CV+Deep Learning——网络架构Pytorch复现系列——basenets(BackBones)
Posted 游客26024
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CV+Deep Learning——网络架构Pytorch复现系列——basenets(BackBones)相关的知识,希望对你有一定的参考价值。
引言此系列重点在于复现计算机视觉(分类、目标检测、语义分割)中深度学习各个经典的网络模型,以便初学者使用(深入浅出)!
代码都运行无误!!
首先复现深度学习经典网络模型(basenet)(就是家喻户晓的Backbone,但是我会对Backbone做一些改动,所以这个系列就不叫Backbone,叫basenet)这些网络大都是分类的经典网络(1.,2.,3.,4.,5.,6.,7.),目标检测的Backbone(8.,9.),有:
1.LeNet5(√)
2.VGG(√)
3.AlexNet(√)
4.ResNet(√)
5.GoogLeNet
5.MobileNet
6.ShuffleNet
7.EfficientNet
8.VovNet
9.DarkNet
...
注意:
a) 完整代码上传至我的github
https://github.com/HanXiaoyiGitHub/Simple-CV-Pytorch-master https://github.com/HanXiaoyiGitHub/Simple-CV-Pytorch-masterb) 编译环境设置为 (其实不用这个编译环境,你会调bug也行!)
https://github.com/HanXiaoyiGitHub/Simple-CV-Pytorch-masterb) 编译环境设置为 (其实不用这个编译环境,你会调bug也行!)
python == 3.9.12
torch == 1.11.0+cu113
torchvision== 0.11.0+cu113
torchaudio== 0.12.0+cu113
pycocotools == 2.0.4
numpy
Cython
matplotlib
opencv-python
tqdm
thopc) 分类数据集使用ImageNet或CIFAR10,其目录 (coco和voc用于目标检测和语义分割现在暂时用不到):
dataset path: /data/
data
|
|----coco----|----coco2017
|
|----cifar
|
|----ImageNet----|----ILSVRC2012
|
|----VOCdevkit
coco2017 path: /data/coco/coco2017
coco2017
|
|
|----annotations
|----train2017
|----test2017
|----val2017
voc path: /data/VOCdevkit
|
| |----Annotations
| |----ImageSets
|----VOC2007----|----JPEGImages
| |----SegmentationClass
| |----SegmentationObject
|
|
| |----Annotations
| |----ImageSets
|----VOC2012----|----JPEGImages
| |----SegmentationClass
| |----SegmentationObject
ILSVRC2012 path : /data/ImageNet/ILSVRC2012
|
|----train
|
|----val
cifar path: /data/cifar
|
|----cifar-10-batches-py
|
|----cifar-10-python.tar.gzd) 使用了amp混精度使gpu加速,若不知如何使用可参考如下链接:
所以需要在网络模型的forward函数前加入 @autocast(),并且又因为使用了1.4以上版本的torch,必须修改ReLu(inplace=False),Dropout(inplace=False),等等有inplace都设置为False。
e) 由于LeNet5、VGG16、AlexNet使用了全连接层不能修改图像的size,所以这些网络架构在图像预处理时图像的size就必须固定
f) 项目文件结构
使用的OS (Ubuntu 20.04),当然windows下也能运行,我运行过。有的文件夹用不上,先别管,我之后会讲。
project path: /data/PycharmProject/
Simple-CV-master path: /data/PycharmProject/Simple-CV-Pytorch-master
|
|----checkpoints ( resnet50-19c8e357.pth \\COCO_ResNet50.pth[RetinaNet]\\ VOC_ResNet50.pth[RetinaNet] )
|
| |----cifar.py ( null, I just use torchvision.datasets.ImageFolder )
| |----CIAR_labels.txt
| |----coco.py
| |----coco_eval.py
| |----coco_labels.txt
|----data----|----__init__.py
| |----config.py ( path )
| |----imagenet.py ( null, I just use torchvision.datasets.ImageFolder )
| |----ImageNet_labels.txt
| |----voc0712.py
| |----voc_eval.py
| |----voc_labels.txt
| |----crash_helmet.jpg
|----images----|----classification----|----sunflower.jpg
| | |----photocopier.jpg
| | |----automobile.jpg
| |
| |----detection----|----000001.jpg
| |----000001.xml
| |----000002.jpg
| |----000002.xml
| |----000003.jpg
| |----000003.xml
|
|----log(XXX[ detection or classification ]_XXX[ train or test or eval ].info.log)
|
| |----__init__.py
| |
| | |----__init.py
| |----anchor----|----RetinaNetAnchors.py
| |
| | |----lenet5.py
| | |----alexnet.py
| |----basenet----|----vgg.py
| | |----resnet.py
| |
| | |----DarkNetBackbone.py
| |----backbones----|----__init__.py ( Don't finish writing )
| | |----ResNetBackbone.py
| | |----VovNetBackbone.py
| |
| |
| |
|----models----|----heads----|----__init.py
| | |----RetinaNetHeads.py
| |
| | |----RetinaNetLoss.py
| |----losses----|----__init.py
| |
| | |----FPN.py
| |----necks----|----__init__.py
| | |-----FPN.txt
| |
| |----RetinaNet.py
|
|----results ( eg: detection ( VOC or COCO AP ) )
|
|----tensorboard ( Loss visualization )
|
|----tools |----eval.py
| |----classification----|----train.py
| | |----test.py
| |
| |
| |
| | |----eval_coco.py
| | |----eval_voc.py
| |----detection----|----test.py
| |----train.py
|
|
| |----AverageMeter.py
| |----BBoxTransform.py
| |----ClipBoxes.py
| |----Sampler.py
| |----iou.py
|----utils----|----__init__.py
| |----accuracy.py
| |----augmentations.py
| |----collate.py
| |----get_logger.py
| |----nms.py
| |----path.py
|
|----FolderOrganization.txt
|
|----main.py
|
|----README.md
|
|----requirements.txt1.LeNet5(size: 32 * 32 * 3)[1]
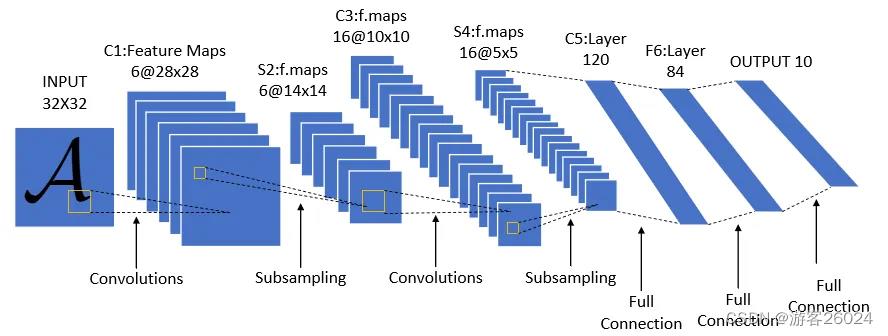
图 1.
