算法和数据结构解析:3 - 二分查找相关问题
Posted 鮀城小帅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法和数据结构解析:3 - 二分查找相关问题相关的知识,希望对你有一定的参考价值。
1. 二分查找
1.1 解析
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法,前提是数据结构必须先排好序,可以在对数时间复杂度内完成查找。
二分查找事实上采用的就是一种分治策略,它充分利用了元素间的次序关系,可在最坏的情况下用O(log n)完成搜索任务。
它的基本思想是:假设数组元素呈升序排列,将n个元素分成个数大致相同的两半,取a[n/2]与欲查找的x作比较,如果x=a[n/2]则找到x,算法终止;如 果x<a[n/2],则我们只要在数组a的左半部继续搜索x;如果x>a[n/2],则我们只要在数组a的右 半部继续搜索x。
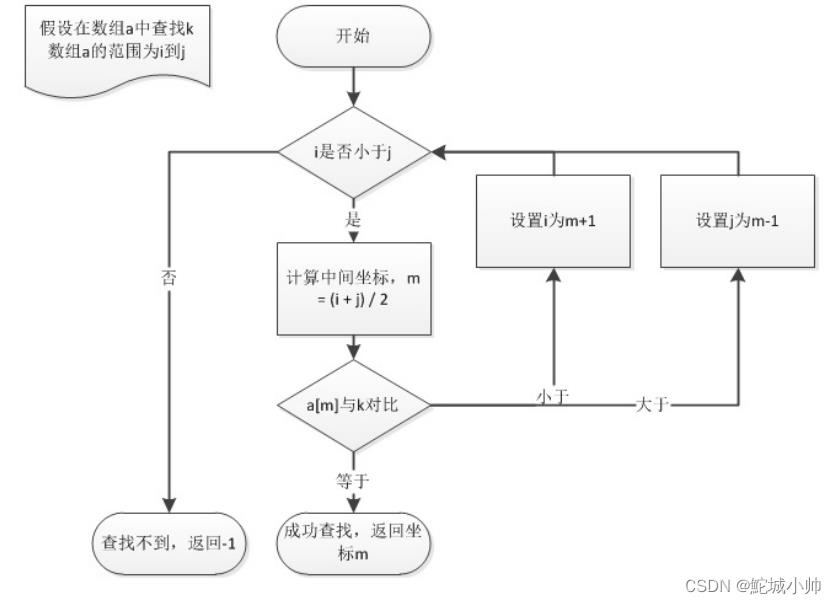
二分查找问题也是面试中经常考到的问题。
1.2 案例代码
用代码实现一个对int数组的二分查找
public static int binarySearch(int[] binary, int key)
// 定义初始查找范围,双指针
int low = 0;
int high = binary.length-1;
if (key < binary[low] && key > binary[high])
return -1;
while (low < high )
int mid = (low + high)/2;
// key 大于中间值,取后半部分
if(key > binary[mid])
low = mid+1;
//key小于中间值,取前半部分
else if (key < binary[mid])
high = mid-1;
else
// key等于当前值
return mid;
return -1;
方法二:递归实现
/**
* 方法二:递归调用
* @param binary
* @param key
* @param fromIndex
* @param toIndex
* @return
*/
public static int binarySearch(int[] binary, int key, int fromIndex, int toIndex)
// 基本判断,当起始位置大于结束位置时,直接返回-1:特殊情况超出最大最小值,直接返回-1
if(key < binary[fromIndex] || key > binary[toIndex] || fromIndex > toIndex)
return -1;
// 计算中间位置
int mid = (fromIndex + toIndex)/2;
// 判断中间位置元素和key的大小关系,更改搜索范围,递归调用
if (binary[mid] < key)
return binarySearch(binary, key, fromIndex, mid -1);
else if (binary[mid] > key)
return binarySearch(binary, key, mid+1, toIndex);
else
return mid;
递归调用,使用空间换取时间。递归调用过程中,栈会一层层的开辟使用,直到最底层返回return。
总结一下二分查找:
- 优点是比较次数少,查找速度快,平均性能好;
- 缺点是要求待查表为有序表,且插入删除困难。
因此,二分查找方法适用于不经常变动而查找频繁的有序列表。使用条件:查找序列是顺序结构,有序。
2.二维矩阵
2.1 题目说明
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。
示例 1:
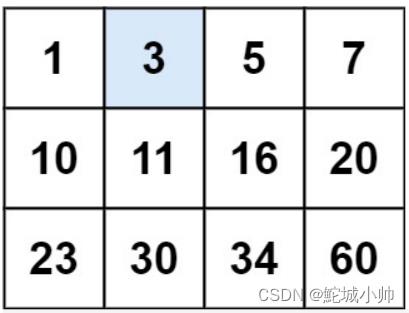
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,50]], target = 3
输出:true
