自动驾驶激光点云 3D 目标检测 VoxelNet 论文简述
Posted frank909
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶激光点云 3D 目标检测 VoxelNet 论文简述相关的知识,希望对你有一定的参考价值。
自动驾驶感知视觉有 2 个流派,分别是摄像头视觉和激光雷达视觉,本文分析激光雷达视觉当中经典的算法模型 VoxelNet。
论文:VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
这是 2017 年的论文出自苹果公司算法团队,这篇论文对于刚学习激光雷达目标检测的同学来讲非常有参考价值。
图像和点云
摄像头对环境进行测量,产生的一般是 RGB 格式图片,图片上的一个像素通常有 rgb 3 个颜色通道的数据。
一般说图像数据是稠密的。
图像上的目标检测大多是 2D 的 bbox。
激光点云数据要做 3D 检测,效果如下图:

激光雷达也对环境进行测量,产生的是点云数据,所谓点云就是一个坐标有(x,y,z,r)这样的数据,xyz 代表 3 维坐标,r 代表信号反射强度。
一般说点云数据是稀疏的。
我在思考一个问题,稀疏和稠密是怎么区分的呢?
单论像素数量,一张分辨率为 1920*1080 的图片有 200 多万像素点,一个 128 线的激光雷达 1s 内大概传输 300 多万个点云数据,所以单论数量的话区分稀疏和稠密没有什么道理。
那大概是什么原因呢?
我认为是空间密度。
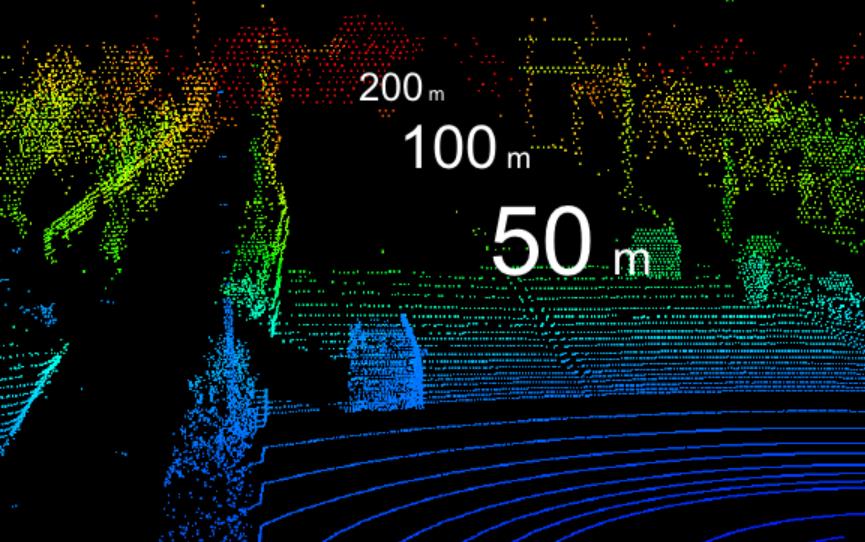
这张图片来自禾赛官网的产品效果示意。
可以看到有些地方点云很稠密,有些地方点云就很稀疏甚至没有。
而图片因为是像素排列,所以不存在稀疏的情况,透明或者黑色都是有相应的 RGB 数据进行存储的。
但点云就不一样,点云数据分布不均。
这引出来了一点问题:
用于激光点云处理的 CNN 模型必定和图像处理的模型有些不一样。
不一样的地方来自于点云数据的前期处理。
像素(pixel)和体素(voxel)
图片是 2 维的,单个点叫做像素。
点云是 3 维的,所有的点形成了点云,但可以想像用一个大的长方体能够把所有的点云装载进去。
点云是稀疏的,为了更高效处理这些数据,VoxelNet 运用了一种前期的处理手段那就是:Voxel Partition。