如图 1.还原代码
加入nn.BatchNorm2d(),使其精度上升,当然为了完全复现,你们可以忽略掉nn.BatchNorm2d(),将其从代码中删除。
可根据数据集类别自行调整最后一层连接层的输出
from torch import nn
from torch.cuda.amp import autocast
class lenet5(nn.Module):
# cifar: 10, ImageNet: 1000
def __init__(self, num_classes=1000, init_weights=False):
super(lenet5, self).__init__()
self.num_classes = num_classes
self.layers = nn.Sequential(
# input:32 * 32 * 3 -> 28 * 28 * 6
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5, padding=0, stride=1, bias=False),
nn.BatchNorm2d(6),
nn.ReLU(),
# 28 * 28 * 6 -> 14 * 14 * 6
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# 14 * 14 * 6 -> 10 * 10 * 16
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, padding=0, stride=1, bias=False),
nn.BatchNorm2d(16),
nn.ReLU(),
# 10 * 10 * 16 -> 5 * 5 * 16
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120),
nn.Linear(120, 84))
self.classifier = nn.Linear(84, self.num_classes)
if init_weights:
self._initialize_weights()
@autocast()
def forward(self, x):
x = self.layers(x)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
2.AlexNet(Size: 224 * 224* 3)[2]

图 2.
如图 2.,若不是特别清楚,可参考下图 3.
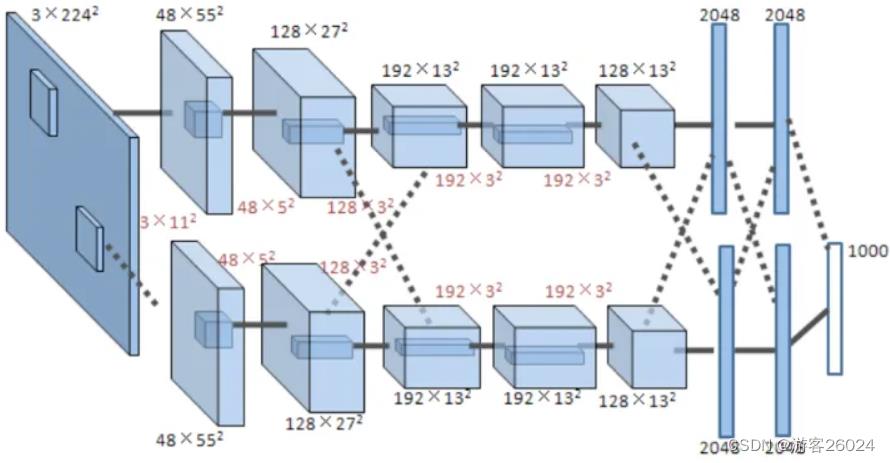
图 3.
