大数据之Spark:Spark面试(初级)
Posted 浊酒南街
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之Spark:Spark面试(初级)相关的知识,希望对你有一定的参考价值。
目录
- 1:介绍一下Spark
- 2:谈一谈Spark的生态体系
- 3:说说Spark的工作流程
- 4:Spark运行模式有哪些?说说你最熟悉的一种
- 5: 谈谈Yarn Cluster和Yarn Client模式的区别
- 6:简单讲下RDD的特性
- 7:RDD的宽依赖和窄依赖了解吗
- 8:你用过的Transformation和Action算子有哪些
- 9:说说job、stage和task的关系
- 10:Spark为什么这么快
1:介绍一下Spark
Apache Spark是一个分布式、内存级计算框架。起初为加州大学伯克利分校AMPLab的实验性项目,后经过开源,在2014年成为Apache基金会顶级项目之一,现已更新至3.2.0版本。
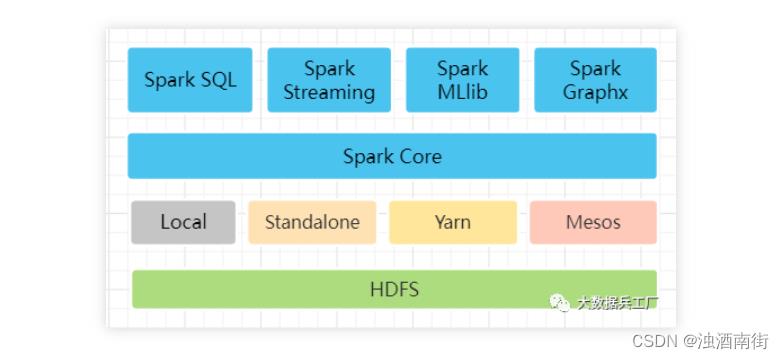
2:谈一谈Spark的生态体系
Spark体系包含Spark Core、Spark SQL、Spark Streaming、Spark MLlib及 Spark Graphx。其中Spark Core为核心组件,提供RDD计算模型。在其基础上的众组件分别提供查询分析、实时计算、机器学、图计算等功能。
3:说说Spark的工作流程
主要考察对Spark运行机制的理解,需要掌握Spark任务提交、资源申请、任务分配等阶段中各组件的协作机制,这里放上Spark官网的工作流程示意图。
Tips: 可结合4、5点运行模式原理展开细说
1、客户端提交任务,创建Driver进程并初始化SparkContext
2、SparkContext向Cluster Manager申请资源
3、Cluster Manager选择合适的worker节点创建executor进程
4、Executor向Driver端注册,并等待其分配task任务
5、SparkContext构建DAG图(有向无环图)、划分stage并分配taskset至Executor
6、Executor启动Task线程执行具体任务

4:Spark运行模式有哪些?说说你最熟悉的一种
Spark的运行模式包括Local、Standalone、Yarn及Mesos几种。其中Local模式仅用于本地开发,Mesos模式国内几乎不用。在公司中因为大数据服务基本搭载Yarn集群调度,因此Spark On Yarn模式会用的比较多。

Standalone模式是Spark内置的运行模式,常用于小型测试集群。这里我就拿Standalone模式来举例:
1、Master为资源调度器,负责executors资源调度
2、Worker负责Executor进程的启动和监控
3、Driver在客户端启动,负责SparkContext初始化

5: 谈谈Yarn Cluster和Yarn Client模式的区别
这是Spark中最普遍的一道面试题,主要是考察对Spark On Yarn 原理掌握的扎实程度。
Yarn Cluster模式的driver进程托管给Yarn(AppMaster)管理,通过yarn UI或者Yarn logs命令查看日志。Yarn Client模式的driver进程运行在本地客户端,因资源调度、任务分发会和Yarn集群产生大量网络通信,出现网络激增现象,适合本地调试,不建议生产上使用。两者具体执行流程整理如下:
Yarn Cluster模式:

Yarn Client模式:

6:简单讲下RDD的特性
RDD(分布式弹性数据集)是Spark的基础数据单元,和mysql数据库中的视图view概念类似,其本身不存储数据,仅作为数据访问的一种虚拟结构。Spark通过对RDD的相互转换操作完成整个计算过程。

