02 kafka 记录的获取
Posted 蓝风9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02 kafka 记录的获取相关的知识,希望对你有一定的参考价值。
前言
最近 会涉及到一些 kafka 相关的环境搭建, 然后 客户端 和 服务器 连接的过程中会出现一些问题
因而 会存在一些 需要了解 kafka 代码的一些需求
从而 衍生出 一些 知识点 的分析, 记录
kafka 的记录是如何获取的 这里就是其中之一
kafka 服务器基于 2.4.1, 客户端基于 2.2.0
测试用例
/**
* Test06KafkaProducer
*
* @author Jerry.X.He <970655147@qq.com>
* @version 1.0
* @date 2022-05-28 10:14
*/
public class Test06KafkaConsumer
// Test06KafkaProducer
public static void main(String[] args)
Properties props = new Properties();
// props.put("bootstrap.servers", "master:9092");
props.put("bootstrap.servers", "192.168.0.103:9092");
// props.put("bootstrap.servers", "127.0.0.1:9092");
props.put("group.id", "test2");
// props.put("enable.auto.commit", "true");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
String topic = "test20220528";
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
try
while (true)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100_000));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
finally
consumer.close();
客户端的处理
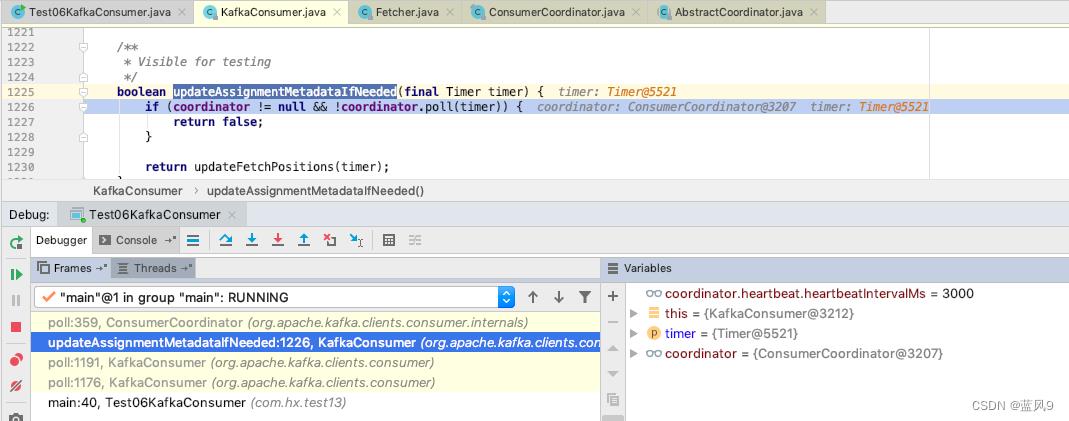
客户端的 poll 分为两个部分, updateAssignmentMetadataIfNeeded 这部分是表示可能存在更新消费偏移的场景
pollForFetches 是表示真实的尝试获取数据, 或者

