论文笔记: Feudal Reinforcement Learning
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记: Feudal Reinforcement Learning相关的知识,希望对你有一定的参考价值。
1992 NIPS
0 abstract
这篇论文展示了如何创建一个 Q-Iearning 管理层次结构。
在该层次结构中,高层管理人员学习如何为他们的下级经理设置任务,而下级经理学习如何满足他们的要求。 下级经理最初不需要了解他们的经理的命令。 他们只是学习在当前命令的背景下最大化他们的强化。
论文使用一个简单的迷宫任务来说明系统。当系统学习如何绕过、满足多个级别的命令时,它比标准、平面、Q-Iearning 更有效地探索并构建更全面的地图。
1 Feudal control
封建学习主要的特征有两个:
- 奖赏隐藏(reward hiding):
- 每层只知道本层的奖赏,而每层的目标(由上层指定)就编码到reward函数中;
- 同时,每一层也要决定下一层的目标(下一层的reward函数)
- 每层只要满足该层的奖励最大化,不用满足上面层级的奖励最大化(因为也不知道)
- 所以可能出现这样的情况:即使下层的决策是能够让上层的reward更大,但由于它让自己的reward变小了,所以也会受到上层的惩罚;即使下层的决策是能够让上层的reward更小,但由于它让自己的reward变大了,所以会受到上层的奖励
- 信息隐层(information hiding):
- 每层只关注其应该关注到的信息,而不是真实的环境信息(全局信息)。
- 底下干活的人无需知道大领导给小领导安排的事儿(reward)
- 大领导也不知道小领导怎么给下属设置reward的
3 迷宫问题

- 从上往下,网格被划分为连续更细的粒度(见图 1)
- 例如,区域 1-(1,1) 的 1 级经理设置区域 2-(1,1)、2-(1,2)、2- (2,1) 和 2-(2,2)的 2 级经理的任务和奖励 。
- 然后,每个时候,agent可选择的动作有五种
- NSEW,四个移动方位
- *,这个是分层强化学习特有的,相当于把“皮球”踢给下层agent,不移动到这一层的其他agent里面去
- 【比如1-(1,1)的action是*,表示它不会移动到1-(1,2)和1-(2,1),而是表示将任务传递给 它所管辖的2-(1,1)、2-(1,2)、2- (2,1) , 2-(2,2)】
- 最上面一层action肯定只能是*
- 最下面一层的action只能是NSEW里面的一个
- 对于上面这个迷宫图的理解,我和论文有一定的出入,不知道我这么理解是否有误
- 如果第0层agent的命令是向南移动
- 论文的理解: 1-(2,2)根据 Q 值决定一个动作,给出 2-(3,2) 或 2-(4,2) 的路径总长度
- 我的理解:1-(2,2)知道第0层agent给自己的任务是向南,也就是到达1-(2,1),那么它会从NSEW中选择到达1-(2,1)且Q值最大的一种动作【因为我的理解是既然它是信息隐藏了,那应该看不到下面一层的信息】
- 1-(2,2) 管理者选择的动作在层次结构中向下传递一层,并成为确定第 2 级 Q 值的状态的一部分
- 我的理解:1-(2,2)比如做出的选择是向西,那么就把这个任务传给它管辖的2-(3,4),2-(4,4),2-(3,3),2-(4,3)
- 论文的理解: 1-(2,2)根据 Q 值决定一个动作,给出 2-(3,2) 或 2-(4,2) 的路径总长度
- 如果第0层agent的命令是向南移动
- 最后进行决策的时候,根据最细粒度agent的action
3.1 结果
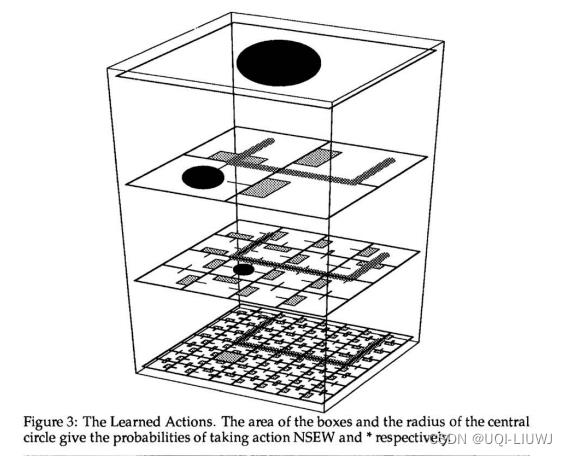
这是训练后的结果,黑点表示动作*(即踢皮球给下属),方格表示选择超那个方位移动。可以发现能很好地避开barrier,同时朝向reward方向移动
以上是关于论文笔记: Feudal Reinforcement Learning的主要内容,如果未能解决你的问题,请参考以下文章