图像分类竞赛涨分小技巧——以智能硬件语音控制的时频图分类挑战赛为例
Posted 卡卡南安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像分类竞赛涨分小技巧——以智能硬件语音控制的时频图分类挑战赛为例相关的知识,希望对你有一定的参考价值。
图像分类竞赛涨分小技巧
一. 前言
在阅读这篇文章之前,请先阅读:图像分类竞赛baseline——以智能硬件语音控制的时频图分类挑战赛为例。这篇文章介绍了赛事背景和数据集格式,提供了基于飞桨实现的Baseline,本文的所有操作都是在Baseline的基础上进行,下面这些提分的小技巧我只会贴出关键性的程序,具体在训练中的实现需要大家自己摸索。
目前我的分数为0.94203,排名长期赛的第六位。

二. 上分小技巧
2.1 数据分割
在baseline中,我们将原始数据打乱后,取最后两百条数据作为验证集。由于原始数据中每一类样本的数量基本一致,这种方法会导致训练集中各个种类的样本差异较大,导致模型“偏科”;同时验证集中各个种类的样本差异也较大,导致验证loss和acc无法正确反映模型性能。因此我们需要从原始数据中取相同数量的样本作为验证集。
#每一类抽取十张作为验证集
val_df = pd.DataFrame()
for i in range(24):
val_df = val_df.append(train_df[train_df['label']==i][-10:])
train_df = train_df.drop(labels=train_df[train_df['label']==i][-10:].index)
val_df = val_df.reset_index(drop=True)
train_df = train_df.reset_index(drop=True)
2.2 数据增强
在原始数据不足时,数据增强是一种提高数据多样性的一种非常有效的方式,在本次竞赛中我主要在这方面下了功夫。
paddle.vision.tranforms中提供了很多常见的数据增强方式,包括随即裁剪、随机翻转、随机旋转、归一化等,使用方法也很简单,直接调用API即可。但是除此以外,还有许多非常好用的数据增强方式没有提供API,这里我提供了我使用到的三种有效的数据增强方法:随机擦除、混类增强和裁剪混合。
2.2.1 随机擦除(Random Erase)
训练中,随机选择图像的矩形区域,并使用随机值擦除其像素。生成具有遮挡级别的训练图像,会降低过拟合风险并使得模型对遮挡具有一定的鲁棒性。
# 随机擦除
def random_erase(img,n_holes,length,rate): #输入img为PIL图片格式的图片
if np.random.rand(1)[0]<rate:
img = np.array(img)
h = img.shape[0] #图片的高
w = img.shape[1] #图片的宽
n_holes = np.random.randint(n_holes)
mask = np.ones((h, w), np.float32) #32*32w*h的全1矩阵
for n in range(n_holes): #n_holes=2,length=4 选择2个区域;每个区域的边长为4
y = np.random.randint(h) #0~31随机选择一个数 y=4
x = np.random.randint(w) #0~31随机选择一个数 x=24
y1 = np.clip(y - length // 2, 0, h) #2,0,32 ->2
y2 = np.clip(y + length // 2, 0, h) #6,0,32 ->6
x1 = np.clip(x - length // 2, 0, w) #24-2,0,32 ->22
x2 = np.clip(x + length // 2, 0, w) #24+2,0,32 ->26
mask[y1: y2, x1: x2] = 0. #将这一小块区域去除
img[:,:,0] = img[:,:,0] * mask
img[:,:,1] = img[:,:,1] * mask
img[:,:,2] = img[:,:,2] * mask
return Image.fromarray(img)
else:
return img
输入参数:
- img:PIL格式的图片;
- n_holes:正方形的最大数量,即数量为0到n_holes中随机值;
- length:正方形边长;
- rate:随机擦除的概率;
输出参数:
- 随机擦除后PIL格式的图片
下面用一张图片展示一下效果:
img = Image.open(train_df['path'].values[0]).convert('RGB')
img2 = random_erase(img,100,10,0.2)

2.2.2 混类增强(Mixup)

将两个样本的图片和标签按照比例混合,扩展了样本分布,让训练出的模型具有更强的健壮性。
def random_mixup(img ,label, mixup_img, mixup_label):#输入img和mixup为IMG格式的图片,label和mixup_label为int类型
img = np.array(img)