updateAssignmentMetadataIfNeeded
updateAssignmentMetadataIfNeeded 的处理也是分为两个步骤, coordinator.poll 是做一些前置条件, 启动心跳线程, 发送 JoinGroupRequest, FindCoordinatorRequest, 自动提交偏移的处理 等等
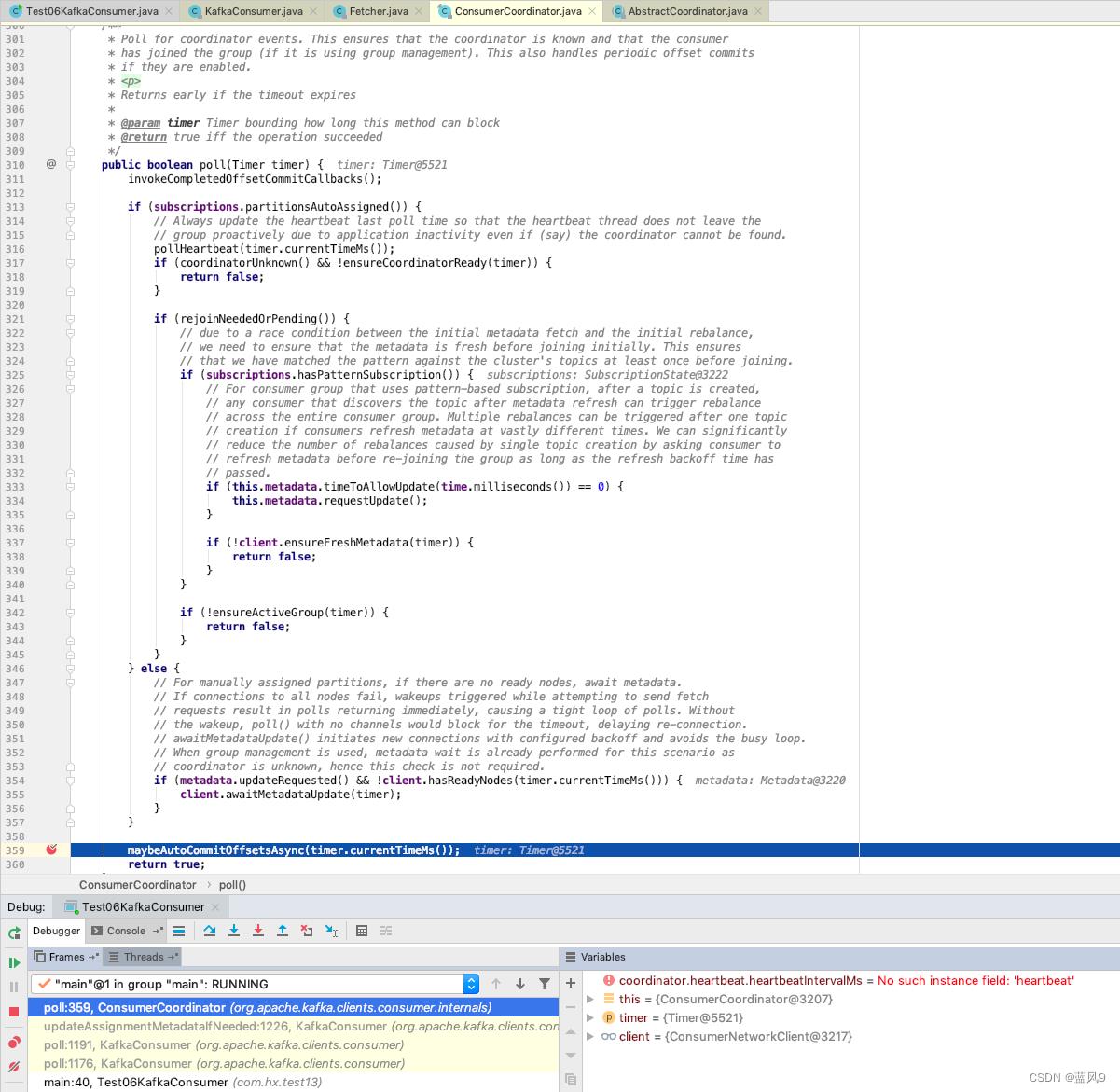
updateFetchPositions 中的处理是 根据 TopicParition + groupId 获取偏移, 然后来更新 当前消费的偏移, 或者 根据时间戳 + 偏移重置策略 来获取偏移, 然后来更新 当前消费的偏移
coordinator.poll 的处理
updateFetchPositions 的处理
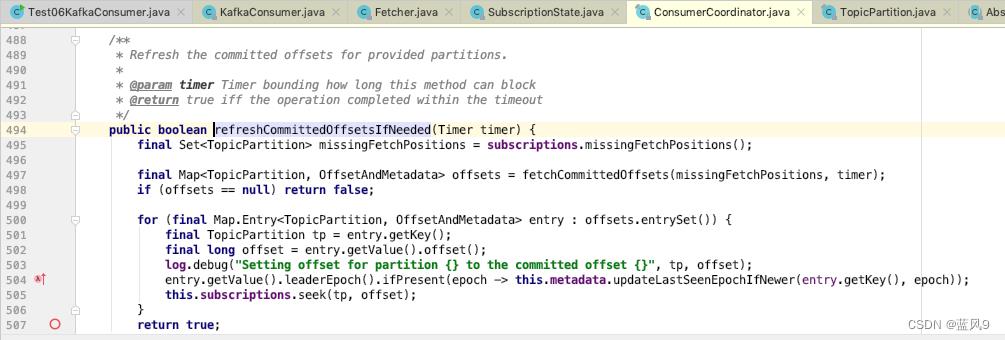
refreshCommittedOffsetsIfNeeded 的处理是根据 TopicParition + groupId 向服务端发送 OffsetFetchRequest, 然后拿到结果之后 更新客户端这边的给定的 TopicParition 的消费偏移
