ChatGPT 视觉模型Visual ChatGPT 深度解析
Posted youcans_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ChatGPT 视觉模型Visual ChatGPT 深度解析相关的知识,希望对你有一定的参考价值。
【ChatGPT 视觉模型】Visual ChatGPT 深度解析与使用
说明:
根据有关要求,本文将【Visual ChatGPT】模型简称为【Visual-GPT】。
本文为删节版,进行了大量删改,有些内容比较晦涩,读者可以略过,当然也可以仔细研读…完整版参见文末链接。
更新说明:文末链接已删除。
1. 【Visual- ChatGPT】火热来袭
3月9日,微软亚洲研究院发布了图文版 ChatGPT——Visual ChatGPT,并在 Github 开源了基础代码,短短一周已经获得了 19.7k 颗星。
2022年11月,OpenAI 推出的 ChatGPT,几个月来已经火爆全球,不仅需要候补注册,还要科学上网。ChatGPT 具有强大的会话能力的语言界面进行人机对话,能陪你聊天、编写代码、修改 bug、解答问题…,但是目前还不能处理或生成视觉图像。
Visual ChatGPT 把一系列 Visual Foundation 视觉模型接入 ChatGPT,使用户能够与 ChatGPT 以文本和图像的形式交互,还能提供复杂的视觉指令,让多个模型协同工作。Visual ChatGPT 可以理解和响应基于文本的输入和基于视觉的输入,减少进入文本到图像模型的障碍,增加各种 AI 工具的互操作性。
Visual Transformer 将 ChatGPT 作为逻辑处理中心,集成 Visual Foundation 视觉基础模型,从而实现:
- 提供视觉聊天系统,可以接收和发送文本和图像;
- 提供复杂的视觉问答和视觉编辑指令,可以解决复杂视觉任务;
- 可以提供反馈,总结答案,还可以主动对模糊的指令进行询问。

Visual-GPT 可以用自然语言简单地从模型中键入想要的内容,如题图所示的过程中进行了几轮对话:
- 用户要求生成一张猫的图像。Visual-GPT 生成了一幅正在看书的猫的图像。
- 用户要求将图像中的猫换成狗,并把书删除。Visual-GPT 将该图像中的猫换成了狗,并删除了图像中的书。
- 用户要求对图像进行 Canny 边缘检测。Visual-GPT 理解并执行了 Canny 边缘检测操作,生成了边缘图像。
- 用户要求基于指定的网络图像,生成一幅黄狗图像,Visual-GPT 也很好地完成了这个任务。
2. 【Visual-GPT】操作实例
2.1 处理流程
Visual-GPT 的基本处理流程如图所示。
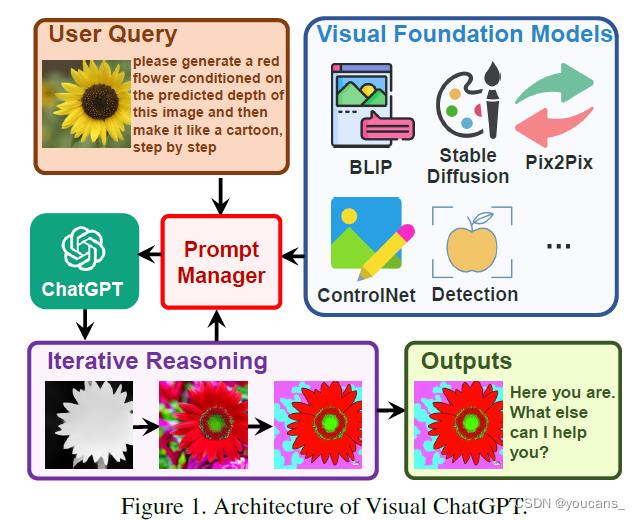
如图所示,用户上传了一张黄色花朵的图像,并输入一条复杂的语言指令「请根据该图像生成的深度图在生成一朵红色花朵,然后逐步将其制作成卡通图片」。
Visual-GPT 中的 Prompt Manager 控制与 VFM 相关的处理流程。ChatGPT 利用这些 VFMs,并以迭代的方式接收其反馈,直到满足用户的要求或达到结束条件。
- 首先是深度估计模型,用来检测图像深度信息;
- 然后是深度图像模型,用来生成具有深度信息的红色花朵图像;
- 最后利用基于 Stable Diffusion 的风格迁移模型,将图像风格转换为卡通图像。
在上述 pipeline 中,Prompt Manager 作为 ChatGPT 的管理调度中心,提供可视化格式的类型并记录信息转换的过程,最后输出最终结果图像并显示。
