c++:从单例到内存屏障
Posted Redrain
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c++:从单例到内存屏障相关的知识,希望对你有一定的参考价值。
首先我们用c++写一个经典的单例:
#include <mutex>
class Singleton
public:
static Singleton* GetInstance()
if (!instance_)
std::lock_guard<std::mutex> lock(lock_);
if (!instance_)
instance_ = new Singleton();
return (Singleton*)instance_;
private:
static std::mutex lock_;
static volatile Singleton* instance_;
private:
Singleton() ;
virtual ~Singleton() ;
Singleton(const Singleton &) = delete;
Singleton& operator=(const Singleton &) = delete;
;
std::mutex Singleton::lock_;
volatile Singleton* Singleton::instance_ = nullptr;
在面试时,单例是个经典的题目,从中可以考察一个程序猿对c++语法和多线程相关的知识。一般情况下,对应届生面到单例的双重检查,就算是达到目的了。一般认为双重检查的单例就是线程安全且性能优良的了
指令重排
现代编译器的代码优化和编译器指令重排可能会影响到代码的执行顺序
int x = 0;
int y = 0;
void ThreadA()
x = 1;
y = 2;
void ThreadB()
if (y == 2)
assert(x == 1);
假如这两个线程里的变量读写操作都是原子操作,那么assert断言会触发吗?答案是会,程序在执行的时候可能先给y赋值为2,但是x任然为0。原因可能是:
- 编译器在生成指令时做了重排,因为对编译器来说线程A中的两个赋值操作没有任何联系
- CPU在执行时做了指令重排
- CPU读取的是多级缓存中的缓存值
编译器和CPU做重排操作,都是为了提升程序执行的性能(虽然这个简单的例子中看不出来)
双重检查的线程安全
接下来讨论双重检查的单例线程安全性。**instance_ = new Singleton();**这个操作实际上是三个步骤:
1. tmp = operator new(sizeof(Singleton));
2. new(tmp) Singleton;
3. instance_ = tmp;
分配内存,执行构造,把地址赋值给instance_。但是结合之前的指令重排可以知道,编译器并不会被约束去执行这些步骤,很多时候第二步和第三步会交换,也就是先给instance_赋值然后再构造。这时候如果还没有进行构造时线程被挂起,另一个线程访问单例就会认为instance_已经构造完毕进而使用了未构造的对象,我们的程序就会crash。那么怎么写一个线程安全的双重检查?这需要用到内存屏障
