这21条避坑指南,让你完美运行自动化
Posted TEST_二 黑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这21条避坑指南,让你完美运行自动化相关的知识,希望对你有一定的参考价值。
引言
在撸码过程中,99.1%的大佬,都不敢说自己的撸出来的代码,是不需要debug的。
换句话说,码农在撸码过程中,最痛苦的,莫过于撸出来的代码,又……
为了能避坑,我也是在撸码过程中,总结的一点避坑方法,请各位大佬笑纳。
无法定位到元素
遇到问题:找不到元素,脚本报“NoSuchElementException:Unable to find element”,或"定位到了,不能操作,点击无效。
解决方法:
-
查看自己的“属性值”是否写正确;
-
元素的标签不唯一,默认找到第一个;
-
向上查看,元素是否在frame或iframe框架中;
-
查看元素是否在新打开的页面中,需要切换到新窗口;
-
换其它的定位方式:id/name/class name/tag name/link text/xpath/css selector;
-
检查元素属性是否是会变动的、是否是隐藏的;
-
添加等待时间sleep(),implicitly_wait(),WebDriverWait(driver, 10, 1).until(定位的元素, messages);
-
查看标签的属性是否有“style=’display:none’->,元素不显示,属性改为block即可;
-
查看标签的属性是否有‘οnclick=return false’->,取消点击,属性改为false即可;
-
针对于后两种情况,修改js属性:

Indentation Error
遇到问题:出现 Indentation Error。
解决方法:脚本代码对齐。
PO设计模式类
1、使用PO设计模式封装页面元素类,需要有初始化函数"init"。
2、页面元素调用Page类时候,Page函数,后面括号的“self”不用写。
3、Page的初始化包含(self,driver)两个元素,在页面封装类中,初始化中调用方式为:

4、页面元素封装时候,定位方式一定要写对,否则报错,定位方式是实现WebUI自动化的基础。
5、在页面封装中,类的初始化使用如下样式:

6、类中定义变量,比如x=“hello”,调用时使用:self.x。
7、在testcase中调用已封装的并且实例化的类时,在testcase中定义函数,不需要写self。

页面封装类中没有已定义函数的问题
提示没有该方法
遇到问题:调用baseView.py文件的公共方法,提示没有该方法。
解决方法:
1、需要在baseView.py文件确认,是否已封装该方法。
2、导入的包/模块是否正确。
没有定义好的函数
遇到问题:提示在页面封装类中没有baseView.py文件中定义好的函数。
解决方法:
1、新建名字为module_baseView.pth文件,内容为“baseView.py文件”存放路径:例如(“E:\\Progect”)。
2、进入python的安装目录,将文件放到python3\\lib\\sit-packages文件夹下。
3、在测试用例中导入其他文件夹模块引入:import sys。
4、sys.path.append(“…”)。
5、from … import …。
parater must be str
遇到问题:出现”parater must be str“。
原因:使用参数有问题。
解决方法:
1、在封装页面元素定位方式时,经常会会遇到二次定位。
2、第一次定位调用基础类的方法,第二次定位就正常写就行了,例如:

继承
继承,使我们减少代码冗余及代码高效的常用方式。
子集继承父级(不是继承银子),老规矩,上例子:

打印输出时错误
遇到问题:打印输出时显示“not all arguments curerted during string format”。
原因:前后参数不对应。
解决方法:调整前后参数,使其一致。
读取文件转码错误
遇到问题:读取txt文件的汉字和字符时,打印出一串编码,如下:(b’\\xef\\xbb\\xbf\\xe5\\xa5\\xbd\\xe7\\x9a\\x84\\r\\n’)。
解决办法:

str object is not callable
遇到问题:出现"“str object is not callable”。
原因:使用定义的变量名字与内置模块名字相同。
解决办法:修改定义变量名。
无法定位到最后一个句柄
遇到问题:开启多窗口,第一次得到的句柄列表为a=[1,2],第二次得到的句柄列表是b=[1,3,2],按照顺序排序,要切换到句柄3。
解决方法:首先把a和b变成集合,再取b不同于a的元素:

然后再转换为列表赋值给变量c:

无法连接
遇到问题:提示 Can not connect to the Service chromedriver。
原因:chromedriver未被调用。
解决方法:
1、python根目录存放chromedriver。
2、hrome版本号与chromedriver版本号 要匹配。
3、chromedriver追加到环境变量(Path)。
4、运行脚本调用chromedriver。
5、Firewalls 允许chromedriver运行。
文件路径配置
读取数据文件,尽量使用参数化,即调用os模块:
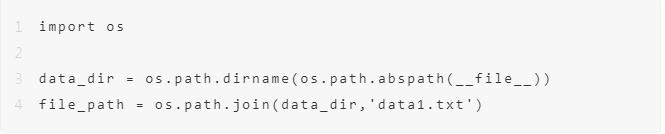
文件改名与复制
python对文件进行"改名"和"复制":

调用脚本小技巧
技巧一
运行自动化脚本时,将鼠标放到屏幕中间或者下方(有可能切换窗口时定位不到),大量脚本运行,一般我们都是在后台运行。
代码示例:

技巧二
cmd窗口,直接把结果写入文本:
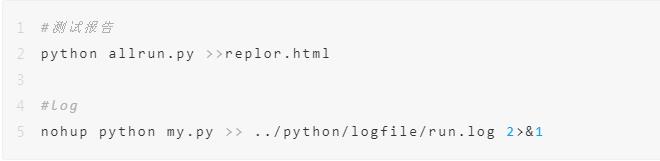
参数说明
nuhup:是no hang up的缩写,即不挂断运行。
2>&1:
0:表示stdin标准输入,用户键盘输入的内容;
1:表示stdout标准输出,输出到显示屏的内容;
2:表示stderr标准错误,报错内容。
自动化测试学习资源
这些资料,以及自动化测试进阶线路详细讲解,对于想进阶测试的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助…….
以上是关于这21条避坑指南,让你完美运行自动化的主要内容,如果未能解决你的问题,请参考以下文章