2.2 操作实例
第一轮对话:
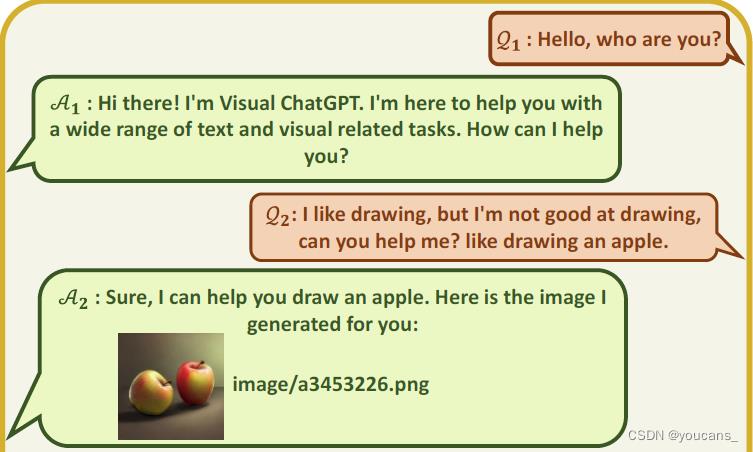
Q1:用户文本询问,问题与图像无关。
A1:模型文本回答,回答与图像无关。
Q2:用户要求画一个苹果。
A2:模型图文回答,绘制了一幅苹果图片。
第二轮对话:
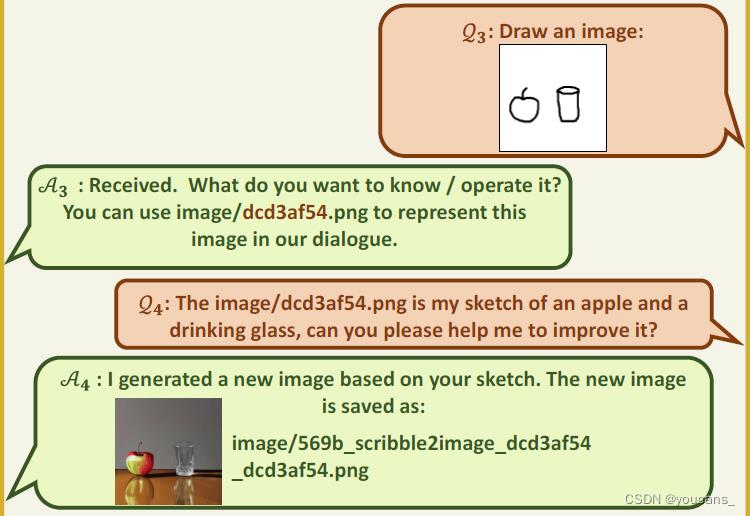
Q3:用户输入图像,是一个苹果和杯子的草图。
A3:模型文本回答,询问用户的意图,并主动提示草图的文件名。
Q4:用户文本输入,要求按草图绘制苹果和杯子。
A5:模型图文回答,按照用户要求绘制了一幅苹果和杯子的图片。
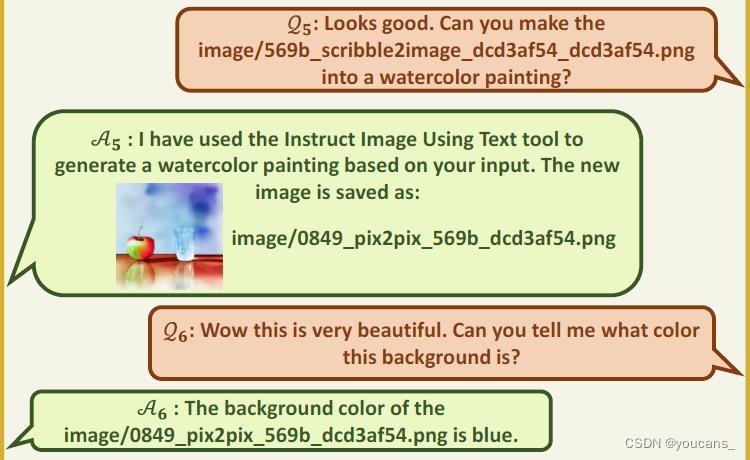
第三轮对话: Q5:用户输入文本,要求把上图修改为水彩画风格。 A5:模型图文回答,按照用户要求把上图修改为一幅水彩画风格的图片。 Q6:用户文本输入,询问图片的背景颜色。 A6:模型文本回答,回答图片的背景颜色。
第四轮对话: Q7:用户文本输入,要求去除图片中的苹果。 A7:模型图文回答,按照用户要求从图片中去除苹果——但是没有去除苹果在桌面上的影子。 Q8:用户输入文本,指出上图中的影子还在桌面上,并要求把换一张黑色的桌子。 A8:模型图文回答,按照用户要求把图片中的桌子换成黑色桌子。

3. 【Visual-GPT】技术原理分析
3.1 技术原理
由于 ChatGPT 是用单一语言模态训练而成,处理视觉信息的能力非常有限。而视觉基础模型(VFM,Visual Foundation Models)在计算机视觉方面潜力巨大,因而能够理解和生成复杂的图像。例如,BLIP 模型是理解和提供图像描述的专家,Stable Diffusion 可以基于文本提示合成图像。然而由于 VFM 模型对输入输出格式的苛求和固定限制,但在人机交互上却不如对话语言模型灵活。
Visual ChatGPT 是在大量文本和图像数据集上训练的。该模型使用不同的视觉基础模型(如 VGG、ResNet和DenseNet)从图像中提取特征,然后将这些特征与基于文本的输入相结合以生成响应。使用有监督和无监督学习技术的组合进行训练,使其能够学习并适应新的场景。
当用户用图像输入问题或陈述时,它分析图像并提取相关特征。然后,它将这些特性与基于文本的输入相结合,以生成与用户查询相关的响应。例如,如果用户上传一辆汽车的图像并询问“这辆汽车的品牌和型号是什么?”,Visual-GPT 将分析图像并根据从图像中提取的视觉特征生成响应。
传统的聊天机器人只依赖基于文本的输入,这限制了它们的能力。Visual-GPT 通过结合计算机视觉扩展了聊天机器人的功能,使其能够基于视觉上下文理解并生成响应。Visual-GPT 的另一个特性是它能够生成创造性的响应。由于它是在GPT-3之上构建的,它可以访问大量文本数据集,这使它能够生成富有创意和多样性的响应。这使得与 Visual-GPT 的交互更具吸引力和人性化。
3.2 系统架构
Visual-GPT 的系统架构如下图所示,由用户查询模块(User Query)、交互管理模块(Prompt Manger)、视觉基础模型(Visual Foundation Models,VFM)、调用 ChatGpt API 系统和迭代交互模块(Iterative Reasoning)、用户输出模块(Outputs)构成。
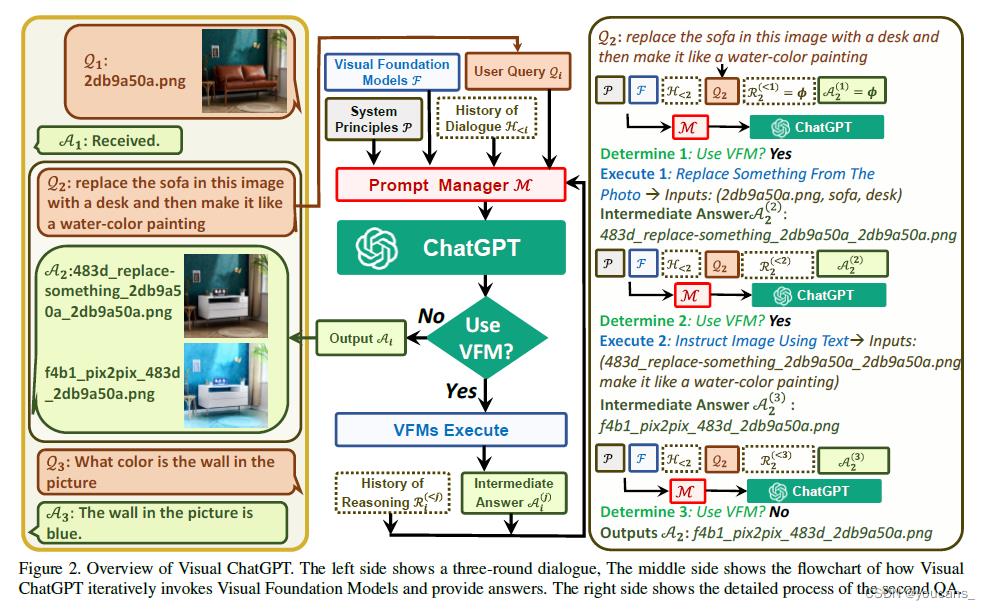
上图左图是多轮对话的过程,中图是 Visual-GPT 如何迭代调用 VFMs 并提供答案的流程图,右图是模型针对第2个 Q/A 的详细运行过程。
