数据湖:分布式容错数据仓库Hive
Posted YoungerChina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖:分布式容错数据仓库Hive相关的知识,希望对你有一定的参考价值。
系列专题:数据湖系列文章
1. 什么是Hive
Apache Hive 是可实现大规模分析的分布式容错数据仓库系统。该数据仓库集中存储信息,您可以轻松对此类信息进行分析,从而做出明智的数据驱动决策。Hive 让用户可以利用 SQL 读取、写入和管理 PB 级数据。
Hive 建立在 Apache Hadoop 基础之上,后者是一种开源框架,可被用于高效存储与处理大型数据集。因此,Hive 与 Hadoop 紧密集成,其设计可快速对 PB 级数据进行操作。Hive 的与众不同之处在于它可以利用 Apache Tez 或 MapReduce 通过类似于 SQL 的界面查询大型数据集。使得查询和分析存储在 Hadoop 上的数据变得非常方便。
2. Hive的发展
Hive 由 Facebook 的技术团队开发的,Apache Hive 是众多满足 Facebook 业务需求的技术之一。它非常受 Facebook 内部所有用户的欢迎。它可以开发各种数据相关的应用,并且运行在具有数百个用户的集群之上。Facebook 的 Apache Hadoop 集群存储超过 2PB 的原始数据,并且每天定期加载 15TB 的数据。现在 Hive 被很多大公司使用并完善,比如亚马逊,IBM,雅虎,Netflix 等等大公司。
3. Hive如何运作?
Hive 旨在让非程序员熟悉 SQL,并使用名为 HiveQL 的类似于 SQL 的界面对 PB 级数据进行操作。传统关系数据库被用于对中小型数据集进行交互式查询,它在处理大型数据集时的表现并不理想。但 Hive 使用批处理,因此它可以快速操作非常大型的分布式数据库。Hive 会将 HiveQL 查询转换成在Hadoop 的分布式作业计划框架,亦即 Yet Another Resource Negotiator (YARN) 上运行的 MapReduce 或 Tez 作业。它会查询存储在分布式存储解决方案,如 Hadoop 分布式文件系统 (HDFS) 或对象存储S3当中的数据。Hive 将其数据库和表元数据存储在元数据仓中,而元数据仓是一种可实现轻松数据提取和发现的基于数据库或文件的存储。
Hive 包含 HCatalog,它是从 Hive 元数据仓读取数据的表和存储管理层,可帮助 Hive、Apache Pig 和 MapReduce 之间的无缝集成。通过元数据仓,HCatalog 允许 Pig 和 MapReduce 使用与 Hive 相同的数据结构,从而无需为每个引擎重新定义元数据仓。自定义应用程序或第三方集成可以使用 WebHCat,而 WebHcat 是 HCatalog 用来访问和重复使用 Hive 元数据仓的 RESTful API。
4. 为什么使用HIve
在 Apache Hive 实现之前,Facebook 已经面临很多挑战,比如随着数据的爆炸式增长,要处理这些数据变得非常困难。而传统的关系型数据库面对这样海量的数据可以说无能为力。Facebook 为了克服这个难题,开始尝试使用 MapReduce。但使用它需要具备 java 编程能力以及必须掌握 SQL,这使得该方案变得有些不切实际。而 Apache Hive 可以很好的解决 Facebook 当前面临的问题。
Apache Hive 避免开发人员给临时需求开发复杂的 Hadoop MapReduce 作业。因为 hive 提供了数据的摘要、分析和查询。Hive 具有比较好的扩展性和稳定性。有、由于 Hive 跟 SQL 语法上比较类似, 这对于 SQL 开发人员在学习和开发 Hive 时成本非常低,比较容易上手。Apache Hive 最重要的特性就是不会 Java,依然可以用好 Hive。
5. Hive 架构
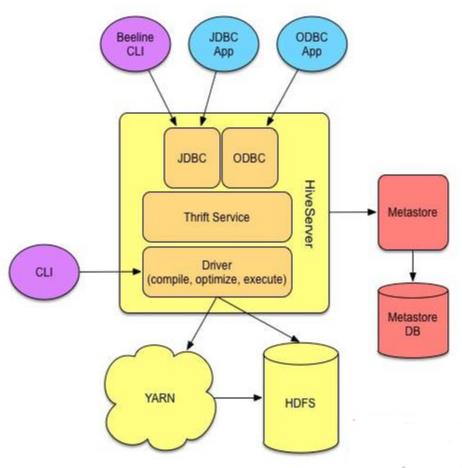
由上图可知,Hadoop 和 MapReduce 是 Hive 架构的根基。
Hive 架构包括如下组件:
- CLI(command line interface)
- JDBC/ODBC
- Thrift Server
- WEB GUI
- Metastore
- Driver(Complier、Optimizer 和 Executor)
这些组件可以分为两大类:
服务端组件
Driver 组件:该组件包括 Complier、Optimizer 和 Executor,它的作用是将 HiveQL 语句进行解析、编译优化,生成执行计划,然后调用底层的 MapReduce 计算框架。
Metastore 组件:元数据服务组件,这个组件存储 Hive 的元数据,hive 的元数据存储在关系数据库里,hive 支持的关系数据库有 derby、mysql。元数据对于 hive 十分重要,因此 hive 支持把 metastore 服务独立出来,安装到远程的服务器集群里,从而解耦 hive 服务和 metastore 服务,保证 hive 运行的健壮性。
Thrift 服务:thrift 是 facebook 开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive 集成了该服务,能让不同的编程语言调用 hive 的接口。
客户端组件
CLI:command line interface,命令行接口。
Thrift 客户端:上面的架构图里没有写上 Thrift 客户端,但是 hive 架构的许多客户端接口是建立在 thrift客户端之上,包括 JDBC 和 ODBC 接口。
WEB GUI:hive 客户端提供了一种通过网页的方式访问 hive 所提供的服务。这个接口对应 hive 的 hwi 组件(hive web interface),使用前要启动 hwi 服务。
6. Hive 的特性
Hive 有很多特性,然我们来一个个看一下:
- Hive 以简单的方式提供数据摘要,数据查询和数据分析能力。
- Hive 支持外部表,这使得它可以处理未存储在 HDFS 的数据。
- Apache Hive 非常适合 Hadoop 的底层接口需求。
- 支持数据分区
- Hive 有一个基于规则的优化器,负责优化逻辑计划。
- 可扩展性以及可伸缩性
- 使用 HiveQL 不需要深入掌握编程语言,只有掌握基本的 SQL 知识就行,使用门槛较低。
- 处理结构化数据。
- 使用 Hive 执行即时查询做数据分析。
7. Hive优缺点
Hive的优势:
- 快速:Hive 所采用的数据可通过批处理快速处理 PB 级数据。
- 熟悉:Hive 提供非程序员可以使用的熟悉的类似于 SQL 的界面。
- 可扩展:Hive 可根据您的需求被轻松分发与扩展。
Hive 具有以下局限性:
- Hive 不支持实时查询和行级更新。
- 高延迟。
- 不适用于在线事务处理。
8. Hive VS. Hbnse
| 特性 | APACHE HIVE | APACHE HBASE |
| 功能 | 类似于 SQL 的查询引擎专为大容量数据存储而设计。支持多种文件格式。 | 通过自定义查询功能提供低延迟分布式键-值存储。数据采用列式存储格式。 |
| 处理类型 | 采用 Apache Tez 或 MapReduce 计算框架的批处理。 | 实时处理。 |
| 延迟 | 中到高,取决于计算引擎的响应能力。对于相同数据卷,分布式执行模型提供比整体式查询系统(如 RDBMS)更出色的性能。 | 低,但可能不一致。HBase 架构的结构限制可能在密集写入负载期间导致延迟激增。 |
| Hadoop 集成 | 在 Hadoop 顶部运行,与 Apache Tez 或 MapReduce 一起使用可进行处理,与 HDFS 或 Amazon S3 一起可进行存储。 | 在 HDFS 或 Amazon S3 顶部运行。 |
| SQL 支持 | 通过 HiveQL 提供类似于 SQL 的查询功能。 | 自身不提供 SQL 支持。您可以为 SQL 功能使用 Apache Phoenix。 |
| Schema | 适用于全部表的定义 Schema。 | 无 Schema。 |
| 数据类型 | 支持结构化和非结构化数据。为常见的 SQL 数据类型提供原生支持,如 INT、FLOAT 和 VARCHAR。 | 仅支持非结构化数据。由用户定义数据字段到 Java 支持的数据类型的映射。 |
9. Hive 使用案例

