Java 并发编程 进阶 -- ThreadLocalRandom类原理剖析原子操作类原理剖析(AtomicLong)并发List原理剖析(CopyOnWriteArrayList)
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 并发编程 进阶 -- ThreadLocalRandom类原理剖析原子操作类原理剖析(AtomicLong)并发List原理剖析(CopyOnWriteArrayList)相关的知识,希望对你有一定的参考价值。
文章目录
1. 并发编程线程进阶
1.1 Java并发包中ThreadLocalRandom类原理剖析
ThreadLocalRandom类是JDK 7在JUC包下新增的随机数生成器,它弥补了Random类在多线程下的缺陷。
1.1.1 Random类及其局限性
在JDK 7之前包括现在,java.util.Random都是使用比较广泛的随机数生成工具类,而且java.lang.Math中的随机数生成也使用的是java.util.Random的实例。下面先看看java. util.Random的使用方法:
public static void main(String[] args)
// (1) 创建一个默认种子的随机数生成器
Random random = new Random();
// (2) 输入5个在[0,10)之间的随机数
for (int i = 0; i < 5; i++)
System.out.println(random.nextInt(5));
- 代码(1)创建一个默认随机数生成器,并使用默认的种子。
- 代码(2)输出10个在0~5(包含0,不包含5)之间的随机数。
随机数的生成需要一个默认的种子,这个种子其实是一个long类型的数字,你可以在创建Random对象时通过构造函数指定,如果不指定则在默认构造函数内部生成一个默认的值。有了默认的种子后,如何生成随机数呢?

由此可见,新的随机数的生成需要两个步骤:
- 首先根据老的种子生成新的种子。
- 然后根据新的种子来计算新的随机数。
步骤(4)要保证原子性,也就是说当多个线程根据同一个老种子计算新种子时,第一个线程的新种子被计算出来后,第二个线程要丢弃自己老的种子,而使用第一个线程的新种子来计算自己的新种子,依此类推,只有保证了这个,才能保证在多线程下产生的随机数是随机的。Random函数使用一个原子变量达到了这个效果,在创建Random对象时初始化的种子就被保存到了种子原子变量里面,下面看next()的代码:
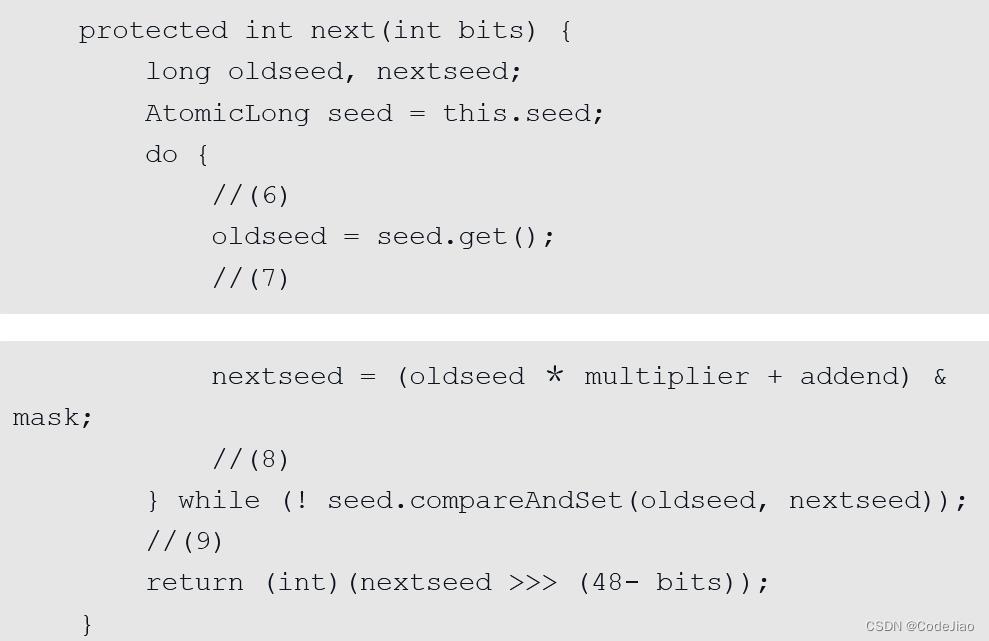
- 代码(6)获取当前原子变量种子的值。
- 代码(7)根据当前种子值计算新的种子。