分析系统架构图,该系统利用 ChatGPT 和 一个Prompt Manager(M) 来做意图识别和语言理解,然后决定后续的操作和产出。
在这个对话的例子中:
- 第一轮对话:首先用户输入一张图片 User Query(Q1),模型回答收到 (A1)。
- 第二轮对话:(1)用户提出”把沙发改为桌子“和”把风格改为水彩画“两个要求(Q2),模型判断需要使用VFM模型;(2)模型判断第一个要求是替换东西,因此调用 repalce object 模块,生成符合第一个要求的图片;(3)模型判断第二个要求是通过语言修改图片,因此调用 pix2pix 模块,生成符合第二个要求的图片;(4)模型判断完成用户提出的需求,输出第二幅图片(A2)。
- 第三轮对话:用户提出问题(Q3),模型判断不需要 VFM,调用 VQA 模块,回答问题得到答案(A3)。
将这个过程抽象出来, 就是一系列系统规则组成的M§和功能模块组成的M(F) :
对于由多个“问题-答案对”所构成的集合 S = ( Q 1 , A 1 ) , ( Q 2 , A 2 ) , . . . , ( Q n , A n ) S=(Q_1,A_1), (Q_2,A_2),...,(Q_n,A_n) S=(Q1,A1),(Q2,A2),...,(Qn,An),要从第 i i i 轮对话中得到答案 A i A_i Ai,需要一系列的 VFM 和中间输出。
将第
i
i
i轮对话中第
j
j
j次的工具调用中间答案记为
A
i
j
A_i^j
Aij,就可以定义 Visual ChatGPT 的模型为:
A
i
j
+
1
=
C
h
a
t
G
P
T
(
M
(
P
)
,
M
(
F
)
,
M
(
H
<
i
)
,
M
(
Q
i
)
,
M
(
R
i
<
j
)
,
M
(
F
(
A
i
j
)
)
)
A_i^j+1 = ChatGPT(M(P), M(F), M(H_<i), M(Q_i), M(R_i^<j), M(F(A_i^j)))
Aij+1=ChatGPT(M(P),M(F),M(H<i),M(Qi),M(Ri<j),M(F(Aij)))
其中:P 是全局原则,F 是各个视觉基础模型,
M
(
H
<
i
)
M(H_<i)
M(H<i) 是历史会话记忆,$ M(Q_i)$ 是第 i 轮的用户输入,
M
(
R
i
<
j
)
M(R_i^<j)
M(Ri<j) 是第 i 轮的推理历史,
A
j
A^j
Aj 是中间答案。
ChatGPT生成最终答案要经历一个不断迭代的过程,它会不断自我询问,自动调用更多VFM。而当用户指令不够清晰时,Visual ChatGPT会询问其能否提供更多细节,避免机器自行揣测甚至篡改人类意图。
3.3 模块说明
M§:
Visual-GPT 为了能让不同的VFM理解视觉信息并生成相应答案,需要设计一系列系统原则,并将其转化为 ChatGPT能够理解的提示。
通过生成这样的提示,Prompt Manager 能够帮助 Visual-GPT 完成生成文本、图像的任务,能够访问一系列VFM并自由选择使用哪个基础模型,提高对文件名的敏感度,进行链式思考和严格推理。
M(F):
Prompt Manager 需要帮助 Visual-GPT 区分不同的VFM,以便准确地完成图像任务。
为此,Prompt Manager对各个基础模型的名称、应用场景、输入和输出提示以及实例给出了具体定义。
M(Q):
Prompt Manager会对用户新上传的图像生成唯一文件名,并生成假的对话历史,其中提到该名称的图片已经收到,这样可以在涉及引用现有图像的查询时忽略文件名的检查。
Prompt Manager会在查询问题之后加上一个后缀提示,来确保成功触发VFM,强制 Visual-GPT 进行思考,给出言之有物的输出。
