一文速学-Pandas处理DataFrame稀疏数据及维度不匹配数据详解
Posted fanstuck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文速学-Pandas处理DataFrame稀疏数据及维度不匹配数据详解相关的知识,希望对你有一定的参考价值。
目录
前言
众所周知我们获取的第一手数据往往都是比较杂乱无章的,这些文件保存一般都是csv文件或者是excel文件,读取转换成DataFrame还有可能因为缺少列索引或者是各类数据维度不相等而报错。
Pandas的基础数据结构Series和DataFrame。若是还不清楚的可以再去看看我之前的博客详细介绍这两种数据结构的处理方法:
一文速学-Pandas实现数值替换、排序、排名、插入和区间切片
一些Pandas基础函数的使用方法:
DataFrame多表合并拼接函数concat、merge参数详解+代码操作展示
Pandas中read_excel函数参数使用详解+实例代码
关于包含在异常值里面的空值和重复值均有三篇博客专门详细介绍了处理他们的方法:
读取成功为DataFrame仍然有很多问题存在,比如列索引缺失,众多NaN数据以及合并计算问题等,这篇文章将具体解决此场景下的内容。
一、索引缺失
读取缺失量较大的数据时,索引并不是能完全覆盖到的。存在着列索引缺失的问题,这是一个比较头疼的问题,使得我们后面的数据特征无法使用:
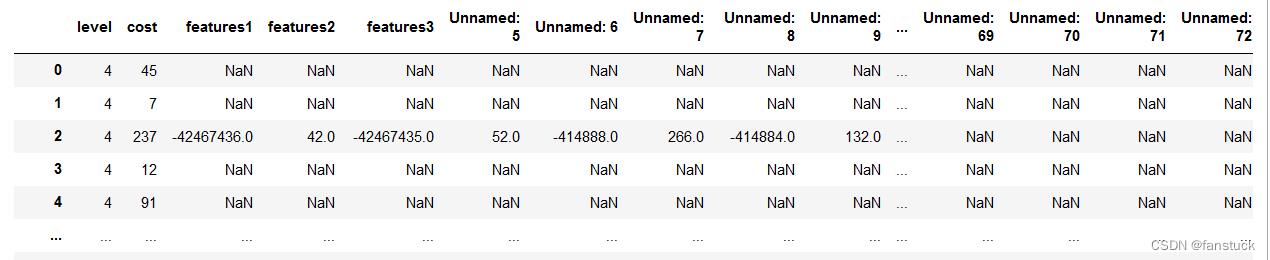
这是针对机器学习的数据集特征,面对这种情况我们可以通过重新设置索引的方式,倘若特征之间是有规律的话,例如上表5列以后的数据每列的列索引都是features的话那么我们可以通过reindex的方法给它补全索引:
def deal_defect(df,n):
df_defect=df.iloc[:,n:]
m=4
list_columns=[]
for i in range(df_defect.shape[1]):
list_columns.append('features%d'%m)
m=m+1
df_defect.columns=list_columns
df_all=pd.concat([df.iloc[:,:n],df_defect],axis=1)
return df_all
deal_defect(df,5)
二、负值取正
若是要对整个DataFrame的值都取负数,并不需要挨个列都转再使用abs函数,读取的DataFrame一般都是object类型不能直接使用abs,需要使用astype将dataframe类型转换:
当数据中带有NaN时是不能直接转int的:
df_fill=df.astype('int')IntCastingNaNError: Cannot convert non-finite values (NA or inf) to integer
但是我们转换为float的时候原始数据集又出现了后面带.0的情况:

这里我们要使用到fillna函数,先转为float取绝对值之后再填充为空值之后替换为-1,这样以来-1的位置就是缺失值的位置,以便于我们识别:
def fill_conver(df):
df_fill=df.astype('float')
df_fill=abs(df_fill)
df_fill=df_fill.fillna('')
df_fill=df_fill.replace('',-1)
df_fill=df_fill.astype(int)
return df_fill
fill_conver(df)
三.提取数值
既然有很多空值我们可以采取侧缺将低于一定比例的数据去除,这部分在上篇缺失值处理文章已经谈到这里不再说明。我们最常遇到的情况就是需要处理空值只提去出相应标签下的数值,这里涉及到列索引的选择和合并操作。例如我们只需要特征列偶数列的数值:
def get_features(df):
list_all_link=[]
df=df.iloc[:,2:]
for i in range(df.shape[0]):
#flag为控制外层循环开关
flag=1
for j in range(df.shape[1]):
if(flag==0):
break
if(j%2==0):
if(df.iloc[i:i+1,j].item()==-1):
flag=0
else:
list_all_link.append(list(df.iloc[i:i+1,j]))
return list_all_link
get_features(df)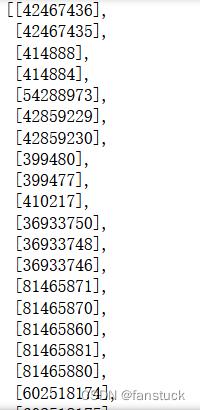
四、提取唯一值
如果我们需要只需要取到的数列中的唯一值,需要对数据集进行处理,可以使用ravel()和unique()函数。此时我们还需要注意删掉-1:
def unique_df(df):
df_features=df.iloc[:,2:]
unique_series=pd.Series(pd.Series(df_features.iloc[:,[i%2==0 for i in range(len(df_features.columns))]].values.ravel()).unique())
list_series=list(unique_series.values)
return list_series
unique_list=unique_df(df)
unique_list.remove(-1)
unique_list
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
以上是关于一文速学-Pandas处理DataFrame稀疏数据及维度不匹配数据详解的主要内容,如果未能解决你的问题,请参考以下文章