卷积神经网络(CNN)介绍
Posted spearhead_cai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积神经网络(CNN)介绍相关的知识,希望对你有一定的参考价值。
简单介绍和总结卷积神经网络(Convolutional Neural Networks)的基本组成网络层和常用的网络结构。
参考文章/书籍:
简介
CNN可以应用在场景分类,图像分类,现在还可以应用到自然语言处理(NLP)方面的很多问题,比如句子分类等。
LeNet是最早的CNN结构之一,它是由大神Yann LeCun所创造的,主要是用在字符分类问题。
下面是一个简单的CNN结构,图来自参考文章1。这个网络结构是用于一个四类分类的问题,分别是狗、猫、船和鸟,图中的输入图片是属于船一类。
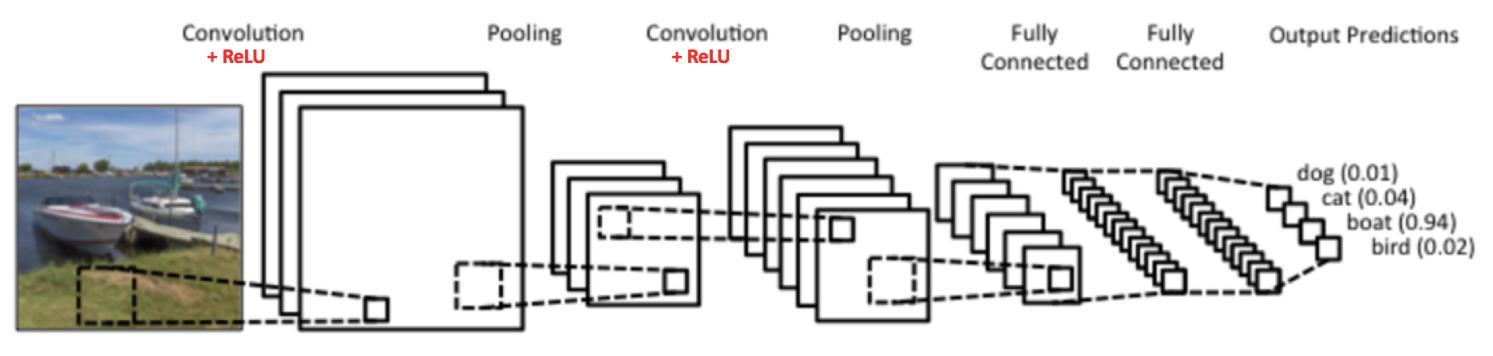
该结构展示了四种运算,也可以说是由四种不同的层,分别是卷积层,非线性层(也就是使用了ReLU函数),Pooling层,全连接层,下面将一一介绍这几种网络层。
卷积层
卷积简介
CNN的名字由来就是因为其使用了卷积运算的缘故。卷积的目的主要是为了提取图片的特征。卷积运算可以保持像素之间的空间关系。
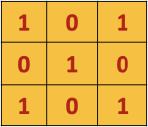
每张图片可以当做是一个包含每个像素值的矩阵,像素值的范围是0~255,0表示黑色,255是白色。下面是一个 5 × 5 5 \\times 5 5×5大小的矩阵例子,它的值是0或者1。

接下来是另一个 3 × 3 3\\times 3 3×3矩阵:
上述两个矩阵通过卷积,可以得到如下图右侧粉色的矩阵结果。
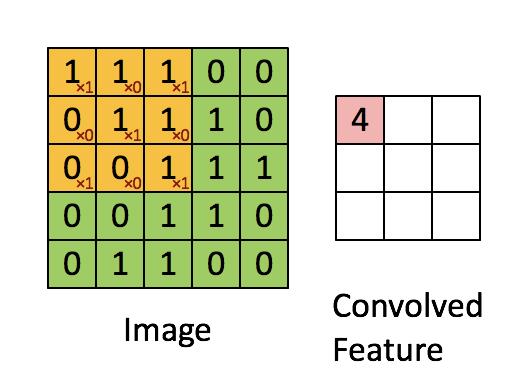
黄色的矩阵在绿色的矩阵上从左到右,从上到下,每次滑动的步进值是1个像素,所以得到一个 3 × 3 3\\times 3 3×3的矩阵。
在CNN中,黄色的矩阵被叫做滤波器(filter)或者核(kernel)或者是特征提取器,而通过卷积得到的矩阵则是称为**“特征图(Feature Map)”或者“Activation Map”**。
另外,使用不同的滤波器矩阵是可以得到不同的 Feature Map ,例子如下图所示:

上图通过滤波器矩阵,实现了不同的操作,比如边缘检测,锐化以及模糊操作等。
在实际应用中,CNN是可以在其训练过程中学习到这些滤波器的值,不过我们需要首先指定好滤波器的大小,数量以及网络的结构。使用越多的滤波器,可以提取到更多的图像特征,网络也就能够有更好的性能。
Feature Map的尺寸是由以下三个参数来决定的:
- 深度(Depth): 深度等于滤波器的数量。
- 步进(Stride): 步进值是在使用滤波器在输入矩阵上滑动的时候,每次滑动的距离。步进值越大,得到的Feature Map的尺寸越小。
- Zero-padding: 有时候可以在输入矩阵的边界填补0,这样就可以将滤波器应用到边缘的像素点上,一个好的Zero-padding是能让我们可以控制好特征图的尺寸的。使用该方法的卷积称为wide convolution,没有使用的则是narrow convolution。
卷积公式和参数量
上一小节简单介绍了卷积的操作和其实现的效果,接下来将介绍卷积运算的公式,以及CNN中卷积层的参数数量。
卷积是大自然中最常见的运算,一切信号观测、采集、传输和处理都可以用卷积过程实现,其用公式表达如下:
KaTeX parse error: No such environment: align at position 8: \\begin̲a̲l̲i̲g̲n̲̲ Y(m,n) & =X(m,…
上述公式中
H
(
m
,
n
)
H(m,n)
H(m,n)表示卷积核。
在CNN中的卷积层的计算步骤与上述公式定义的二维卷积有点差异,首先是维度升至三维、四维卷积,跟二维卷积相比多了一个**“通道”(channel)**,每个通道还是按照二维卷积方式计算,而多个通道与多个卷积核分别进行二维卷积,得到多通道输出,需要“合并”为一个通道;其次是卷积核在卷积计算时没有“翻转”,而是与输入图片做滑动窗口“相关”计算。用公式重新表达如下:
Y
l
(
m
,
n
)
=
X
k
(
m
,
n
)
∗
H
k
l
(
m
,
n
)
=
∑
k
=
0
K
−
1
∑
i
=
0
I
−
1
∑
j
=
0
J
−
1
X
k
(
m
+
i
,
n
+
j
)
H
k
l
(
i
,
j
)
Y^l(m,n) =X^k(m,n)*H^kl(m,n) = \\sum_k=0^K-1\\sum_i=0^I-1\\sum_j=0^J-1X^k(m+i,n+j)H^kl(i,j)
Yl(m,n)=Xk(m,n)∗Hkl(m,n)=k=0∑K−1i=0∑I−1j=0∑J−1Xk(m+i,n+j)Hkl(i,j)
这里假定卷积层有
L
L
L个输出通道和
K
K
K个输入通道,于是需要有
K
L
KL
KL个卷积核实现通道数目的转换。其中
X
k
X^k
Xk表示第
k
k
k个输入通道的二维特征图,
Y
l
Y^l
Yl表示第
l
l
l个输出通道的二维特征图,
H
k
l
H^kl
Hkl表示第
k
k
k行、第
l
l
l列二维卷积核。假定卷积核大小是
I
∗
J
I*J
I∗J,每个输出通道的特征图大小是
M
∗
N
M*N
M∗N,则该层每个样本做一次前向传播时卷积层的计算量是
C
a
l
c
u
l
a
t
i
o
n
s
(
M
A
C
)
=
I
∗
J
∗
M
∗
N
∗
K
∗
L
Calculations(MAC)=I*J*M*N*K*L
Calculations(MAC)=I∗J∗M∗N∗K∗L。
卷积层的学习参数,也就是卷积核数目乘以卷积核的尺寸– P a r a m s = I ∗ J ∗ K ∗ L Params = I*J*K*L Params=I∗J∗K∗L。
这里定义计算量-参数量之比是CPR= C a l c u l a t i o n s / P a r a m s = M ∗ N Calculations/Params=M*N Calculations/Params=M∗N。
因此可以得出结论:卷积层的输出特征图尺寸越大,CPR越大,参数重复利用率越高。若输入一批大小为B的样本,则CPR值可提高B倍。
优点
卷积神经网络通过**『参数减少』与『权值共享』**大大减少了连接的个数,也即需要训练的参数的个数。
假设我们的图像是1000*1000的,则有106个隐层神经元,那么它们全连接的话,也就是每个隐层神经元都连接图像的每个像素点,就有1012个连接,也即1012个权值参数需要训练,这显然是不值得的。但是对于一个只识别特定feature的卷积核,需要大到覆盖整个图像的所有像素点吗?通常是不需要的,**一个特定feature,尤其是第一层需要提取的feature,通常都相当基础,只占图像很小的一部分。所以我们设置一个较小的局部感受区域,比如`10*10`,也即每个神经元只需要和这`10*10`的局部图像相连接,所以106个神经元也就有10^8个连接。这就叫参数减少。**