M(F(A)):
VFM给出的中间输出,Prompt Manager会为其生成链式文件名,作为下一轮内部对话的输入。
3.4 Prompt Manager 功能与规则
Visual-GPT 的核心是 Prompt Manager,具体功能如下:
- 首先明确告诉 ChatGPT 每个 VFM 的功能,并指定输入输出格式。
- 然后转换不同的视觉信息(如 png 图像、深度图像和 mask 矩阵)转换为语言格式。
- 最后处理不同 VFM 的历史、优先级和冲突。
通过 Prompt Manager 的帮助,ChatGPT 可以利用这些 VFM,并以迭代方式接收反馈,直到满足用户的需求或达到结束条件。
Visual-GPT 集成了不同 VFM 来理解视觉信息并生成相应答案的系统。因此,Visual-GPT 需要制定一些基本规则,并将其转化为 ChatGPT 可以理解的命令。
这些基本规则包括:
- Visual-GPT 的任务需求:协助完成一系列与文本和视觉相关的任务,例如 VQA、图像生成和编辑。
- VFM 的可访问性:Visual ChatGPT 可以访问 VFM 列表来解决各种 VL( vision-language ) 任务,使用哪种基础模型由 ChatGPT 模型本身决定。
- 文件名敏感度:在对话中可能包含多个图像及不同的更新版本,使用精确的文件名以避免歧义至关重要,滥用文件名会导致混淆图片。Visual-GPT 被设计为严格使用文件名,确保检索和操作图像文件的正确性。
- Chain-of-Thought:一些看似简单的命令可能需要多个 VFM,例如生成卡通图片的过程涉及深度估计、深度到图像和风格转换的 VFM。Visual-GPT 引入了 CoT 以帮助决定、利用和调度多个 VFM,将用户的问题分解为多个子问题来解决更具挑战性需求。
- 推理格式的严谨性:Visual-GPT 必须遵循严格的推理格式。该研究使用精细的正则表达式匹配算法解析中间推理结果,为 ChatGPT 模型构建合理的输入格式,以帮助其确定下一次执行,例如触发新的 VFM 或返回最终响应。
- 可靠性:Visual-GPT 作为一种语言模型,可能会伪造假图像文件名或事实,这会使系统不可靠。为了处理此类问题,需要设计 prompt 使忠于视觉基础模型的输出,而不能伪造图像内容或文件名。此外,prompt 还将引导 ChatGPT 优先利用 VFM,而不是根据对话历史生成结果。
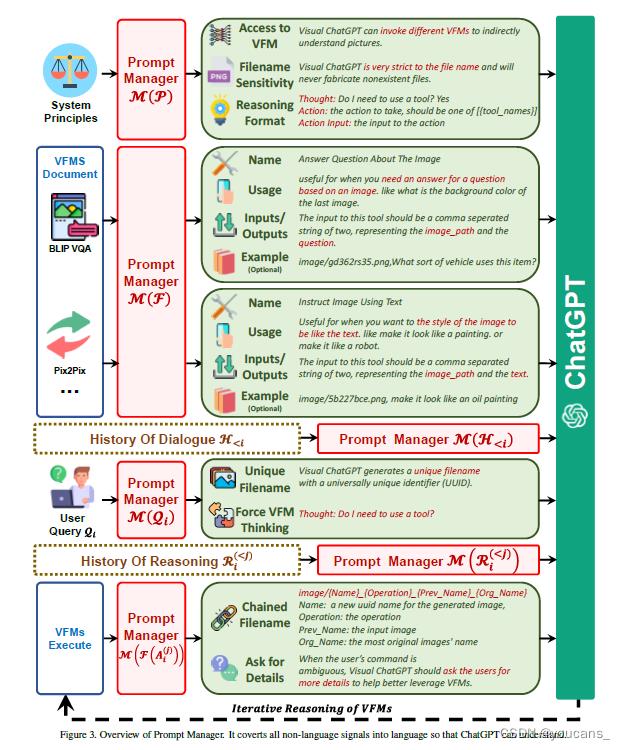
3.5 视觉基础模型(Visual Foundatin Model)
Visual-GPT 支持 22 种视觉基础模型(Visual Foundatin Model):
- 从图像中删除对象(Remove Objects from Image):image path, textual what to remove -> image path
- 替换图像中的对象(Replace Objects from Image):image path, textual what to replace, textual what to add -> image path
- 按文本要求修改图像(Change Image by the Text):image path, textual how to modify -> image path
- 图像问题解答(Image Question Answering):image path, question -> answer
