有空就学学的实例分割1——Tensorflow2搭建Mask R-CNN实例分割平台
Posted Bubbliiiing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有空就学学的实例分割1——Tensorflow2搭建Mask R-CNN实例分割平台相关的知识,希望对你有一定的参考价值。
有空就学学的实例分割1——Tensorflow2搭建Mask R-CNN实例分割平台
学习前言
把Mask RCNN用tensorflow2实现了一遍,至少要跟得上时代对不对。

什么是Mask R-CNN
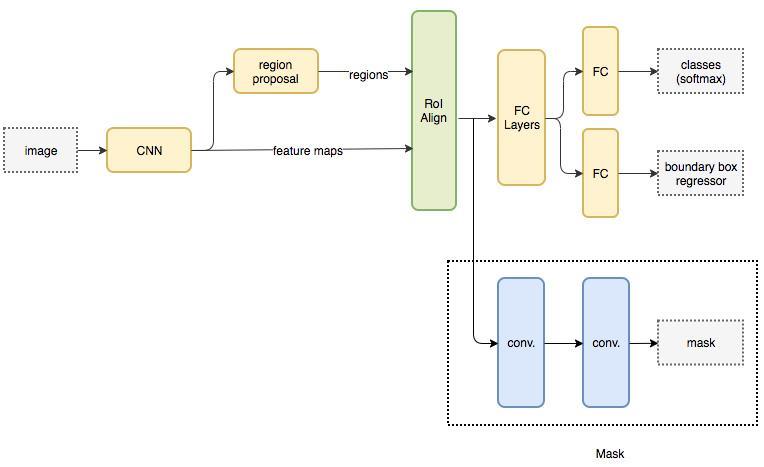
Mask R-CNN是He Kaiming大神2017年的力作,其在进行目标检测的同时进行实例分割,取得了出色的效果。
其网络的设计也比较简单,在Faster R-CNN基础上,在原本的两个分支上(分类+坐标回归)增加了一个分支进行语义分割,
源码下载
https://github.com/bubbliiiing/mask-rcnn-tf2
喜欢的可以点个star噢。
Mask R-CNN实现思路
一、预测部分
1、主干网络介绍
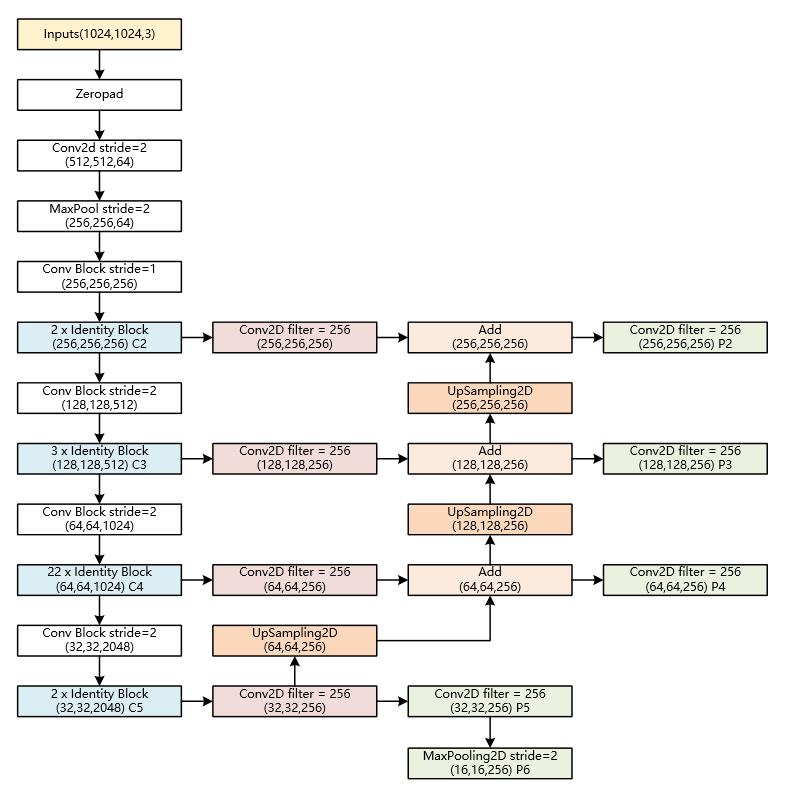
Mask-RCNN使用Resnet101作为主干特征提取网络,对应着图像中的CNN部分,其对输入进来的图片有尺寸要求,需要可以整除2的6次方。在进行特征提取后,利用长宽压缩了两次、三次、四次、五次的特征层来进行特征金字塔结构的构造。
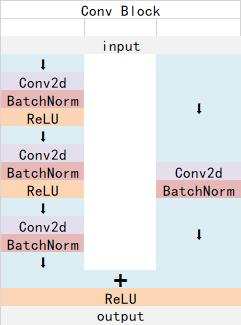
ResNet101有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
Conv Block的结构如下:
Identity Block的结构如下:
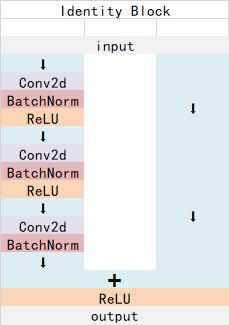
这两个都是残差网络结构。
以官方使用的coco数据集输入的shape为例,输入的shape为1024x1024,shape变化如下:
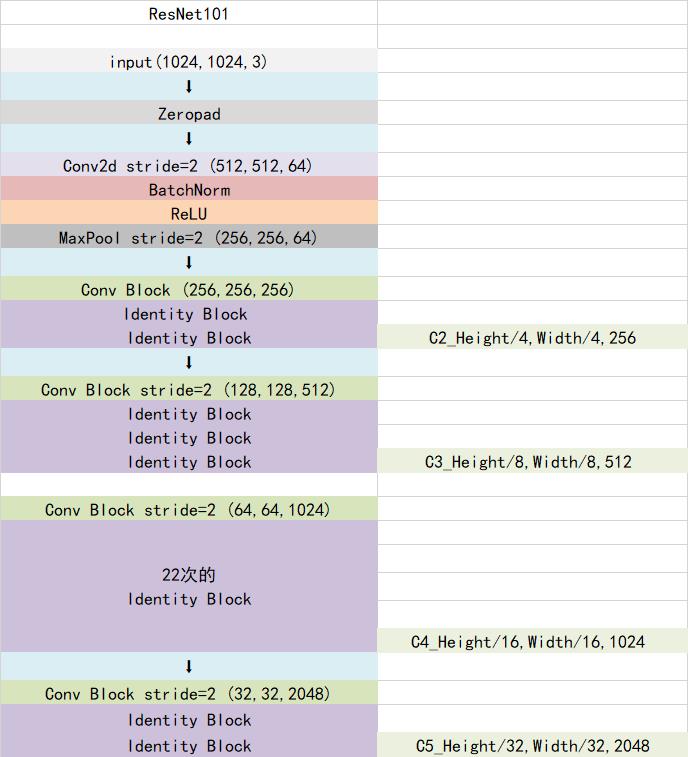
我们取出长宽压缩了两次、三次、四次、五次的结果来进行特征金字塔结构的构造。
实现代码:
from tensorflow.keras.layers import (Activation, Add, BatchNormalization,
Conv2D, MaxPooling2D, ZeroPadding2D)
from tensorflow.keras.regularizers import l2
#----------------------------------------------#
# conv_block和identity_block的区别主要就是:
# conv_block会压缩输入进来的特征层的宽高
# identity_block用于加深网络
#----------------------------------------------#
def identity_block(input_tensor, kernel_size, filters, stage, block, use_bias=True, weight_decay=0, train_bn=True):
nb_filter1, nb_filter2, nb_filter3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(nb_filter1, (1, 1), name=conv_name_base + '2a', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', name=conv_name_base + '2b', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name=bn_name_base + '2b')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter3, (1, 1), name=conv_name_base + '2c', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name=bn_name_base + '2c')(x, training=train_bn)
x = Add()([x, input_tensor])
x = Activation('relu', name='res' + str(stage) + block + '_out')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2), use_bias=True, weight_decay=0, train_bn=True):