将图 3. 转成图 4. ,这是因为之前的AlexNet是放在两张显卡(当年的计算力是不行的)上跑,现在的计算力能跟上了,可放在一张GPU上跑。
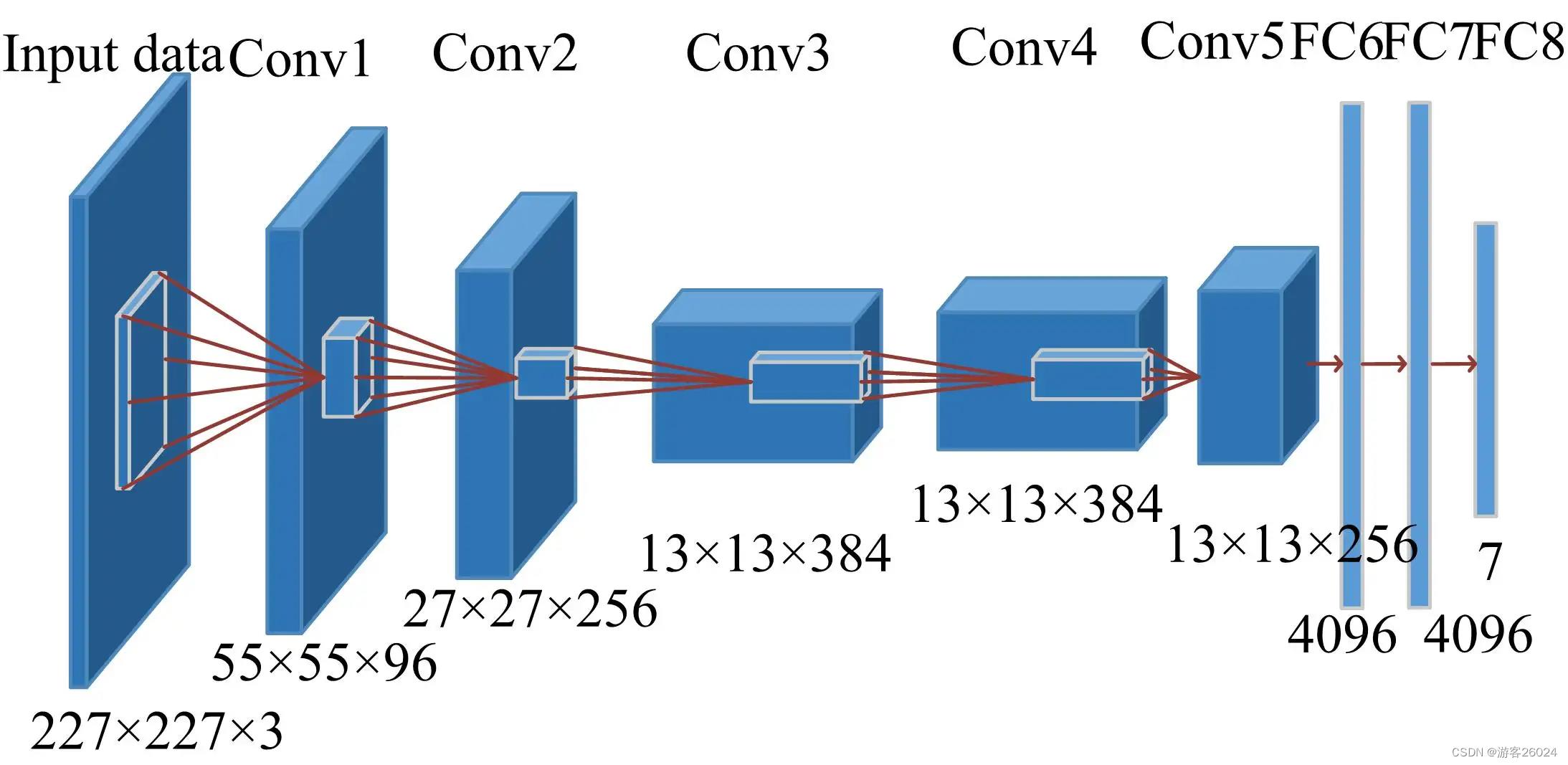
图 4.
可根据数据集类别自行调整最后一层连接层的输出
加入nn.BatchNorm2d(),使其精度上升,当然为了完全复现,你们可以忽略掉nn.BatchNorm2d(),将其从代码中删除。
import torch.nn as nn
from torch.cuda.amp import autocast
class alexnet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(alexnet, self).__init__()
self.layers = nn.Sequential(
# input: 224 * 224 * 3 -> 55 * 55 * (48*2)
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2, bias=False),
nn.BatchNorm2d(96),
nn.ReLU(),
# 55 * 55 * (48*2) -> 27 * 27 * (48*2)
nn.MaxPool2d(kernel_size=3, stride=2),
# 27 * 27 * (48*2) -> 27 * 27 * (128*2)
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
# 27 * 27 * (128*2) -> 13 * 13 * (128*2)
nn.MaxPool2d(kernel_size=3, stride=2),
# 13 * 13 * (128*2) -> 13 * 13 * (192*2)
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(384),
nn.ReLU(),
# 13 * 13 * (192*2) -> 13 * 13 * (192*2)
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(384),
nn.ReLU(),
# 13 * 13 * (192*2) -> 13 * 13 * (128*2)
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
# 13 * 13 * (128*2) -> 6 * 6 * (128*2)
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Dropout(0.5),
nn.Linear(6 * 6 * 128 * 2, 2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048, 2048),
nn.ReLU()
)
self.classifier = nn.Linear(2048, num_classes)
if init_weights:
self._initialize_weights()
@autocast()
def forward(self, x):
x = self.layers(x)
x = self.fc(x)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)3.VGG(Size: 224 * 224* 3)[3]

图 5.
如图 5.复现绿框中框出的网络架构,还原代码
我是看不下去精度那么差,所以我就把nn.BatchNorm2d(i)添加进去,并且做了迁移学习。
可根据数据集类别自行调整最后一层连接层的输出
import torch
from torch import nn
from utils.path import CheckPoints
from torch.cuda.amp import autocast
__all__ = [
'vgg11',
'vgg13',
'vgg16',
'vgg19',
]
# if your network is limited, you can download them, and put them into CheckPoints(my Project:Simple-CV-Pytorch-master/checkpoints/).
model_urls =
# 'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg11': '/vgg11-bbd30ac9.pth'.format(CheckPoints),
# 'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg13': '/vgg13-c768596a.pth'.format(CheckPoints),
# 'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg16': '/vgg16-397923af.pth'.format(CheckPoints),
# 'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg19': '/vgg19-dcbb9e9d.pth'.format(CheckPoints)
def vgg_(arch, num_classes, pretrained, init_weights=False, **kwargs):
cfg = cfgs["vgg" + arch]
features = make_features(cfg)
model = vgg(num_classes=num_classes, features=features, init_weights=init_weights, **kwargs)
