Spark SQL简介
Posted 程序员超时空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL简介相关的知识,希望对你有一定的参考价值。
Spark SQL简介
一、从Shark说起
1、在这之前我们要先理解Hive的工作原理:
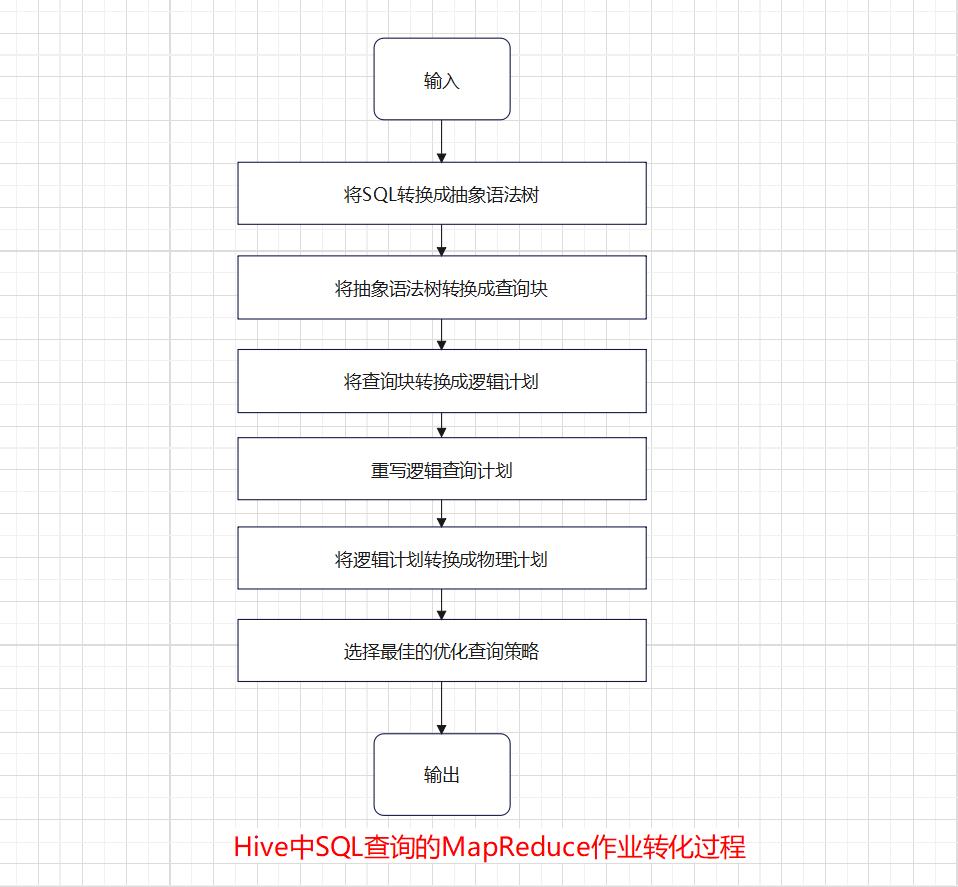
Hive是一个基于Hadoop的数据仓库工具,提供了类似于关系数据库SQL的查询语言——HiveSQL,用户可以通过HiveSQL语句快速实现简单的MapReduce统计,Hive自身可以自动将HiveSQL语句快速转换成MapReduce任务进行运行。
2、Shark提供了类似于Hive的功能,与Hive不同的是,Shark把SQL语句转换成Spark作业,而不是MapReduce作业。
可以近似地认为:Shark仅将物理执行计划从MapReduce作业替换成了Spark作业,也就是通过Hive的HiveSQL解析功能,把HiveSQL翻译成Spark上的RDD操作。

Shark的设计导致了两个问题:
一、是执行计划优化完全依赖于Hive,不方便添加新的优化策略。二、是因为Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支。
3、Spark SQL架构如下:

Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。
Spark SQL增加了DataFrame(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。
Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范。
二、DataFrame概述
1、DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。
Spark能够轻松实现从mysql到DataFrame的转化,并且支持SQL查询。
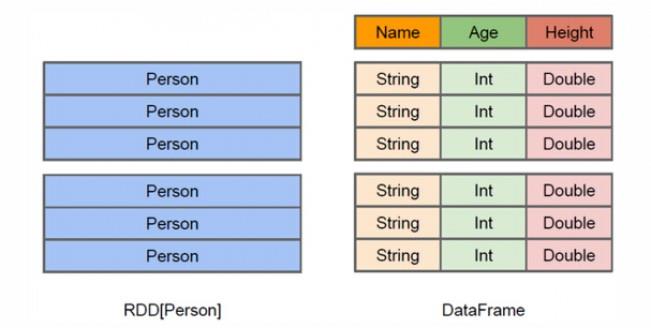
RDD是分布式的 Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的。
DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息。
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能。
SparkSession支持从不同的数据源加载数据,并把数据转换DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持。
在编写独立应用程序时,可以通过如下语句创建一个SparkSession对象
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
实际上,在启动进入pyspark以后,pyspark就默认提供了一个SparkContext对象(名称为sc)和一个SparkSession对象(名称为spark)

2、从不同类型的文件中加载数据创建DataFrame
