Day651.NoSQL与RDBMS合理搭配问题 -Java业务开发常见错误
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day651.NoSQL与RDBMS合理搭配问题 -Java业务开发常见错误相关的知识,希望对你有一定的参考价值。
NoSQL与RDBMS合理搭配问题
Hello,阿昌来也!今天学习分享记录的关于Nosql数据库和mysql数据库的一系列对比,架构安排,发挥出每种数据库的优势案例。
近几年,各种非关系型数据库,也就是 NoSQL 发展迅猛,在项目中也非常常见。其中不乏一些使用上的极端情况,比如直接把关系型数据库(RDBMS)全部替换为 NoSQL,或是在不合适的场景下错误地使用 NoSQL。
其实,每种 NoSQL 的特点不同,都有其要着重解决的某一方面的问题。因此,我们在使用 NoSQL 的时候,要尽量让它去处理擅长的场景,否则不但发挥不出它的功能和优势,还可能会导致性能问题。
NoSQL 一般可以分为缓存数据库、时间序列数据库、全文搜索数据库、文档数据库、`图数据库等。
这次,缓存数据库 Redis、时间序列数据库 InfluxDB、全文搜索数据库 ElasticSearch 为例,通过一些测试案例,和聊聊这些常见 NoSQL 的特点,以及它们擅长和不擅长的地方。
最后,我也还会和你说说 NoSQL 如何与 RDBMS 相辅相成,来构成一套可以应对高并发的复合数据库体系。
一、Redis vs MySQL
Redis 是一款设计简洁的缓存数据库,数据都保存在内存中,所以读写单一 Key 的性能非常高。我们来做一个简单测试,分别填充 10 万条数据到 Redis 和 MySQL 中。
MySQL 中的 name 字段做了索引,相当于 Redis 的 Key,data 字段为 100 字节的数据,相当于 Redis 的 Value:
@SpringBootApplication
@Slf4j
public class CommonMistakesApplication
//模拟10万条数据存到Redis和MySQL
public static final int ROWS = 100000;
public static final String PAYLOAD = IntStream.rangeClosed(1, 100).mapToObj(__ -> "a").collect(Collectors.joining(""));
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private StandardEnvironment standardEnvironment;
public static void main(String[] args)
SpringApplication.run(CommonMistakesApplication.class, args);
@PostConstruct
public void init()
//使用-Dspring.profiles.active=init启动程序进行初始化
if (Arrays.stream(standardEnvironment.getActiveProfiles()).anyMatch(s -> s.equalsIgnoreCase("init")))
initRedis();
initMySQL();
//填充数据到MySQL
private void initMySQL()
//删除表
jdbcTemplate.execute("DROP TABLE IF EXISTS `r`;");
//新建表,name字段做了索引
jdbcTemplate.execute("CREATE TABLE `r` (\\n" +
" `id` bigint(20) NOT NULL AUTO_INCREMENT,\\n" +
" `data` varchar(2000) NOT NULL,\\n" +
" `name` varchar(20) NOT NULL,\\n" +
" PRIMARY KEY (`id`),\\n" +
" KEY `name` (`name`) USING BTREE\\n" +
") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;");
//批量插入数据