# if you're training for the first time, no pretrained is required!
if pretrained:
pretrained_models = torch.load(model_urls["vgg" + arch])
# transfer learning
# if you want to train your own dataset
if arch == '11':
del pretrained_models['features.8.weight']
del pretrained_models['features.11.weight']
del pretrained_models['features.16.weight']
elif arch == '13':
del pretrained_models['features.7.weight']
del pretrained_models['features.10.weight']
del pretrained_models['features.15.weight']
del pretrained_models['features.17.weight']
del pretrained_models['features.22.weight']
elif arch == '16':
del pretrained_models['features.7.weight']
del pretrained_models['features.10.weight']
del pretrained_models['features.14.weight']
del pretrained_models['features.17.weight']
del pretrained_models['features.21.weight']
del pretrained_models['features.24.weight']
del pretrained_models['features.28.weight']
elif arch == '19':
del pretrained_models['features.7.weight']
del pretrained_models['features.10.weight']
del pretrained_models['features.14.weight']
del pretrained_models['features.21.weight']
del pretrained_models['features.23.weight']
del pretrained_models['features.28.weight']
del pretrained_models['features.34.weight']
else:
raise ValueError("Pretrained: unsupported VGG depth")
model.load_state_dict(pretrained_models, strict=False)
return model
def vgg11(num_classes, pretrained=False, init_weights=False, **kwargs):
return vgg_('11', num_classes, pretrained, init_weights, **kwargs)
def vgg13(num_classes, pretrained=False, init_weights=False, **kwargs):
return vgg_('13', num_classes, pretrained, init_weights, **kwargs)
def vgg16(num_classes, pretrained=False, init_weights=False, **kwargs):
return vgg_('16', num_classes, pretrained, init_weights, **kwargs)
def vgg19(num_classes, pretrained=False, init_weights=False, **kwargs):
return vgg_('19', num_classes, pretrained, init_weights, **kwargs)
class vgg(nn.Module):
# cifar: 10, ImageNet: 1000
def __init__(self, features, num_classes=1000, init_weights=False):
super(vgg, self).__init__()
self.num_classes = num_classes
self.features = features
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(7 * 7 * 512, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
)
self.classifier = nn.Linear(4096, self.num_classes)
if init_weights:
self._initialize_weights()
@autocast()
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
def make_features(cfgs: list):
layers = []
in_channels = 3
for i in cfgs:
if i == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, i, kernel_size=3, stride=1, padding=1, bias=False)
layers += [conv2d, nn.BatchNorm2d(i), nn.ReLU()]
in_channels = i
return nn.Sequential(*layers)
cfgs =
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
4.ResNet[4]

图 6.
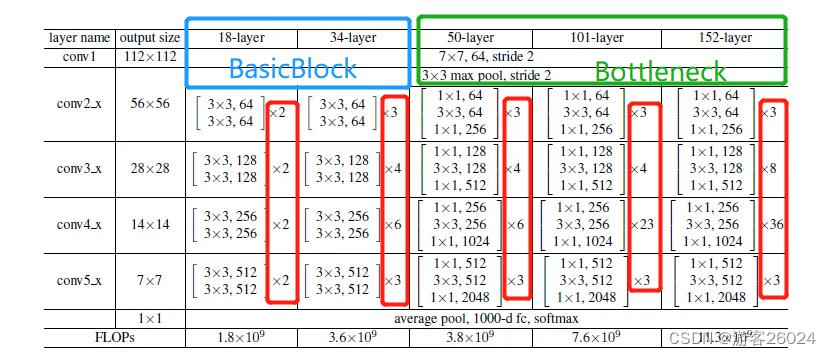
如图 6. 复现网络架构(ResNet18,ResNet34,ResNet50,ResNet101,ResNet152),还原代码
首先来看每个block如何复现?如图18-layer, 34-layer由下图 7. 绿框表示,50-layer, 101-layer, 152-layer由下图 7. 蓝框表示;

block: 18-layer, 34-layer
# 18-layer, 34-layer
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return outblock: 50-layer, 101-layer, 152-layer
# 50-layer, 101-layer, 152-layer
class Bottleneck(nn.Module):
"""
self.conv1(kernel_size=1,stride=2)
self.conv2(kernel_size=3,stride=1)
to
self.conv1(kernel_size=1,stride=1)
self.conv2(kernel_size=3,stride=2)
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3,
stride=stride, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels * self.expansion, kernel__size=1,
stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out整个ResNet模型的还原,先还原第一层卷积和最大池化层

class ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channels = 64
self.conv1 = nn.Conv2d(in_channels=3, out_channels=self.in_channels, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)之后的layer层,如图 8. 代码与图中的表示模块的对等关系
conv2_x -> self.layer1,
conv3_x -> self.layer2,
conv4_x -> self.layer3,
conv5_x -> self.layer4
...
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
...50-layer, 101-layer, 152-layer 复现虚线部分;18-layer,34-layer也是这样,就不展示了。
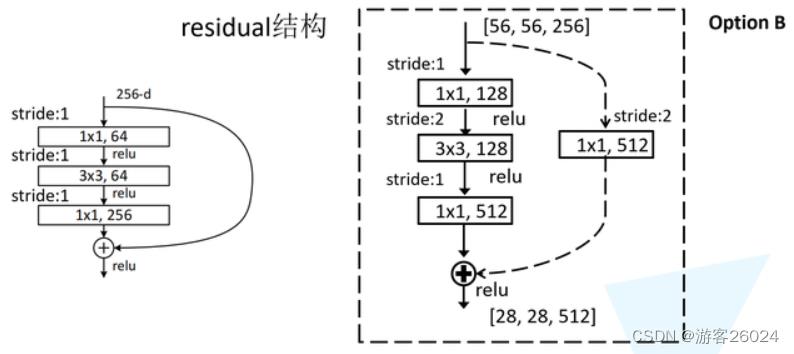
图 8.