#从不同类型的文件中加载数据创建DataFrame
df1 = spark.read.text("file:///home/hadoop/program1/people.txt")
df1.show()
df2 = spark.read.json("file:///home/hadoop/program1/people.json")
df2.show()
df1_1 = spark.read.format("text").load("file:///home/hadoop/program1/people.txt")
df1_1.show()
df2_1 = spark.read.format("json").load("file:///home/hadoop/program1/people.json")
df2_1.show()
结果:

3、DataFrame的保存
#DataFrame的保存
#例:把上面名称为df1的文件保存到不同格式文件中
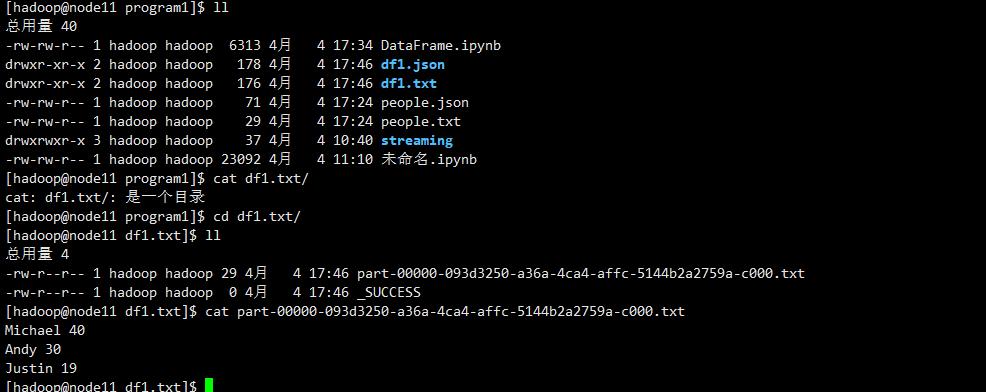
df1.write.text("df1.txt")
df1.write.json("df1.json")
df1.write.format("text").save("df1.txt")
df1.write.format("json").save("df1.json")
df2.select("name","age").write.format("json").save("file:///home/hadoop/program1/df2.json") #选取指定的列保存
另一种存储方式Parquet。详细见下面链接。
当把该数据保存到一个文本文件中会新生成一个名称为df1.json的目录(不是文件)和一个名称df1.txt的目录(不是文件)
如果再次读取json或text文件生成DataFrame,可以直接用这个目录名称,不需要使用part-00000-093d3250-a36a-4ca4-affc-5144b2a2759a-c000.txt文件(当然,使用这个文件也可以)。
三、DataFrame的常用操作
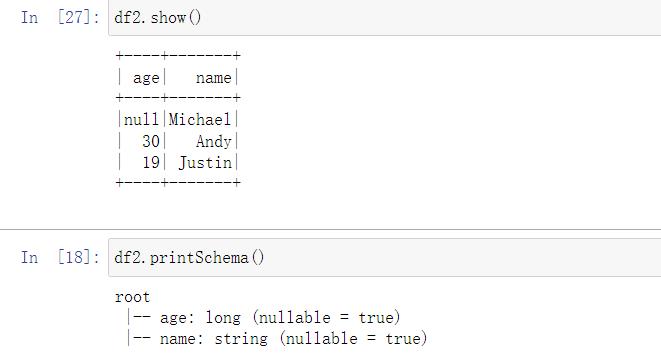
- printSchema()
打印出DataFrame的模式(Schema)信息。
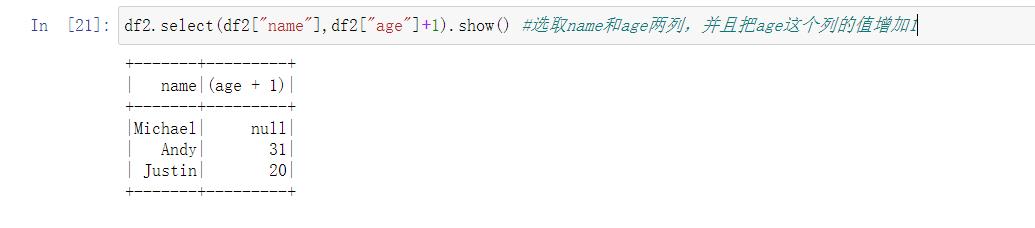
- select()
从DataFrame中选取部分列的数据。
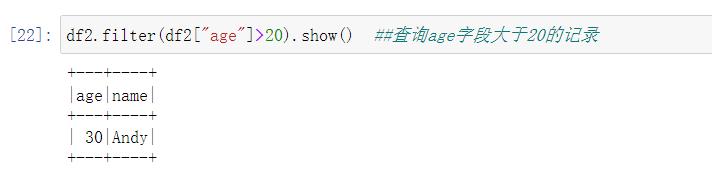
- filter()
实现条件查询,找到满足条件要求的记录。
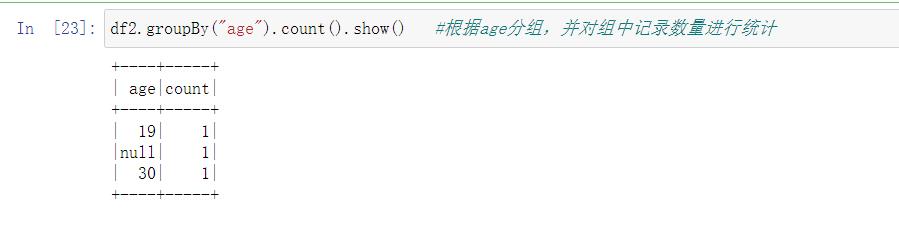
- groupBy()
用于对记录进行分组。
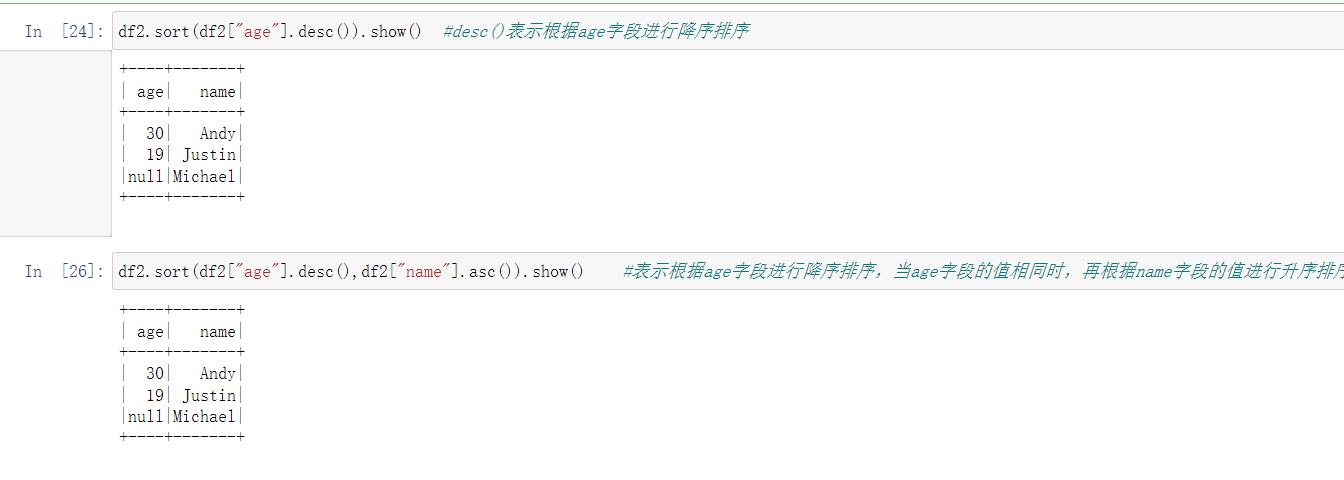
- sort()
用于对记录进行排序。
四、从RDD转换得到DataFrame
Spark提供了如下_两种_方法实现从RDD转换得到DataFrame
1.利用反射机制推断RDD模式
利用反射机制来推断包含特定类型对象的RDD的模式(Schema),适用于数据结构已知时的RDD转换。