String sql = "INSERT INTO `r` (`data`,`name`) VALUES (?,?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter()
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException
preparedStatement.setString(1, PAYLOAD);
preparedStatement.setString(2, "item" + i);
@Override
public int getBatchSize()
return ROWS;
);
log.info("init mysql finished with count ", jdbcTemplate.queryForObject("SELECT COUNT(*) FROM `r`", Long.class));
//填充数据到Redis
private void initRedis()
IntStream.rangeClosed(1, ROWS).forEach(i -> stringRedisTemplate.opsForValue().set("item" + i, PAYLOAD));
log.info("init redis finished with count ", stringRedisTemplate.keys("item*"));
启动程序后,输出了如下日志,数据全部填充完毕:
[14:22:47.195] [main] [INFO ] [o.g.t.c.n.r.CommonMistakesApplication:80 ] - init redis finished with count 100000
[14:22:50.030] [main] [INFO ] [o.g.t.c.n.r.CommonMistakesApplication:74 ] - init mysql finished with count 100000
然后,比较一下从 MySQL 和 Redis 随机读取单条数据的性能。“公平”起见,像 Redis 那样,我们使用 MySQL 时也根据 Key 来查 Value,也就是根据 name 字段来查 data 字段,并且我们给 name 字段做了索引:
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@GetMapping("redis")
public void redis()
//使用随机的Key来查询Value,结果应该等于PAYLOAD
Assert.assertTrue(stringRedisTemplate.opsForValue().get("item" + (ThreadLocalRandom.current().nextInt(CommonMistakesApplication.ROWS) + 1)).equals(CommonMistakesApplication.PAYLOAD));
@GetMapping("mysql")
public void mysql()
//根据随机name来查data,name字段有索引,结果应该等于PAYLOAD
Assert.assertTrue(jdbcTemplate.queryForObject("SELECT data FROM `r` WHERE name=?", new Object[]("item" + (ThreadLocalRandom.current().nextInt(CommonMistakesApplication.ROWS) + 1)), String.class)
.equals(CommonMistakesApplication.PAYLOAD));
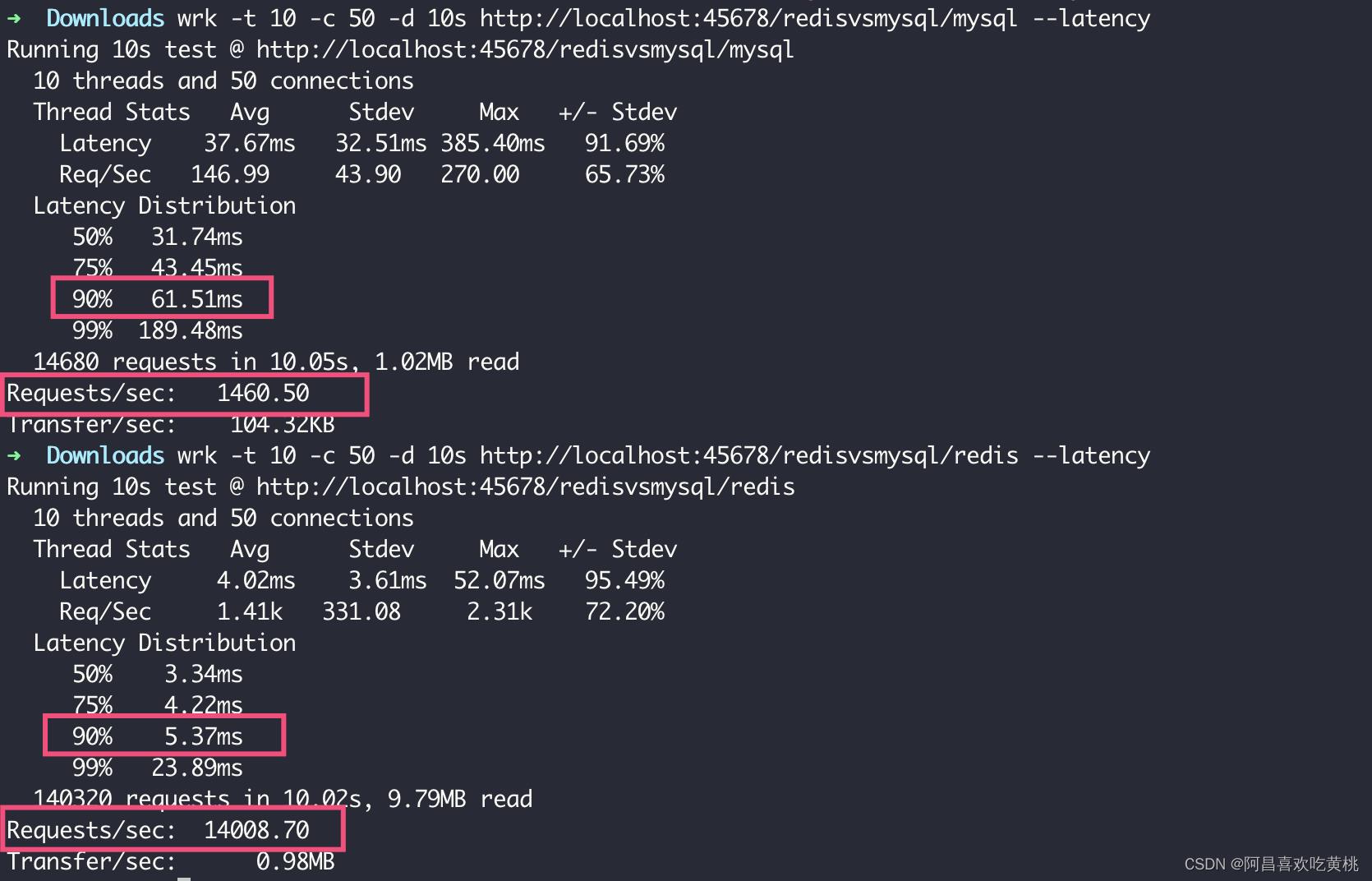
在我的电脑上,使用 wrk 加 10 个线程 50 个并发连接做压测。可以看到,MySQL 90% 的请求需要 61ms,QPS 为 1460;而 Redis 90% 的请求在 5ms 左右,QPS 达到了 14008,几乎是 MySQL 的十倍:
但 Redis 薄弱的地方是,不擅长做 Key 的搜索。对 MySQL,我们可以使用 LIKE 操作前匹配走 B+ 树索引实现快速搜索;
但对 Redis,我们使用 Keys 命令对 Key 的搜索,其实相当于在 MySQL 里做全表扫描。我写一段代码来对比一下性能:
@GetMapping("redis2")
public void redis2()
Assert.assertTrue(stringRedisTemplate.keys("item71*").size() == 1111);
@GetMapping("mysql2")
public void mysql2()
Assert.assertTrue(jdbcTemplate.queryForList("SELECT name FROM `r` WHERE name LIKE 'item71%'", String.class).size() == 1111);
可以看到,在 QPS 方面,MySQL 的 QPS 达到了 Redis 的 157 倍;在延迟方面,MySQL 的延迟只有 Redis 的十分之一。
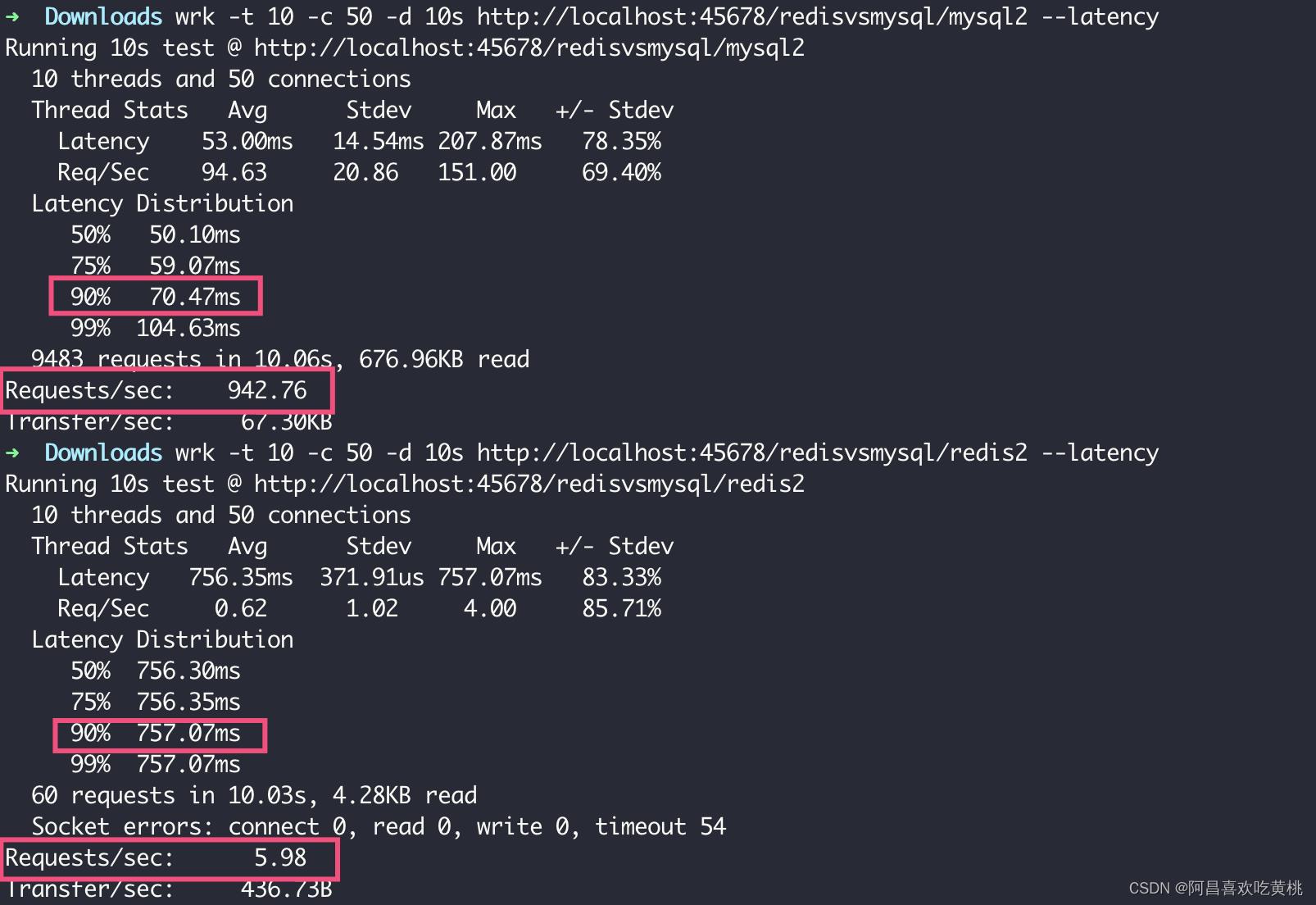
Redis 慢的原因有两个:
- Redis 的 Keys 命令是 O(n) 时间复杂度。如果数据库中 Key 的数量很多,就会非常慢。
- Redis 是单线程的,对于慢的命令如果有并发,串行执行就会非常耗时。
一般而言,我们使用 Redis 都是针对某一个 Key 来使用,而不能在业务代码中使用 Keys 命令从 Redis 中“搜索数据”,因为这不是 Redis 的擅长。对于 Key 的搜索,我们可以先通过关系型数据库进行,然后再从 Redis 存取数据(如果实在需要搜索 Key 可以使用 SCAN 命令)。在生产环境中,我们一般也会配置 Redis 禁用类似 Keys 这种比较危险的命令,你可以参考这里。
总结一下,正如“缓存设计”一讲中提到的,对于业务开发来说,大多数业务场景下 Redis 是作为关系型数据库的辅助用于缓存的,我们一般不会把它当作数据库独立使用。
此外值得一提的是,Redis 提供了丰富的数据结构(Set、SortedSet、Hash、List),并围绕这些数据结构提供了丰富的 API。如果我们好好利用这个特点的话,可以直接在 Redis 中完成一部分服务端计算,避免“读取缓存 -> 计算数据 -> 保存缓存”三部曲中的读取和保存缓存的开销,进一步提高性能。
二、InfluxDB vs MySQL
InfluxDB 是一款优秀的时序数据库。在“之前”记录过,我们就是使用 InfluxDB 来做的 Metrics 打点。
时序数据库的优势,在于处理指标数据的聚合,并且读写效率非常高。
同样的,我们使用一些测试来对比下 InfluxDB 和 MySQL 的性能。在如下代码中,我们分别填充了 1000 万条数据到 MySQL 和 InfluxDB 中。其中,每条数据只有 ID、时间戳、10000 以内的随机值这 3 列信息,对于 MySQL 我们把时间戳列做了索引:
@SpringBootApplication
@Slf4j
public class CommonMistakesApplication
public static void main(String[] args)
SpringApplication.run(CommonMistakesApplication.class, args);
//测试数据量
public static final int ROWS = 10000000;
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private StandardEnvironment standardEnvironment;
@PostConstruct
public void init()
//使用-Dspring.profiles.active=init启动程序进行初始化
if (Arrays.stream(standardEnvironment.getActiveProfiles()).anyMatch(s -> s.equalsIgnoreCase("init")))
initInfluxDB();
initMySQL();
//初始化MySQL
private void initMySQL()
long begin = System.currentTimeMillis();
jdbcTemplate.execute("DROP TABLE IF EXISTS `m`;");
//只有ID、值和时间戳三列
jdbcTemplate.execute("CREATE TABLE `m` (\\n" +