nb_filter1, nb_filter2, nb_filter3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(nb_filter1, (1, 1), strides=strides, name=conv_name_base + '2a', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', name=conv_name_base + '2b', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name=bn_name_base + '2b')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter3, (1, 1), name=conv_name_base + '2c', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name=bn_name_base + '2c')(x, training=train_bn)
shortcut = Conv2D(nb_filter3, (1, 1), strides=strides, name=conv_name_base + '1', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(input_tensor)
shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut, training=train_bn)
x = Add()([x, shortcut])
x = Activation('relu', name='res' + str(stage) + block + '_out')(x)
return x
#----------------------------------------------#
# 获得resnet的主干部分
#----------------------------------------------#
def get_resnet(input_image, train_bn=True, weight_decay=0):
#----------------------------------------------#
# 假设输入进来的图片为1024,1024,3
#----------------------------------------------#
# 1024,1024,3 -> 512,512,64
x = ZeroPadding2D((3, 3))(input_image)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1', use_bias=True, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name='bn_conv1')(x, training=train_bn)
x = Activation('relu')(x)
# 512,512,64 -> 256,256,64
x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
C1 = x
# 256,256,64 -> 256,256,256
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1), weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c', weight_decay=weight_decay, train_bn=train_bn)
C2 = x
# 256,256,256 -> 128,128,512
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d', weight_decay=weight_decay, train_bn=train_bn)
C3 = x
# 128,128,512 -> 64,64,1024
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a', weight_decay=weight_decay, train_bn=train_bn)
block_count = 22
for i in range(block_count):
x = identity_block(x, 3, [256, 256, 1024], stage=4, block=chr(98 + i), weight_decay=weight_decay, train_bn=train_bn)
C4 = x
# 64,64,1024 -> 32,32,2048
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c', weight_decay=weight_decay, train_bn=train_bn)