那什么叫权值共享呢?在上面的局部连接中,106个神经元,每个神经元都对应100个参数,所以是108个参数,那如果每个神经元所对应的参数都是相同的,那需要训练的参数就只有100个了。
这后面隐含的道理在于,这100个参数就是一个卷积核,而卷积核是提取feature的方式,与其在图像上的位置无关,图像一个局部的统计特征与其他局部的统计特征是一样的,我们用在这个局部抽取feature的卷积核也可以用在图像上的其它任何地方。
而且这100个参数只是一种卷积核,只能提取一种feature,我们完全可以采用100个卷积核,提取100种feature,而所需要训练的参数也不过104,最开始我们训练1012个参数,还只能提取一种特征。选取100个卷积核,我们就能得到100张FM,每张FM可以看做是一张图像的不同通道。
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN特征检测层通过训练数据进行学习,在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者,由于同一FM上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,避免了特征提取和分类过程中数据重建的复杂度。
非线性层(ReLU)
非线性修正函数**ReLU(Rectified Linear Unit)**如下图所示:

这是一个对每个像素点实现点乘运算,并用0来替换负值像素点。其目的是在CNN中加入非线性,因为使用CNN来解决的现实世界的问题都是非线性的,而卷积运算是线性运算,所以必须使用一个如ReLU的非线性函数来加入非线性的性质。
其他非线性函数还包括tanh和Sigmoid,但是ReLU函数已经被证明在大部分情况下性能最好。
Pooling层
**空间合并(Spatial Pooling)**也可以叫做子采样或者下采样,可以在保持最重要的信息的同时降低特征图的维度。它有不同的类型,如最大化,平均,求和等等。
对于Max Pooling操作,首先定义一个空间上的邻居,比如一个 2 × 2 2\\times 2 2×2的窗口,对该窗口内的经过ReLU的特征图提取最大的元素。除了提取最大的元素,还可以使用窗口内元素的平均值或者是求和的值。不过,Max Pooling的性能是最好的。例子可以如下图所示:
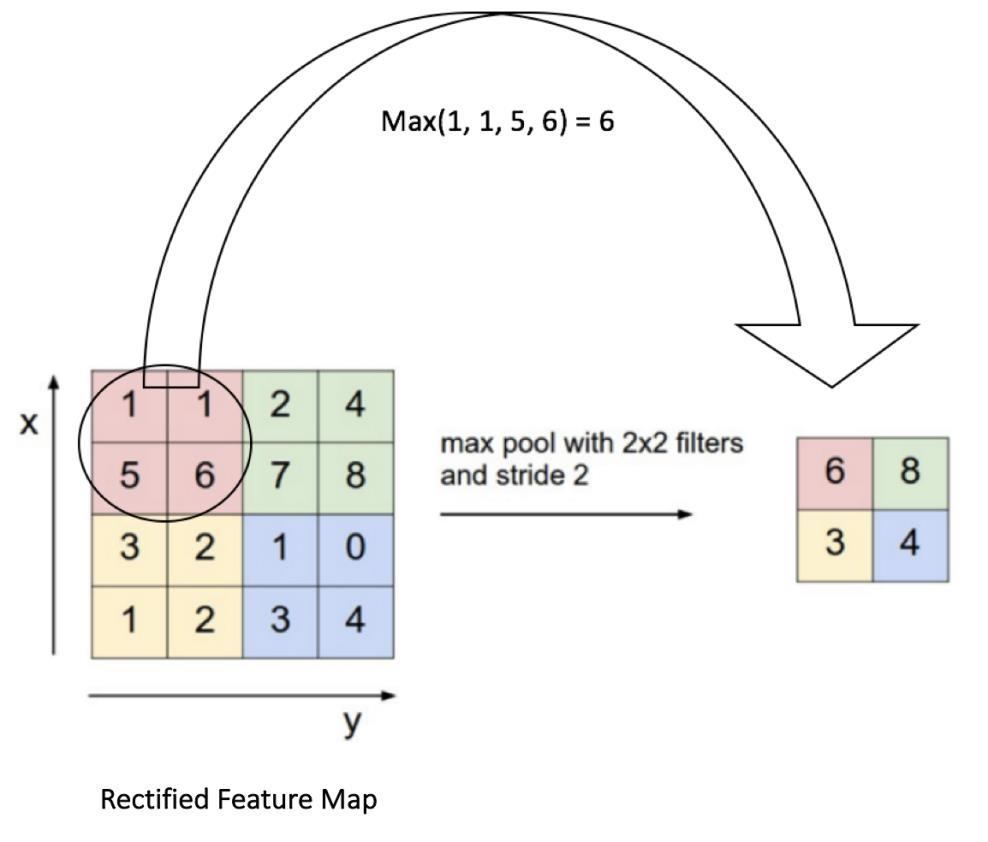
上图中使用的步进值是2。
根据相关理论,特征提取的误差主要来自两个方面:
- 邻域大小受限造成的估计值方差增大;
- 卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。
使用Pooling的原因有如下几点:
- 不变性,更关注是否存在某些特征而不是特征具体的位置。可以看作加了一个很强的先验,让学到的特征要能容忍一些的变化。
- 减小下一层输入大小,减小计算量和参数个数。
- 获得定长输出。(文本分类的时候输入是不定长的,可以通过池化获得定长输出)
- 防止过拟合或有可能会带来欠拟合
全连接层
全连接层就是一个传统的多层感知器,它在输出层使用一个softmax激活函数。其主要作用就是将前面卷积层提取到的特征结合在一起然后进行分类。Softmax函数可以将输入是一个任意实数分数的向量变成一个值的范围是0~1的向量,但所有值的总和是1。
在CNN出现之前,最早的深度学习网络计算类型都是全连接形式的。
全连接层的主要计算类型是**矩阵-向量乘(GEMV)。**假设输入节点组成的向量是 x x x,维度是 D D D,输出节点组成的向量是 y y y,维度是 V V V,则全连接层计算可以表示为 y = W x y=Wx y=Wx。