" `id` bigint(20) NOT NULL AUTO_INCREMENT,\\n" +
" `value` bigint NOT NULL,\\n" +
" `time` timestamp NOT NULL,\\n" +
" PRIMARY KEY (`id`),\\n" +
" KEY `time` (`time`) USING BTREE\\n" +
") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;");
String sql = "INSERT INTO `m` (`value`,`time`) VALUES (?,?)";
//批量插入数据
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter()
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException
preparedStatement.setLong(1, ThreadLocalRandom.current().nextInt(10000));
preparedStatement.setTimestamp(2, Timestamp.valueOf(LocalDateTime.now().minusSeconds(5 * i)));
@Override
public int getBatchSize()
return ROWS;
);
log.info("init mysql finished with count took ms", jdbcTemplate.queryForObject("SELECT COUNT(*) FROM `m`", Long.class), System.currentTimeMillis()-begin);
//初始化InfluxDB
private void initInfluxDB()
long begin = System.currentTimeMillis();
OkHttpClient.Builder okHttpClientBuilder = new OkHttpClient().newBuilder()
.connectTimeout(1, TimeUnit.SECONDS)
.readTimeout(10, TimeUnit.SECONDS)
.writeTimeout(10, TimeUnit.SECONDS);
try (InfluxDB influxDB = InfluxDBFactory.connect("http://127.0.0.1:8086", "root", "root", okHttpClientBuilder))
String db = "performance";
influxDB.query(new Query("DROP DATABASE " + db));
influxDB.query(new Query("CREATE DATABASE " + db));
//设置数据库
influxDB.setDatabase(db);
//批量插入,10000条数据刷一次,或1秒刷一次
influxDB.enableBatch(BatchOptions.DEFAULTS.actions(10000).flushDuration(1000));
IntStream.rangeClosed(1, ROWS).mapToObj(i -> Point
.measurement("m")
.addField("value", ThreadLocalRandom.current().nextInt(10000))
.time(LocalDateTime.now().minusSeconds(5 * i).toInstant(ZoneOffset.UTC).toEpochMilli(), TimeUnit.MILLISECONDS).build())
.forEach(influxDB::write);
influxDB.flush();
log.info("init influxdb finished with count took ms", influxDB.query(new Query("SELECT COUNT(*) FROM m")).getResults().get(0).getSeries().get(0).getValues().get(0).get(1), System.currentTimeMillis()-begin);