def _make_layer(self, block, channels, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channels != channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=channels * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels * block.expansion)
)
...之后调用ResNet模型,选取合适的layer(18, 34, 50, 101, 152)
def resnet18(num_classes=1000, pretrained=False, include_top=True):
return resnet_('18', BasicBlock, [2, 2, 2, 2], num_classes, pretrained, include_top)
def resnet34(num_classes=1000, pretrained=False, include_top=True):
return resnet_('34', BasicBlock, [3, 4, 6, 3], num_classes, pretrained, include_top)
def resnet50(num_classes=1000, pretrained=False, include_top=True):
return resnet_('50', Bottleneck, [3, 4, 6, 3], num_classes, pretrained, include_top)
def resnet101(num_classes=1000, pretrained=False, include_top=True):
return resnet_('101', Bottleneck, [3, 4, 23, 3], num_classes, pretrained, include_top)
def resnet152(num_classes=1000, pretrained=False, include_top=True):
return resnet_('152', Bottleneck, [3, 8, 36, 3], num_classes, pretrained, include_top)完整代码
import torch
import torch.nn as nn
from utils.path import CheckPoints
from torch.cuda.amp import autocast
__all__ = [
'resnet18',
'resnet34',
'resnet50',
'resnet101',
'resnet152'
]
# if your network is limited, you can download them, and put them into CheckPoints(my Project:Simple-CV-Pytorch-master/checkpoints/).
model_urls =
# 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet18': '/resnet18-5c106cde.pth'.format(CheckPoints),
# 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet34': '/resnet34-333f7ec4.pth'.format(CheckPoints),
# 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet50': '/resnet50-19c8e357.pth'.format(CheckPoints),
# 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet101': '/resnet101-5d3b4d8f.pth'.format(CheckPoints),
# 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnet152': '/resnet152-b121ed2d.pth'.format(CheckPoints)
def resnet_(arch, block, block_num, num_classes, pretrained, include_top, **kwargs):
model = resnet(block=block, blocks_num=block_num, num_classes=num_classes, include_top=include_top, **kwargs)
# if you're training for the first time, no pretrained is required!
if pretrained:
# if you want to use cpu, you should modify map_loaction=torch.device("cpu")
pretrained_models = torch.load(model_urls["resnet" + arch], map_location=torch.device("cuda:0"))
# transfer learning
# if you want to train your own dataset
# del pretrained_models['module.classifier.bias']
model.load_state_dict(pretrained_models, strict=False)
return model
# 18-layer, 34-layer
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
@autocast()
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
# 50-layer, 101-layer, 152-layer
class Bottleneck(nn.Module):
"""
self.conv1(kernel_size=1,stride=2)
self.conv2(kernel_size=3,stride=1)
to
self.conv1(kernel_size=1,stride=1)
self.conv2(kernel_size=3,stride=2)
acc: up 0.5%
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3,
stride=stride, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels * self.expansion, kernel__size=1,
stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
@autocast()
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class resnet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
super(resnet, self).__init__()
self.include_top = include_top
self.in_channels = 64
self.conv1 = nn.Conv2d(in_channels=3, out_channels=self.in_channels, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.flatten = nn.Flatten()
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channels, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channels != channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=channels * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels * block.expansion)
)
layers = []
layers.append(block(in_channels=self.in_channels, out_channels=channels, downsample=downsample, stride=stride))
self.in_channels = channels * block.expansion
for _ in range(1, block_num):
layers.append(
block(in_channels=self.in_channels, out_channels=channels))
return nn.Sequential(*layers)
@autocast()
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = self.flatten(x)
x = self.fc(x)
return x
def resnet18(num_classes=1000, pretrained=False, include_top=True):
return resnet_('18', BasicBlock, [2, 2, 2, 2], num_classes, pretrained, include_top)
def resnet34(num_classes=1000, pretrained=False, include_top=True):
return resnet_('34', BasicBlock, [3, 4, 6, 3], num_classes, pretrained, include_top)
def resnet50(num_classes=1000, pretrained=False, include_top=True):
return resnet_('50', Bottleneck, [3, 4, 6, 3], num_classes, pretrained, include_top)
def resnet101(num_classes=1000, pretrained=False, include_top=True):
return resnet_('101', Bottleneck, [3, 4, 23, 3], num_classes, pretrained, include_top)
def resnet152(num_classes=1000, pretrained=False, include_top=True):
return resnet_('152', Bottleneck, [3, 8, 36, 3], num_classes, pretrained, include_top)一些配置文件
utils/path.py
import os.path
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(BASE_DIR)
# Gets home dir cross platform
# "/data/"
MyName = "PycharmProject"
Folder = "Simple-CV-Pytorch-master"
# Path to store checkpoint model
CheckPoints = 'checkpoints'
CheckPoints = os.path.join(BASE_DIR, MyName, Folder, CheckPoints)
# Path to store tensorboard load
tensorboard_log = 'tensorboard'
tensorboard_log = os.path.join(BASE_DIR, MyName, Folder, tensorboard_log)
# Path to save log
log = 'log'
log = os.path.join(BASE_DIR, MyName, Folder, log)
# Path to save classification train log
classification_train_log = 'classification_train'
# Path to save classification test log
classification_test_log = 'classification_test'
# Path to save classification eval log
classification_eval_log = 'classification_eval'
# Classification evaluate model path
classification_evaluate = None