mixup_img = np.array(mixup_img)
label_onehot = np.zeros(24)
label_onehot[label] = 1
mixup_label_onehot = np.zeros(24)
mixup_label_onehot[mixup_label] = 1
alpha = 1
lam = np.random.beta(alpha,alpha) #混合比例
img_new = lam*img + (1-lam)*mixup_img
label_new = lam*label_onehot + (1-lam)*mixup_label_onehot
return Image.fromarray(np.uint8(img_new)), paddle.to_tensor(np.float32(label_new))
输入参数:
- img & mixup_img:待混合的两张PIL格式的图片;
- label & mixup_label:两张图片对应的标签,为int格式
输出参数:
- 混合后PIL格式的图片
- 混合后Tensor型的标签,为one_hot编码
下面用两张图片展示一下效果:
img1 = Image.open(train_df['path'].values[0]).convert('RGB')
label1 = train_df['label'].values[0]
img2 = Image.open(train_df['path'].values[1]).convert('RGB')
label2 = train_df['label'].values[1]
img_new, label_new = random_mixup(img1, label1, img2, label2)
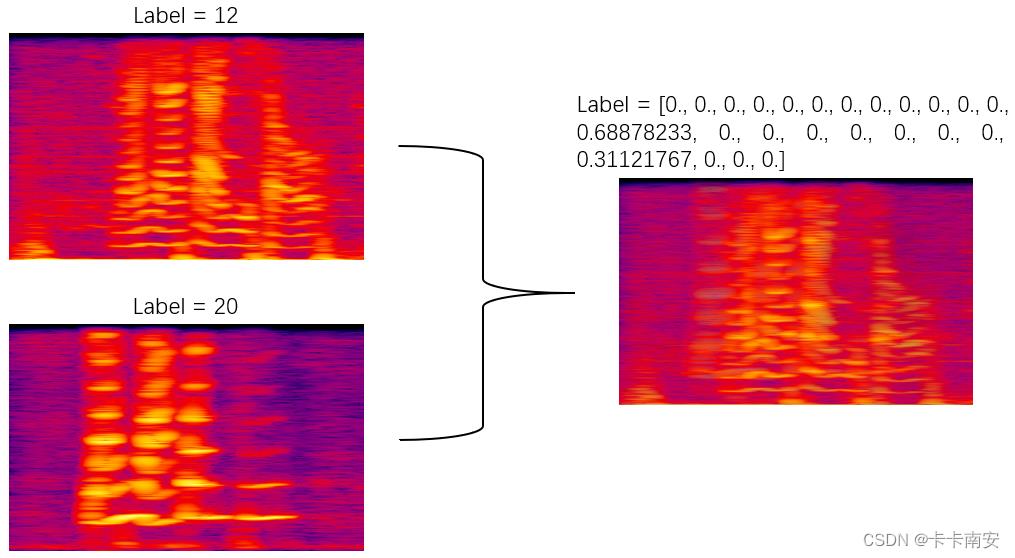
⭐需要注意的是,要使用mixup则数据标签必须为one_hot编码,同时损失函数需要设置为criterion = nn.CrossEntropyLoss(soft_label=True),表示使用one_hot编码。
2.2.3 裁剪混合(Cutmix)

将一张图的某一部分进行裁剪叠加到另一张图上面作为新的输入图片放入网络中进行训练,标签按照两类元素占图片的面积比加权求和。
def rand_bbox(size, lam):
if len(size) == 4:
W = size[2]
H = size[3]
elif len(size) == 3 or len(size) == 2:
W = size[0]
H = size[1]
else:
raise Exception
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
def cutmix(img ,label, cutmix_img, cutmix_label):
#int转化为one_hot
label_onehot = np.zeros(24)
label_onehot[label] = 1
cutmix_label_onehot = np.zeros(24)
cutmix_label_onehot[cutmix_label] = 1
alpha = 1
lam = np.random.beta(alpha,alpha)
bbx1, bby1, bbx2, bby2 = rand_bbox(img.size, lam)
img_new = img.copy()
img_new.paste(cutmix_img.crop((bbx1, bby1, bbx2, bby2)),(bbx1, bby1, bbx2, bby2))
# 计算 1 - bbox占整张图像面积的比例
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (img_new.size[0] * img_new.size[1]))
label_new = lam*label_onehot + (1-lam)*cutmix_label_onehot
return img_new,paddle.to_tensor(np.float32(label_new))
输入参数:
- img & cutmix_img:待混合的两张PIL格式的图片;
- label & cutmix_label:两张图片对应的标签,为int格式
输出参数:
- 混合后PIL格式的图片
- 混合后Tensor型的标签,为one_hot编码
下面用两张图片展示一下效果:
img1 = Image.open(train_df['path'].values[0]).convert('RGB')
label1 = train_df['label'].values[0]
img2 = Image.open(train_df['path'].values[1]).convert('RGB')
label2 = train_df['label'].values[1]
img_new, label_new = cutmix(img1, label1, img2, label2)

2.2.4 归一化(Normalize)