示例 2:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,50]], target = 13
输出:false
示例 3:
输入:matrix = [], target = 0
输出:false
提示:
- m == matrix.length
- n == matrix[i].length
- 0 <= m, n <= 100
- -104 <= matrix[i][j], target <= 104
2.2分析
既然这是一个查找元素的问题,并且数组已经排好序,我们自然可以想到用二分查找是一个高效的查找方式。
输入的 m x n 矩阵可以视为长度为 m x n的有序数组:
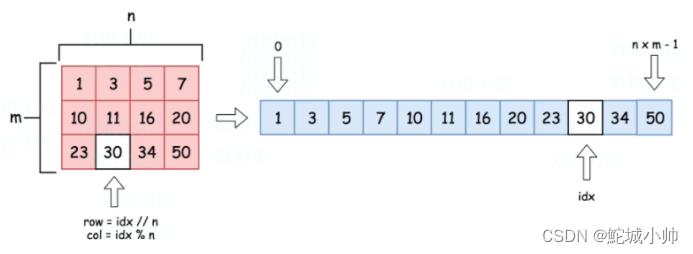
行列坐标为(row, col)的元素,展开之后索引下标为idx = row * n + col;反过来,对于一维下标为idx的元素,对应二维数组中的坐标就应该是:
row = idx / n; col = idx % n;
2.3 实现:二分查找
/**
* 方法一:二分查找
* @param matrix
* @param target
* @return
*/
public static boolean searchMatrix(int[][] matrix, int target)
// 如果长度为0,则必定不存在
int rowLength = matrix.length;
// 获取列长度
int colLength = matrix[0].length;
if (rowLength==0 )
return false;
int left = 0;
int right = rowLength * colLength -1 ;
// 二分查找,定义左右指针,左指针小于等于右指针
while ( left <= right)
// 中间指针
int midIndex = (left + right)/2;
// 获取当前值
int midElement = matrix[midIndex / colLength ][ midIndex % colLength ];
if (midElement < target)
left = midIndex + 1;
else if (midElement > target)
right = midIndex - 1;
else
return true;
;
return false;
复杂度分析
- 时间复杂度 : 由于是标准的二分查找,时间复杂度为O(log(m n))。
- 空间复杂度 : 没有用到额外的空间,复杂度为O(1)。
3. 寻找重复数
3.1 题目说明
给定一个包含 n + 1 个整数的数组 nums,其数字都在 1 到 n 之间(包括 1 和 n),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
示例 1:
输入: [1,3,4,2,2]
输出: 2
示例 2:
输入: [3,1,3,4,2]
输出: 3
说明:
- 不能更改原数组(假设数组是只读的)。
- 只能使用额外的 O(1) 的空间。
- 时间复杂度小于 O(n2) 。
- 数组中只有一个重复的数字,但它可能不止重复出现一次。
3.2 分析
怎样证明 nums 中存在至少一个重复值?其实很简单,这是“抽屉原理”(或者叫“鸽子洞原理”)的简单应用。
这里,nums 中的每个数字(n+1个)都是一个物品,nums 中可以出现的每个不同的数字(n个)都是一个 “抽屉”。把n+1 个物品放入n个抽屉中,必然至少会有一个抽屉放了2个或者2个以上的物品。所以这意味着nums中至少有一个数是重复的。
3.3 方法一:保存元素法(存入HashMap)
首先我们想到,最简单的办法就是,遍历整个数组,挨个统计每个数字出现的次数。
用一个HashMap保存每个数字对应的count数量,就可以直观地判断出是否重复了。
代码如下:
/**
* 方法一:使用HashMap保存每个数出现的次数
* @param nums
* @return
*/
public int findDuplicate(int[] nums)
Map<Integer,Integer> map = new HashMap<>();
