从 Redis7.0 发布看 Redis 的过去与未来
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从 Redis7.0 发布看 Redis 的过去与未来相关的知识,希望对你有一定的参考价值。

前言
经历接近一年的开发、三个候选版本,Redis 7.0终于正式发布,这是Redis历史上改变最多的一个大版本,它不仅包含了50多个新命令,还有大量核心新特性与改进,这些不仅能够解决用户使用中的诸多问题,还进一步拓展了Redis的使用场景。
虽然Redis 7.0做了许多大胆的尝试,但是稳定性依然是最重要的基石。Redis官方在7.0的GA博文中也强调这一点:“While user-facing features are easy to boast of, the real “unsung heroes” in this version are efforts to make Redis more performant, stable, and lean.”(虽然面向用户的功能更容易得到称赞,但这个版本中的无名英雄是我们持续不断的对Redis的优化,使其变得更加精简、高效、稳定)。相信从这里可以看出,Redis发展至今稳定性始终被摆在最重要的位置,因此对于7.0的稳定性担忧大可打消。
下面请先跟随我们一同了解Redis7.0的几个核心新特性。
Redis7.0核心新特性概览
Function
Function是Redis脚本方案的全新实现,在Redis 7.0之前用户只能使用EVAL命令族来执行Lua脚本,但是Redis对Lua脚本的持久化和主从复制一直是undefined状态,在各个大版本甚至release版本中也都有不同的表现。因此社区也直接要求用户在使用Lua脚本时必须在本地保存一份(这也是最为安全的方式),以防止实例重启、主从切换时可能造成的Lua脚本丢失,维护Redis中的Lua脚本一直是广大用户的痛点。
Function的出现很好的对Lua脚本进行了补充,它允许用户向Redis加载自定义的函数库,一方面相对于EVALSHA的调用方式用户自定义的函数名可以有更为清晰的语义,另一方面Function加载的函数库明确会进行主从复制和持久化存储,彻底解决了过去Lua脚本在持久化上含糊不清的问题。
那么自7.0开始,Function命令族和EVAL命令族有了各自明确的定义:FUNCTION LOAD会把函数库自动进行主从复制和持久化存储;而SCRIPT LOAD则不会进行持久化和主从复制,脚本仅保存在当前执行节点。并且社区也在计划后续版本中让Function支持更多语言,例如javascript、Python等,敬请期待。
总的来说,Function在7.0中被设计为数据的一部分,因此能够被保存在RDB、AOF文件中,也能通过主从复制将Function由主库复制到所有从库,可以有效解决之前Lua脚本丢失的问题,我们也非常建议大家逐步将Redis中的Lua脚本替换为Function。
Multi-part AOF
AOF是Redis数据持久化的核心解决方案,其本质是不断追加数据修改操作的redo log,那么既然是不断追加就需要做回收也即compaction,在Redis中称为AOF rewrite。
然而AOF rewrite期间的增量数据如何处理一直是个问题,在过去rewrite期间的增量数据需要在内存中保留,rewrite结束后再把这部分增量数据写入新的AOF文件中以保证数据完整性。可以看出来AOF rewrite会额外消耗内存和磁盘IO,这也是Redis AOF rewrite的痛点,虽然之前也进行过多次改进但是资源消耗的本质问题一直没有解决。
阿里云的Redis企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了Multi-part AOF机制来解决,同时也贡献给了社区并随此次7.0发布。具体方法是采用base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和IO资源的浪费,同时也支持对历史AOF文件的保存管理,结合AOF文件中的时间信息还可以实现PITR按时间点恢复(阿里云企业版Tair已支持),这进一步增强了Redis的数据可靠性,满足用户数据回档等需求。
对具体实现感兴趣的同学可以查看本文末尾参考资料。
Sharded-pubsub
Redis自2.0开始便支持发布订阅机制,使用pubsub命令族用户可以很方便地建立消息通知订阅系统,但是在cluster集群模式下Redis的pubsub存在一些问题,最为显著的就是在大规模集群中带来的广播风暴。
Redis的pubsub是按channel频道进行发布订阅,然而在集群模式下channel不被当做数据处理,也即不会参与到hash值计算无法按slot分发,所以在集群模式下Redis对用户发布的消息采用的是在集群中广播的方式。
那么问题显而易见,假如一个集群有100个节点,用户在节点1对某个channel进行publish发布消息,该节点就需要把消息广播给集群中其他99个节点,如果其他节点中只有少数节点订阅了该频道,那么绝大部分消息都是无效的,这对网络、CPU等资源造成了极大的浪费。