C5 = x
return [C1, C2, C3, C4, C5]
2、特征金字塔FPN的构建
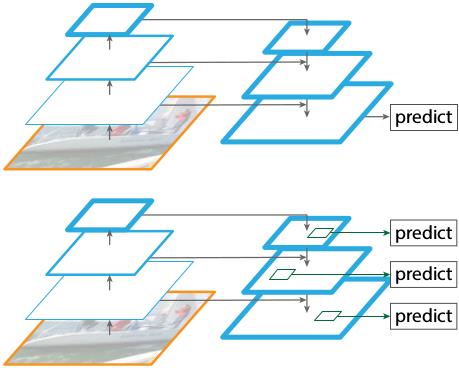
特征金字塔FPN的构建是为了实现特征多尺度的融合,在Mask R-CNN当中,我们取出在主干特征提取网络中长宽压缩了两次C2、三次C3、四次C4、五次C5的结果来进行特征金字塔结构的构造。
提取到的P2、P3、P4、P5、P6可以作为RPN网络的有效特征层,利用RPN建议框网络对有效特征层进行下一步的操作,对先验框进行解码获得建议框。
提取到的P2、P3、P4、P5可以作为Classifier和Mask网络的有效特征层,利用Classifier预测框网络对有效特征层进行下一步的操作,对建议框解码获得最终预测框;利用Mask语义分割网络对有效特征层进行下一步的操作,获得每一个预测框内部的语义分割结果。
实现代码如下:
#----------------------------------------------#
# 组合成特征金字塔的结构
# P5长宽共压缩了5次
# P5为32,32,256
#----------------------------------------------#
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
#----------------------------------------------#
# 将P5上采样和P4进行相加
# P4长宽共压缩了4次
# P4为64,64,256
#----------------------------------------------#
P4 = Add(name="fpn_p4add")([
UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
#----------------------------------------------#
# 将P4上采样和P3进行相加
# P3长宽共压缩了3次
# P3为128,128,256
#----------------------------------------------#
P3 = Add(name="fpn_p3add")([
UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
#----------------------------------------------#
# 将P3上采样和P2进行相加
# P2长宽共压缩了2次
# P2为256,256,256
#----------------------------------------------#
P2 = Add(name="fpn_p2add")([
UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
#-----------------------------------------------------------#
# 各自进行一次256通道的卷积,此时P2、P3、P4、P5通道数相同
# P2为256,256,256
# P3为128,128,256
# P4为64,64,256
# P5为32,32,256
#-----------------------------------------------------------#
P2 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
#----------------------------------------------#
# 在建议框网络里面还有一个P6用于获取建议框
# P5为16,16,256
#----------------------------------------------#
P6 = MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
#----------------------------------------------#
# P2, P3, P4, P5, P6可以用于获取建议框
#----------------------------------------------#
rpn_feature_maps = [P2, P3, P4, P5, P6]
#----------------------------------------------#
# P2, P3, P4, P5用于获取mask信息
#----------------------------------------------#
mrcnn_feature_maps = [P2, P3, P4, P5]
3、获得Proposal建议框
由上一步获得的有效特征层在图像中就是Feature Map,其有两个应用,一个是和ROIAsign结合使用、另一个是进入到Region Proposal Network进行建议框的获取。