分布式:RDD本质上可以看成是一组只读的、可分区的分布式数据集,支持跨节点多台机器上进行并行计算。
弹性:数据优先内存存储,当计算节点内存不够时,可以把数据刷到磁盘等外部存储,且支持手动设定存储级别。
容错性:RDD的血脉机制保存RDD的依赖关系,同时支持Checkpoint容错机制,当RDD结构更新或数据丢失时可对RDD进行重建。
RDD的创建支持从集合List中parallelize()、外部Text/JSON/JDBC等数据源读取、RDD的Transformation转换等方式,以Scala代码为例:

7:RDD的宽依赖和窄依赖了解吗
这又是一道经典的面试题,切记不要忽视细节!Spark中的RDD血脉机制,当RDD数据丢失时,可以根据记录的血脉依赖关系重新计算。而DAG调度中对计算过程划分stage,划分的依据也是RDD的依赖关系。
针对不同的函数转换,RDD之间的依赖关系分为宽依赖和窄依赖。宽依赖会产生shuffle行为,经历map输出、中间文件落地和reduce聚合等过程。

首先,我们看一下Spark官网中对于宽依赖和窄依赖的定义:
宽依赖: 父RDD每个分区被多个子RDD分区使用
窄依赖: 父RDD每个分区被子RDD的一个分区使用
这里需要注意的是,网上有些论调是不正确的,只各自考虑了一种情况:
窄依赖就是一个父分区对应一个子分区(错误)
宽依赖就是一个父分区对应所有子分区(错误)
下面我们结合示意图,分别列出宽依赖和窄依赖存在的四种情况:
窄依赖(一个父RDD对应一个子RDD:map/filter、union算子)

窄依赖(多个父RDD对应一个子RDD:co-partioned join算子)

宽依赖(一个父RDD对应多个非全部子RDD: groupByKey算子等)

宽依赖(一个父RDD对应全部子RDD: not co-partioned join算子)

8:你用过的Transformation和Action算子有哪些
Spark中的Transformation操作会生成一个新的RDD,且具有Lazy特性,不触发任务的实际执行。常见的算子有map、filter、flatMap、groupByKey、join等。一般聚合类算子多数会导致shuffle。
map: 遍历RDD中元素,转换成新元素, 然后用新元素组成一个新的RDD
filter: 遍历RDD中元素进行判断,结果为真则保留,否则删除
flatMap: 与map类似,不过每个元素可返回多个元素
groupByKey: 聚合类算子,根据元素key分组(会产生shuffle)
join: 对包含<key, value>键值对的多个RDD join操作
Action操作是对RDD结果进行聚合或输出,此过程会触发Spark Job任务执行,从而执行之前所有的Transformation操作,结果可返回至Driver端。常见的算子有foreach、reduce、count、saveAsTextFile等。
foreach: 遍历RDD中元素
reduce: 将RDD中的所有元素依次聚合
count: 遍历RDD元素,进行累加计数
saveAsTextFile: 将RDD结果保存到目标源TextFile中
9:说说job、stage和task的关系
Job、stage和task是spark任务执行流程中的三个基本单位。其中job是最大的单位,也是Spark Application任务执行的基本单元,由action算子划分触发生成。
stage隶属于单个job,根据shuffle算子(宽依赖)拆分。单个stage内部可根据数据分区数划分成多个task,由TaskScheduler分发到各个Executor上的task线程中执行。

10:Spark为什么这么快
Spark是一个基于内存的,用于大规模数据处理的统一分析引擎,其运算速度可以达到Mapreduce的10-100倍。具有如下特点:
内存计算。Spark优先将数据加载到内存中,数据可以被快速处理,并可启用缓存。
shuffle过程优化。和Mapreduce的shuffle过程中间文件频繁落盘不同,Spark对Shuffle机制进行了优化,降低中间文件的数量并保证内存优先。
RDD计算模型。Spark具有高效的DAG调度算法,同时将RDD计算结果存储在内存中,避免重复计算。
以上是关于大数据之Spark:Spark面试(初级)的主要内容,如果未能解决你的问题,请参考以下文章