fetcher.resetOffsetsIfNeeded() 是根据用户配置的 TopicParition + 重置策略 来向服务端发送 ListOffsetRequest 请求, 然后 拿到结果之后 更新客户端这边的给定的 TopicParition 的消费偏移

refreshCommittedOffsetsIfNeeded
从 subscriptions 列表中获取等待获取 offset 的 parittion 的相关, 这个是 发送 OffsetFetchRequest 来获取服务端保存的给定的 topicPartiion, groupId 消费的偏移
拿到之后 基于 subscriptions 更新当前 groupId, topicPartition 的消费偏移, 注意这里的 seek 更新了 position 以及 resetStrategy
fetcher.resetOffsetsIfNeeded
这里获取当前需要获取偏移的 topicParition, 根据 resetStrategy 来重置偏移, 默认为 LATEST, 可以配置为 LATEST, EARLIEST, NONE
如果是上面从服务器的 offset 中获取了偏移, 之类就不会再处理偏移了, 如果没有从 offset 中获取偏移, 则根据 resetStrategy 更新当前 topicParition 的偏移

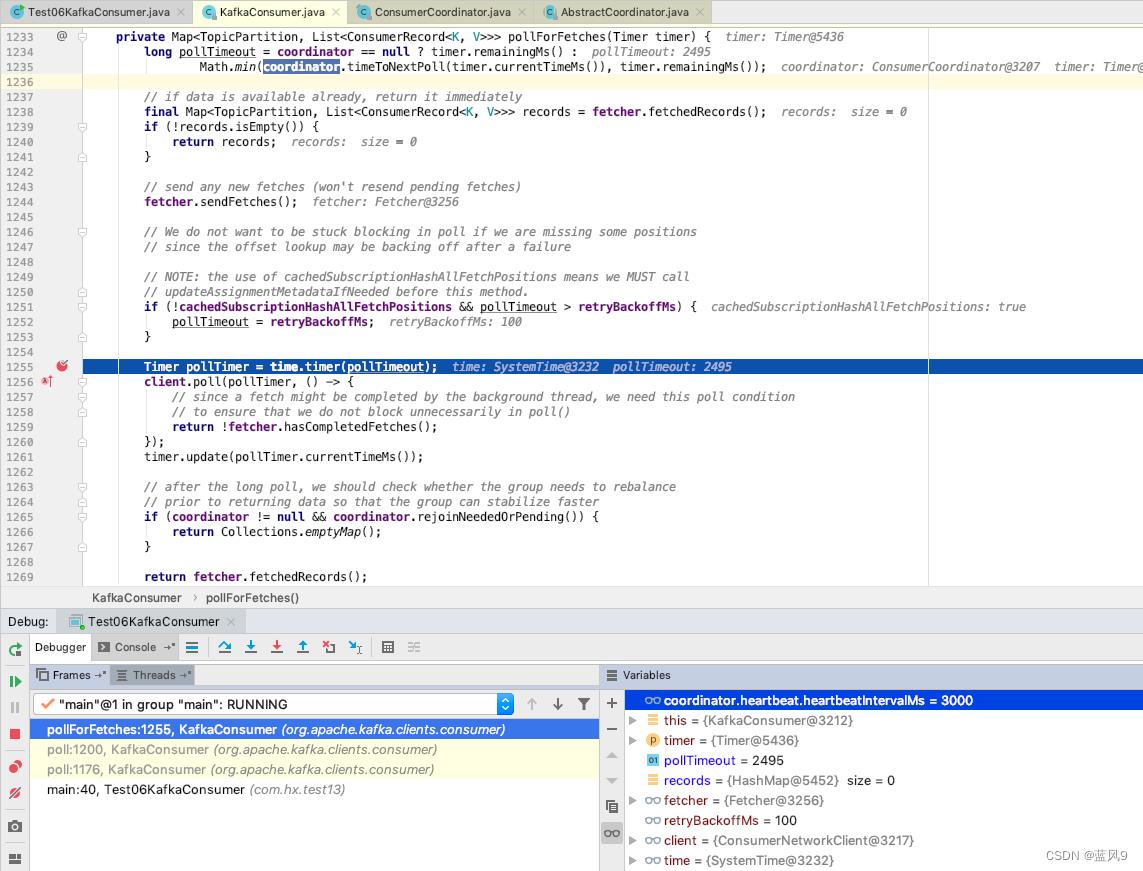