# Images classification path
image_cls = 'automobile.jpg'
images_cls_path = 'images/classification'
images_cls_path = os.path.join(BASE_DIR, MyName, Folder, images_cls_path, image_cls)
# Data
DATAPATH = BASE_DIR
# ImageNet/ILSVRC2012
ImageNet = "ImageNet/ILSVRC2012"
ImageNet_Train_path = os.path.join(DATAPATH, ImageNet, 'train')
ImageNet_Eval_path = os.path.join(DATAPATH, ImageNet, 'val')
# CIFAR10
CIFAR = 'cifar'
CIFAR_path = os.path.join(DATAPATH, CIFAR)data/config.py
from utils import path
# Path to save log
log = path.log
# Path to save classification train log
classification_train_log = path.classification_train_log
# Path to save classification test log
classification_test_log = path.classification_test_log
# Path to save classification eval log
classification_eval_log = path.classification_eval_log
# Path to store checkpoint model
checkpoint_path = path.CheckPoints
# Classification evaluate model path
classification_evaluate = path.classification_evaluate
# Classification test images
images_cls_root = path.images_cls_path
# Path to save tensorboard
tensorboard_log = path.tensorboard_log训练代码
tools/classification/train.py
import os
import logging
import argparse
import warnings
warnings.filterwarnings('ignore')
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys.path.append(BASE_DIR)
import time
import torch
from data import *
import torchvision
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
from torchvision import transforms
from utils.accuracy import accuracy
from torch.utils.data import DataLoader
from utils.get_logger import get_logger
from models.basenets.lenet5 import lenet5
from models.basenets.alexnet import alexnet
from utils.AverageMeter import AverageMeter
from torch.cuda.amp import autocast, GradScaler
from models.basenets.vgg import vgg11, vgg13, vgg16, vgg19
from models.basenets.resnet import resnet18, resnet34, resnet50, resnet101, resnet152
def parse_args():
parser = argparse.ArgumentParser(description='PyTorch Classification Training')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset',
type=str,
default='CIFAR',
choices=['ImageNet', 'CIFAR'],
help='ImageNet, CIFAR')
parser.add_argument('--dataset_root',
type=str,
default=CIFAR_ROOT,
choices=[ImageNet_Train_ROOT, CIFAR_ROOT],
help='Dataset root directory path')
parser.add_argument('--basenet',
type=str,
default='lenet',
choices=['resnet', 'vgg', 'lenet', 'alexnet'],
help='Pretrained base model')
parser.add_argument('--depth',
type=int,
default=5,
help='BaseNet depth, including: LeNet of 5, AlexNet of 0, VGG of 11, 13, 16, 19, ResNet of 18, 34, 50, 101, 152')
parser.add_argument('--batch_size',
type=int,
default=32,
help='Batch size for training')
parser.add_argument('--resume',
type=str,
default=None,
help='Checkpoint state_dict file to resume training from')
parser.add_argument('--num_workers',
type=int,
default=8,
help='Number of workers user in dataloading')
parser.add_argument('--cuda',
type=str,
default=True,
help='Use CUDA to train model')
parser.add_argument('--momentum',
type=float,
default=0.9,
help='Momentum value for optim')
parser.add_argument('--gamma',
type=float,
default=0.1,
help='Gamma update for SGD')
parser.add_argument('--accumulation_steps',
type=int,
default=1,
help='Gradient acumulation steps')
parser.add_argument('--save_folder',
type=str,
default=config.checkpoint_path,
help='Directory for saving checkpoint models')
parser.add_argument('--tensorboard',
type=str,
default=False,
help='Use tensorboard for loss visualization')
parser.add_argument('--log_folder',
type=str,
default=config.log,
help='Log Folder')
parser.add_argument('--log_name',
type=str,
default=config.classification_train_log,
help='Log Name')
parser.add_argument('--tensorboard_log',
type=str,
default=config.tensorboard_log,
help='Use tensorboard for loss visualization')
parser.add_argument('--lr',
type=float,
default=1e-2,
help='learning rate')
parser.add_argument('--epochs',
type=int,
default=30,
help='Number of epochs')
parser.add_argument('--weight_decay',
type=float,
default=1e-4,
help='weight decay')
parser.add_argument('--milestones',
type=list,
default=[15, 20, 30],
help='Milestones')
parser.add_argument('--num_classes',
type=int,
default=10,
help='the number classes, like ImageNet:1000, cifar:10')
parser.add_argument('--image_size',
type=int,
default=32,
help='image size, like ImageNet:224, cifar:32')
parser.add_argument('--pretrained',
type=str,
default=True,
help='Models was pretrained')
parser.add_argument('--init_weights',
type=str,
default=False,
help='Init Weights')
return parser.parse_args()
args = parse_args()
# 1. Log
get_logger(args.log_folder, args.log_name)
logger = logging.getLogger(args.log_name)
# 2. Torch choose cuda or cpu
if torch.cuda.is_available():
if args.cuda:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if not args.cuda:
print("WARNING: It looks like you have a CUDA device, but you aren't using it" +
"\\n You can set the parameter of cuda to True.")
torch.set_default_tensor_type('torch.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if not os.path.exists(args.save_folder):
os.mkdir(args.save_folder)
def train():
# 3. Create SummaryWriter
if args.tensorboard:
from torch.utils.tensorboard import SummaryWriter
# tensorboard loss
writer = SummaryWriter(args.tensorboard_log)
# vgg16, alexnet and lenet5 need to resize image_size, because of fc.
if args.basenet == 'vgg' or args.basenet == 'alexnet':
args.image_size = 224
elif args.basenet == 'lenet':
args.image_size = 32
# 4. Ready dataset
if args.dataset == 'ImageNet':
if args.dataset_root == CIFAR_ROOT:
raise ValueError('Must specify dataset_root if specifying dataset ImageNet2012.')
elif os.path.exists(ImageNet_Train_ROOT) is None:
raise ValueError("WARNING: Using default ImageNet2012 dataset_root because " +
"--dataset_root was not specified.")