在进行建议框获取的时候,我们使用的有效特征层是P2、P3、P4、P5、P6,它们使用同一个RPN建议框网络获取先验框调整参数,还有先验框内部是否包含物体。
在Mask R-cnn中,RPN建议框网络的结构和Faster RCNN中的RPN建议框网络类似。
首先进行一次3x3的通道数为512的卷积。
然后再分别进行一次anchors_per_location x 4的卷积 和一次anchors_per_location x 2的卷积。
anchors_per_location x 4的卷积 用于预测 公用特征层上 每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为Faster-RCNN的预测结果需要结合先验框获得预测框,预测结果就是先验框的变化情况。)
anchors_per_location x 2的卷积 用于预测 公用特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
当我们输入的图片的shape是1024x1024x3的时候,公用特征层的shape就是256x256x256、128x128x256、64x64x256、32x32x256、16x16x256,相当于把输入进来的图像分割成不同大小的网格,然后每个网格默认存在3(anchors_per_location )个先验框,这些先验框有不同的大小,在图像上密密麻麻。
anchors_per_location x 4的卷积的结果会对这些先验框进行调整,获得一个新的框。
anchors_per_location x 2的卷积会判断上述获得的新框是否包含物体。
到这里我们可以获得了一些有用的框,这些框会利用anchors_per_location x 2的卷积判断是否存在物体。
到此位置还只是粗略的一个框的获取,也就是一个建议框。然后我们会在建议框里面继续找东西。
实现代码为:
#------------------------------------#
# 五个不同大小的特征层会传入到
# RPN当中,获得建议框
#------------------------------------#
def rpn_graph(feature_map, anchors_per_location, weight_decay=0):
#------------------------------------#
# 利用一个3x3卷积进行特征整合
#------------------------------------#
shared = Conv2D(512, (3, 3), padding='same', activation='relu',
name='rpn_conv_shared', kernel_regularizer=l2(weight_decay))(feature_map)
#------------------------------------#
# batch_size, num_anchors, 2
# 代表这个先验框是否包含物体
#------------------------------------#
x = Conv2D(anchors_per_location * 2, (1, 1), padding='valid', activation='linear', name='rpn_class_raw', kernel_regularizer=l2(weight_decay))(shared)
rpn_class_logits = Reshape([-1,2])(x)
rpn_probs = Activation("softmax", name="rpn_class_xxx")(rpn_class_logits)
#------------------------------------#
# batch_size, num_anchors, 4
# 这个先验框的调整参数
#------------------------------------#
x = Conv2D(anchors_per_location * 4, (1, 1), padding="valid", activation='linear', name='rpn_bbox_pred', kernel_regularizer=l2(weight_decay))(shared)
rpn_bbox = Reshape([-1, 4])(x)
return [rpn_class_logits, rpn_probs, rpn_bbox]
#------------------------------------#
# 建立建议框网络模型
# RPN模型
#------------------------------------#
def build_rpn_model(anchors_per_location, depth, weight_decay=0):
input_feature_map = Input