归一化的作用就是将需要处理的数据,经过一定的处理方法,将其数值限制在一定范围内。在深度学习图像处理中,归一化处理之后,可以使数据更好的响应激活函数,提高数据的表现力,减少梯度爆炸和梯度消失的出现。常见的归一化处理是将数据处理为均值是0,方差是1的高斯分布,而paddle.vision.transforms.Normalize()就可以实现这样的功能。
当图片经过paddle.vision.transforms.ToTensor()后,图片被转化为Tensor格式,转换之后shape为(CxHxW),数值范围在[0,1]。由于不同数据的平均值和标准差都不相同,因此我们需要计算整个数据集上三个通道的平均值和标准差。
#获取所有图片三通道的均值和方差
all_df = train_df.append(test_df,ignore_index=True).append(val_df, ignore_index=True)
all_dataset = XunFeiDataset(all_df['path'].values, all_df['label'].values,
transforms.Compose([
transforms.RandomCrop((450,750)),
transforms.ToTensor()
]),mode='test')
def getStat(train_data):
'''
Compute mean and variance for training data
:param train_data: 自定义类Dataset(或ImageFolder即可)
:return: (mean, std)
'''
print('Compute mean and variance for training data.')
print(len(train_data))
train_loader = DataLoader(
train_data, batch_size=1, shuffle=False, num_workers=0)
mean = np.zeros(3)
std = np.zeros(3)
for X, _ in train_loader:
for d in range(3):
mean[d] += X[:, d, :, :].mean().cpu().numpy()[0]
std[d] += X[:, d, :, :].std().cpu().numpy()[0]
mean = mean/len(train_data)
std = std/len(train_data)
return list(mean), list(std)
print(getStat(all_dataset))
运行后输出为:
Compute mean and variance for training data.
3163
([0.6766141943829066, 0.06216619949979672, 0.2686088090203644], [0.24656723146663978, 0.14537001843179825, 0.17407946023116036])
将计算得到的数据填入Normalize的参数即可:
Normalize((0.677, 0.062, 0.268), (0.246, 0.145, 0.174))
2.2.5 标签平滑(Label Smooth)
标签平滑作为一种简单的正则化技巧,它能提高分类任务中模型的泛化性能和准确率,缓解数据分布不平衡的问题,经过标签平滑后的one_label不再只有0和1,变成可以理解为该类的概率的形式。标签平滑可以降低模型的可信度,并防止模型下降到过拟合所出现的损失的深度裂缝里。
Paddle提供了Label Smooth的API。
label_onehot = paddle.to_tensor(np.float32([0,0,1,0]))
nn.functional.label_smooth(label_onehot)
输出为:
Tensor(shape=[4], dtype=float32, place=Place(cpu), stop_gradient=True,
[0.02500000, 0.02500000, 0.92499995, 0.02500000])
2.2.6 修改后的Dataset
在添加了这些数据增强的方法后,我们的Dataset也要进行一些修改:
# 定义数据集读取方法
class XunFeiDataset(Dataset):
def __init__(self, img_path, label, transforms=None, mode='train'):
self.img_path = img_path
self.label = label
self.transforms = transforms
self.mode = mode
def __getitem__(self, index):
img = Image.open(self.img_path[index]).convert('RGB')
#将label转化为one_hot编码
label_onehot = np.zeros(24)
label_onehot[self.label[index]] = 1
label_onehot = paddle.to_tensor(np.float32(label_onehot))