dataset = torchvision.datasets.ImageFolder(
root=args.dataset_root,
transform=torchvision.transforms.Compose([
transforms.Resize((args.image_size,
args.image_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]))
elif args.dataset == 'CIFAR':
if args.dataset_root == ImageNet_Train_ROOT:
raise ValueError('Must specify dataset_root if specifying dataset CIFAR10.')
elif args.dataset_root is None:
raise ValueError("Must provide --dataset_root when training on CIFAR10.")
dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True,
transform=torchvision.transforms.Compose([
transforms.Resize((args.image_size,
args.image_size)),
torchvision.transforms.ToTensor()]))
else:
raise ValueError('Dataset type not understood (must be ImageNet or CIFAR), exiting.')
dataloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=args.batch_size,
shuffle=True, num_workers=args.num_workers,
pin_memory=False, generator=torch.Generator(device='cuda'))
top1 = AverageMeter()
top5 = AverageMeter()
losses = AverageMeter()
# 5. Define train model
# Unfortunately, Lenet5 and Alexnet don't provide pretrianed Model.
if args.basenet == 'lenet':
if args.depth == 5:
model = lenet5(num_classes=args.num_classes,
init_weights=args.init_weights)
else:
raise ValueError('Unsupported LeNet depth!')
elif args.basenet == 'alexnet':
model = alexnet(num_classes=args.num_classes,
init_weights=args.init_weights)
elif args.basenet == 'vgg':
if args.depth == 11:
model = vgg11(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
elif args.depth == 13:
model = vgg13(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
elif args.depth == 16:
model = vgg16(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
elif args.depth == 19:
model = vgg19(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
else:
raise ValueError('Unsupported VGG depth!')
# Unfortunately for my resnet, there is no set init_weight, because I'm going to set object detection algorithm
elif args.basenet == 'resnet':
if args.depth == 18:
model = resnet18(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 34:
model = resnet34(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 50:
model = resnet50(pretrained=args.pretrained,
num_classes=args.num_classes) # False means the models was not trained
elif args.depth == 101:
model = resnet101(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 152:
model = resnet152(pretrained=args.pretrained,
num_classes=args.num_classes)
else:
raise ValueError('Unsupported ResNet depth!')
else:
raise ValueError('Unsupported model type!')
if args.cuda:
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6. Loading weights
if args.resume:
other, ext = os.path.splitext(args.resume)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
model_load = os.path.join(args.save_folder, args.resume)
model.load_state_dict(torch.load(model_load))
else:
print('Sorry only .pth and .pkl files supported.')
if args.init_weights:
# initialize newly added models' weights with xavier method
if args.basenet == 'resnet':
print("There is no set init_weight, because I'm going to set object detection algorithm.")
else:
print("Initializing weights...")
else:
print("Not Initializing weights...")
if args.pretrained:
if args.basenet == 'lenet' or args.basenet == 'alexnet':
print("There is no available pretrained model on the website. ")
else:
print("Models was pretrained...")
else:
print("Pretrained models is False...")
model.train()
iteration = 0
# 7. Optimizer
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum,
weight_decay=args.weight_decay)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.MultiStepLR(
optimizer, milestones=args.milestones, gamma=args.gamma)
scaler = GradScaler()
# 8. Length
iter_size = len(dataset) // args.batch_size
print("len(dataset): , iter_size: ".format(len(dataset), iter_size))
logger.info(f"args - args")
t0 = time.time()
# 9. Create batch iterator
for epoch in range(args.epochs):
t1 = time.time()
torch.cuda.empty_cache()
# 10. Load train data
for data in dataloader:
iteration += 1
images, targets = data
# 11. Backward
optimizer.zero_grad()
if args.cuda:
images, targets = images.cuda(), targets.cuda()
criterion = criterion.cuda()
# 12. Forward
with autocast():
outputs = model(images)
loss = criterion(outputs, targets)
loss = loss / args.accumulation_steps
if args.tensorboard:
writer.add_scalar("train_classification_loss", loss.item(), iteration)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# 13. Measure accuracy and record loss
acc1, acc5 = accuracy(outputs, targets, topk=(1, 5))
top1.update(acc1.item(), images.size(0))
top5.update(acc5.item(), images.size(0))
losses.update(loss.item(), images.size(0))
if iteration % 100 == 0:
logger.info(
f"- epoch: epoch, iteration: iteration, lr: optimizer.param_groups[0]['lr'], "
f"top1 acc: acc1.item():.2f%, top5 acc: acc5.item():.2f%, "
f"loss: loss.item():.3f, (losses.avg): losses.avg:3f "
)
scheduler.step(losses.avg)
t2 = time.time()
h_time = (t2 - t1) // 3600
m_time = ((t2 - t1) % 3600) // 60
s_time = ((t2 - t1) % 3600) % 60
print("epoch is finished, and the time is hmins".format(epoch, int(h_time), int(m_time), int(s_time)))
# 14. Save train model
if epoch != 0 and epoch % 10 == 0:
print('Saving state, iter:', epoch)
torch.save(model.state_dict(),
args.save_folder + '/' + args.dataset +
'_' + args.basenet + str(args.depth) + '_' + repr(epoch) + '.pth')
torch.save(model.state_dict(),
args.save_folder + '/' + args.dataset + "_" + args.basenet + str(args.depth) + '.pth')
if args.tensorboard:
writer.close()
t3 = time.time()
h = (t3 - t0) // 3600
m = ((t3 - t0) % 3600) // 60
s = ((t3 - t0) % 3600) % 60
print("The Finished Time is hms".format(int(h), int(m), int(s)))
return top1.avg, top5.avg, losses.avg
if __name__ == '__main__':