Airbnb 在世界范围内为人们提供住宿和活动匹配,注册的房东超过 290 万名,可提供 80 万间民宿供有需要者在夜间住宿。Airbnb 使用 Amazon EMR 在 S3 湖内数仓上运行 Apache Hive。在 EMR 集群上运行 Hive 让 Airbnb 分析师可对存储于 S3 湖内数仓中的数据执行临时 SQL 查询。通过迁移到 S3 湖内数仓,Airbnb 降低了自身开支,并且现在可以进行成本归属分析,使 Apache Spark 作业的速度比原来增加了三倍。

Guardian 通过其保险和财富管理产品及服务为 2700 万名会员提供他们值得拥有的安全保护。Guardian 使用 Amazon EMR 在 S3 湖内数仓上运行 Apache Hive。Apache Hive 被用于批处理。S3 湖内数仓为 Guardian Direct 提供支持,该数字平台让消费者可以研究与购买 Guardian 产品和保险产业的第三方产品。

FINRA(美国金融业监管局)是美国最大的独立安全监管机构,负责监控和管制金融交易行为。FINRA 使用 Amazon EMR 在 S3 湖内数仓上运行 Apache Hive。在 EMR 集群上运行 Hive 让 FINRA 可以利用 SQL 处理与分析多达 900 亿个事件的交易数据。相较于 FINRA 的本地解决方案,云湖内数仓能够实现高达 2000 万 USD 的成本节约,并大幅缩短恢复与升级所需的时间。
Vanguard 是一家在美国注册的投资顾问,它也是最大的共同基金提供商和第二大交易型开放式指数基金提供商。Vanguard 使用 Amazon EMR 在 S3 湖内数仓上运行 Apache Hive。数据被存储在 S3 中,而 EMR 会在此类数据基础上构建一个 Hive 元数据仓。Hive 元数据仓包含与 EMR 集群中的数据和表有关的全部元数据,从而实现轻松分析数据。Hive 还让分析师可对存储于 S3 湖内数仓中的数据执行临时 SQL 查询。通过 Amazon EMR 迁移到 S3 湖内数仓帮助超过 150 名数据分析师成功提高运维效率,并将 EC2 和 EMR 的成本降低了 60 万 USD。
10. 参考资料
[01]https://aws.amazon.com/cn/big-data/what-is-hive/
[02]https://www.hadoopdoc.com/hive/hive-tutorial
以上是关于数据湖:分布式容错数据仓库Hive的主要内容,如果未能解决你的问题,请参考以下文章
数据湖 VS 传统数据仓库→ 基于 Spark 的数据湖项目实践