pollForFetches
pollForFetches 的处理是检查是否已有异步响应的结果, 如果有直接返回
否则 向服务端发送请求
然后 以心跳的时间周期为单位等待, 直到timer的超时, 获取 异步发送请求得到的结果, 如果没有, 响应空列表即可
客户端在不断的处理以上流程
在 fetcher.sendFetches 中判断当前的 TopicParition 的消费数据 和 上一次得到的消费数据是否一致, 如果一致 则移除给定的 TopicParition 的数据
发送仅仅包含 groupId 的 FetchRequest 给服务端
然后 服务器通过 session 获取关注的 topicParition 的相关的消费信息, 然后从服务器 poll 给定的 topicParition 的数据, 如果有新的数据 响应给客户端
服务端的处理
主要是针对如下 FetchRequest, FetchOffset, ListOffsetRequest 来说明
FetchRequest
从客户端传过来的 offset 开始向后消费
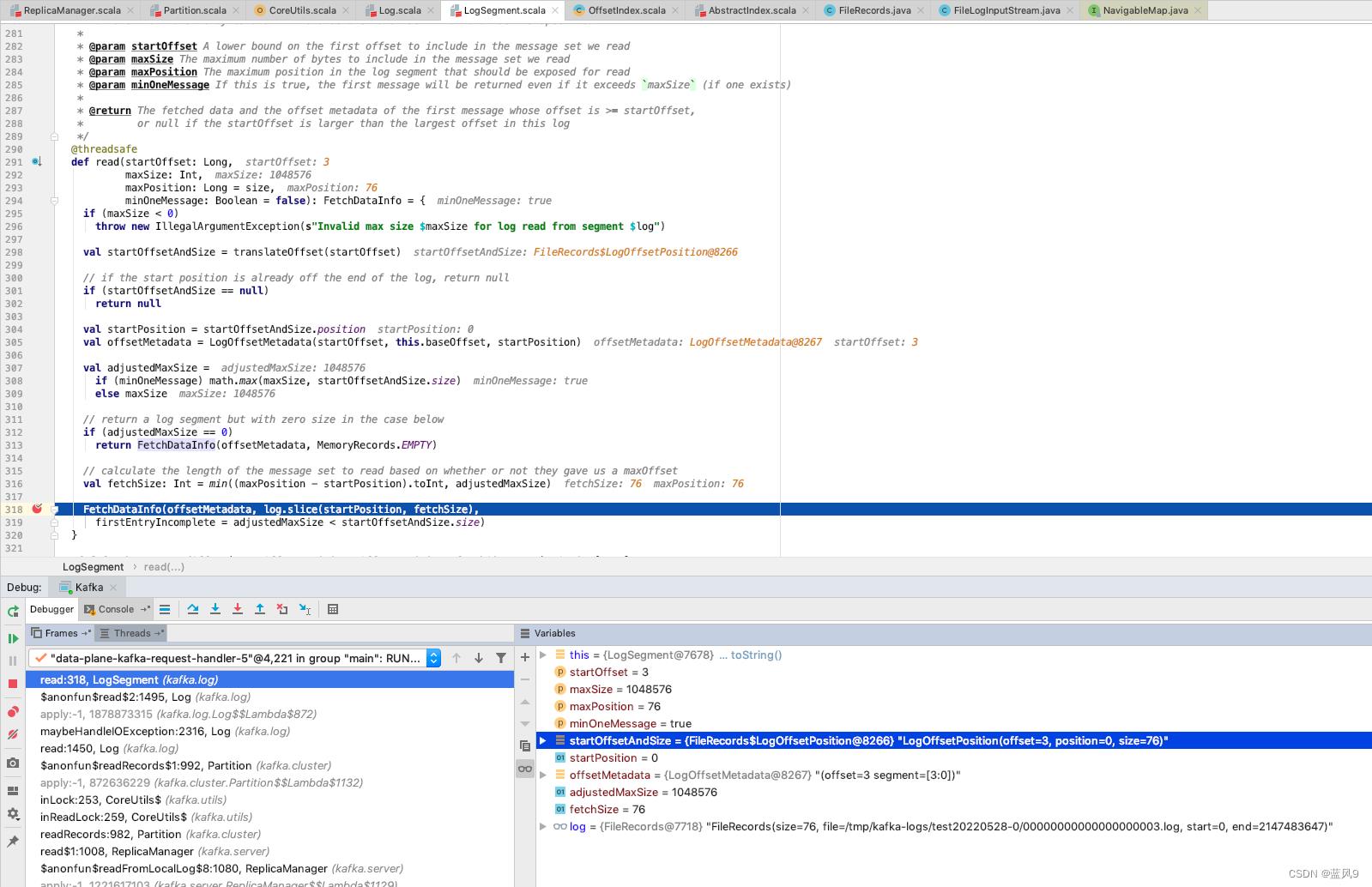
Log.read 外面这一层首先是根据 offset 获取所在的 segment, 每一个 segment 记录的有 baseOffset, 当前 segment 的第一个记录的 baseOffset[这里是基于 skiplist 查询]