torch.multiprocessing.set_start_method('spawn')
logger.info("Program started")
top1, top5, loss = train()
print("top1 acc: , top5 acc: , loss:".format(top1, top5, loss))
logger.info("Done!")测试代码
tools/classification/test.py
import logging
import os
import argparse
import warnings
warnings.filterwarnings('ignore')
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys.path.append(BASE_DIR)
import time
from data import *
from PIL import Image
import torch.nn.parallel
from torchvision import transforms
from utils.get_logger import get_logger
from models.basenets.lenet5 import lenet5
from models.basenets.alexnet import alexnet
from models.basenets.vgg import vgg11, vgg13, vgg16, vgg19
from models.basenets.resnet import resnet18, resnet34, resnet50, resnet101, resnet152
def parse_args():
parser = argparse.ArgumentParser(description='PyTorch Classification Testing')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset',
type=str,
default='CIFAR',
choices=['ImageNet', 'CIFAR'],
help='ImageNet, CIFAR')
parser.add_argument('--images_root',
type=str,
default=config.images_cls_root,
help='Dataset root directory path')
parser.add_argument('--basenet',
type=str,
default='alexnet',
choices=['resnet', 'vgg', 'lenet', 'alexnet'],
help='Pretrained base model')
parser.add_argument('--depth',
type=int,
default=0,
help='BaseNet depth, including: LeNet of 5, AlexNet of 0, VGG of 11, 13, 16, 19, ResNet of 18, 34, 50, 101, 152')
parser.add_argument('--evaluate',
type=str,
default=config.classification_evaluate,
help='Checkpoint state_dict file to evaluate training from')
parser.add_argument('--save_folder',
type=str,
default=config.checkpoint_path,
help='Directory for saving checkpoint models')
parser.add_argument('--log_folder',
type=str,
default=config.log,
help='Log Folder')
parser.add_argument('--log_name',
type=str,
default=config.classification_test_log,
help='Log Name')
parser.add_argument('--cuda',
type=str,
default=True,
help='Use CUDA to train model')
parser.add_argument('--num_classes',
type=int,
default=10,
help='the number classes, like ImageNet:1000, cifar:10')
parser.add_argument('--image_size',
type=int,
default=32,
help='image size, like ImageNet:224, cifar:32')
parser.add_argument('--pretrained',
type=str,
default=False,
help='Models was pretrained')
return parser.parse_args()
args = parse_args()
# 1. Torch choose cuda or cpu
if torch.cuda.is_available():
if args.cuda:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if not args.cuda:
print("WARNING: It looks like you have a CUDA device, but you aren't using it" +
"\\n You can set the parameter of cuda to True.")
torch.set_default_tensor_type('torch.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if not os.path.exists(args.save_folder):
os.mkdir(args.save_folder)
# 2. Log
get_logger(args.log_folder, args.log_name)
logger = logging.getLogger(args.log_name)
def get_label_file(filename):
if not os.path.exists(filename):
print("The dataset label.txt is empty, We need to create a new one.")
os.mkdir(filename)
return filename
def dataset_labels_results(filename, output):
filename = os.path.join(BASE_DIR, 'data', filename + '_labels.txt')
get_label_file(filename=filename)
with open(file=filename, mode='r') as f:
dict = f.readlines()
output = output.cpu().numpy()
output = output[0]
output = dict[output]
f.close()
return output
def test():
# vgg16, alexnet and lenet5 need to resize image_size, because of fc.
if args.basenet == 'vgg' or args.basenet == 'alexnet':
args.image_size = 224
elif args.basenet == 'lenet':
args.image_size = 32
# 3. Ready image
if args.images_root is None:
raise ValueError("The images is None, you should load image!")
image = Image.open(args.images_root)
transform = transforms.Compose([
transforms.Resize((args.image_size,
args.image_size)),
transforms.ToTensor()])
image = transform(image)
image = image.reshape(1, 3, args.image_size, args.image_size)
# 4. Define to train mode
if args.basenet == 'lenet':
if args.depth == 5:
model = lenet5(num_classes=args.num_classes)
else:
raise ValueError('Unsupported LeNet depth!')
elif args.basenet == 'alexnet':
model = alexnet(num_classes=args.num_classes)
elif args.basenet == 'vgg':
if args.depth == 11:
model = vgg11(pretrained=args.pretrained, num_classes=args.num_classes)
elif args.depth == 13:
model = vgg13(pretrained=args.pretrained, num_classes=args.num_classes)
elif args.depth == 16:
model = vgg16(pretrained=args.pretrained, num_classes=args.num_classes)
elif args.depth == 19:
model = vgg19(pretrained=args.pretrained, num_classes=args.num_classes)
else:
raise ValueError('Unsupported VGG depth!')
elif args.basenet == 'resnet':
if args.depth == 18:
model = resnet18(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 34:
model = resnet34(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 50:
model = resnet50(pretrained=args.pretrained,
num_classes=args.num_classes) # False means the models is not trained
elif args.depth == 101:
model = resnet101(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 152:
model = resnet152(pretrained=args.pretrained,
num_classes=args.num_classes)
else:
raise ValueError('Unsupported ResNet depth!')
else:
raise ValueError('Unsupported model type!')
if args.cuda:
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 5. Loading model
if args.evaluate:
other, ext = os.path.splitext(args.evaluate)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
model_evaluate_load = os.path.join(args.save_folder, args.evaluate)
model.load_state_dict(torch.load(model_evaluate_load))
else:
print('Sorry only .pth and .pkl files supported.')
elif args.evaluate is None:
print("Sorry, you should load weights! ")
model.eval()
# 6. print
logger.info(f"args - args")
# 7. Test
以上是关于CV+Deep Learning——网络架构Pytorch复现系列——basenets(BackBones)的主要内容,如果未能解决你的问题,请参考以下文章