例:现在要把people.txt加载到内存中生成一个DataFrame,并查询其中的数据:
from pyspark.sql import Row
people = sc.textFile("file:///home/hadoop/program1/people.txt") #生成RDD文件
people1 = people.map(lambda x:x.split(" ")).map(lambda x:Row(name=x[0],age=x[1])) #得到新的RDD,每个元素都是Row对象
schemaPeople = spark.createDataFrame(people1) #转换成DataFrame
schemaPeople.createOrReplaceTempView("people") #注册为临时表,临时表名字为people
personsDF = spark.sql("select name,age from people where age>20") #SQL语句查询
personsRDD = personsDF.rdd.map(lambda x:"Name: "+x.name+","+"Age "+x.age) #格式化输出
personsRDD.collect()
结果:
['Name: Michael,Age 40', 'Name: Andy,Age 30']
2.使用编程方式定义RDD模式
使用编程接口构造一个模式(Schema),并将其应用在已知的RDD上,适用于数据结构未知时的RDD转换。
from pyspark.sql.types import *
from pyspark.sql import Row
#下面生成“表头”
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split(" ")]
schema = StructType(fields)
#下面生成“表中的记录”
lines = sc.textFile("file:///home/hadoop/program1/people.txt")
parts = lines.map(lambda x: x.split(" "))
people = parts.map(lambda x: Row(x[0], x[1].strip()))
#下面把“表头”和“表中的记录”拼装在一起
schemaPeople = spark.createDataFrame(people, schema)
schemaPeople.createOrReplaceTempView("people")
results = spark.sql("select name,age from people")
results.show()
结果
+-------+---+
| name|age|
+-------+---+
|Michael| 40|
| Andy| 30|
| Justin| 19|
+-------+---+
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦
以上是关于Spark SQL简介的主要内容,如果未能解决你的问题,请参考以下文章