## 内存屏障(memory barriers)
内存屏障,也叫内存栅栏(Memory Fence)。分编译器屏障(Compiler Barrier,也叫优化屏障) 和CPU内存屏障,其中编译器屏障只对编译器有效。我们一般提的内存屏障是指CPU内存屏障。
使用内存屏障,就是我们使用具有同步语义的指令来标记真正需要同步的变量和操作,告诉CPU和编译器不要对这些标记好的同步操作和变量做违反顺序一致性的优化,而其它未被标记的地方可以做原有的优化,这样就可以解决指令重排导致的问题
c++11增加了原子操作和内存屏障相关的功能,通过引入atomic头文件即可使用,在c++11之前需要使用pthread或者windows api来执行原子操作和内存屏障。atomic头文件中定义了一个模板类型atomic<T>,它封装了原子操作以及memory order相关的特性,并对各种整型(char、short、int、long等)、指针等类型提供了特化版本。对atomic模版封装的变量进行读写操作是原子的。他提供了两个基本的函数:
void store (T val, memory_order sync = memory_order_seq_cst) noexcept;
T load (memory_order sync = memory_order_seq_cst) const noexcept;
store用来写原子变量,load读原子变量。这两个函数的第二个参数memory_order是个枚举,表示c++11标准定义的不同内存操作顺序(memory order),我们用此来操作不同的内存屏障
typedef enum memory_order
memory_order_relaxed, // relaxed
memory_order_consume, // consume
memory_order_acquire, // acquire
memory_order_release, // release
memory_order_acq_rel, // acquire/release
memory_order_seq_cst // sequentially consistent
memory_order;
这些枚举值在多线程的内存访问顺序上提供了不同程度的约束,其中memory_order_relaxed是最弱的,最强的是memory_order_seq_cst(它也是所有原子操作的默认参数)。
memory_order_relaxed
松散的内存屏障,表示**没有指令同步的限制**,std::atomic使用此操作时,只保障原子性,无指令同步操作。图片来源于网络
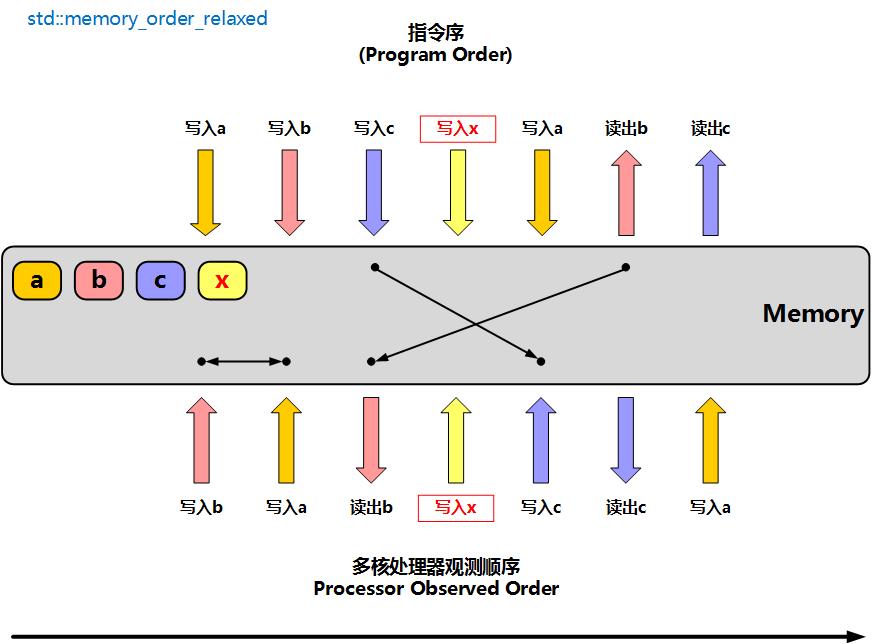
图中上方表示编译后的程序的指令执行顺序,下方代表CPU实际执行顺序。图中,a、b、b代表普通变量,x代表atomic类型变量,且设置为memory_order_relaxed操作方式。
