Pandas中to_datetime()转换时间序列函数一文详解
Posted fanstuck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas中to_datetime()转换时间序列函数一文详解相关的知识,希望对你有一定的参考价值。
前言
由于在Pandas中经常要处理到时间序列数据,需要把一些object或者是字符、整型等某列进行转换为pandas可识别的datetime时间类型数据,方便时间的运算等操作。基于前两篇文章的基础:
一文速学-Pandas中DataFrame转换为时间格式数据与处理
在这两篇文章中基本把pandas操作时间类型数据的一些常规操作都有提及和展示,作为重要相关函数to_datetime(),该函数参数值得单独拿出来讲一讲,可以省去很多转换之后的BUG错误。
目录
一、基本语法与功能
基本语法:
pandas.to_datetime( arg,
errors='raise',
dayfirst=False,
yearfirst=False,
utc=None,
format=None,
exact=True,
unit=None,
infer_datetime_format=False,
origin='unix',
cache=True)基本功能:
该函数将一个标量,数组,Series或者是DataFrame/字典类型的数据转换为pandas中datetime类型的时间类型数据。
若是直接使用该函数不使用它的其他参数功能:
import pandas as pd
from datetime import datetime
import numpy as np
df_csv=pd.read_csv('file.csv')
df_csv['collect_date']=pd.to_datetime(df_csv['collect_date'])
可以把()内的DataFrame和Series、array等转换为datetime数据类型:
collect_date datetime64[ns]
二、参数说明和代码演示
| Parameters: | arg : integer, float, string, datetime, list, tuple, 1-d array, Series
errors : ‘ignore’, ‘raise’, ‘coerce’, default ‘raise’
dayfirst : boolean, default False
yearfirst : boolean, default False
utc : boolean, default None
box : boolean, default True
format : string, default None
exact : boolean, True by default
unit : string, default ‘ns’
infer_datetime_format : boolean, default False
origin : scalar, default is ‘unix’
cache : boolean, default False
|
|---|---|
| Returns: | ret : datetime if parsing succeeded.
|
上述是官方文档:pandas.to_datetime
首先我们将逐个了解每个参数的功能和作用,之后再进行实例使用。
1. arg
接受类型:{int, float, str, datetime, list, tuple, 1-d array, Series, DataFrame/dict-like( 0.18.1版本一下不支持)}
该参数指定了要转换为datetime的对象。如果提供的是Dataframe,则该类型至少需要以下列:“年”、“月”、“日”,才能转化为datetime。
也就是说你直接传入一个dataframe是不可能实现的,会报错:
ValueError: to assemble mappings requires at least that [year, month, day] be specified: [day,month,year] is missing
但是只要DataFrame里面带了列名为‘year’,‘month’,‘day’就可以合并:
df_time=pd.DataFrame('year':[2022,2022,2022],
'month':[6,6,6],
'day':[13,14,15])
df_time=pd.to_datetime(df_time)0 2022-06-13 1 2022-06-14 2 2022-06-15 dtype: datetime64[ns]
但是如果非可识别的时间索引,就会报错:
df_time=pd.DataFrame('year':[2022,2022,2022],
'month':[6,6,6],
'day':[13,14,15],
'value':[1,2,3])
df_time=pd.to_datetime(df_time)
df_timeValueError: extra keys have been passed to the datetime assemblage: [value]
所以一般传入一个series或者dataframe的一列转换最好。
2.errors
接受类型:‘ignore’, ‘raise’, ‘coerce’,默认:default ‘raise’
- 如果为“raise”,则无效解析将引发异常。
- 如果为“coerce”,则无效解析将设置为NaT。
- 如果“ignore”,则无效解析将返回输入的值。
我们将errors设置为coerce时:
df_time=pd.DataFrame('time':['2022/6/13','2022/6/14','2022/6/15'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['master']=pd.to_datetime(df_time['master'],errors='coerce') 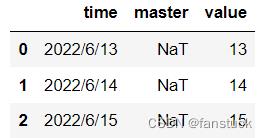
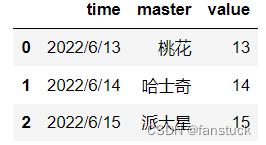
将errors设置为‘ignore’时:
df_time=pd.DataFrame('time':['2022/6/13','2022/6/14','2022/6/15'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['master']=pd.to_datetime(df_time['master'],errors='ignore')不会报错,不改动:
3.dayfirst
接受类型:{bool,默认为False
如果arg是str或相似的列表类型,需要指定日期分析顺序。如果为True,则首先解析日期,例如,“2012年11月10日”被解析为2012年11月10日。
df_time=pd.DataFrame('time':['13/6/2022','14/6/2022','15/6/2022'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['time']=pd.to_datetime(df_time['time'],dayfirst=True)
df_time 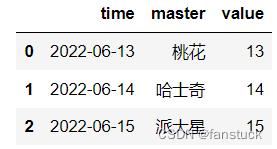
如果我们传入的日期超过了31天,则将给予警告:
ParserError: day is out of range for month: 32/6/2022
4.yearfirst
接受类型:{bool,默认为False
如果arg是str或相似的列表类型,需要指定日期分析顺序。
如果为True,则将日期解析为第一年,例如,“2012年11月10日”解析为2010年11月12日。
如果dayfirst和yearfirst都为True,则在yearfirst优先(与dateutil相同)。yearfirst=True不严格,但更倾向于使用yearfirst进行分析。
df_time=pd.DataFrame('time':['13/6/22','14/6/22','15/6/22'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['time']=pd.to_datetime(df_time['time'],yearfirst=True) 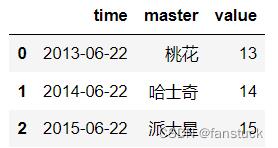
5.utc
接受类型:bool,默认为None
该参数控制与时区相关的解析、本地化和转换。
utc为时间协调时,又称世界统一时间、世界标准时间、国际协调时间。由于英文(CUT)和法文(TUC)的缩写不同,作为妥协,简称UTC。协调世界时是以原子时秒长为基础,在时刻上尽量接近于世界时的一种时间计量系统。中国大陆采用ISO 8601-1988的《数据元和交换格式信息交换日期和时间表示法》(GB/T 7408-1994)称之为国际协调时间,代替原来的GB/T 7408-1994;中国台湾采用CNS 7648的《资料元及交换格式–资讯交换–日期及时间的表示法》,称之为世界统一时间。
- 如果为True,则函数始终返回时区感知的UTC本地化时间戳、序列或DatetimeIndex。为此,时区原始输入被本地化为UTC,而时区感知输入被转换为UTC。
- 如果为False(默认),输入将不会强制为UTC。时区原始输入将保持原始,而时区感知输入将保持其时间偏移。混合偏移(通常为夏令时)存在限制,有关详细信息,请参见示例部分。
df_time['time']=pd.to_datetime(df_time['time'],utc=True) 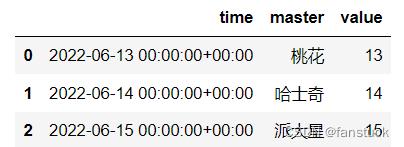
df_time['time']=pd.to_datetime(df_time['time'],utc=False) 
关于更多可以了解 Time zone handling
6.format
接受类型:{str}默认default None
解析时间的strftime,例如%d/%m/%Y”。请注意,“%f”将一直解析到纳秒。有关选项的更多信息,请参阅strftime文档。strftime时间字符:

df_time=pd.DataFrame('time':['2013/6/22','2014/6/22','2015/6/22'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['time']=pd.to_datetime(df_time['time'],format='%Y/%m/%d')
这里会把时间统一 换成yyyy-mm-dd的形式,等于说是限定死了time的格式,不对的格式将直接报错。
7.exact
接受类型:{bool}默认default None
控制格式的使用方式:
- 如果为True,则需要精确的格式匹配。
- 如果为False,则允许格式与目标字符串中的任何位置匹配。
df_time=pd.DataFrame('time':['2013/6/22','2014/6/22','2015/6/22'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['time']=pd.to_datetime(df_time['time'],format='%Y/%d/%m',exact=False)
