微突发丢包的艺术
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微突发丢包的艺术相关的知识,希望对你有一定的参考价值。
假设所有流量均 TCP-based,并且均良好 TCP cc。
从链路 Buffer 视角看,丢哪个位置的包影响是不同的:
- 队尾丢包:所有流检测到丢包主动降速前,丢包将持续,是否全局同步取决于流量 RTT 方差,即它们检测到丢包时机的差异。
- 队首丢包:所有流均最快检测到丢包并降速,拥塞缓解。强调 cc 的良好性很重要,如果发送端激进重传,队首丢包反而加重拥塞且有拥塞崩溃风险,它违背了守恒律(每个包副本在网络上只有一个)。
- 随机丢包:参考 RED,WRED。
从应用的视角,对特定的应用,丢哪个位置的包影响是不同的:
- 白酒样式:如文件传输。数据越老越重要,对于可靠传输,接收端可能会丢弃更多带有空洞的乱序包以节省内存,丢弃老数据将会加重重传。
- 牛奶样式:如流媒体传输。数据越新越重要,这是防止卡顿的要点,太老的数据,丢就丢吧。对于 TCP-based 流媒体传输,即使丢弃靠近队尾的新数据,排队延时也必不可免。
始终保持 Buffer 短队列,不要 overflow 就对了。
造成 Buffer overflow 的高危因素即微突发,快速缓解微突发是高尚的。
来一个高尚的丢包策略,追堵造成微突发的祸首。
当 Buffer 队列超过警戒阈值并持续走高,大概率微突发正在发生。微突发往往是某些特殊特征的流量导致,比如:
- 多个源打同一个目标。
- 同一源打向多个目标。
- 多个源打向同一网段。
- 同一网段打多个网段。
其中同一源打多个目标当前已不太现实,这种能力由单台设备的能力天然限速,但多源打同一目标以及多源打同一网段比较常见,DDoS,incast 均为此类型。
若要针对性解决微突发问题,需要构建复杂的虚拟队列以及复杂的调度算法,这无疑增加了常态时的处理开销从而降低 PPS,高尚的做法是自适应丢弃微突发流量。
基于以下虽不严谨但合理的假设:
- 微突发期间,造成微突发的流量在同一时间段内总流量中占比最大。
