基于Spark技术的银行客户数据分析
Posted 不懂开发的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Spark技术的银行客户数据分析相关的知识,希望对你有一定的参考价值。
基于Spark技术的银行客户数据分析
申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计4672字,阅读大概需要3分钟
1. 实验室名称:
大数据实验教学系统
2. 实验项目名称:
案例:银行客户数据分析
一、业务场景
某银行积累有大量客户数据,现希望大数据分析团队使用Spark技术对这些数据进行分析,以期获得有价值的信息。
二、数据集说明
本案例用到的数据集说明如下:
数据集文件:/data/dataset/bank-full.csv
该数据集包含银行客户信息,其中部分字段的说明如下:
| 字段 | 定义 |
|---|---|
| age | 客户年龄 |
| job | 职业 |
| marital | 婚姻状况 |
| education | 受教育程度 |
| balance | 银行账户余额 |
三、操作步骤
阶段一、启动HDFS、Spark集群服务和zeppelin服务器
1、启动HDFS集群
在Linux终端窗口下,输入以下命令,启动HDFS集群:
1. $ start-dfs.sh
2、启动Spark集群
在Linux终端窗口下,输入以下命令,启动Spark集群:
1. $ cd /opt/spark
2. $ ./sbin/start-all.sh
3、启动zeppelin服务器
在Linux终端窗口下,输入以下命令,启动zeppelin服务器:
1. $ zeppelin-daemon.sh start
4、验证以上进程是否已启动
在Linux终端窗口下,输入以下命令,查看启动的服务进程:
1. $ jps
如果显示以下6个进程,则说明各项服务启动正常,可以继续下一阶段。
1. 2288 NameNode
2. 2402 DataNode
3. 2603 SecondaryNameNode
4. 2769 Master
5. 2891 Worker
6. 2984 ZeppelinServer
阶段二、准备案例中用到的数据集
1、将本案例要用到的数据集上传到HDFS文件系统的”/data/dataset/“目录下。在Linux终端窗口下,输入以下命令:
1. $ hdfs dfs -mkdir -p /data/dataset
2. $ hdfs dfs -put /data/dataset/bank-full.csv /data/dataset/
2、在Linux终端窗口下,输入以下命令,查看HDFS上是否已经上传了该数据集:
1. $ hdfs dfs -ls /data/dataset/
这时应该看到数据集文件bank-full.csv已经上传到了HDFS的”/data/dataset/“目录下。
阶段三、对数据集进行探索和分析
1、新建一个zeppelin notebook文件,并命名为bank_project。
2、加载数据集到RDD。在notebook单元格中,输入以下代码,加载数据集到RDD:
1. val filePath = "/data/dataset/bank-full.csv" // 定义要加载数据集的hdfs路径
2. val bankText = sc.textFile(filePath) // 读取数据集到rdd
3.
4. bankText.cache // 缓存rdd
同时按下Shift+Enter键,执行以上代码。
3、对数据集进行简单探索。在notebook单元格中,输入以下代码:
1. bankText.take(2).foreach(println)
同时按下Shift+Enter键,执行以上代码,输出内容如下:
“age”;”job”;”marital”;”education”;”default”;”balance”;”housing”;”loan”;”contact”;”day”;”month”;”duration”;”campaign”;”pdays”;”previous”;”poutcome”;”y”
58;”management”;”married”;”tertiary”;”no”;2143;”yes”;”no”;”unknown”;5;”may”;261;1;-1;0;”unknown”;”no”
由以上输出内容可以看出,原始的数据集中带有标题行。另外,除了我们关注的5个字段外,实际还包括了其他更多的字段。
4、数据提炼。我们需要对原始数据集进行处理,去掉标题行,并只提取所需要的5个字段。在notebook单元格中,输入以下代码:
1. // 定义case class类
2. case class Bank(age:Integer,job:String,marital:String,education:String,balance:Integer)
3.
4. // 拆分每一行,过滤掉第一行(以age开头的标题行),并映射到 Bank case class
5. val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\\"age\\"").map(s =>
6. Bank(s(0).replaceAll("\\"","").replaceAll(" ", "").toInt,
7. s(1).replaceAll("\\"",""),
8. s(2).replaceAll("\\"",""),
9. s(3).replaceAll("\\"",""),
10. s(5).replaceAll("\\"","").toInt)
11. )
同时按下Shift+Enter键,执行以上代码,输出内容如下:
defined class Bank
bank: org.apache.spark.rdd.RDD[Bank] = MapPartitionsRDD[4] at map at :36
由以上输出内容可以看出,经过转换以后,RDD中的内容变量了Bank类型的对象。
5、将band RDD转换为DataFrame。在notebook单元格中,输入以下代码:
1. val bankDF = bank.toDF()
同时按下Shift+Enter键,执行以上代码,输出内容如下:
bankDF: org.apache.spark.sql.DataFrame = [age: int, job: string … 3 more fields]
由以上输出内容可以看出,经过转换以后,我们获得了一个名为bankDF的DataFrame。
6、查看bankDF的数据和格式。在notebook单元格中,输入以下代码:
1. bankDF.show
同时按下Shift+Enter键,执行以上代码,输出内容如下:
由以上输出内容可以看出,在使用show方法显示DataFrame时,默认只显示前20行记录。
7、注册临时表,使用SQL进行查询。在notebook单元格中,输入以下代码:
1. bankDF.createOrReplaceTempView("bank_tb")
同时按下Shift+Enter键,执行以上代码,创建一个名为”bank_tb”的临时视图。
8、查看年龄小于30岁的客户信息。在notebook单元格中,输入以下代码:
1. spark.sql("select * from bank_tb where age<30").show
同时按下Shift+Enter键,执行以上代码,,输出内容如下:

9、输出DataFrame的Schema模式信息。在notebook单元格中,输入以下代码:
1. bankDF.printSchema
同时按下Shift+Enter键,执行以上代码,,输出内容如下:
root
|— age: integer (nullable = true)
|— job: string (nullable = true)
|— marital: string (nullable = true)
|— education: string (nullable = true)
|— balance: integer (nullable = true)
由以上输出内容可以看出,在转换为DataFrame时,Spark SQL自动推断数据类型,其中age和balance字段为integer整型,其他字段为string字符串类型。
10、查看不同年龄段的客户人数。在notebook单元格中,输入以下代码:
1. spark.sql("""select age,count(age) as total_ages
2. from bank_tb
3. where age<30
4. group by age
5. order by age""").show
同时按下Shift+Enter键,执行以上代码,输出内容如下:

11、查看不同年龄段的客户人数,并可视化展示。在notebook单元格中,输入以下代码:
1. %sql
2. select age,count(age) as total_ages
3. from bank_tb
4. where age<30
5. group by age
6. order by age
同时按下Shift+Enter键,执行以上代码,输出内容如下:
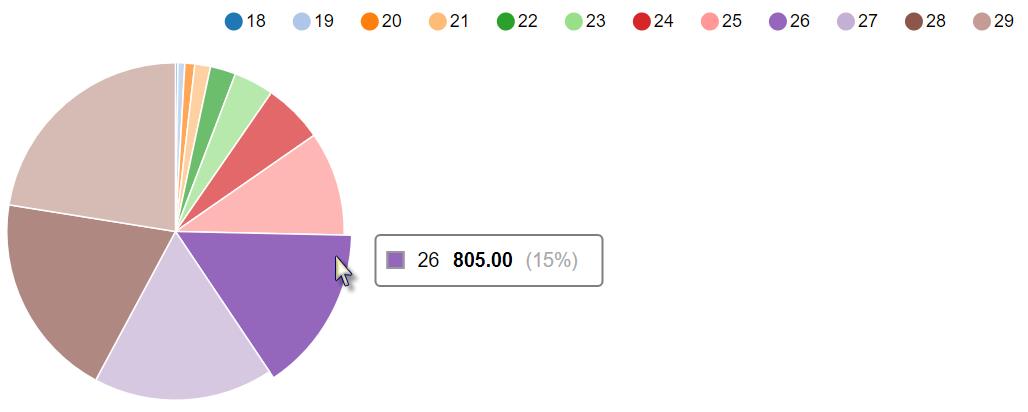
注意,在执行可视化时,一定要在单元格中的第一行指定”%sql”。在生成的可视化图上,将鼠标放在不同的比例部分,会出现相应的数字。
12、根据婚姻状况的不同显示对应的年龄分布,并可视化展示。在notebook单元格中,输入以下代码:
1. %sql
2. select age, count(1)
3. from bank_tb
4. where marital="$marital=single,single(未婚)|divorced(离婚)|married(已婚)"
5. group by age
6. order by age
同时按下Shift+Enter键,执行以上代码,输出内容如下:
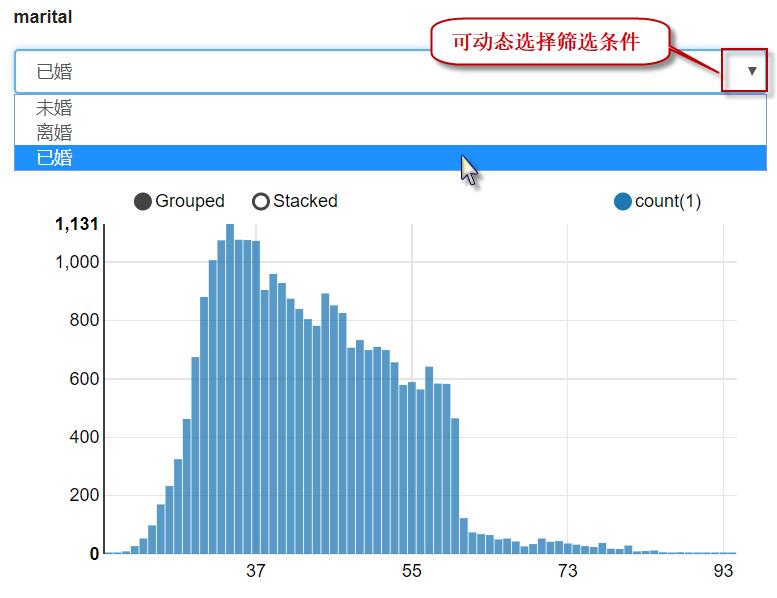
注意,在执行可视化时,一定要在单元格中的第一行指定”%sql”。在生成的可视化图上,可单击下拉框右侧的三角按钮选择婚姻类别,动态查看相应的结果。
阶段四、自行练习
1、使用本案例的数据集,查询客户中每种婚姻状况对应的人数,并可视化呈现。
2、使用本案例的数据集,查询不同年龄段客户的平均存款余额,并可高化呈现。

以上是关于基于Spark技术的银行客户数据分析的主要内容,如果未能解决你的问题,请参考以下文章