读点论文EfficientNetV2: Smaller Models and Faster Training 训练感知的神经架构搜索+自适应的渐近训练方法优化训练(TPU,大数据量)
Posted 羞儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读点论文EfficientNetV2: Smaller Models and Faster Training 训练感知的神经架构搜索+自适应的渐近训练方法优化训练(TPU,大数据量)相关的知识,希望对你有一定的参考价值。
EfficientNetV2: Smaller Models and Faster Training
Abstract
- 本文介绍了EfficientNetV2,这是一个新的卷积网络系列,与以前的模型相比,具有更快的训练速度和更好的参数效率。为了开发这些模型,本文采用了训练感知的神经结构搜索和缩放的组合,共同优化训练速度和参数效率。这些模型是从富含Fused-MBConv等新操作的搜索空间中搜索出来的。本文的实验表明,EfficientNetV2模型的训练速度比最先进的模型快得多,而体积却小到6.8倍。
- 本文的训练可以通过在训练过程中逐步增加图像大小来进一步加速,但这往往会导致准确性的下降。为了弥补这种准确性的下降,本文提出了一种改进的渐进式学习方法,它随着图像大小自适应地调整正则化(如数据增量)。
- 通过渐进式学习,本文的EfficientNetV2在ImageNet和CIFAR/Cars/Flowers数据集上的表现明显优于以前的模型。通过在相同的ImageNet21k上进行预训练,本文的EfficientNetV2在ImageNet ILSVRC2012上达到了87.3%的最高准确率,比最近的ViT的准确率高出2.0%,同时使用相同的计算资源训练速度提高了5-11倍。代码在:automl/efficientnetv2 at master · google/automl (github.com)
- 论文:[2104.00298] EfficientNetV2: Smaller Models and Faster Training (arxiv.org)
- B站UP主[霹雳吧啦Wz]:https://www.bilibili.com/video/BV19v41157AU
Introduction
- 随着模型规模和训练数据规模越来越大,训练效率对深度学习很重要。例如,GPT-3(Brown等人,2020年),拥有更大的模型和更多的训练数据,展示了少数几个样本学习的显著能力,但它需要数周的训练,有数千个GPU,使得它难以重新训练或改进。
- 训练效率最近获得了重大关注。例如,NFNets(Brock等人,2021)
旨
在
通
过
去
除
昂
贵
的
批
量
归
一
化
来
提
高
训
练
效
率
\\textcolorblue旨在通过去除昂贵的批量归一化来提高训练效率
旨在通过去除昂贵的批量归一化来提高训练效率;最近的几项工作(Srinivas等人,2021)侧重于通过在卷积网络(ConvNets)中添加注意层来提高训练速度;Vision Transformers(Dosovitskiy等人,2021)通过使用Transformer块提高大规模数据集的训练效率。然而,这些方法在大参数规模上往往伴随着昂贵的开销,如下图(b)所示。
-
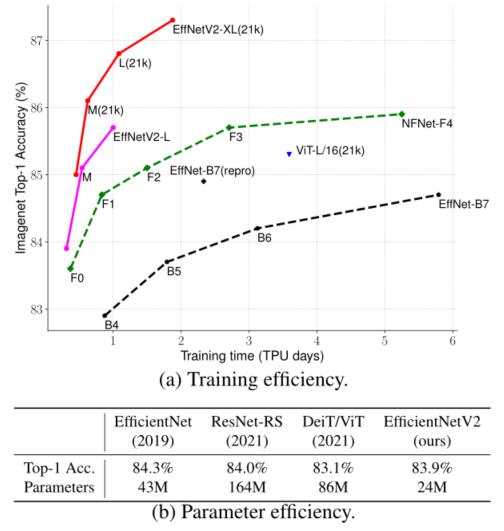
-
ImageNet ILSVRC2012 top-1 准确率与训练时间和参数的关系
-
标记为21k的模型在ImageNet21k上进行了预训练,而其他模型则直接在ImageNet ILSVRC2012上训练。
-
训 练 时 间 是 在 32 个 T P U 核 心 下 测 量 的 \\textcolorred训练时间是在32个TPU核心下测量的 训练时间是在32个TPU核心下测量的。所有的EfficientNetV2模型都是通过渐进式学习训练的。本文的EfficientNetV2的训练速度比其他模型快5-11倍,而使用的参数却少了6.8倍。
-