借此假设,随想出一个装置,它无需左右对比即可判定谁是肇事者,见下图:
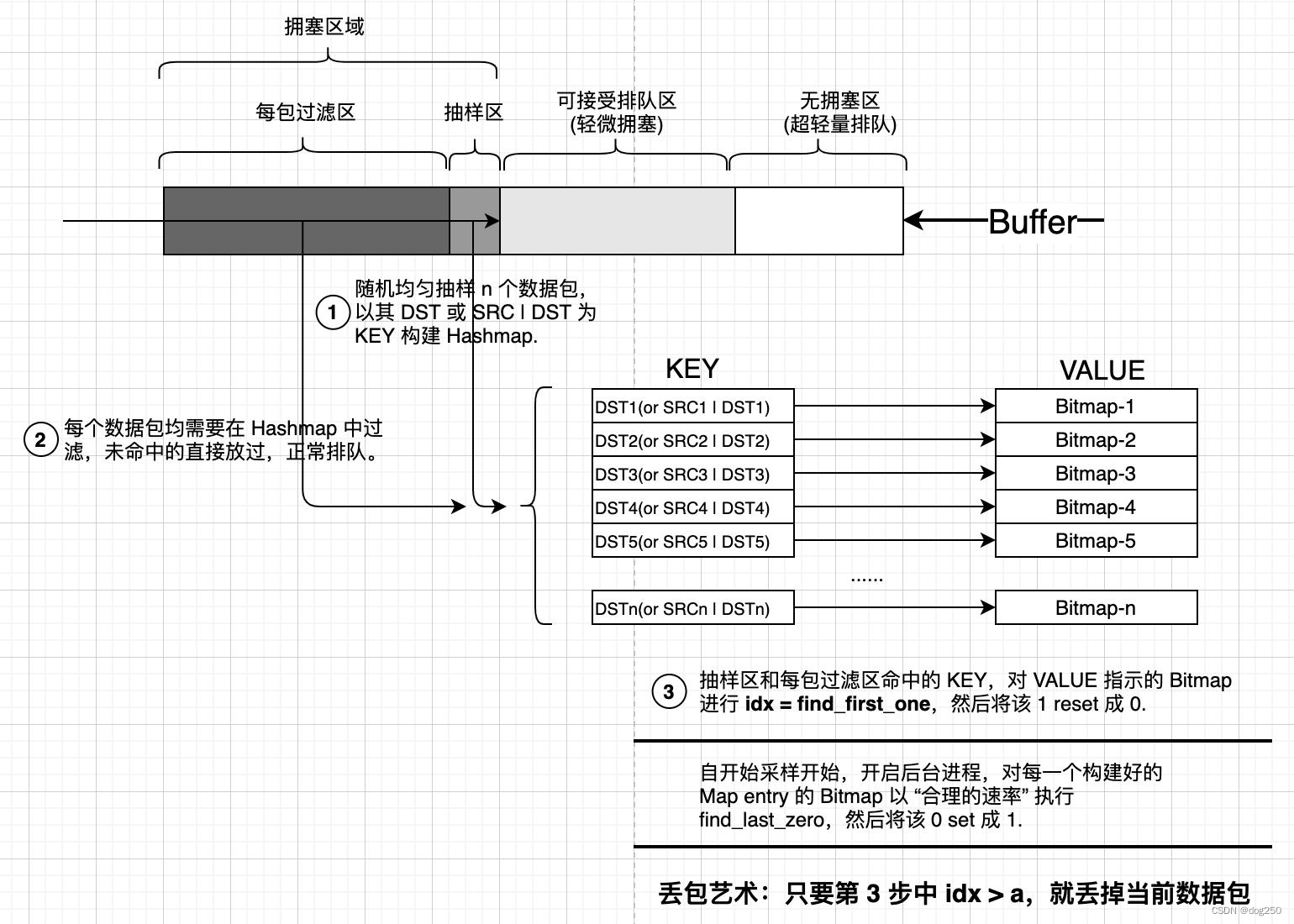
简单解释,如果微突发导致 Buffer 队列长度增加至拥塞水位以上到达采样区,假设采用 Dst/24 作为 KEY,随机采集的数据包构建的 Top-N Hashmap-entrys 几乎一定包含微突发流量的 entry,如果微突发持续,该 entry 的 VALUE Bitmap 被 reset 的速率必然大于被 set 的速率,从而造成 idx = find_first_one 偏大而丢包,最终成功阻滞微突发流量,缓解拥塞。
如果业务形态本身就是微突发呢?很抱歉,不允许。另外,以 DST/24 为 KEY 进行尾丢,与 SRC 不相关,因此尾丢并不刻意针对某条流,而是针对引发微突发的所有流(多打一)。它们若是良好 TCP,总会超时退避重传,如果不是良好的 TCP,还讲什么道德。
上面提到的 Hashmap 相关的 CRUD 操作,不细说,如果觉得慢,效率低,不好的话,可以空间换时间,做一个 4G 大小的 DST IPv4 索引,每个地址一个 index 即可。实际大概也就是这个极端和另一个极端的偏置折中。
协助排查一起公网带宽陡降的 case,最终是微突发导致。公网似乎没有什么缓解微突发的方法,这和 IDC 不同。IDC 网络和业务是闭环的,机房就在那里,最物理的方案就是扩容调整收敛比,或者直接告知业务不能这么怼,问题就解决了,但公网不行,运营商的设备没法调整,只能任其丢包。这导致面对 IDC 和公网时,拥塞控制的策略完全不同。IDC 重网络轻终端,终端资源要留给计算,过度复杂的算法因 overhead 过高在 IDC 被弃用。GBN 在公网几乎绝迹,在 IDC 依然默认重传策略。…。站在运营商设备视角,试图解决微突发缓解问题,写了这篇短文,自觉高尚。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于微突发丢包的艺术的主要内容,如果未能解决你的问题,请参考以下文章