- 代码(8)使用CAS操作,它使用新的种子去更新老的种子,在多线程下可能多个线程都同时执行到了代码(6),那么可能多个线程拿到的当前种子的值是同一个,然后执行步骤(7)计算的新种子也都是一样的,但是步骤(8)的CAS操作会保证只有一个线程可以更新老的种子为新的,失败的线程会通过循环重新获取更新后的种子作为当前种子去计算老的种子,这就解决了上面提到的问题,保证了随机数的随机性。
- 代码(9)使用固定算法根据新的种子计算随机数。
ThreadLocalRandom产生原因:
每个Random实例里面都有一个原子性的种子变量用来记录当前的种子值,当要生成新的随机数时需要根据当前种子计算新的种子并更新回原子变量。在多线程下使用单个Random实例生成随机数时,当多个线程同时计算随机数来计算新的种子时,多个线程会竞争同一个原子变量的更新操作,由于原子变量的更新是CAS操作,同时只有一个线程会成功,所以会造成大量线程进行自旋重试,这会降低并发性能,所以ThreadLocalRandom应运而生。
1.11.2 ThreadLocalRandom
为了弥补多线程高并发情况下Random的缺陷,在JUC包下新增了ThreadLocalRandom类。下面首先看下如何使用它:
public static void main(String[] args)
// (1) 创建一个默认种子的随机数生成器
ThreadLocalRandom random = ThreadLocalRandom.current();
// (2) 输入5个在[0,10)之间的随机数
for (int i = 0; i < 5; i++)
System.out.println(random.nextInt(5));
其中,代码(1)调用ThreadLocalRandom.current()来获取当前线程的随机数生成器。下面来分析下ThreadLocalRandom的实现原理:
ThreadLocalRandom使用ThreadLocal的原理,让每个线程都持有一个本地的种子变量,该种子变量只有在使用随机数时才会被初始化。在多线程下计算新种子时是根据自己线程内维护的种子变量进行更新,从而避免了竞争。
1.2 Java并发包中原子操作类原理剖析
JUC包提供了一系列的原子性操作类,这些类都是使用非阻塞算法CAS实现的,相比使用锁实现原子性操作这在性能上有很大提高。由于原子性操作类的原理都大致相同,这里讲解最简单的AtomicLong类的实现原理以及JDK 8中新增的LongAdder和LongAccumulator类的原理。有了这些基础,再去理解其他原子性操作类的实现就不会感到困难了。
1.2.1 原子变量操作类(AtomicLong为例)