Sharded-pubsub便是用来解决这个问题,意如其名,sharded-pubsub会把channel按分片来进行分发,一个分片节点只负责处理属于自己的channel而不会进行广播,以很简单的方法避免了资源的浪费。
Client-eviction
Redis支持内存规格配置,maxmemory和maxmemory-policy大家已经都很熟悉了,但是在这里我还是想再解释一下:maxmemory控制的是Redis的整体运行内存而非数据内存,例如client buffer、lua cache、fucntion cache、db metadata等这些都会算在运行内存中,如果运行内存超过了maxmemory就会触发evict删除数据,这也是用户在使用Redis时的一大痛点。
在这些非数据内存使用当中,又以client buffer消耗最大,在大流量场景下client需要缓存很多用户读写数据(想象一下keys的结果需要先缓存在client output buffer中再发送给用户),由于网络流量的内存消耗导致触发eviction删除数据的情况非常之多。虽然Redis很早就支持对
client-output-buffer-limit配置项,但其限制的也只是单个连接维度的output buffer,没有全局统计client使用内存和限制。为了解决这个问题,7.0新增了maxmemory-clients配置项,来对所有client使用的内存做限制,如果超过了这个限制就会挑选内存消耗最大的client释放,用来缓解内存使用的消耗。
Client-eviction并不是终点,还有很多元数据的内存使用会对用户造成困扰,Redis是基于内存的数据库,我们需要对各个模块的内存进行更精确的统计和控制,让用户能够对数据存储有更为清晰的理解和规划。
Redis历史回顾
Redis发展至今已历经7个大版本,而每个大版本都有大量的新特性产生。例如从3.0开始支持cluster集群模式;4.0开发的lazyfree和PSYNC2解决了Redis长久的大key删除阻塞问题及同步中断无法续传的问题;5.0新增了stream数据结构使Redis具备功能完整的轻量级消息队列能力;6.0更是发布了诸多企业级特性如threaded-io、TLS和ACL等,大幅提升了Redis的性能和安全性。
国内开发者与Redis社区建设
感谢国内开发者,中国区已经成为Redis社区最大的贡献来源之一
阿里云从Redis 4.0开始就深度参与到Redis开源社区当中,向社区贡献了大量能力,目前阿里云在Redis社区共有1名core team member(核心维护者)和2名contributor(核心贡献者),是原作者和Redis Labs以外对Redis社区贡献最大的组织。
我们见证了Redis用户在国内的快速增长,阿里云与Redis社区的深度合作也逐渐吸引了更多的国内开发者参与到Redis建设中去。尤其是在Redis core team成立之后,社区maintainer也和Redis一样变成了多线程(1->5),对于issue和PR的快速处理大幅提升了社区的活跃度。这次7.0的release note中也可以看到已经有超过5名国内开发者贡献了核心feature,并贡献了近半数commit。
这些变化与我们在阿里云上的统计结果也是相符合的:Redis目前同样也已是国内用户使用规模最大的NoSQL数据库之一,并一直处于高速增长中,越来越多的泛互联网甚至传统行业也在逐步接纳Redis,用于快速高效的构建业务应用服务。
虽然Redis发展迅速,但国内用户却大都无法享受技术红利
Redis社区目前主流维护版本是6.0,5.0版本已经进入低维护阶段,而国内还有大量2.8,3.0,4.0版本在使用中。这就很矛盾,一方面,一些对用法,性能,稳定性和抖动控制的能力都贡献在了新版本上,另一方面,国内用户却“看的到,用不上”。
除去6.0,7.0上的高级稳定性优化不说,比如在4.0前,没有lazyfree删除一个大key是同步的会卡住数据库引擎直接导致业务中断。又比如,Redis其实安全性尤其是lua是一直有较大问题的,这些升级也都“隐含”在了新版本中。虽然阿里云仍然在坚持把这些漏洞的修复拉回到低版本上,但是在公网当中还是有大量的低版本实例存在安全风险。
过多用户担心升级版本的兼容性,一方面阿里云也在要求社区来提供一些兼容性验证工具,另一方面阿里云对版本跟进是很快的,可以让用户在新版发布后尽快进行验证。从Redis整体和阿里云的大量客户升级情况来看,版本的向前兼容性是非常好的,大可放心升级。
希望更多的国内用户深度参与社区建设
国外使用Redis的方式和国内使用明显有差异,比如国外更多的是使用在缓存场景,而国内大多数的用法却是内存数据库。社区的发展和roadmap的制定,目前国内用户的声音较小。
目前国内开发者在社区活跃度很高,但更多的是围绕在bugfix,和feature上。我们还是建议无论是国内开发者还是使用者可以深层参与进去,举个简单的例子,提需求、讲明白需求、证明需求的合理性都是参与社区建设,这样才能更好的把我们国内的需求传达,后续甚至可以深度参与开发,跟踪交付,这些社区工作的含金量无疑更高。
在功能上,不仅仅包括API层面的增加,包括接入,可观测性,一致性,一致性和安全等目前社区都在等待需求中。虽然core team member可以代表国内用户来把一些需求写进roadmap,但是真实用户的发声会提供更有力的支撑。
Redis使用场景拓展与展望--Redis还能做什么?
