ctrl+C退出spark-shell。此例中Executor的⽣命周期如下图:
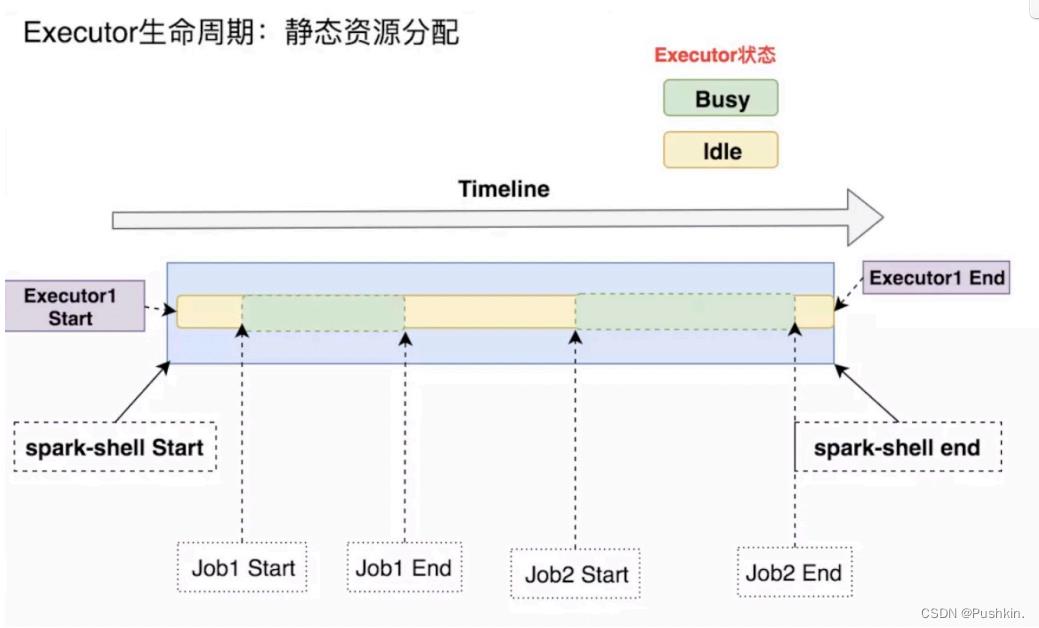
从上图可以看出, Executor在整个应⽤执⾏过程中,其状态⼀直处于Busy(执⾏Task)或Idle(空等)。处于Idle状态的Executor造成资源浪费这个问题已经在上⾯提到。下⾯重点看下开启Spark动态资源分配功能,Executor如何运作。
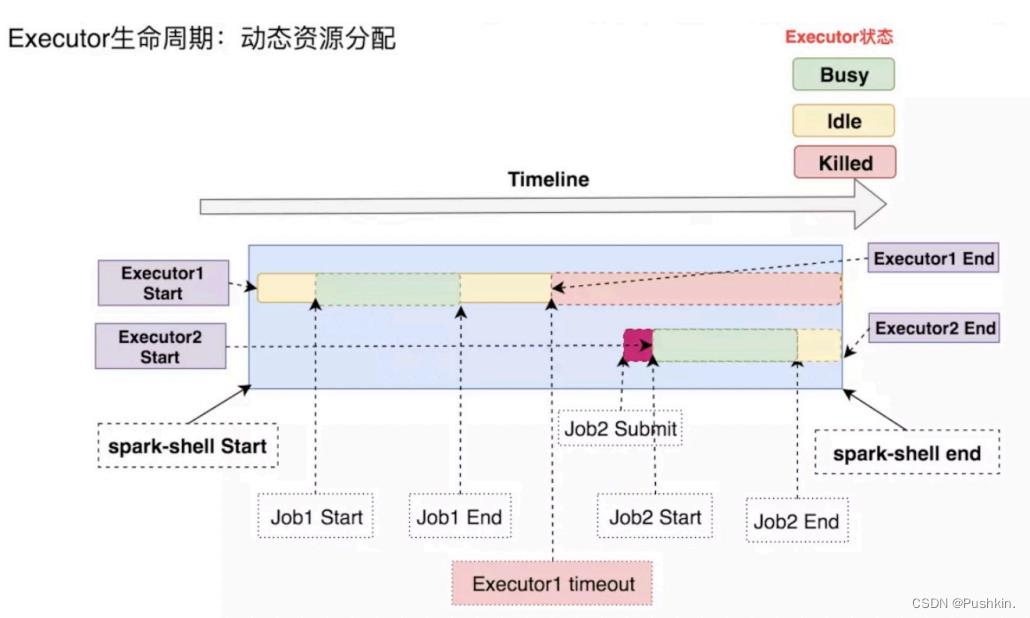
下⾯分析下上图中各个步骤:
spark-shell Start:启动spark-shell应⽤,并通过--num-executor指定了1个执⾏器。
Executor1 Start:启动执⾏器Executor1。注意: Executor启动前存在⼀个AM向
ResourceManager申请资源的过程,所以启动时机略微滞后与Driver。
Job1 Start:提交第⼀个wordcount作业,此时, Executor1处于Busy状态。
Job1 End:作业1结束, Executor1⼜处于Idle状态。
Executor1 timeout: Executor1空闲⼀段时间后,超时被Kill。
Job2 Submit:提交第⼆个wordcount,此时,没有Active的Executor可⽤。 Job2处于Pending状态。
Executor2 Start:检测到有Pending的任务,此时Spark会启动Executor2。
Job2 Start:此时,已经有Active的执⾏器, Job2会被分配到Executor2上执⾏。
Job2 End: Job2结束。
Executor2 End: Ctrl+C 杀死Driver, Executor2也会被RM杀死。

以上是关于Spark优化-开启动态资源分配的主要内容,如果未能解决你的问题,请参考以下文章