AtomicLong是原子性递增或者递减类,其内部使用Unsafe来实现,我们看下面的代码:

- 代码(1)通过Unsafe.getUnsafe()方法获取到Unsafe类的实例,这里你可能会有疑问,为何能通过Unsafe.getUnsafe()方法获取到Unsafe类的实例?其实这是因为AtomicLong类也是在rt.jar包下面的,AtomicLong类就是通过BootStarp类加载器进行加载的。
- 代码(5)中的value被声明为volatile的,这是为了在多线程下保证内存可见性,value是具体存放计数的变量。
- 代码(2)(4)获取value变量在AtomicLong类中的偏移量。
下面重点看下AtomicLong中的主要函数:
递增和递减操作代码:
 在如上代码内部都是通过调用Unsafe的getAndAddLong方法来实现操作,这个函数是个原子性操作,这里第一个参数是AtomicLong实例的引用,第二个参数是value变量在AtomicLong中的偏移值,第三个参数是要设置的第二个变量的值。
在如上代码内部都是通过调用Unsafe的getAndAddLong方法来实现操作,这个函数是个原子性操作,这里第一个参数是AtomicLong实例的引用,第二个参数是value变量在AtomicLong中的偏移值,第三个参数是要设置的第二个变量的值。
boolean compareAndSet(long expect, long update)方法:
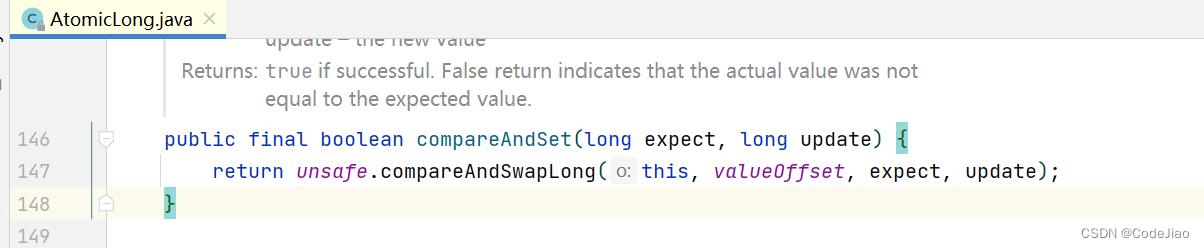
在内部调用了unsafe.compareAndSwapLong方法。如果原子变量中的value值等于expect,则使用update值更新该值并返回true,否则返回false。
示例代码:多线程使用AtomicLong统计0的个数。
public class Atomic
// (10) 创建Long型原子计数器
private static final AtomicLong atomicLong = new AtomicLong();
// (11) 创建数据源
private static final Integer[] arrayOne = new Integer[]0, 1, 2, 3, 0, 5, 6, 0, 56, 0;
private static final Integer[] arrayTwo = new Integer[]10, 1, 2, 3, 0, 5, 6, 0, 56, 0;
public static void main(String[] args) throws InterruptedException
//(12)线程one统计数组arrayOne中0的个数
Thread threadOne = new Thread(() ->