多模服务进入爆发期
Redis是一直贴着用户使用发展起来的,它如此受欢迎主要因为两个特点,极高的性能以及丰富、方便使用的数据结构,这些简单好用的数据结构能够大幅度降低开发业务复杂度。
我们可以看到,以Redislabs为代表的厂商正在大力的丰富Redis的数据结构(modules),如RedisSearch、Redis-Json、RedisGraph、RedisTimeSeries和RedisBloom等。
同样的,阿里云内存数据库Tair很早就在研发各类增强数据结构和模块,目前我们在公共云Tair服务中提供的商业化扩展型数据结构比Redislabs提供的更多,部分模块功能更强,有兴趣可参见文档(本文末尾参考资料)。
目前已有大量云上用户在利用Tair增强型数据结构来构建代码,提高开发效率,甚至完成此前难以完成的工作。2022年是一个Redis扩展结构的爆发年,业内已经渡过接纳期,进入高速发展阶段。无论是Tair还是Redis,我们相信不断丰富的数据结构能够让它们走的更远,从缓存演变为高性能的计算型内存数据库,突破、并解决更多场景问题。
一致性能力上的发展
落盘一致性和副本一致性是使用数据库绕不开的两个话题。长期以来许多人对Redis的应用场景仅仅认定为缓存(尤其是国外用户)。Redis自诞生之初便支持持久化机制RDB和AOF,并且AOF还提供了不同级别的持久化语义:如appendfsync采用最高级别always时可以保证数据完全落盘不丢失,具备与传统数据库一样的强落盘一致性。
在多副本一致性上,主要是指主备一致性上,原生的Redis仍旧采用异步复制,数据修改操作只要在本地执行完成就会返回结果,相比于其他数据库没有提供副本间数据强一致的语义。这也限制了Redis的使用场景,在对数据可靠性有极高要求的用户(例如金融行业,和传统行业)中还没有被完全接纳。
目前业内也都在对Redis的持久化能力上进行发展。比较有代表性的,是阿里云的Tair持久内存版、AWS的MemoryDB、和业内开源的一些Redis-like的基于rocksdb的系统,商业化如Tair的容量存储版(前混合存储)。
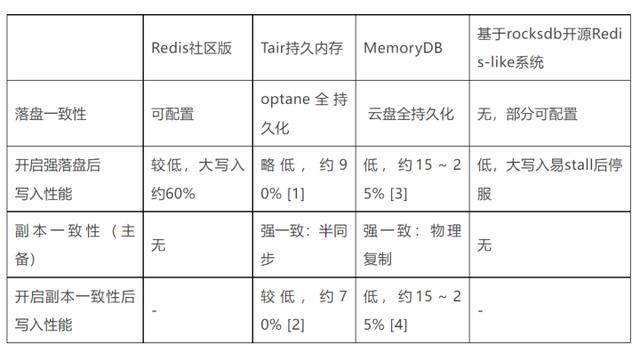
表1: 社区Redis和其他商业化、开源产品的落盘一致性与副本一致性对比 注1:与开源Redis社区版比较 注2:与开源Redis基于内存的使用成本比较 注3,4:来自AWS官方博客测试数据
综合来看,随着用户对Redis的应用范围的扩大,与此同时对于容量、成本和数据可靠性的需求也在不断提升,这些也逐渐成为了衡量Redis企业级能力的重要指标。各大厂商和开源产品也都在构建这些能力上提出了许多解决方案。下面介绍一些典型产品和方案。
AWS的MemoryDB
AWS MemoryDB的思路是基于类似Aurora的共享存储概念,把日志存放在远端共享存储中,同时内存中仍然保留Redis原有的结构。通过这种方式提升数据的持久化一致性,同时也保证了数据读取的延时和吞吐;而缺点则同样因为日志保存在远端,写入性能严重下降(仅有ElastiCache也即Redis社区版的15%~25%,该数据来自AWS官方评测,见本文末尾参考资料)。在主备一致性上,由于直接采取日志的物理复制,所以主备一致性近似接近落盘一致性。
值得一提的是原来AOF rewrite这种压缩(compaction)引起的开销也因为在远端做掉而规避掉,因此是一种很彻底的云原生解法。
阿里云自研内存数据库Tair
