ML之PFI(eli5):基于mpg汽车油耗数据集利用RF随机森林算法和PFI置换特征重要性算法实现模型特征可解释性排序
Posted 一个处女座的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ML之PFI(eli5):基于mpg汽车油耗数据集利用RF随机森林算法和PFI置换特征重要性算法实现模型特征可解释性排序相关的知识,希望对你有一定的参考价值。
ML之PFI(eli5):基于mpg汽车油耗数据集利用RF随机森林算法和PFI置换特征重要性算法实现模型特征可解释性排序
目录
基于mpg数据集利用RF随机森林算法和PFI置换特征重要性算法实现模型特征可解释性排序
# T1、基于模型本身的解释—如随机森林树模型,但模型可能会存在偏差
相关文章
ML之PFI(eli5):基于mpg汽车油耗数据集利用RF随机森林算法和PFI置换特征重要性算法实现模型特征可解释性排序
ML之PFI(eli5):基于mpg汽车油耗数据集利用RF随机森林算法和PFI置换特征重要性算法实现模型特征可解释性排序实现
基于mpg汽车油耗数据集利用RF随机森林算法和PFI置换特征重要性算法实现模型特征可解释性排序
# 1、定义数据集
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | origin | name |
| 18 | 8 | 307 | 130 | 3504 | 12 | 70 | usa | chevrolet chevelle malibu |
| 15 | 8 | 350 | 165 | 3693 | 11.5 | 70 | usa | buick skylark 320 |
| 18 | 8 | 318 | 150 | 3436 | 11 | 70 | usa | plymouth satellite |
| 16 | 8 | 304 | 150 | 3433 | 12 | 70 | usa | amc rebel sst |
| 17 | 8 | 302 | 140 | 3449 | 10.5 | 70 | usa | ford torino |
# 2、数据集预处理
before (398, 9)
mpg cylinders displacement ... model_year origin name
0 18.0 8 307.0 ... 70 usa chevrolet chevelle malibu
1 15.0 8 350.0 ... 70 usa buick skylark 320
2 18.0 8 318.0 ... 70 usa plymouth satellite
3 16.0 8 304.0 ... 70 usa amc rebel sst
4 17.0 8 302.0 ... 70 usa ford torino
[5 rows x 9 columns]
after dropna and drop (392, 8)
mpg cylinders displacement ... acceleration model_year origin
0 18.0 8 307.0 ... 12.0 70 usa
1 15.0 8 350.0 ... 11.5 70 usa
2 18.0 8 318.0 ... 11.0 70 usa
3 16.0 8 304.0 ... 12.0 70 usa
4 17.0 8 302.0 ... 10.5 70 usa# 3、模型建立和训练
# 3.1、数据集切分
X_feature_ns: ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year']
# 4、对模型进行PFI可视化
# T1、基于模型本身的解释—如随机森林树模型,但模型可能会存在偏差
<style>
table.eli5-weights tr:hover
filter: brightness(85%);
</style>
<table class="eli5-weights eli5-feature-importances" style="border-collapse: collapse; border: none; margin-top: 0em; table-layout: auto;">
<thead>
<tr style="border: none;">
<th style="padding: 0 1em 0 0.5em; text-align: right; border: none;">Weight</th>
<th style="padding: 0 0.5em 0 0.5em; text-align: left; border: none;">Feature</th>
</tr>