int size = arrayOne.length;
for (Integer integer : arrayOne)
if (integer == 0)
atomicLong.incrementAndGet();
);
//(13)线程two统计数组arrayTwo中0的个数
Thread threadTwo = new Thread(() ->
int size = arrayTwo.length;
for (Integer integer : arrayTwo)
if (integer == 0)
atomicLong.incrementAndGet();
);
// (14) 启动子线程
threadOne.start();
threadTwo.start();
// (15) 等待线程执行完毕
threadOne.join();
threadTwo.join();
System.out.println("arrayOne & arrayTwo 0 的个数是: " + atomicLong.get());
运行结果:
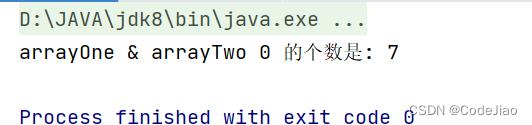
如上代码中的两个线程各自统计自己所持数据中0的个数,每当找到一个0就会调用AtomicLong的原子性递增方法。
在没有原子类的情况下,实现计数器需要使用一定的同步措施,比如使用synchronized关键字等,但是这些都是阻塞算法,对性能有一定损耗,而本章介绍的这些原子操作类都使用CAS非阻塞算法,性能更好。
但是在高并发情况下AtomicLong还会存在性能问题。JDK 8提供了一个在高并发下性能更好的LongAdder类,下面我们来讲解这个类。
1.2.2 JDK 8新增的原子操作类LongAdder
AtomicLong通过CAS提供了非阻塞的原子性操作,相比使用阻塞算法的同步器来说它的性能已经很好了,但是JDK开发组并不满足于此。使用AtomicLong时,在高并发下大量线程会同时去竞争更新同一个原子变量,但是由于同时只有一个线程的CAS操作会成功,这就造成了大量线程竞争失败后,会通过无限循环不断进行自旋尝试CAS的操作,而这会白白浪费CPU资源。
因此JDK 8新增了一个原子性递增或者递减类LongAdder用来克服在高并发下使用AtomicLong的缺点。既然AtomicLong的性能瓶颈是由于过多线程同时去竞争一个变量的更新而产生的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源,是不是就解决了性能问题?是的,LongAdder就是这个思路。下面通过图来理解两者设计的不同之处,如图所示。
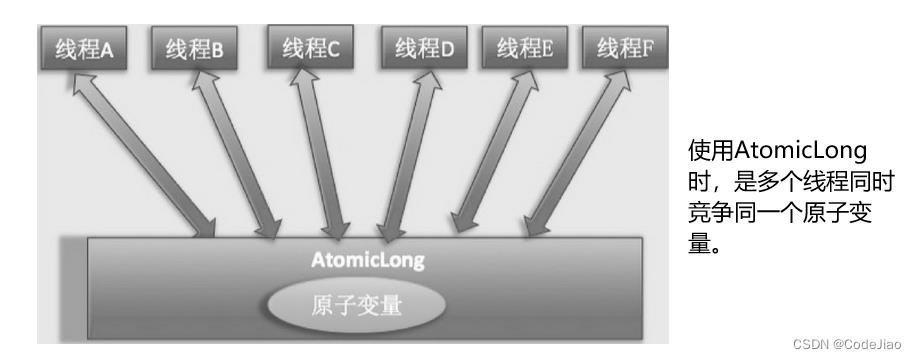