在持久化上阿里云走了另外一条路,通过引入新介质持久化内存来解决成本,大容量和持久化能力的问题。这个方案带来的挑战是使用持久化内存存储结构设计上较为复杂,既要控制性能衰减,又要保证兼容性。Tair持久内存很好的解决了这些问题,对比MemoryDB成本更低,读性能基本持平的情况下写入的速度也更快(见本文末尾参考资料),更关键的是基本原封原样的兼容了Redis API,大幅降低了用户的切换成本。
并且,Tair持久内存型还支持半同步和强写入一致性,无论MemoryDB还是Tair持久内存都真正的做到了内存数据库的数据容错性要求。
其他开源产品的发展
国内也出现了一些原创性的优秀落盘开源产品(Redis-Like系统),这些产品大都基于LSM存储结构如rocksdb上的。它们的优点主要是磁盘介质相对内存更为便宜,但同样目前存在的缺点也非常多:运维复杂度较高,直接映射为运维成本、KV无法原生的支持Redis的数据结构、把Redis的强类型变成弱类型等等。
目前这类系统在一致性和容错性上仍有很大的改善空间,而在用户使用体感上,由于很多用户使用习惯还是把Redis-like系统用在业务的同步链路上,对于LSM KV引擎的延时上抖动整体吞吐的影响直接映射成了用户体感,因此很难作为一款通用型产品,而这些痛点也同样存在与Tair容量存储型中(过去叫混合存储版),这也是一个需要长期在存储和兼容性上优化的方向。
综上所述,容量版本可以很好地解决用户的使用成本问题,但是只有更好地解决了落盘一致性问题和副本一致性问题,才能够把Redis类系统的使用场景拓展到企业级。这也是目前看来云厂商一个激烈竞争的企业级产品主流赛道,也有较高的技术门槛。
写在最后
Redislabs在2021年8月正式更名为Redis,大家看到社区版Redis的主页也已经重构修改过了。本身Redis的商业化进度非常快,比如在主页上“夹带” Redis Stack;又比如在github上将一众常用的SDK都购买后,开始添加部分Redislabs商业化开源的支持等。最后Redis可能也会像MongoDB,ElasticSearch一样走向彻底的商业化。但目前社区仍是非常公开和活跃的。
Redis8.0的 feature计划已经开始,一方面我们也如上文所述,建议国内开发者更多的参与到深层次的社区讨论,让社区更多的向国内使用习惯靠拢,这对重度依赖Redis的国内企业情况是非常现实的;另一方面,能够通过社区参与来提升我们的人才竞争力,除去持久化系统,还有分布式架构,高吞吐低延时核心引擎,多模服务和脚本引擎,安全与审计等都需要持续投入。如果国内在Redis领域也能够有10~20名内存数据库的顶尖专家,那么即便是Redis走向商业化闭源其影响对国内用户都会非常小。
最后,欢迎大家使用Redis7.0,也愿我们一起在Redis等内存数据库技术上走得更远!
参考资料:
【1】Redis 7.0 Multi Part AOF的设计和实现:
https://developer.aliyun.com/article/866957
【2】Amazon MemoryDB 与 Amazon ElastiCache比较:https://aws.amazon.com/cn/blogs/china/comparison-of-amazon-memorydb-and-amazon-elasticache/?nc1=b_nrp
【3】Tair扩展数据结构概览:https://help.aliyun.com/document_detail/146579.html
【4】Tair持久内存型性能白皮书:https://help.aliyun.com/document_detail/185189.html
本文为阿里云原创内容,未经允许不得转载。
以上是关于从 Redis7.0 发布看 Redis 的过去与未来的主要内容,如果未能解决你的问题,请参考以下文章