论文笔记:Universal Value Function Approximators
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记:Universal Value Function Approximators相关的知识,希望对你有一定的参考价值。
ICML 2015
1 介绍
这篇paper提出了UVFA(universal value function approximators),这是根据state(其他的value function也有的部分) 和goal(其他的value function没有的部分)来估计期望收益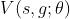
学习UVFA的挑战在于,一般来说agent只会看到很小一部分的(s,g)组合,不可能遍历到所有的state-goal对。如果用监督学习来训练
,那么也很有可能因为数据量不足而欠拟合,成为一个困难的回归问题。
这里UVFA使用了类似于矩阵分解的方法,将数据看作一个稀疏矩阵,每一行是一个观测到的state s,每一列是一个观测到的目标 g。然后将矩阵分解成状态embedding Φ(s)和目标embedding φ(g)。
——>于是可以分别学习从state到Φ(s);goal到φ(g)的非线性mapping
2 模型部分

two-stream architecture可以很好地学习到state和goal之间的共同结构
- 在很多情况下,goal都可以定义成state的形式/state的组合,
 。因而Φ和φ之间应该有一些可以共享的feature。
。因而Φ和φ之间应该有一些可以共享的feature。
- 这篇论文在MLP Φ和φ中,前几层的参数是共享的,所以state和goal共同的feature就能被学习到了
- ——>partially symmetric architecture
- 在有些情况下,UVFA可能是对称的
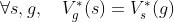
- 比如计算state s 和goal g之间距离的UVFA
- 此时我们可以令Φ=φ,h是一个对称的算子(比如点积)
- ——>symmetric architecture
2.1 监督学习UVFA
2.1.1 端到端学习
通过一个合适的loss function(比如MSE  )+梯度下降实现
)+梯度下降实现
2.1.2 two-stage 学习
- stage1:将V*(g)放到一个矩阵中,行表示state,列表示goal。进行矩阵分解,得到
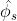 和
和 【图1 第三张图的右半部分】
【图1 第三张图的右半部分】 - stage2:将和作为ground-truth,学习Φs和φg 【图1 第三张图的左半部分】
2.2 强化学习UVFA
强化学习的话,就没有ground-truth V*(g)了,得通过一些方式求得Q-value
文中使用一种Horde 架构的方式可以产生不同目标对应的Q-value,那篇paper没有看,不过用bootstriping(TD)的话,结果上来说是差不多的【TD的话会稍微不稳定一些】

【注意一点:具体这个goal是怎么取的,文章中还是没说】
【到第10步,Q-value算出来之后,和强化学习就没太大的关系了,后面几步就是矩阵分解+两个embedding network的training】
以上是关于论文笔记:Universal Value Function Approximators的主要内容,如果未能解决你的问题,请参考以下文章