// 遍历所有元素,统计count值
for (int num : nums)
// 判断当前 num 是否在 map 中出现
if(map.containsKey(num))
// 如果出现过,num就是重复值
return num;
else
// 没出现过,添加到map
map.put(num,num);
return -1;
3.4 方法二:保存元素法改进(存入Set)
也可以直接保存到一个Set里,就知道这个元素到底有没有了。
/**
* 方法二:使用Set保存每个数
* @param nums
* @return
*/
public int findDuplicate2(int[] nums)
Set<Integer> set = new HashSet<>();
// 遍历所有元素,统计count值
for (int num : nums)
// 判断当前 num 是否在 set 中出现
if(set.contains(num))
// 如果出现过,num就是重复值
return num;
else
// 没出现过,添加到set
set.add(num);
return -1;
复杂度分析
时间复杂度:O(n),我们只对数组做了一次遍历,在HashMap和HashSet中查找的复杂度是O(1)。
空间复杂度:O(n),我们需要一个HashMap或者HashSet来做额外存储,最坏情况下,这需要线性的存储空间。
尽管时间复杂度较小,但以上两种保存元素的方法,都用到了额外的存储空间,这个空间复杂度不能让我们满意。
3.5 方法三:排序法
本方法是先在原数组上排序。
排序之后,所有重复的数会排在一起;这样,只要我们遍历的时候发现连续两个元素相等,就可以输出结果了。
/**
* 方法三:先排序,然后找相邻的相同元素
* @param nums
* @return
*/
public int findDuplicate3(int[] nums)
Arrays.sort(nums);
// 遍历数组元素,遇到跟前一个相同的,就返回
for (int i = 0; i < nums.length; i++)
if(nums[i] == nums[i-1])
return nums[i];
return -1;
复杂度分析
- 时间复杂度: O(nlgn)。对数组排序,在Java 中要花费 O(nlgn) 时间,后续是一个线性扫描,所以总的时间复杂度是O(nlgn)。
- 空间复杂度: O(1) (or O(n)),在这里,我们对 nums 进行了排序,因此内存大小是固定的。当然,这里的前提是我们可以用常数的空间,在原数组上直接排序。如果我们不能修改输入数组,那么我们必须把 nums 拷贝出来,并进行排序,这需要分配线性的额外空间。
3.6 方法四:二分查找
这道题目中数组其实是很特殊的,我们可以从原始的 [1, N] 的自然数序列开始想。现在增加到了N+1个数,根据抽屉原理,肯定会有重复数。对于增加重复数的方式,整体应该有两种可能:
- 如果重复数(比如叫做target)只出现两次,那么其实就是1~N所有数都出现了一次,然后再加一个target;
- 如果重复数target出现多次,那在情况1的基础上,它每多出现一次,就会导致1~N中的其它数少一个。
例如:1~9之间的10个数的数组,重复数是6:
1,2,5,6,6,6,6,6,7,9
本来最简单(重复数出现两次,其它1~9的数都出现一次)的是
1,2,3,4,5,6,6,7,8,9
现在没有3、4和8,所以6会多出现3次。
我们可以发现一个规律:
- 以target为界,对于比target小的数i,数组中所有小于等于它的数,最多出现一次(有可能被多出现的target占用了),所以总个数不会超过i。
- 对于比target大的数j,如果每个元素都只出现一次,那么所有小于等于它的元素是j个;而现在target会重复出现,所以总数一定会大于j。
用数学化的语言描述就是:
我们把对于1~N内的某个数i,在数组中小于等于它的所有元素的个数,记为count[i]。
则:当i属于[1, target-1]范围内,count[i] <= i;当i属于[target, N]范围内,count[i] > i。