然后 LogSegment.read 这里首先是查询 offset 对应的索引, 以及物理位置, 然后计算当前请求需要传输的数据大小 min((maxPosition - startPosition).toInt, adjustedMaxSize)
比如 我这里 从 offset 0 开始读取, adjustedMaxSize 为 1048576, log 文件总大小为 228, 因此当前批次传输给客户端的就是这三条记录 228 byte
master:Tmp jerry$ ll /tmp/kafka-logs/test20220528-0/
total 48
-rw-r--r-- 1 jerry wheel 0 Jun 11 16:02 00000000000000000000.index
-rw-r--r-- 1 jerry wheel 228 Jun 11 16:02 00000000000000000000.log
-rw-r--r-- 1 jerry wheel 24 Jun 11 16:02 00000000000000000000.timeindex
-rw-r--r-- 1 jerry wheel 10 Jun 11 15:57 00000000000000000002.snapshot
-rw-r--r-- 1 jerry wheel 10485760 Jun 11 16:02 00000000000000000003.index
-rw-r--r-- 1 jerry wheel 76 Jun 11 16:02 00000000000000000003.log
-rw-r--r-- 1 jerry wheel 10 Jun 11 16:02 00000000000000000003.snapshot
-rw-r--r-- 1 jerry wheel 10485756 Jun 11 16:02 00000000000000000003.timeindex
-rw-r--r-- 1 jerry wheel 8 Jun 11 15:57 leader-epoch-checkpoint
然后客户端的下一个 FetchRequest 带过来的 offset 是 3, 读取的是下一个 segment 里面的数据
FetchOffset
从 group 中维护的 offsets 中获取需要的 topicParition 的偏移的数据返回
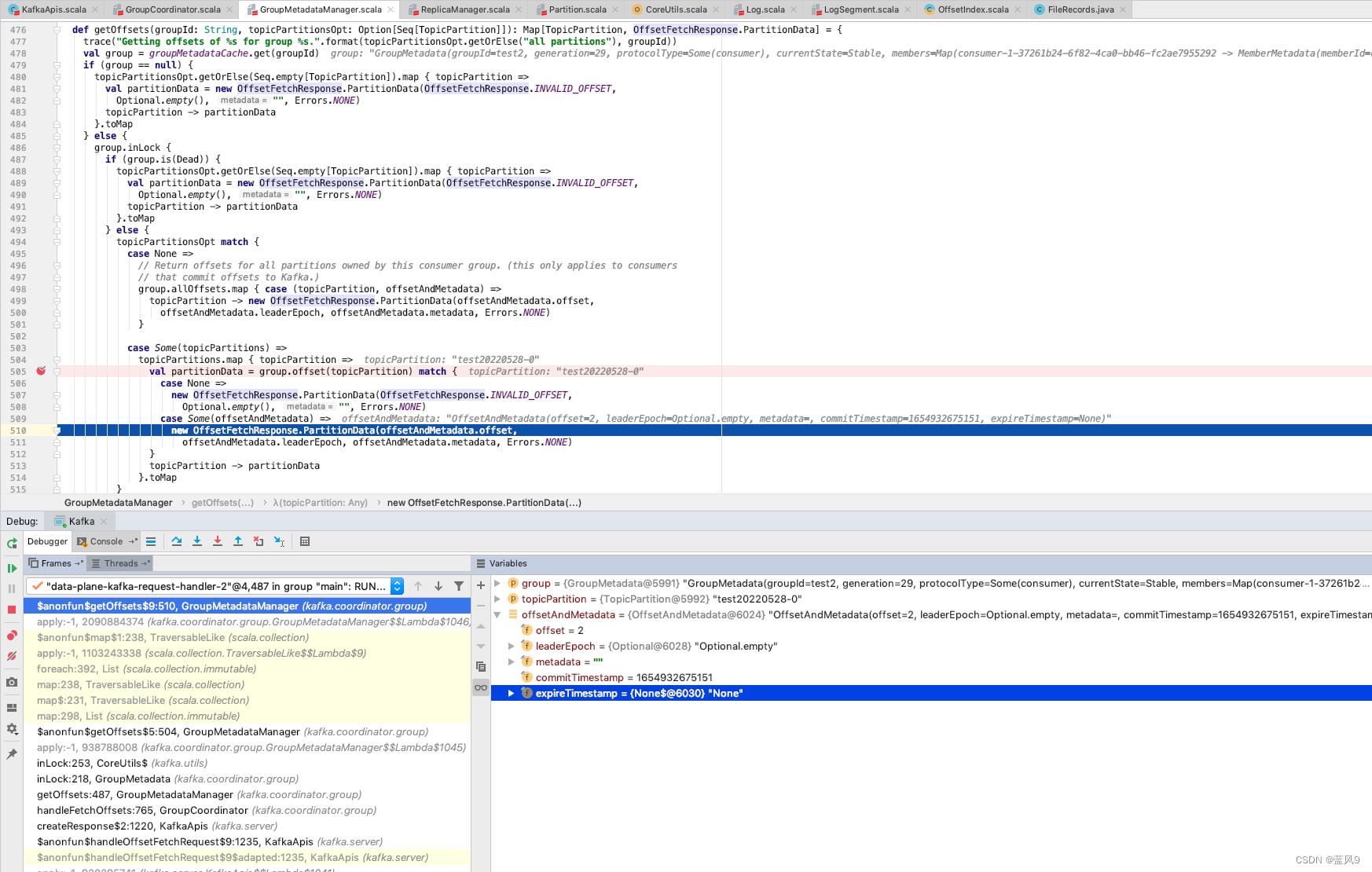
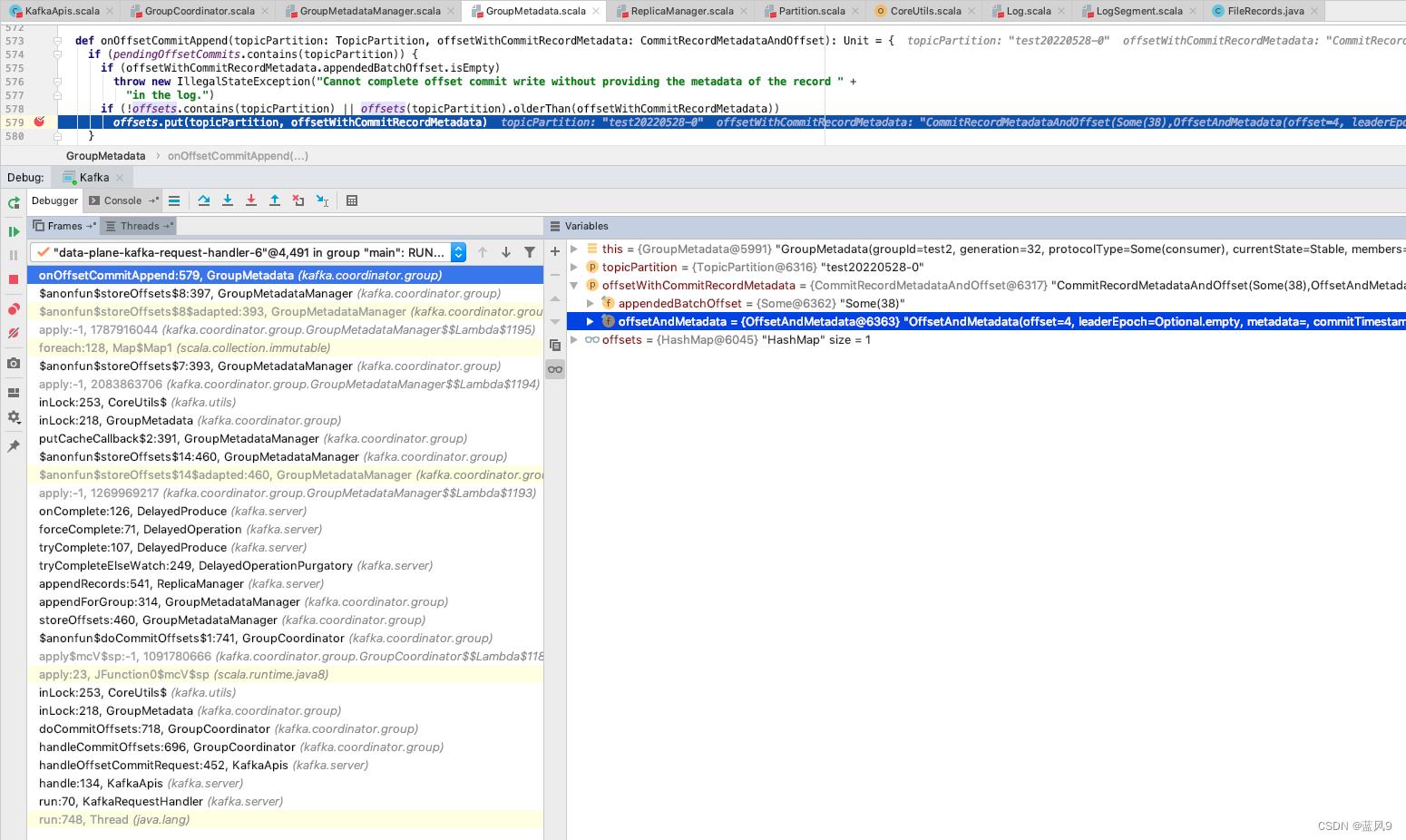
这个 group.offsets 的数据维护来自于