其中 W W W是 V ∗ D V*D V∗D的权值矩阵。
全连接层的参数量为 P a r a m s = V ∗ D Params=V*D Params=V∗D,其单个样本前向传播的计算量也是 C a l c u l a t i o n s ( M A C ) = V ∗ D Calculations(MAC)=V*D Calculations(MAC)=V∗D,也就是 C P R = C a l c u l a t i o n s / P a r a m s = 1 CPR=Calculations/Params=1 CPR=Calculations/Params=1。也就是其权值利用率很低。
可以将一批大小为 B B B的样本 x i x_i xi逐列拼接成矩阵 X X X,一次性通过全连接层,得到一批输出向量构成的矩阵 Y Y Y,相应地前面的矩阵-向量乘运算升为矩阵-矩阵乘计算(GEMM): Y = W X Y=WX Y=WX。
这样全连接层前向计算量提高了 B B B倍,CPR相应提高了 B B B倍,权重矩阵在多个样本之间实现了共享,可提高计算速度。
比较卷积层和全连接层,卷积层在输出特征图维度实现了权值共享,这是降低参数量的重要举措,同时,卷积层局部连接特性(相比全连接)也大幅减少了参数量。因此卷积层参数量占比小,但计算量占比大,而全连接层是参数量占比大,计算量占比小。所以在进行计算加速优化时,重点放在卷积层;在进行参数优化、权值剪裁时,重点放在全连接层。
激活函数
激活函数是给网络提供非线性的特性,在每个网络层中对输入数据进行非线性变换的作用,这有两个好处。
- 对数据实现归一化操作
激活函数都有各自的取值范围,比如Sigmoid函数取值范围是[0,1],Tanh函数取值范围是[-1,1],这种好处对网络的正反向训练都有好处:
(1)正向计算网络的时候,由于输入数值的大小没有限制,其数值差距会非常大,第一个坏处是大数值会更被重视,而小数值的重要性会被忽视,其次,随着层数加深,这种大数值会不断累积到后面的网络层,最终可能导致数值爆炸溢出的情况;
(2)反向计算网络的时候,每层数值大小范围不同,有的在[0,1],有的在[0,10000],这在模型优化时会对设定反向求导的优化步长增加难度,设置过大会让梯度较大的维度因为过量更新而造成无法预期的结果;设置过小,梯度较小的维度会得不到充分的更新,就无法有所提升。
- 打破之前的线性映射关系。
如果网络只有线性部分,那么叠加多个网络层是没有意义的,因为多层神经网络可以退化为一层神经网络。
反向传播Backpropagation
CNN的整个训练过程如下所示:
- 首先是随机初始化所有滤波器以及其他参数和权重值;
- 输入图片,进行前向传播,也就是经过卷积层,ReLU和pooling运算,最后到达全连接层进行分类,得到一个分类的结果,也就是输出一个包含每个类预测的概率值的向量;
- 计算误差,也就是代价函数,这里代价函数可以有多种计算方法,比较常用的有平方和函数,即 实 际 值 预 测 值 E r r o r = 1 2 ∑ ( 实 际 值 − 预 测 值 ) 2 实际值预测值Error = \\frac12\\sum(实际值-预测值)^2 实际值预测值Error=21∑(实际值−预测值)2;
- 使用反向传播来计算网络中对应各个权重的误差的梯度,一般是使用梯度下降法来更新各个滤波器的权重值,目的是为了让输出的误差,也就是代价函数的值
以上是关于卷积神经网络(CNN)介绍的主要内容,如果未能解决你的问题,请参考以下文章