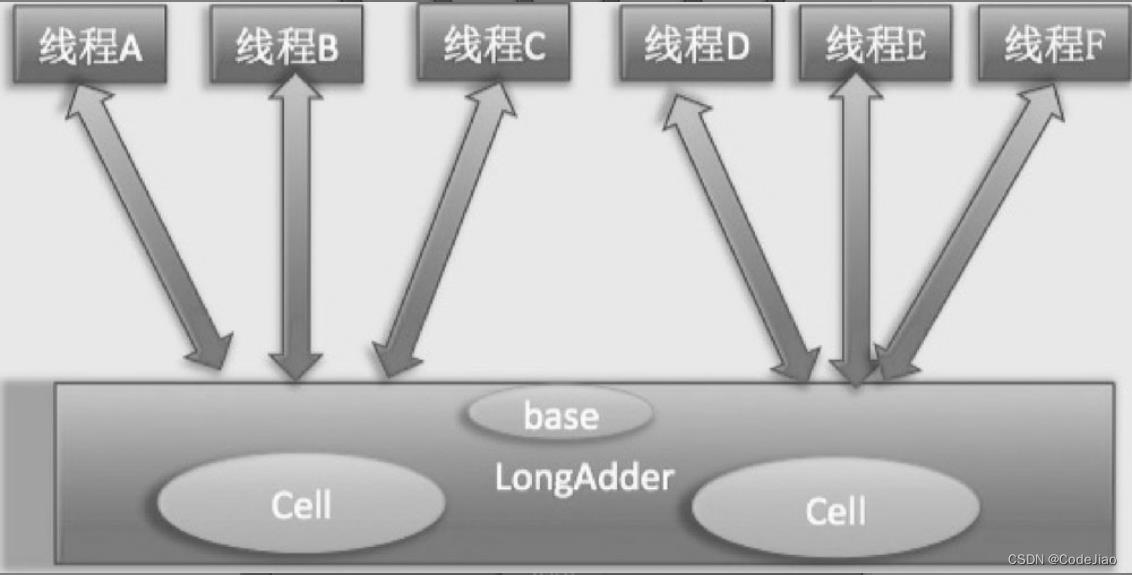
使用LongAdder时,则是在内部维护多个Cell变量,每个Cell里面有一个初始值为0的long型变量,这样,在同等并发量的情况下,争夺单个变量更新操作的线程量会减少,这变相地减少了争夺共享资源的并发量。另外,多个线程在争夺同一个Cell原子变量时如果失败了,它并不是在当前Cell变量上一直自旋CAS重试,而是尝试在其他Cell的变量上进行CAS尝试,这个改变增加了当前线程重试CAS成功的可能性。最后,在获取LongAdder当前值时,是把所有Cell变量的value值累加后再加上base返回的。
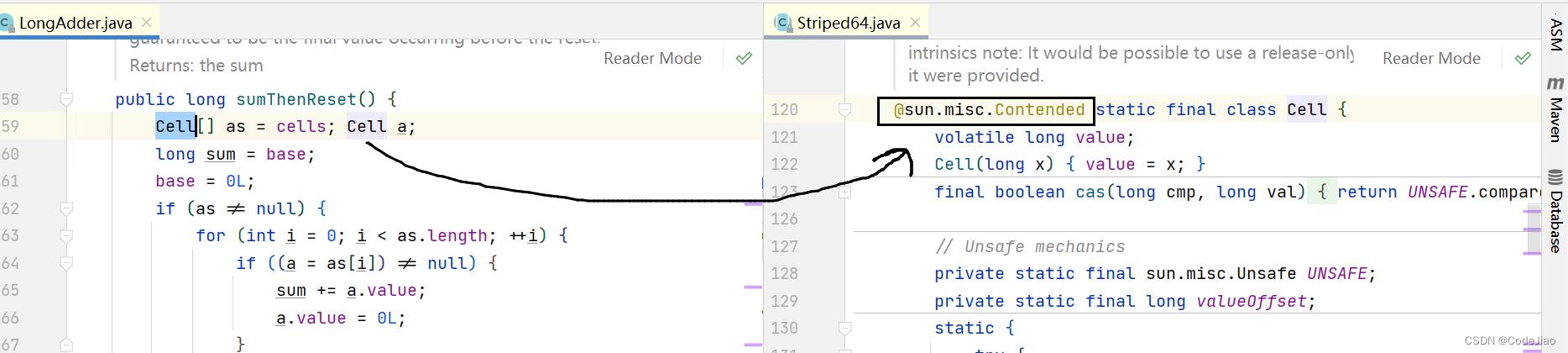
该类通过内部cells数组分担了高并发下多线程同时对一个原子变量进行更新时的竞争量,让多个线程可以同时对cells数组里面的元素进行并行的更新操作。另外,数组元素Cell使用@sun.misc.Contended注解进行修饰,这避免了cells数组内多个原子变量被放入同一个缓存行,也就是避免了伪共享,这对性能也是一个提升。
1.2.3 LongAccumulator类原理探究
LongAdder类是LongAccumulator的一个特例,LongAccumulator比LongAdder的功能更强大。例如下面的构造函数,其中accumulatorFunction是一个双目运算器接口,其根据输入的两个参数返回一个计算值,identity则是LongAccumulator累加器的初始值。
 上面提到,LongAdder其实是LongAccumulator的一个特例,调用LongAdder就相当于使用下面的方式调用LongAccumulator:
上面提到,LongAdder其实是LongAccumulator的一个特例,调用LongAdder就相当于使用下面的方式调用LongAccumulator:

LongAccumulator相比于LongAdder,可以为累加器提供非0的初始值,后者只能提供默认的0值。另外,前者还可以指定累加规则,比如不进行累加而进行相乘,只需要在构造LongAccumulator时传入自定义的双目运算器即可,后者则内置累加的规则。
1.3 Java并发包中并发List原理剖析
1.3.1 CopyOnWriteArrayList介绍
并发包中的并发List只有CopyOnWriteArrayList。CopyOnWriteArrayList是一个线程安全的ArrayList,对其进行的修改操作都是在底层的一个复制的数组(快照)上进行的,也就是使用了写时复制策略。
CopyOnWriteArraylist的类图结构如图:
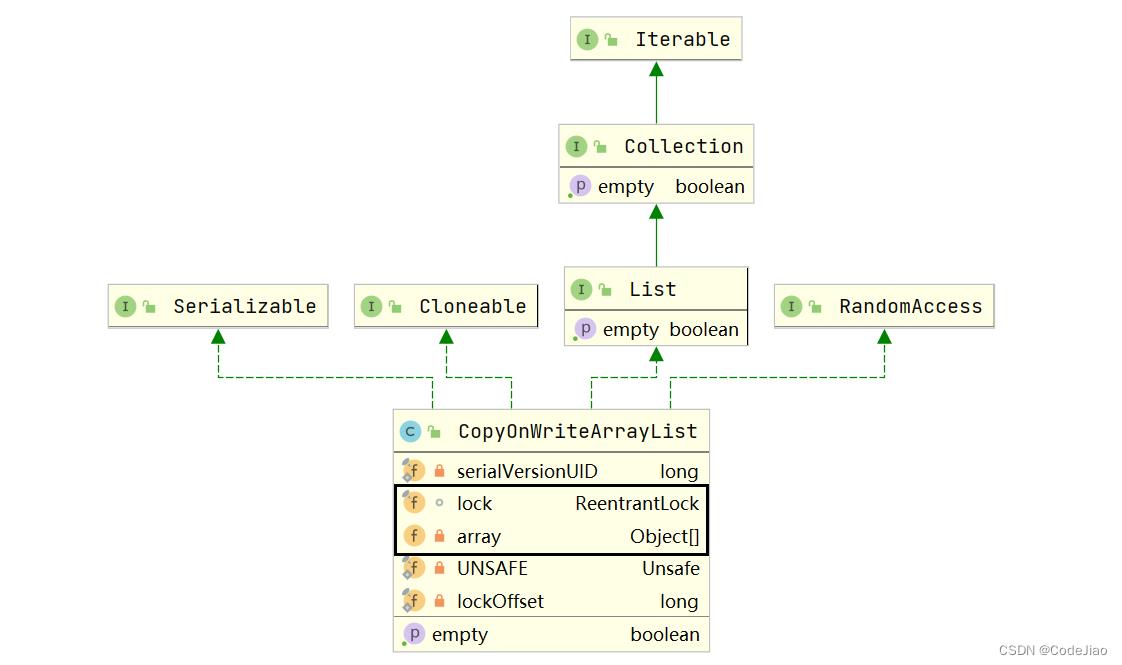
在CopyOnWriteArrayList的类图中,每个CopyOnWriteArrayList对象里面有一个array数组对象用来存放具体元素,ReentrantLock独占锁对象用来保证同时只有一个线程对array进行修改。
CopyOnWriteArrayList使用写时复制的策略来保证list的一致性,而获取—修改—写入三步操作并不是原子性的,所以在增删改的过程中都使用了独占锁,来保证在某个时间只有一个线程能对list数组进行修改。另外CopyOnWriteArrayList提供了弱一致性的迭代器,从而保证在获取迭代器后,其他线程对list的修改是不可见的,迭代器遍历的数组是一个快照。
独占锁介绍:
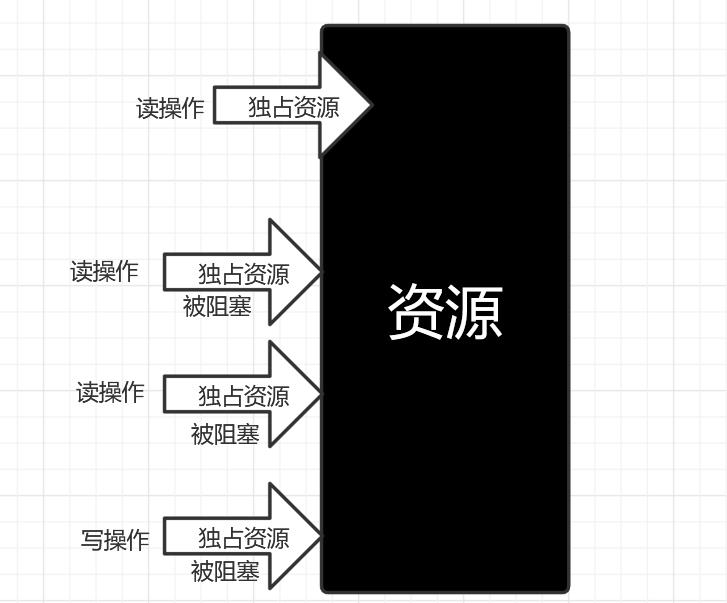
独占锁是一种思想: 只能有一个线程获取锁,以独占的方式持有锁。和悲观锁、互斥锁同义。
Java中用到的独占锁: synchronized,ReentrantLock。
1.3.3 弱一致性的迭代器
遍历列表元素可以使用迭代器。在讲解什么是迭代器的弱一致性前,先举一个例子来说明如何使用迭代器:
public static void main(String[] args)
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("Hello");
list.add("World");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext())
System.out.println(iterator.next());
运行结果:
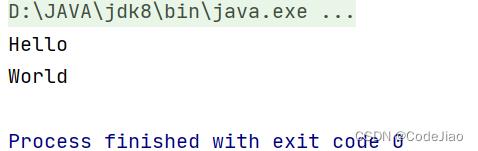
迭代器的hasNext方法用于判断列表中是否还有元素,next方法则具体返回元素。好了,下面来看CopyOnWriteArrayList中迭代器的弱一致性是怎么回事,所谓弱一致性是指返回迭代器后,其他线程对list的增删改对迭代器是不可见的,下面看看这是如何做到的。
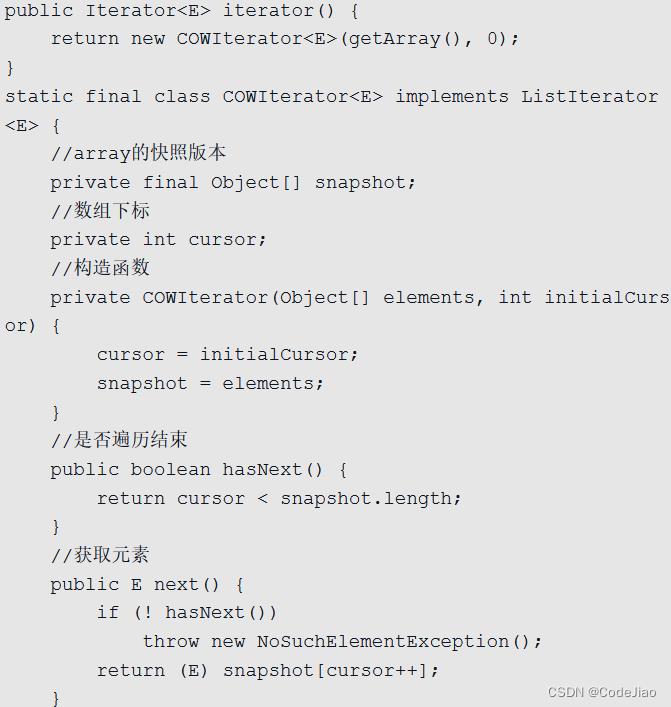
在如上代码中,当调用iterator()方法获取迭代器时实际上会返回一个COWIterator对象,COWIterator对象的snapshot变量保存了当前list的内容,cursor是遍历list时数据的下标。