if self.mode == 'train': #训练时才做数据增强
#随机擦除 100代表100个正方形,10代表每个正方形边长为10,0.2代表20%的概率
img = random_erase(img,100,10,0.2)
#mixup,0.2的概率
if np.random.rand(1)[0]<0.2:
mixup_idx = np.random.randint(0, len(self.img_path)-1)
mixup_img = Image.open(self.img_path[mixup_idx]).convert('RGB')
mixup_label = self.label[mixup_idx]
img, label_onehot = random_mixup(img, self.label[index], mixup_img, mixup_label)
#cutmix,0.2的概率
if np.random.rand(1)[0]<0.2:
cutmix_idx = np.random.randint(0, len(self.img_path)-1)
cutmix_img = Image.open(self.img_path[cutmix_idx]).convert('RGB')
cutmix_label = self.label[cutmix_idx]
img, label_onehot = cutmix(img, self.label[index], cutmix_img, cutmix_label)
if self.transforms is not None:
img = self.transforms(img)
label_onehot = nn.functional.label_smooth(label_onehot)
return img, label_onehot
def __len__(self):
return len(self.img_path)
2.3 学习率和优化函数
采用学习率衰减的方法能够有效地提高模型精度,同时优化函数采用AdamW。
Adamw 即 Adam + weight decate,效果与 Adam + L2正则化相同,但是计算效率更高,因为L2正则化需要在loss中加入正则项,之后再算梯度,最后在反向传播,而Adamw直接将正则项的梯度加入反向传播的公式中,省去了手动在loss中加正则项这一步。
scheduler = paddle.optimizer.lr.StepDecay(0.0001,15,gamma=0.1,verbose=False)
optimizer = paddle.optimizer.AdamW(learning_rate=scheduler, parameters=model.parameters())
关于更多学习率衰减的方法请查看:Pytorch中的学习率调整方法,里面的API飞桨也基本都有。
2.4 训练方式
经过检验,五折交叉验证的方式能够大大提高预测精度,具体实现请参考Baseline,在预测测试集时,我们可以用在验证集上表现最好的参数来预测得到每一折的结果。
for i in range(k_fold):
······
for epoch in range(epoches):
······
if val_acc>max_acc:
test_pred = predict(test_loader, model, criterion)
max_acc = val_acc
三. 我的上分之路
| 数据预处理/特征工程 | 模型 | 分数 |
|---|---|---|
| Resize(256)、随机裁剪(224),归一化(baseline参数) | resnet18 | 0.80-0.86 |
| 随机裁剪(450,750),归一化(baseline参数) | resnet18 | 0.91126 |
| 随机裁剪(450,750),随机擦除、归一化(baseline参数) | resnet18 | 0.91533 |
| 重新分割验证集、随机裁剪(450,750),随机擦除、mixup、归一化(更新参数) | resnet34 | 0.92375 |
| 重新分割验证集、随机裁剪(450,750),随机擦除、mixup、归一化(更新参数) 、五折交叉验证 | resnet34 | 0.93375 |
| 重新分割验证集、随机裁剪(450,750),随机擦除、mixup、label_smooth、归一化(更新参数) 、五折交叉验证 | resnet34 | 0.93518 |
| 重新分割验证集、随机裁剪(450,750),随机擦除、mixup、cutmix、label_smooth、归一化(更新参数) | resnet34 | 0.93509 |
| 重新分割验证集、随机裁剪(450,750),随机擦除、mixup、cutmix、label_smooth、归一化(更新参数)、五折交叉验证 | resnet34 | 0.94203 |
四. 最后
这个比赛的上分之路应该就到此结束了,这次上分我主要是从数据特征工程等方面入手,并没有对模型进行太多的改动,大家可以考虑在此基础上对模型结构进行进一步优化,以期获得更高的分数。
以上是关于图像分类竞赛涨分小技巧——以智能硬件语音控制的时频图分类挑战赛为例的主要内容,如果未能解决你的问题,请参考以下文章