前面讲到可以想像用一个长方体装载所有的点云,为了更精细化处理,voxel partition 将这个长方体进行了切割,以固定的单元大小进行切割。
假设所有的点云就装载在一个盒子里面,这个盒子沿XYZ轴的尺寸分别是 WHD,假设要进行 voxel partition 操作,最小单元大小是
v
w
,
v
h
,
v
d
v_w,v_h,v_d
vw,vh,vd,最终会产生一个 3D 网络,它的尺寸也可以通过数学公式求得。
D
′
=
D
/
v
d
,
H
′
=
H
/
v
h
,
W
′
=
W
/
v
w
D'=D/v_d,H'=H/v_h,W'=W/v_w
D′=D/vd,H′=H/vh,W′=W/vw
一个最小的单元称为一个体素(voxel),体素中可能有点云,也可能没有点云,所以应对这种状态,最好的方法是要对每个 voxel 中的点云进行编码和特征学习。
VoxelNet 是一个端到端的网络模型,特征学习是它的第一步,它总共分为 3 大部分:
- 特征学习网络
- 中间卷积层
- RPN
论文中的示意图描述的非常清楚:
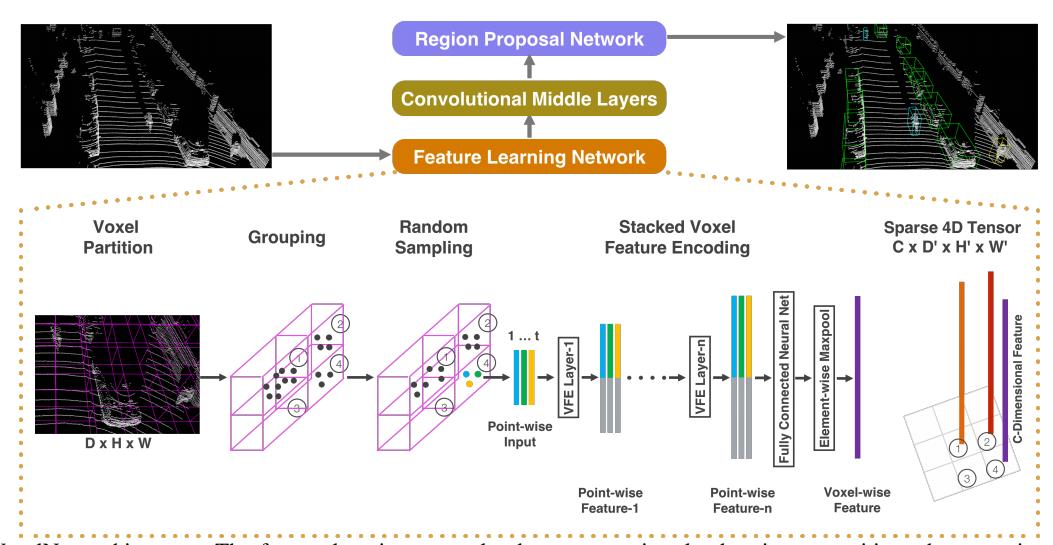
特征学习网络
VoxelNet 的特征学习分为这 5 个过程:
- Voxel Partition
- Grouping
- Random Sampling
- Stacked Voxel Feature Encoding
- Sparse 4D Tensor
Grouping
前面讲到 Voxel Partition,也讲到一个 Voxel 中点云的数量不一,数量不一的原因可能是因为距离、遮挡、相对位姿等等。Grouping 是将一个 Voxel 中的所有点云先进行一个简单的聚合。
Random Sampling
一般一帧点云的数量在 10W 以上,同时处理这么多数据硬件开销很大,最好的方式就是采样。
VoxelNet 采用随机采样,每个 Voxel 固定采集 T 个数量的点云,T 是超参数,在实际业务中可能根据点云数量会不同。
Random Sampling 除了能减少计算量外,还有有效降低因为每个 voxel 点云数据不均带来的信息偏差,提高训练效率。
Stacked Voxel Feature Encoding
Voxel Feature Encoding 简称 VFE,是 VoxelNet 中的核心思想,主要目的是对点云进行特征编码。
这一部分需要好好研究一下。
Stacked Voxel Feature Encoding 自然就是一系列堆栈式的编码层,其实核心思想是产生好几个层次的特征表示。
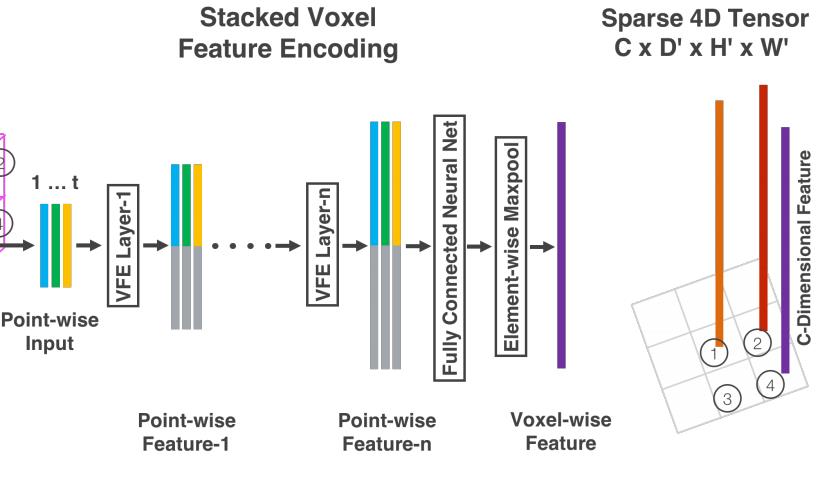
第 1 级层次是点云级的输入。