为什么说snapshot是list的快照呢?明明是指针传递的引用啊,而不是副本。如果在该线程使用返回的迭代器遍历元素的过程中,其他线程没有对list进行增删改,那么snapshot本身就是list的array,因为它们是引用关系。但是如果在遍历期间其他线程对该list进行了增删改,那么snapshot就是快照了,因为增删改后list里面的数组被新数组替换了,这时候老数组被snapshot引用。这也说明获取迭代器后,使用该迭代器元素时,其他线程对该list进行的增删改不可见,因为它们操作的是两个不同的数组,这就是弱一致性。
示例:演示多线程下迭代器的弱一致性的效果。
public class Atomic
private static final CopyOnWriteArrayList<String> arrayList = new
CopyOnWriteArrayList<>();
public static void main(String[] args) throws InterruptedException
arrayList.add("hello");
arrayList.add("alibaba");
arrayList.add("welcome");
arrayList.add("to");
arrayList.add("hangzhou");
Thread threadOne = new Thread(() ->
//修改list中下标为1的元素为baba
arrayList.set(1, "baba");
//删除元素
arrayList.remove(2);
arrayList.remove(3);
);
//保证在修改线程启动前获取迭代器
Iterator<String> itr = arrayList.iterator();
threadOne.start();
// 保证threadOne的run方法执行完毕(完成对arrayList的修改)
Thread.sleep(1000);
while (itr.hasNext()) System.out.println(itr.next());
运行结果:
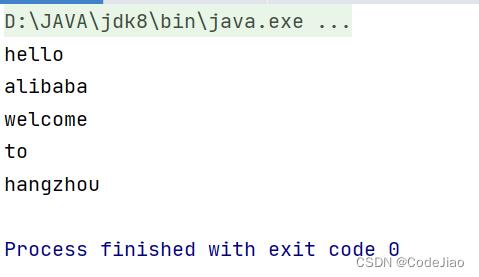
在如上代码中,main函数首先初始化了arrayList,然后在启动线程前获取到了arrayList迭代器。子线程threadOne启动后首先修改了arrayList的第一个元素的值,然后删除了arrayList中下标为2和3的元素。主线程在子线程执行完毕后使用获取的迭代器遍历数组元素,从输出结果我们知道,在子线程里面进行的操作一个都没有生效,这就是迭代器弱一致性的体现。需要注意的是,获取迭代器的操作必须在子线程操作之前进行。
以上是关于Java 并发编程 进阶 -- ThreadLocalRandom类原理剖析原子操作类原理剖析(AtomicLong)并发List原理剖析(CopyOnWriteArrayList)的主要内容,如果未能解决你的问题,请参考以下文章