- 从图像生成描述文本(Image-to-Text):image path -> natural language description
- 从描述文本生成图像(Text-to-Image):textual description -> image path
- 对图像进行边缘检测(Image-to-Edge):image path -> edge image path
- 从边缘检测图和文本描述生成新图像(Edge-to-Image):edge image path, textual description -> image path
- 对图像进行直线检测(Image-to-Line):image path -> line image path
- 从直接检测图和文本生成新图像(Line-to-Image):line image path, textual description -> image path
- 对图像进行 HED 边缘检测(Image-to-Hed):image path -> hed image path
- 从HED边缘检测和文本生成新图像(Hed-to-Image):hed image path, textual description -> image path
- 生成分割图像(Image-to-Seg):image path -> segment image path
- 从分割图像和文本生成新图像(Seg-to-Image):segment image path, textual description ->image path
- 从图像生成深度图(Image-to-Depth):image path -> depth image path
- 从深度图和文本生成新图像(Depth-to-Image):depth image path, textual description -> image path
- 从图像生成法线图(Image-to-NormalMap):image path -> norm image path
- 从法线图和文本生成新图像(NormalMap-to-Image):norm image path, textual description -> image path
- 从图像生成草图(Image-to-Sketch):image path -> sketch image path
- 从草图和文本生成新图像(Sketch-to-Image):sketch image path, textual description -> image path
- 对图像进行姿态检测(Image-to-Pose):image path -> pos image path
- 从姿态检测和文本生成新图像(Pose-to-Image):pos image path, textual description -> image path
4. 【Visual-GPT】使用与运行
【本文为删节版,相关内容已删除。】
4.1 clone the repo
4.2 prepare the basic environments
4.3 start local runing
5. 【Visual-GPT】论文简介
5.1 论文获取

Title:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
标题:Visual ChatGPT:使用 Visual Foundation 模型进行对话、绘图和编辑
作者:Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
机构:Microsoft Researc Asia(微软亚洲研究院)