第一 kafka 初始化的时候从 _consume_offset 中加载 group 的偏移信息
第二 提交 CommitOffsetRequest 的时候, 需要注册 topicParition 的偏移信息
kafka 初始化的时候从 _consume_offset 中加载 group 的偏移信息
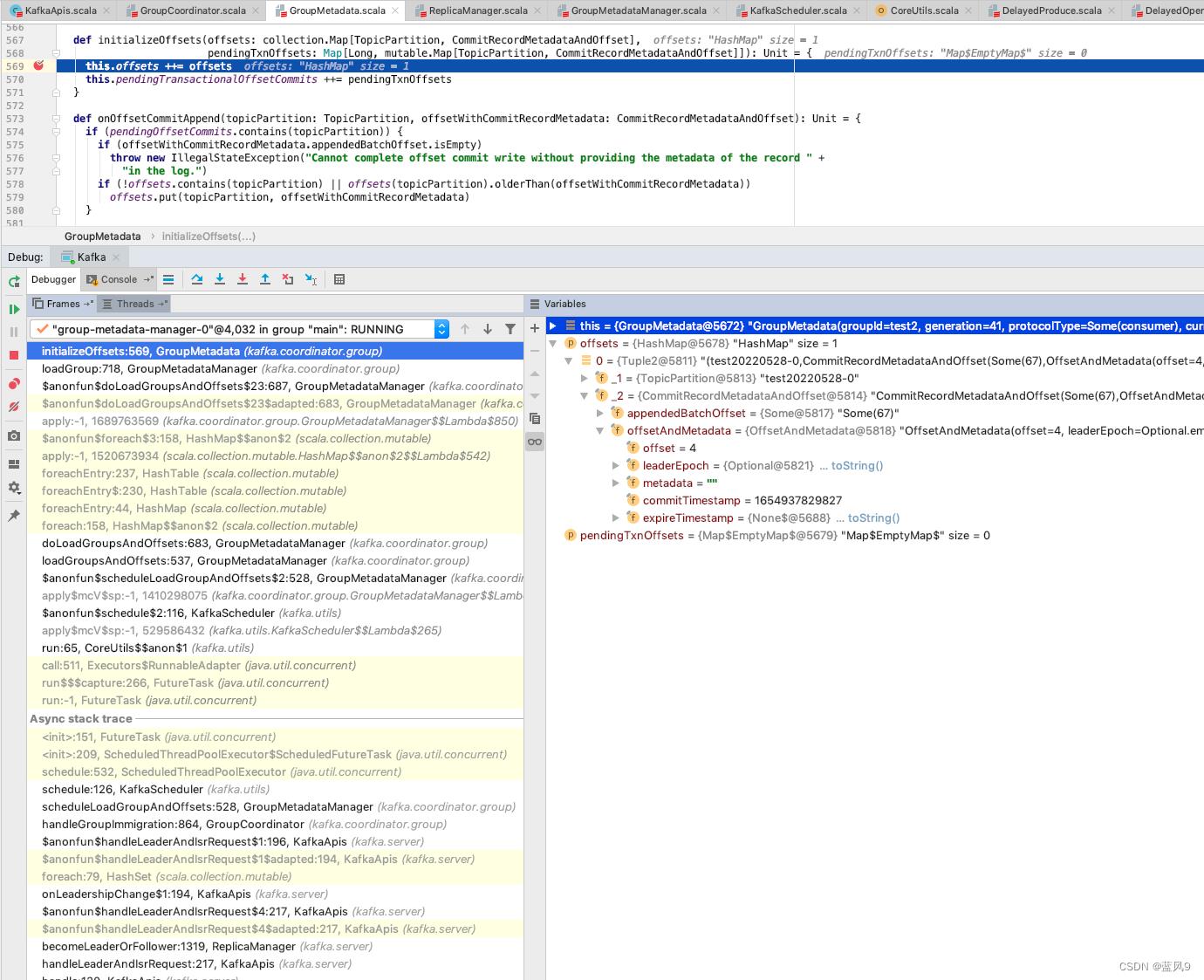
遍历 topicParition 列表, 加载 _consume_offset 相关

将 offset 持久化到 _consume_offset 中的地方在这里, 添加到 __consume_offset_38 中, 这个 38 是根据 groupId 的 hashCode 计算的一个标志
ListOffsetRequest
根据 重置策略/时间戳 获取 偏移, 如果是 EARLIEST, 直接返回 偏移0
如果是 LATEST, 根据 isolationLevel 获取 lastStableOffset/higherWatermak, 一般来说是最大记录的 offset + 1
否则根据 timestamp 找到日志文件中大于等于 timestamp 的的第一条记录的 偏移信息, 这里需要查询 timeindex 文件, 来检索时间戳

完
以上是关于02 kafka 记录的获取的主要内容,如果未能解决你的问题,请参考以下文章