df_time 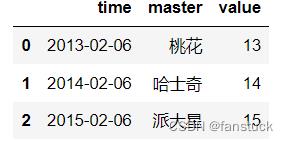
如果为True则报错:
ValueError: unconverted data remains: 2
8.unit
接受类型:{str}默认 default ‘ns’
arg的单位(D、s、ms、us、ns)表示该单位,它是一个整数或浮点数。这将基于原点。例如,使用unit='ms'和origin='unix'(默认值),这将计算到unix epoch开始的毫秒数。
像我们传入的这些yyyy-mm-dd的类型是不行的,这个解析的是时间戳的形式:
df_time=pd.DataFrame('time':['14524','14525','42512'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['time']=pd.to_datetime(df_time['time'],unit='ms') 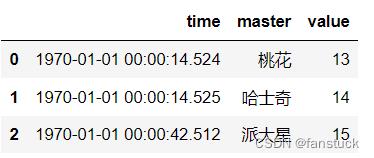
该计算开始日期为1970-01-01 00:00:00,可以通过origin来调整。
df_time=pd.DataFrame('time':['14524','14525','42512'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['time']=pd.to_datetime(df_time['time'],unit='d')调整unit的参数可以让函数识别传入时间的值:
df_time=pd.DataFrame('time':['14524','14525','42512'],
'master':['桃花','哈士奇','派大星'],
'value':[13,14,15])
df_time['time']=pd.to_datetime(df_time['time'],unit='d') 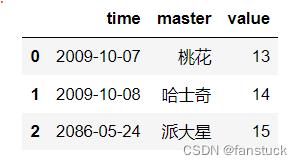
9.infer_datetime_format
接受类型:{bool}默认default False
如果为True且未给出格式,则尝试根据第一个非NaN元素推断datetime字符串的格式,如果可以推断,可切换到更快的解析方法。在某些情况下,这可以将解析速度提高约5-10倍。
如果给出的时间序列是固定的,则建议把这个参数调整为True可以加快检索速度。
10.origin
接受类型:{scalar},默认 default ‘unix’
定义参考日期。数值将被解析为自该参考日期以来的单位数(由单位定义)。
- 如果“unix”(或POSIX)时间;原点设置为1970-01-01。
- 若为“julian”,单位必须为“D”,原点设置为Julian Calendar的开始。公元前4713年1月1日中午开始的一天被指定为第0天。
- 如果时间戳是可转换的,则原点设置为由原点标识的时间戳。

11.cache
接受类型:{bool}默认default True
如果为True,使用唯一的已转换日期缓存来应用日期时间转换。在分析重复的日期字符串时,尤其是带有时区偏移的日期字符串时,可能会产生显著的加速。仅当至少有50个值时才使用缓存。存在越界值将导致缓存不可用,并可能会减慢解析速度。
三、返回类型
1.datetime
如果分析成功。返回类型取决于输入(括号中的类型对应于时区分析失败或时间戳分析超出范围时的回退)
- 标量:时间戳(或datetime.datetime)
- 类似数组:DatetimeIndex(或对象数据类型包含datetime.datetime的系列)
- 系列:datetime64数据类型系列(或包含datetime.datetime的对象数据类型系列)
- DataFrame:datetime64数据类型系列(或包含datetime.datetime的对象数据类型系列)
2.raises
ParserError
从字符串分析日期时失败。
ValueError
当另一个日期时间转换错误发生时。例如,数据帧中缺少“年”、“月”、“日”列之一,或者时区感知日期时间。datetime位于类似混合时间偏移的数组中,utc=False。
- scalars可以是int、float、str、datetime对象(来自stdlib datetime模块或numpy)。如果可能,它们将转换为时间戳,否则将转换为日期时间。日期时间。None/NaN/null标量转换为NaT。
- array-like可以包含int、float、str、datetime对象。如果可能,它们将转换为DatetimeIndex,否则将转换为包含datetime的对象dtype索引。日期时间。在这两种情况下,None/NaN/null条目都转换为NaT。
- series将转换为datetime64数据类型的系列,否则将转换为包含datetime的对象数据类型的系列。日期时间。在这两种情况下,None/NaN/null条目都转换为NaT。
- DataFrame/dict-like:转换为datetime64数据类型的系列。对于每一行,通过组合各种数据框列创建一个日期时间。列键可以是常见的缩写,['year','month','day','minute','second','ms','us','ns')或相同的复数形式。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见
以上是关于Pandas中to_datetime()转换时间序列函数一文详解的主要内容,如果未能解决你的问题,请参考以下文章