此时在一个线程上执行时,在这个线程认为不影响最终结果的前提下,实际执行时指令可能完全是乱的。写入a、写入b的操作实际执行时可能是调换了;写入c的操作可能实际在写入x之后执行;读出b的操作实际在写入x之前执行
memory_order_release
单向释放内存屏障,表示**线程中的读写指令不能重排到此写原子变量指令之后,另一个执行读原子变量的线程,可以正确读取指令之前的变量**
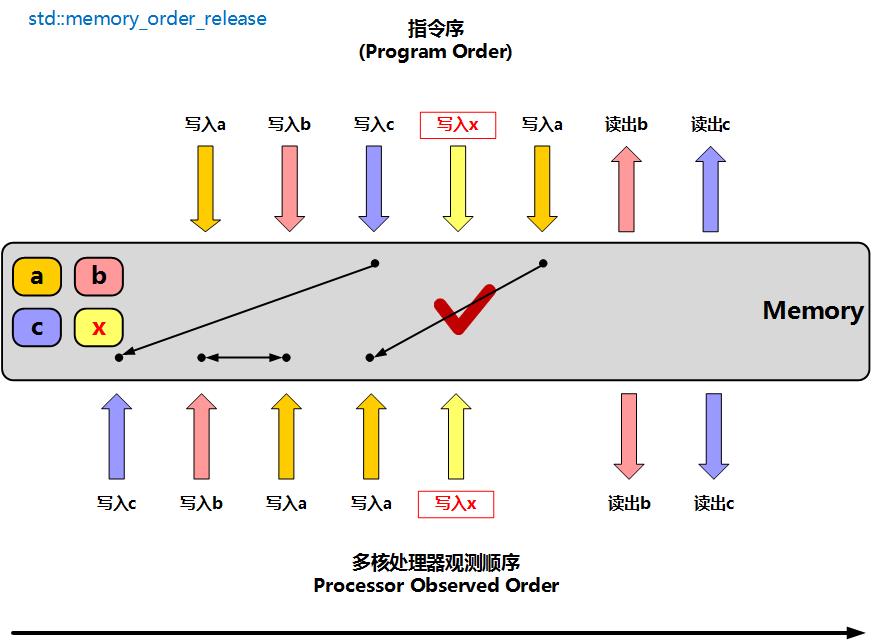
此时在一个线程上执行时,写入x的内存屏障操作之后的指令允许重排到x之前,但是写入x之前的指令不会被重排到x后面。不过写入x指令前后的那些指令的顺序是允许重排的。所以使用memory_order_release屏障后,可以保障另一个线程在执行了读取x操作之后,读取a、b、c的值是正确的,因为a、b、b的写入操作一定不会被重排到x操作之后
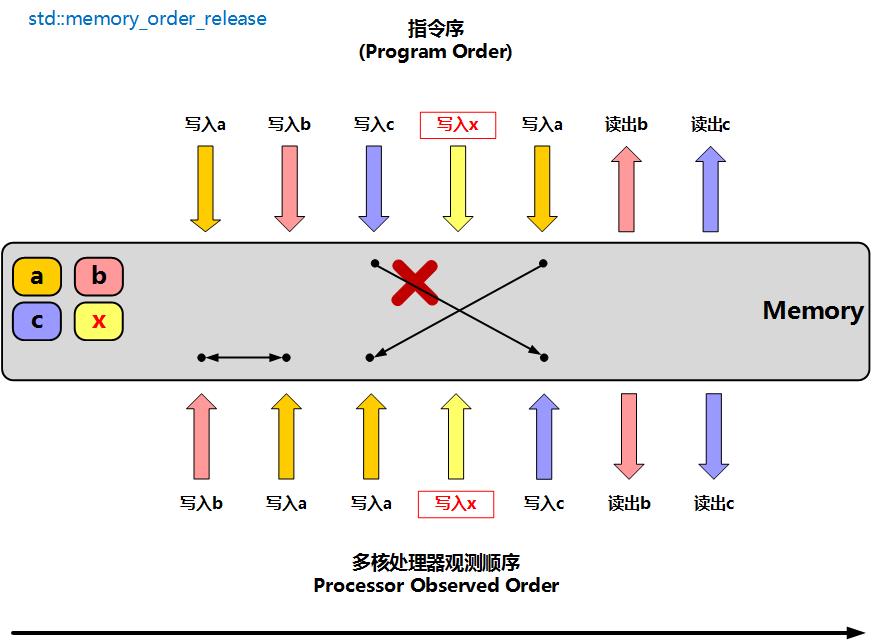
memory_order_acquire
单项加载内存屏障,表示**线程中的读写指令不能重排到此读屏障指令之前,另一个执行写原子变量的线程里写操作之前的变量,可以被此线程 读取**
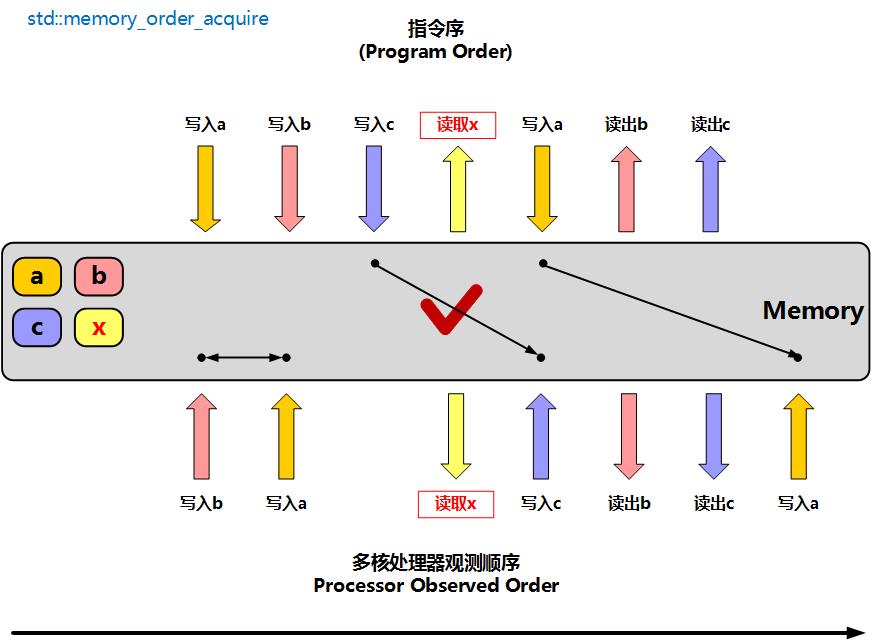
此时在一个线程上执行时,读取x的内存屏障操作之前的指令允许重排到x之后,但是读取x之后的指令不会被重排到x前面。实际上memory_order_release用于写入、memory_order_acquire用于读取,他们是成对使用:线程A使用memory_order_release写原子变量x,线程A使用memory_order_acquire读原子变量x。线程A写x之前的操作,都可以被线程B在读x之后看到
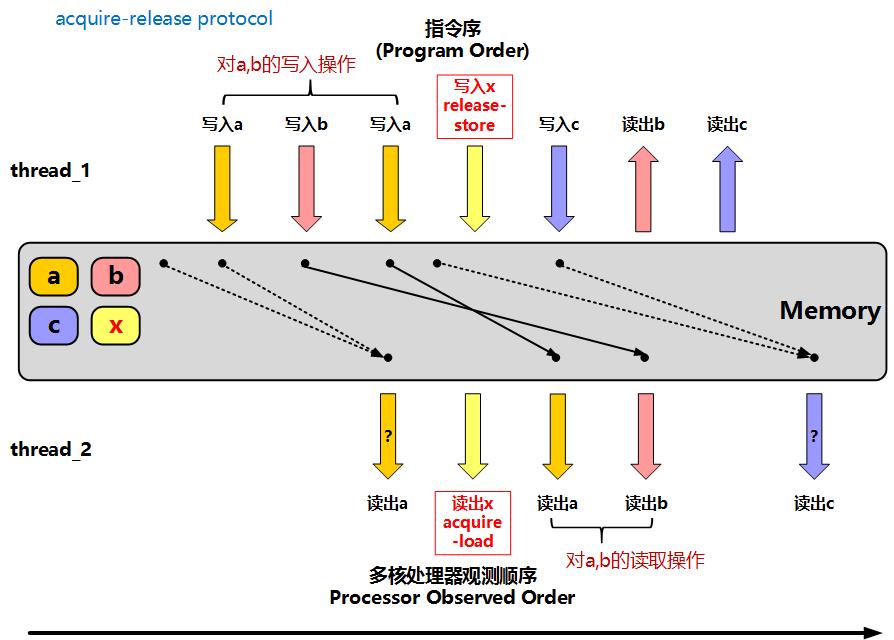
图中,thread_1执行写入x操作之前,先写了a、b变量,在thread_2执行读取x操作后,再去读取a、b的值,这是正确的操作。但是如果thread_2在读取x之前去读a变量,就没法保证读到的a变量是thread_1在写入x之前最后写入a的值。同时thread_2读取变量c的值,不一定是thread_1写入x后写入的c,因为这个写入c的操作允许被重排到写入x之前
memory_order_consume
这个内存屏障与memory_order_acquire的功能相似,而且大多数编译器并没有实现这个屏障,所以就不单独说了
memory_order_acq_rel
双向读写内存屏障,相当于结合了memory_order_release、memory_order_acquire。表示**线程中此屏障之前的的读写指令不能重排到屏障之后,屏障之后的读写指令也不能重排到屏障之前**。此时需要不同线程都是用**同一个原子变量**,且都是用memory_order_acq_rel
memory_order_seq_cst