启动后,程序输出了如下日志:
[16:08:25.062] [main] [INFO ] [o.g.t.c.n.i.CommonMistakesApplication:104 ] - init influxdb finished with count 1.0E7 took 54280ms
[16:11:50.462] [main] [INFO ] [o.g.t.c.n.i.CommonMistakesApplication:80 ] - init mysql finished with count 10000000 took 205394ms
InfluxDB 批量插入 1000 万条数据仅用了 54 秒,相当于每秒插入 18 万条数据,速度相当快;
MySQL 的批量插入,速度也挺快达到了每秒 4.8 万。
接下来,我们测试一下。对这 1000 万数据进行一个统计,查询最近 60 天的数据,按照 1 小时的时间粒度聚合,统计 value 列的最大值、最小值和平均值,并将统计结果绘制成曲线图:
@Autowired
private JdbcTemplate jdbcTemplate;
@GetMapping("mysql")
public void mysql()
long begin = System.currentTimeMillis();
//使用SQL从MySQL查询,按照小时分组
Object result = jdbcTemplate.queryForList("SELECT date_format(time,'%Y%m%d%H'),max(value),min(value),avg(value) FROM m WHERE time>now()- INTERVAL 60 DAY GROUP BY date_format(time,'%Y%m%d%H')");
log.info("took ms result ", System.currentTimeMillis() - begin, result);
@GetMapping("influxdb")
public void influxdb()
long begin = System.currentTimeMillis();
try (InfluxDB influxDB = InfluxDBFactory.connect("http://127.0.0.1:8086", "root", "root"))
//切换数据库
influxDB.setDatabase("performance");
//InfluxDB的查询语法InfluxQL类似SQL
Object result = influxDB.query(new Query("SELECT MEAN(value),MIN(value),MAX(value) FROM m WHERE time > now() - 60d GROUP BY TIME(1h)"));
log.info("took ms result ", System.currentTimeMillis() - begin, result);
因为数据量非常大,单次查询就已经很慢了,所以这次我们不进行压测。分别调用两个接口,可以看到 MySQL 查询一次耗时 29 秒左右,而 InfluxDB 耗时 980ms:
[16:19:26.562] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.n.i.PerformanceController:31 ] - took 28919 ms result [date_format(time,'%Y%m%d%H')=2019121308, max(value)=9993, min(value)=4, avg(value)=5129.5639, date_format(time,'%Y%m%d%H')=2019121309, max(value)=9990, min(value)=12, avg(value)=4856.0556, date_format(time,'%Y%m%d%H')=2019121310, max(value)=9998, min(value)=8, avg以上是关于Day651.NoSQL与RDBMS合理搭配问题 -Java业务开发常见错误的主要内容,如果未能解决你的问题,请参考以下文章