论文链接: https://arxiv.org/abs/2303.04671
开源代码: https://github.com/microsoft/visual-chatgpt
我已经将本文上传到 CSDN,读者也可以从 arxiv 自行下载。
第一作者:吴晨飞,高级研究员,2020 年加入微软亚洲研究院自然语言计算组,研究领域为多模型的预训练、理解和生成。
通讯作者: 段楠,微软亚洲研究院首席研究员及自然语言计算组研究经理,中国科学技术大学兼职博导,天津大学兼职教授,研究领域为自然语言处理、代码智能、多模态智能和机器推理等。
5.2 主要贡献
(1)提出 Visual ChatGPT,打开了 ChatGPT 和 VFM 连接的大门,使 ChatGPT 能够处理复杂的视觉任务。
(2)设计了一个 Prompt Manager,其中涉及 22 个不同的 VFM,并定义了它们之间的内在关联,以便更好地交互和组合。
(3)进行了大量的零样本实验,并展示了大量的案例来验证 Visual ChatGPT 的理解和生成能力。
5.3 本文的启发
- 本文开启了 ChatGPT 处理视觉任务的大门。
- NLP —> Natural Language PhotoShop,自然语言文本描述下的图片创作编辑和问答。
- 可以通过系统设计和工具包设计的 Prompt 实现无监督的工具调用,类似于 zero-shot 的 toolformer。
- ChatGPT 本身对仿真场景的能力很强,也能接受图片路径和函数关系,可以很好地使用基础视觉模型。
- Visual ChatGPT 本身是一个语言模型,所谓的两方多轮对话只是一个 Human AI 的多轮特殊形式。
5.4 模型复现
Visual-GPT 的运行步骤如下。
(1)创建 Python3.8 环境并激活新的环境:
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
(2)安装所需的依赖(详见4.2):
# prepare the basic environments
pip install -r requirement.txt
(3)clone the repo:
【删除】
clone the repo 所建立的文件夹结构如下:
├── assets
│ ├── demo.gif
│ ├── demo_short.gif
│ └── figure.jpg
├── download.sh
├── LICENSE.md
├── README.md
├── requirement.txt
└── visual_chatgpt.py
(4)设置工作目录:
将工作目录设置为创建的 github repo 的 copy:
# clone the repo
%cd visual-chatgpt
(5)下载基本视觉模型 VFM:
# download the visual foundation models
bash download.sh
(6)输入 OpenAI_API_key:
要开始使用OpenAI API,请访问 platform.OpenAI.com 并使用 Google 或 Microsoft 邮箱注册帐户,获取 API 密钥,该密钥将允许您访问API。——科学上网,势不可挡!
%env OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY=Your_Private_Openai_Key
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY=Your_Private_Openai_Key