最严格的内存屏障,顺序一致屏障。表示**线程中此屏障之前的的读写指令不能重排到屏障之后,屏障之后的读写指令也不能重排到屏障之前,并且两个相邻memory_order_seq_cst原子操作之间的其它操作(包括非原子变量操作),不能重排到这两个相邻操作之外**。memory_order_seq_cst比memory_order_acq_rel更强,memory_order_acq_rel的顺序保障,是要基于同一个原子变量的,也就是说,在这个原子变量之前的读写,不能重排到这个原子变量之后,同时这个原子变量之后的读写,也不能重排到这个原子变量之前。但是,如果两个线程基于memory_order_acq_rel使用了两个不同的原子变量x1, x2,那在x1之前的读写,重排到x2之后,是完全可能的,在x1之后的读写,重排到x2之前,也是被允许的。然而,如果两个原子变量x1,x2,是基于memory_order_seq_cst在操作,那么即使是x1之前的读写,也不能被重排到x2之后,x1之后的读写,也不能重排到x2之前,也就说,如果都用memory_order_seq_cst,那么程序代码顺序(Program Order)就将会是你在多个线程上都实际观察到的顺序(Observed Order)。(java只有这种memory order,通过java的关键字volatile来提供)。memory_order_acq_rel的操作针对同一个原子变量,而memory_order_seq_cst不限于同一个原子变量。
线程安全的单例
class Singleton
public:
static Singleton* GetInstance()
Singleton *tmp = instance_.load(std::memory_order_acquire);
if (!tmp)
std::lock_guard<std::mutex> lock(lock_);
tmp = instance_.load(std::memory_order_relaxed);
if (!tmp)
tmp = new Singleton();
instance_.store(tmp, std::memory_order_release);
return (Singleton*)instance_;
private:
static std::mutex lock_;
static std::atomic<Singleton*> instance_;
private:
Singleton() ;
virtual ~Singleton() ;
Singleton(const Singleton &) = delete;
Singleton& operator=(const Singleton &) = delete;
;
std::mutex Singleton::lock_;
std::atomic<Singleton*> Singleton::instance_ = nullptr;
原子操作配合memory_order_acquire、memory_order_release内存屏障,保证指令顺序不被打乱,来写出一个线程安全的双重检查单例。
但是实际上,**c++11**增加了一个重要的特性。就是多线程下局部静态变量的初始化由编译器来保证线程安全,只初始化一次,所以我们实际上写线程安全的单例可以这样:
static Singleton* GetInstance()
static Singleton instance;
return &instance;
两行代码,搞定~~,编译器通常也是用上面的双重检查逻辑来实现这个功能
volatile
说道c++多线程,volatile就很容易被提起,它的作用有:
1. 告诉编译器,这个变量是易变的,当编译器遇到这个变量的时候,只能从变量的内存地址中读取这个变量,不可以从寄存器读取
2. 告诉编译器不要将变量优化掉,保证这个指令一定会被执行
3. 两个包含volatile变量的指令,编译后不可以乱序(编译器屏障)。但是实际执行时CPU可能打乱顺序
volatile关键字只针对编译器,对CPU没有作用,所以关于volatile在多线程中的作用的结论是:
1. 不保证原子性
2. 不保障实际执行顺序
3. 不提供CPU内存屏障
所以如果做多线程开发,变量在内存中的可见性、原子性、CPU执行顺序,最终还是要依赖CPU内存屏障来支持的。但**java、c#**中的volatile关键字的内部实现中使用了CPU内存屏障(而且是是memory_order_seq_cst),所以java和c#多线程开发中volatile是有用的
线程安全的无锁数据结构
一般情况下,我们业务上的多线程开发中不直接使用内存屏障,而是乖乖使用锁。因为内存屏障使用的确很麻烦。内存屏障不属于加锁,所以很多时候用来做一些无锁编程,比如设计无锁数据结构。具体的实践可以参考《C++ Concurrency IN ACTION》,书中讲的非常详细
回到单例
关于的线程安全的双重检查单例,chromium浏览器内核源码中base库中有更加细致的实现,有兴趣的可以研究一下:https://source.chromium.org/chromium/chromium/src/+/master:base/lazy_instance_helpers.h?q=lazy_instance_helpers.h&ss=chromium%2Fchromium%2Fsrc
template <typename Type>
Type* GetOrCreateLazyPointer(subtle::AtomicWord* state,
Type* (*creator_func)(void*),
void* creator_arg,
void (*destructor)(void*),
void* destructor_arg)
DCHECK(state);
DCHECK(creator_func);
// If any bit in the created mask is true, the instance has already been
// fully constructed.
constexpr subtle::AtomicWord kLazyInstanceCreatedMask =
~internal::kLazyInstanceStateCreating;
// We will hopefully have fast access when the instance is already created.
