Hadoop
Posted AC.WJH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop相关的知识,希望对你有一定的参考价值。
目录
采集日志Flume

| hadoop102 | hadoop103 | hadoop104 | |
| Flume(采集日志) | Flume | Flume |
日志采集Flume安装
安装部署
1.将ae-flume-1.9.0-bin.tar.gz上传到linux的/opt/software目录下
2.解压apache-flume-1.9.0-bin.tar.gz到/opt/module/目录下
3.修改apache-flume-1.9.0-bin的名称为flume
4.将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
5.将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
[atguigu@hadoop102 software]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
[atguigu@hadoop102 module]$ mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume
[atguigu@hadoop102 module]$ rm /opt/module/flume/lib/guava-11.0.2.jar
[atguigu@hadoop102 conf]$ mv flume-env.sh.template flume-env.sh
[atguigu@hadoop102 conf]$ vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212注意:删除guava-11.0.2.jar的服务器节点,一定要配置hadoop环境变量。否则会报异常
Flume组件选型

日志采集Flume配置
1)Flume配置分析
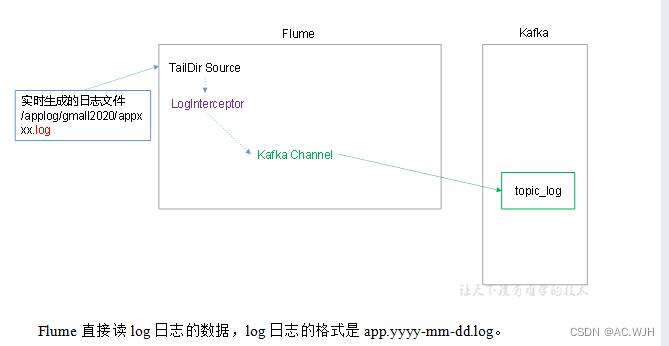
2)Flume的具体配置如下
1.在/opt/module/flume/conf目录下创建file-flume-kafka.conf文件
[atguigu@hadoop102 conf]$ vim file-flume-kafka.conf#为各组件命名
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1Flume拦截器
1)创建Maven工程flume-interceptor
2)创建包名:com.atguigu.flume.interceptor
3) 在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>4)在com.atguigu.flume.interceptor包下创建JSONUtils类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
public class JSONUtils
public static boolean isJSONValidate(String log)
try
JSON.parse(log);
return true;
catch (JSONException e)
return false;
5)在com.atguigu.flume.interceptor包下创建LogInterceptor类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor
@Override
public void initialize()
@Override
public Event intercept(Event event)
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
if (JSONUtils.isJSONValidate(log))
return event;
else
return null;
@Override
public List<Event> intercept(List<Event> list)
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext())
Event next = iterator.next();
if(intercept(next)==null)
iterator.remove();
return list;
public static class Builder implements Interceptor.Builder
@Override
public Interceptor build()
return new ETLInterceptor();
@Override
public void configure(Context context)
@Override
public void close()
日志采集Flume启动停止脚本
1.在home/atguigu/bin目录下创建脚本f1.sh ,并在脚本中填写如下内容
[atguigu@hadoop102 bin]$ vim f1.sh#! /bin/bash
case $1 in
"start")
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log1.txt 2>&1 &"
done
;;
"stop")
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk 'print \\$2' | xargs -n1 kill -9 "
done
;;2.增加脚本权限
3.f1集群启动喝停止脚本
[atguigu@hadoop102 bin]$ chmod u+x f1.sh
[atguigu@hadoop102 module]$ f1.sh start
[atguigu@hadoop102 module]$ f1.sh stop消费Kafka数据Flume

| hadoop102 | hadoop103 | hadoop104 | |
| Flume(消费Kafka) | Flume |
消费者Flume配置
1)Flume配置分析
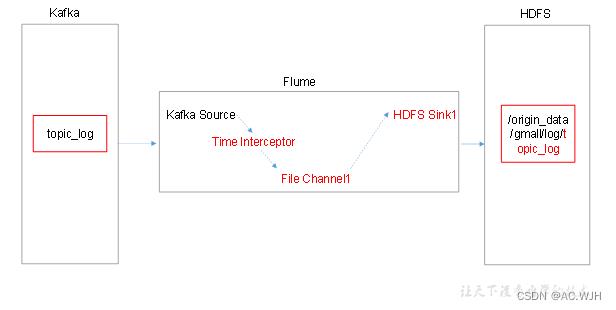
2)Flume的具体配置如下
1.在hadoop104的/opt/module/flume/conf目录下创建kafka-flume-hdfs.conf文件
[atguigu@hadoop104 conf]$ vim kafka-flume-hdfs.conf
## 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
#控制生成的小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1Flume时间拦截器
由于Flume默认会用Linux系统时间,作为输出到HDFS路径的时间。如果数据是23:59分产生的。Flume消费Kafka里面的数据时,有可能已经是第二天了,那么这部门数据会被发往第二天的HDFS路径。我们希望的是根据日志里面的实际时间,发往HDFS的路径,所以下面拦截器作用是获取日志中的实际时间。
解决的思路:拦截json日志,通过fastjson框架解析json,获取实际时间ts。将获取的ts时间写入拦截器header头,header的key必须是timestamp,因为Flume框架会根据这个key的值识别为时间,写入到HDFS。
1)在com.atguigu.flume.interceptor包下创建TimeStampInterceptor类
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize()
@Override
public Event intercept(Event event)
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
@Override
public List<Event> intercept(List<Event> list)
events.clear();
for (Event event : list)
events.add(intercept(event));
return events;
@Override
public void close()
public static class Builder implements Interceptor.Builder
@Override
public Interceptor build()
return new TimeStampInterceptor();
@Override
public void configure(Context context)
2)重新打包
3)需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面
4)分发Flume到hadoop103、hadoop104
[atguigu@hadoop102 lib]$ ls | grep interceptor
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
[atguigu@hadoop102 module]$ xsync flume/消费者Flume启动停止脚本
1)在/home/atguigu/bin目录下创建脚本f2.sh并填写如下内容
[atguigu@hadoop102 bin]$ vim f2.sh#! /bin/bash
case $1 in
"start")
for i in hadoop104
do
echo " --------启动 $i 消费flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log2.txt 2>&1 &"
done
;;
"stop")
for i in hadoop104
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk 'print \\$2' | xargs -n1 kill"
done
;;
esac2)增加脚本执行权限
Flume内存优化

采集通道启动/停止脚本
1)在bin目录下创建脚本cluster.sh,并填写以下内容
[atguigu@hadoop102 bin]$ vim cluster.sh#!/bin/bash
case $1 in
"start")
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
hdp.sh start
#启动 Kafka采集集群
kf.sh start
#启动 Flume采集集群
f1.sh start
#启动 Flume消费集群
f2.sh start
;;
"stop")
echo ================== 停止 集群 ==================
#停止 Flume消费集群
f2.sh stop
#停止 Flume采集集群
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
hdp.sh stop
#停止 Zookeeper集群
zk.sh stop
;;
esac2)增加脚本权限
[atguigu@hadoop102 bin]$ chmod u+x cluster.sh
以上是关于Hadoop的主要内容,如果未能解决你的问题,请参考以下文章