(7)创建图像保存目录
!mkdir ./image
(8)运行 Visual GPT
!python3.8 ./visual_chatgpt.py
注意问题:
(1)可以通过 “–load” 指定 GPU/CPU 分配,该参数设置使用的 VFM 模型及加载位置。可用的 Visual Foundation 模型参见 3.6 节内容。
例如,将 ImageCaptiing 加载到 cpu,将 Text2Image 加载到 cuda:0,则设置为:
python visual_chatgpt.py --load ImageCaptioning_cpu, Text2Image_cuda:0
(2)VFM 模型所需的内存资源很大,推荐的设置选项为:
- CPU 用户:只加载 ImageCaptioning_cpu, Text2Image_cpu
- 1 Tesla T4 15GB 用户:只加载 ImageCaptioning_cuda:0, Text2Image_cuda:0,可以加载 ImageEditing_cuda:0
- 4 Tesla V100 32GB 用户:加载如下
--load ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3
(3)不同 VFM 模型所需内存的参考值。
| Foundation Model | Memory Usage (MB) |
|---|---|
| ImageEditing | 6.5 |
| ImageCaption | 1.7 |
| T2I | 6.5 |
| canny2image | 5.4 |
| line2image | 6.5 |
| hed2image | 6.5 |
| scribble2image | 6.5 |
| pose2image | 6.5 |
| BLIPVQA | 2.6 |
| seg2image | 5.4 |
| depth2image | 6.5 |
| normal2image | 3.9 |
| InstructPix2Pix | 2.7 |
5.5 常见错误
-
RuntimeError: CUDA error: invalid device ordinal
问题原因:GPU 的数量不够。
解决方案:将 visual_chatgpt.py 文件中的所有 cuda:\\d 替换为 cuda:0。 -
OutOfMemoryError: CUDA out of memory
问题原因:没有足够的 GPU 内存来运行 VFM模型。
解决方案:忽略 download.sh 和 visual_chatgpt.py 文件中不需要的一些模型,只加载必要的模型。
5.6 代码解读
**说明:**本节内容来自外网,博主也在解读和测试。在此贴出相关内容,仅供参考,更多解读详见 【Visua ChatGPT: Paper and Code Review】。
with gr.Column(scale=0.15, min_width=0):
btn = gr.UploadButton(“Upload”, file_types=[“image”])
btn.upload(bot.run_image, [btn, state, txt], [chatbot, state, txt])
def run_image(self, image, state, txt):
image_filename = os.path.join('image', str(uuid.uuid4())[0:8] + ".png")
print("======>Auto Resize Image...")