// Since a thread sees |state| == 0 or kLazyInstanceStateCreating at most
// once, the load is taken out of NeedsLazyInstance() as a fast-path. The load
// has acquire memory ordering as a thread which sees |state| > creating needs
// to acquire visibility over the associated data. Pairing Release_Store is in
// CompleteLazyInstance().
subtle::AtomicWord instance = subtle::Acquire_Load(state);
if (!(instance & kLazyInstanceCreatedMask))
if (internal::NeedsLazyInstance(state))
// This thread won the race and is now responsible for creating the
// instance and storing it back into |state|.
instance =
reinterpret_cast<subtle::AtomicWord>((*creator_func)(creator_arg));
internal::CompleteLazyInstance(state, instance, destructor,
destructor_arg);
else
// This thread lost the race but now has visibility over the constructed
// instance (NeedsLazyInstance() doesn't return until the constructing
// thread releases the instance via CompleteLazyInstance()).
instance = subtle::Acquire_Load(state);
DCHECK(instance & kLazyInstanceCreatedMask);
return reinterpret_cast<Type*>(instance);
bool NeedsLazyInstance(subtle::AtomicWord* state)
// Try to create the instance, if we're the first, will go from 0 to
// kLazyInstanceStateCreating, otherwise we've already been beaten here.
// The memory access has no memory ordering as state 0 and
// kLazyInstanceStateCreating have no associated data (memory barriers are
// all about ordering of memory accesses to *associated* data).
if (subtle::NoBarrier_CompareAndSwap(state, 0, kLazyInstanceStateCreating) ==
0)
// Caller must create instance
return true;
// It's either in the process of being created, or already created. Spin.
// The load has acquire memory ordering as a thread which sees
// state_ == STATE_CREATED needs to acquire visibility over
// the associated data (buf_). Pairing Release_Store is in
// CompleteLazyInstance().
if (subtle::Acquire_Load(state) == kLazyInstanceStateCreating)
const base::TimeTicks start = base::TimeTicks::Now();
do
const base::TimeDelta elapsed = base::TimeTicks::Now() - start;
// Spin with YieldCurrentThread for at most one ms - this ensures maximum
// responsiveness. After that spin with Sleep(1ms) so that we don't burn
// excessive CPU time - this also avoids infinite loops due to priority
// inversions (https://crbug.com/797129).
if (elapsed < TimeDelta::FromMilliseconds(1))
PlatformThread::YieldCurrentThread();
else
PlatformThread::Sleep(TimeDelta::FromMilliseconds(1));
while (subtle::Acquire_Load(state) == kLazyInstanceStateCreating);
// Someone else created the instance.
return false;
void CompleteLazyInstance(subtle::AtomicWord* state,
subtle::AtomicWord new_instance,
void (*destructor)(void*),
void* destructor_arg)
// Instance is created, go from CREATING to CREATED (or reset it if
// |new_instance| is null). Releases visibility over |private_buf_| to
// readers. Pairing Acquire_Load is in NeedsLazyInstance().
subtle::Release_Store(state, new_instance);
// Make sure that the lazily instantiated object will get destroyed at exit.
if (new_instance && destructor)
AtExitManager::RegisterCallback(destructor, destructor_arg);
参考资料:
1. 《C++并发编程实战》(原名:C++ Concurrency IN ACTION, Anthony Williams)
1. 《 C++ and the Perils of Double-Checked Locking 》https://erdani.com/publications/DDJ_Jul_Aug_2004_revised.pdf
1. https://www.cnblogs.com/mataiyuan/p/13372374.html
1. https://www.cnblogs.com/aquester/p/10328479.html
1. https://www.dazhuanlan.com/2019/12/14/5df40323d6adf/
以上是关于c++:从单例到内存屏障的主要内容,如果未能解决你的问题,请参考以下文章