前面讲到一个非空的 Voxel 中会取样 T 个点云,VoxelNet 作者设定了如下表达式:

i 代表 Voxel 中取样的 T 个点云中的第 i 个。
x,y,z 自然是点云位置信息。
r 是反射率。
有了表达式后,首先要做的是什么呢?
计算质心.
质心用
(
v
x
,
v
y
,
v
z
)
(v_x,v_y,v_z)
(vx,vy,vz)表示。
然后通过计算每个点云和质心的偏移量,得到点云的增广表达式。
V
i
n
=
p
^
i
=
[
x
i
,
y
i
,
z
i
,
x
i
−
v
x
,
y
i
−
v
y
,
z
i
−
v
z
]
T
∈
R
7
i
=
1...
t
V_in=\\left \\\\hatp_i=[x_i,y_i,z_i,x_i-v_x,y_i-v_y,z_i-v_z]^T\\in \\mathbbR^7\\right \\_i=1...t
Vin=p^i=[xi,yi,zi,xi−vx,yi−vy,zi−vz]T∈R7i=1...t
由原始输入的 4 维扩展到 7 维。
然后每个
p
i
p_i
pi要经过一个FCN全连接处理转换到特征空间。
f
i
f_i
fi代表特征空间中每个向量,它能从Voxel中获取到形状信息。
上面讲的是点云级别,接下来处理元素级别。
思路也很简单,就要是通过 Maxpooling 得到 Voxel 中的一些局部聚合特征(locally aggregated feature),用
f
~
\\tildef
f~表示。
最后,每个 point-wise feature 和 locally aggregated feature 进行拼接,得到最终的feature,表示如下:
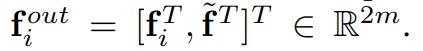
上面讲的是单个 Voxel 的编码操作,对于其它 Voxel 操作步骤是一样的,但所有的 Voxel 对应同一个 FCN。
前面表述的是 VFE1,而 VoxelNet 中划分了许多个 Voxel,每个Voxel 都有对应的 VFE,用
V
F
E
−
i
(
C
i
n
,
C
o
u
t
)
VFE-i(C_in,C_out)
VFE−i(Cin,Cout)表示。
in代表输入input_feature 的通道数,out 表示编码后的通道数量。
其中,经过线性变换中需要学习一个 Matrix,尺寸是
C
i
n
∗
(
C
o
u
t
/
2
)
C_in*(C_out/2)
Cin∗(Cout/2),后面通过 Maxpooling 操作补齐了 out 这个数量,具体操作参见 VFE-1 分析过程。
Sparse Tensor Representation
因为划分 Voxel 的时候,90% 的 Voxel 都是空的,所以,VoxelNet 只处理非空 Voxel 能有效节省计算量。
Voxel 编码后可以用4D Tensor 表示,尺寸
C
∗
D
′
∗
H
′
∗
W
′
C*D'*H'*W'
C∗D′∗H′∗W′。
如图所示:

常规卷积层(Convolutional Middle Layers)
VFE 编码后的数据会送到一系列常规的卷积层当中,作为中间过程。

用
C
o
n
v
M
D
(
c
i
n
,
c
o
u
t
,
k
,
s
,
p
)
ConvMD(c_in, c_out, k, s, p)
ConvMD(cin,cout,k,s,p)表示卷积操作。
M 代表卷积维度。
k 是卷积核尺寸
s 是卷积当中的 stride
p 是卷积当中的 pading
一个卷积中间层格式是:
Conv3D->BN Layer->Relu Layer
RPN
RPN 这个概念来源于 Faster R-CNN 系列,VoxelNet 中也运用到了 RPN,但经过了改良。
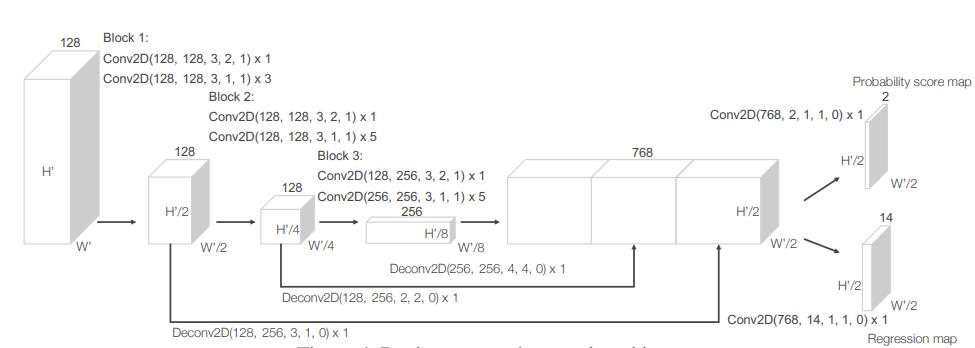
论文中提到,RPN 中的 FCN网络分为 3 块。
每一块都会实现 2x 效果的下采样率。
然后,又实现了向上采样,将倒数 3 块上采样到固定的尺寸,然后拼接起来。
最终,由上采样拼接后的卷积引出 2 个目标分支:
- 分支 1:概率图
- 分支2:回归图
注意它们的尺寸,概率图通道数是 2,代表正负 anchor 的概率,这个概率应该通过 softmax 处理过。
回归图的通道数是 7,代表的就是一个 anchor 的 3D 信息(x,y,z,l,w,h,theta)。
Loss Function
除了神经网络模型外,Loss Function 怎么设定成为最重要的事情。
因为有 Anchor 的存在,要计算 3D 框的信息自然就会引入 offset。
VoxelNet 对于 Anchor 有正负之分。
Loss 也离不开 GroundTruth。
在 VoxelNet 中 GroundTruth 表示如下:

Anchor 的正样本表示如下:

其中
θ
\\theta
θ是3D目标的偏航角.
用
u
∗
u*
u∗代表残差。

这里不是单纯的残差,x,y,z 的残差经过了归一化操作。

分母是 da,也就是 anchorbox 的对角线长度.
求 l,w,h 的残差时是求比例然后 log 函数缩放.
求 theta 角倒是真正意义上的残差.
最终 Loss Function 定义如下:
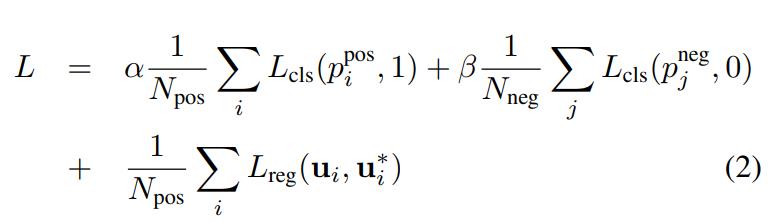
总体 Loss 由 2 部分组成:
- 分类 Loss
- 回归 Loss
其中分类 Loss 计算的是 anchorbox 的正样本概率和负样本概率的二分交叉熵.
α
\\alpha
α和
β
\\beta
β是用来平衡的。
而回归当中的 loss 只计算正样本,采用 Smoth Loss L1 方法。
μ
i
\\mu_i
μi 代表前面 RPN 的输入,
μ
∗
\\mu*
μ∗前面提到过是 Groundtruth 和 正样本的残差.
高效处理
GPU 处理稠密数据时非常有效,但点云数据是很稀疏的,所以,要高效处理就需要做一些数据处理。
VoxelNet 给出的答案是复用缓存。

缓存的尺寸是 K × T × 7。
K 代表最大数量的非空 Voxel。
T 代表一个 Voxel 中点云最多数量.
7 是指经编码后的尺寸.
核心思想就是类 HashTable 的形式。
- 如果一个 Voxel 还未初始化,就初始化,再插入点云
- 如果一个 Voxel 已经初始化就复用,在 < T 的情况下插入点云
- 如果一个 Voxel 已经初始化,但其中点云数量等于 T 则不插入新的点云
经过缓存处理后,稀疏的点云能够变成稠密的数据,之后再经过中间卷积层和RPN处理,GPU能够更加高效。
训练相关
本文的重心是介绍 VoxelNet 算法思想,所以其它的就稍微带过一下。
VoxelNet 相关训练是以 KITTI 数据集为基础的,涉及到 2 大类别子数据集合
- 汽车
- 行人和自行车
两种子数据集对应的 Voxel size 是一样的 DHW 分别是 0.4x0.2x0.2。
但因为汽车、行人、自行车的尺寸不一样,所以,anchor 的尺寸自然也要不一样。
anchor 尺寸本质就是现实世界中某一类别的平均尺寸。
- 汽车 anchor size: l,w,h[3.9,1.6,1.56]
- 行人 anchor size:l,w,h[0.8,0.6,1.73]
- 自行车 anchor sizel,w,h[1.76,0.6,1.8]
另外,为了捕捉更丰富的信息,每种大类 Voxel 中 T 的数量是不一样的。
- 汽车 T = 35
- 行人自行车 T= 45
IOU的计算是针对鸟瞰图而言的,汽车和行人阈值也不一样。
- 汽车,> 0.6 正样本,< 0.45 负样本,其它忽略
- 行人自行车,> 0.5 正样本,< 0.35 负样本,其它忽略
本质上还是因为类别的尺寸不一样。
数据增强
在论文中数据增强洋洋洒洒写了 3 段,核心思想无非就是提出一种“pertutation"的操作。
- 将 3D box 绕 Z 轴旋转一定角度,然后 xyz 施加随机范围内的偏移量。
- 对所有的点云施加全局的缩放效果。
- 对所有点云施加全局的旋转效果。
第一个操作无非是增加数据,后面 2 个是为了提高网络的鲁棒性表现。
更详细的操作请阅读原论文。
性能表现
因为是几年前的模型,所以,这里就不张贴相应的模型评估结果了。
但我注意到的一个细节是,在 TitanX 显卡上,VoxelNet 跑一帧需要 225ms。
对比图像目标检测的模型,yolo 系列能轻松达到 17ms 的推断时间,VoxelNet 当然不算快。
即使不与 YOLO 比,单纯这 225ms 推断时间也无法说明别人你与实时性有任何关系。
总结
VoxelNet 非常优秀,值得好好学习,它价值体现在这 4 点:
- 提出了一种 end-to-end 的点云处理网络模型;
- 有效表达了点云数据,形成了一种稀疏的数据到稠密数据的处理能力;
- 改良并融合了 RPN,提升了目标检测的性能。
以上是关于自动驾驶激光点云 3D 目标检测 VoxelNet 论文简述的主要内容,如果未能解决你的问题,请参考以下文章