</thead>
<tbody>
<tr style="background-color: hsl(120, 100.00%, 80.00%); border: none;">
<td style="padding: 0 1em 0 0.5em; text-align: right; border: none;">
0.2846
± 0.2878
</td>
<td style="padding: 0 0.5em 0 0.5em; text-align: left; border: none;">
displacement
</td>
</tr>
<tr style="background-color: hsl(120, 100.00%, 85.66%); border: none;">
<td style="padding: 0 1em 0 0.5em; text-align: right; border: none;">
0.1770
± 0.2423
</td>
<td style="padding: 0 0.5em 0 0.5em; text-align: left; border: none;">
weight
</td>
</tr>
<tr style="background-color: hsl(120, 100.00%, 86.61%); border: none;">
<td style="padding: 0 1em 0 0.5em; text-align: right; border: none;">
0.1604
± 0.1535
</td>
<td style="padding: 0 0.5em 0 0.5em; text-align: left; border: none;">
horsepower
</td>
</tr>
<tr style="background-color: hsl(120, 100.00%, 87.85%); border: none;">
<td style="padding: 0 1em 0 0.5em; text-align: right; border: none;">
0.1397
± 0.1684
</td>
<td style="padding: 0 0.5em 0 0.5em; text-align: left; border: none;">
mpg
</td>
</tr>
<tr style="background-color: hsl(120, 100.00%, 89.82%); border: none;">
<td style="padding: 0 1em 0 0.5em; text-align: right; border: none;">
0.1085
± 0.0800
</td>
<td style="padding: 0 0.5em 0 0.5em; text-align: left; border: none;">
acceleration
</td>
</tr>
<tr style="background-color: hsl(120, 100.00%, 92.40%); border: none;">
<td style="padding: 0 1em 0 0.5em; text-align: right; border: none;">
0.0715
± 0.0545
</td>
<td style="padding: 0 0.5em 0 0.5em; text-align: left; border: none;">
model_year
</td>
</tr>
<tr style="background-color: hsl(120, 100.00%, 93.41%); border: none;">
<td style="padding: 0 1em 0 0.5em; text-align: right; border: none;">
0.0583
± 0.1736
</td>
<td style="padding: 0 0.5em 0 0.5em; text-align: left; border: none;">
cylinders
</td>
</tr>
</tbody>
</table>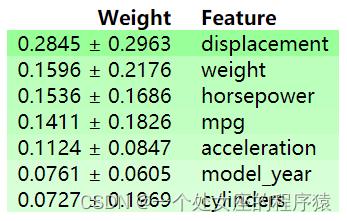
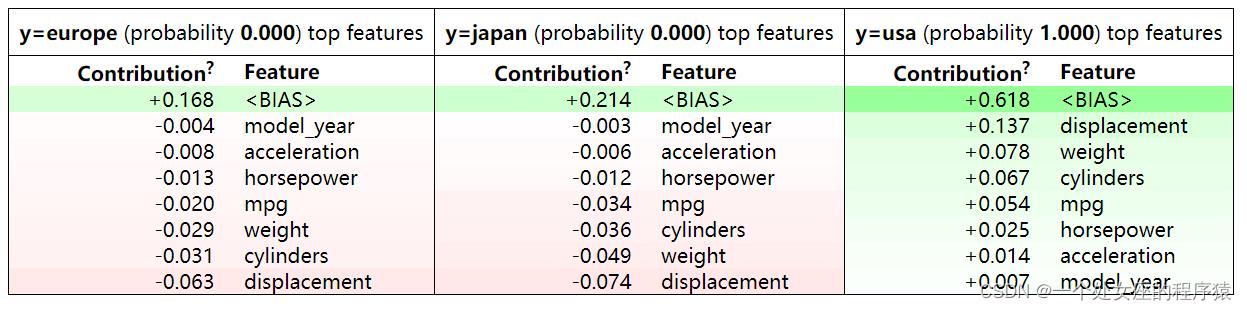
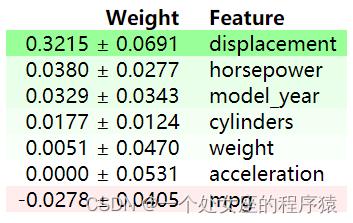
# T2、基于模型度量的解释—PFI置换特征重要性并可视化
以上是关于ML之PFI(eli5):基于mpg汽车油耗数据集利用RF随机森林算法和PFI置换特征重要性算法实现模型特征可解释性排序的主要内容,如果未能解决你的问题,请参考以下文章