img = Image.open(image.name)
width, height = img.size
ratio = min(512 / width, 512 / height)
width_new, height_new = (round(width * ratio), round(height * ratio))
img = img.resize((width_new, height_new))
img = img.convert('RGB')
img.save(image_filename, "PNG")
print(f"Resize image form widthxheight to width_newxheight_new")
description = self.i2t.inference(image_filename)
Human_prompt = "nHuman: provide a figure named . The description is: . This information helps you to understand this image, but you should use tools to finish following tasks, "
"rather than directly imagine from my description. If you understand, say "Received". n".format(image_filename, description)
AI_prompt = "Received. "
self.agent.memory.buffer = self.agent.memory.buffer + Human_prompt + 'AI: ' + AI_prompt
print("======>Current memory:n %s" % self.agent.memory)
state = state + [(f"*image_filename*", AI_prompt)]
print("Outputs:", state)
return state, state, txt + ' ' + image_filename + ' '
如上所述,上传图像后,调用run_image函数。此函数通过uuid创建新的图像名称,对图像进行预处理,然后创建添加到缓存的人工旋转。
还可以看出,图像描述与文件名一起被包括作为初始输入。该描述由Blip图像字幕模型生成。
class ImageCaptioning:
def __init__(self, device):
print("Initializing ImageCaptioning to %s" % device)
self.device = device
self.processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
self.model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base").to(self.device)
self.i2t = ImageCaptioning(device="cuda:4")
从上面声明的Human_prompt变量中可以看出,短语“但在根据我的描述直接想象之前,您应该使用工具完成以下任务。设置ChatGPT使用VFM而不是任意提供响应的音调。
Human_prompt = "nHuman: provide a figure named . The description is: . This information helps you to understand this image, but you should use tools to finish following tasks, "
"rather than directly imagine from my description. If you understand, say "Received". n".format(image_filename, description)
除了调用提交图像之外,每个调用还具有前缀和后缀,以进一步确保模型不会以特殊方式运行。前缀中列出的一些关键准则如下:
-
作为一种语言模型,VisualChatGPT不能直接读取图像,但它有一系列工具来完成各种视觉任务。每个图像都将创建一个文件名为“image/xxx.png”,VisualChatGPT可以调用各种工具来间接理解图像。
-
VisualChatGPT 对图像的文件名非常严格,不支持不存在的文件。
-
Visual ChatGPT可以按顺序使用这些工具,并且忠于工具观察结果的输出,而不是伪造图像内容和图像文件名。如果创建了新图像,它将记住上次观察工具时的文件名。
-
Visual ChatGPT可以访问以下工具:
这些声明使Visual ChatGPT能够使用可用的可视化工具,以及如何处理文件名以及如何与用户就VFM模型之一生成的图像进行通信。
代理有一个可以使用的所有工具的列表,在本例中是VFM。每个工具都有详细描述其功能,例如:
Tool(name="Generate Image From User Input Text", func=self.t2i.inference,
description="useful when you want to generate an image from a user input text and save
it to a file. like: generate an image of an object or something, or
generate an image that includes some objects. "
"The input to this tool should be a string, representing the text
used to generate image. "),
所使用的工具之一是VFM,它可以将文本转换为图像,如图所示,为代理提供了有关工具名称的信息,该信息概括了模型的功能、要调用的函数以及详细描述工具和输入。以及仪器输出。
然后,代理使用工具的描述和过去的对话历史来决定下一步使用哪个工具。使用ReAct框架做出决策。
self.agent = initialize_agent(
self.tools,
self.llm,
agent="conversational-react-description",
verbose=True,
memory=self.memory,
return_intermediate_steps=True,
agent_kwargs='prefix': VISUAL_CHATGPT_PREFIX,
'format_instructions': VISUAL_CHATGPT_FORMAT_INSTRUCTIONS,
'suffix': VISUAL_CHATGPT_SUFFIX,
ReAct可以被认为是推理链(CoT)推理范式的扩展。而CoT允许LM生成一系列推理来解决任务,从而减少产生幻觉的可能性。
<以上是关于ChatGPT 视觉模型Visual ChatGPT 深度解析的主要内容,如果未能解决你的问题,请参考以下文章