Zookeeper集群搭建详细过程 | 附带详细过程截图
Posted 大数据小禅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper集群搭建详细过程 | 附带详细过程截图相关的知识,希望对你有一定的参考价值。
🚀 作者 :“大数据小禅”
🚀 简介:详细讲解Zookeeper的环境搭建,附带过程截图。
🚀 安装包获取:获取对应的安装包可以通过最下方公众号联系我备注获取。
1.Zookeeper简介
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive)等等一些大数据组件。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
2.Zookeeper环境搭建
1.解压安装包,采用3.5.7版本的安装包。集群一共三台机器,在主节点Node1进行配置后分发给其他两台机器。
tar -zxvf zookeeper-3.5.7.tar.gz -C /app
2.创建zkData存放集群数据
cd /app/zookeeper-3.5.7
mkdir zkData
3.创建myid文件,添加与server对应的编号
cd zkData
vim myid
#在myid文件中输入1之后保存。 这里要注意的是,每台机器的myid都要不一样
4.配置zoo.cfg文件
#进入到安装包的conf目录,编辑配置文件模板
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
#修改以下内容
------------------------------------------
#修改配置dataDir
dataDir=/app/zookeeper-3.5.7/zkData
#文件增加如下配置 编号就代表了集群的myid
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
5.分发集群安装包
scp -r zookeeper-3.5.7/ node2:/app/
scp -r zookeeper-3.5.7/ node3:/app/
6.修改node2,node3机器的myid
#修改集群其他机器的myid,node2改成2,node3改成3.同样是编辑zkData文件,修改里面的数字即可
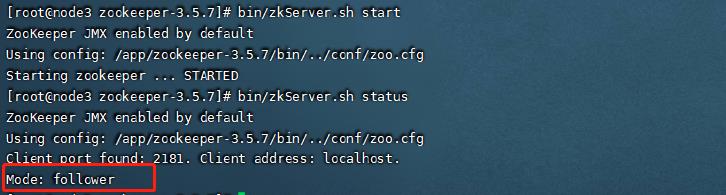
7.启动集群
在安装包的根目录下运行bin/zkServer.sh start可以启动zookeeper,使用bin/zkServer.sh status可以查看到集群的模式,是follower还是leader
启动后可以使用jps看到对应的进程。



欢迎小伙伴们 点赞👍、收藏⭐、留言💬
👇🏻 关注公众号: 大数据小禅👇🏻,获取对应安装包与资料
以上是关于Zookeeper集群搭建详细过程 | 附带详细过程截图的主要内容,如果未能解决你的问题,请参考以下文章