所以要找target,其实就是要找1~N中这个分界的数。所以我们可以对1~N的N个自然数进行二分查找,它们可以看作一个排好序的数组,但不占用额外的空间。
/**
* 方法四:二分查找
* @param nums
* @return
*/
public int findDuplicate4(int[] nums)
int left = 1;
int right = nums.length-1;
while (left <= right)
// 计算中间的值
int mid = ( left + right ) / 2;
// 对当前的mid计算count值
int count = 0;
for (int i = 0; i < nums.length; i++)
if (nums[i] < mid) count++;
// 判断count的mid本身的大小关系
if ( count <= mid )
left = mid + 1; // count小于等于mid自身,说明mid比target小,左指针右移
else
right = mid;
// 左右指针重合时,找到target
if (left == right)
return mid;
return -1;
复杂度分析
- 时间复杂度:O(nlog n),其中 n 为nums[] 数组的长度。二分查找最多需要O(logn) 次,而每次判断count的时候需要O(n) 遍历 nums[] 数组求解小于等于 i 的数的个数,因此总时间复杂度为O(nlogn)。
- 空间复杂度:O(1)。我们只需要常数空间存放若干变量。
3.7 方法五:快慢指针(循环检测)
这是一种比较特殊的思路。把nums看成是顺序存储的链表,nums中每个元素的值是下一个链表节点的地址。
那么如果nums有重复值,说明链表存在环,本问题就转化为了找链表中环的入口节点,因此可以用快慢指针解决。
比如数组
[3,6,1,4,6,6,2]
保存为:
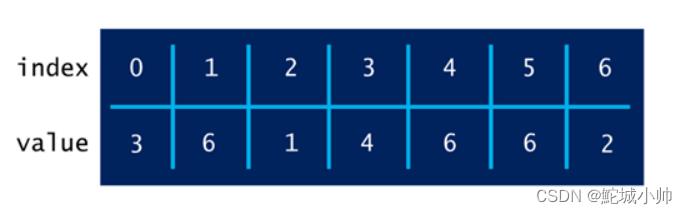
整体思路如下:
- 第一阶段,寻找环中的节点
- 初始时,都指向链表第一个节点nums[0];
- 慢指针每次走一步,快指针走两步;
- 如果有环,那么快指针一定会再次追上慢指针;相遇时,相遇节点必在环中
- 第二阶段,寻找环的入口节点(重复的地址值)
- 重新定义两个指针,让before,after分别指向链表开始节点,相遇节点
- before与after相遇时,相遇点就是环的入口节点
第二次相遇时,应该有:
慢指针总路程 = 环外0到入口 + 环内入口到相遇点 (可能还有 + 环内m圈)
快指针总路程 = 环外0到入口 + 环内入口到相遇点 + 环内n圈
并且,快指针总路程是慢指针的2倍。所以:
环内n-m圈 = 环外0到入口 + 环内入口到相遇点。
把环内项移到同一边,就有:
环内相遇点到入口 + 环内n-m-1圈 = 环外0到入口
这就很清楚了:从环外0开始,和从相遇点开始,走同样多的步数之后,一定可以在入口处相遇。所以第二阶段的相遇点,就是环的入口,也就是重复的元素。
/**
* 方法五:快慢指针
* @param nums
*/
public int finDuplicate5(int[] nums)
// 定义快慢指针
int fast = 0,low = 0;
// 第一阶段:寻找链表中的环
do
// 快指针一次走两步,慢指针一次走一步
low = nums[low];
fast = nums[nums[fast]];
while ( fast != low );
// 第二阶段:寻找环在链上的入口节点
int ptr1 = 0,ptr2 = low;
while ( ptr1 != ptr2)
ptr1 = nums[ptr1];
ptr2 = nums[ptr2];
return ptr1;
复杂度分析
- 时间复杂度:O(n),不管是寻找环上的相遇点,还是环的入口,访问次数都不会超过数组长度。
- 空间复杂度:O(1),我们只需要定义几个指针就可以了。
通过快慢指针循环检测这样的巧妙方法,实现了在不额外使用内存空间的前提下,满足线性时间复杂度O(n)。
以上是关于算法和数据结构解析:3 - 二分查找相关问题的主要内容,如果未能解决你的问题,请参考以下文章