通过上图很明显能够看出EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)水平,而且训练速度更快参数数量更少( 比 当 前 火 热 的 V i s i o n T r a n s f o r m e r 还 要 强 \\textcolorblue比当前火热的Vision~Transformer还要强 比当前火热的Vision Transformer还要强)。
-
EfficientNetV2-XL (21k)在ImageNet ILSVRC2012的Top-1上达到87.3%。 在 E f f i c i e n t N e t V 1 中 作 者 关 注 的 是 准 确 率 , 参 数 数 量 以 及 F L O P s ( 理 论 计 算 量 小 不 代 表 推 理 速 度 快 ) , 在 E f f i c i e n t N e t V 2 中 作 者 进 一 步 关 注 模 型 的 训 练 速 度 \\textcolorgreen在EfficientNetV1中作者关注的是准确率,参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度 在EfficientNetV1中作者关注的是准确率,参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度。
-
- 在本文中,使用训练感知的神经结构搜索(NAS)和缩放的组合来提高训练速度和参数效率。鉴于EfficientNets的参数效率(Tan & Le, 2019a),本文首先系统地研究EfficientNets的训练瓶颈。
- 研究表明,在EfficientNets中:
- (1)用非常大的图像尺寸进行训练是缓慢的;
- 训练图像的尺寸很大时,训练速度非常慢。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size.
- 在之前使用EfficientNet时发现当使用到B3(img_size=300)- B7(img_size=600)时基本训练不动,而且非常吃显存。
- (2)深度卷积在早期层是缓慢的;
- 在网络浅层中使用Depthwise convolutions速度会很慢。无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。故引入Fused-MBConv结构。
- Fused-MBConv结构也非常简单,即将原来的
MBConv结构主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3。 - 作者使用NAS技术去搜索
MBConv和Fused-MBConv的最佳组合。
- (3)每一个阶段的平等扩展是次优的。
- 在EfficientNetv1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中, 作 者 采 用 了 非 均 匀 的 缩 放 策 略 来 缩 放 模 型 \\textcolorred作者采用了非均匀的缩放策略来缩放模型 作者采用了非均匀的缩放策略来缩放模型,与V1的差别。
- (1)用非常大的图像尺寸进行训练是缓慢的;
- 基于这些观察,本文设计了一个富含Fused-MBConv等额外操作的搜索空间,并应用训练感知的NAS和缩放来共同优化模型精度、训练速度和参数大小。本文发现的网络被命名为EfficientNetV2,其训练速度比之前的模型快4倍(下图),而参数大小却小6.8倍。
-
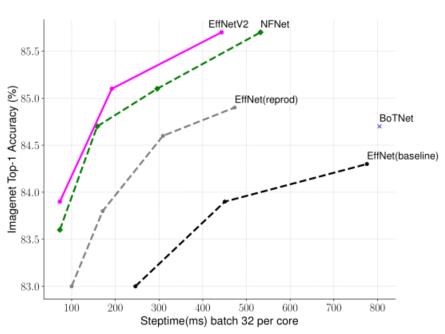
-
TPUv3上的ImageNet准确性和训练步骤时间–步骤时间越短越好;所有模型都是用固定的图像尺寸训练的,没有渐进学习。
-
- 本文的训练可以通过在训练过程中逐步增加图像大小来进一步加快训练速度。
- 以前的许多工作,如渐进式调整大小(Howard,2018)、FixRes(Touvron等人,2019)和Mix&Match(Hoffer等人,2019),在训练中使用了较小的图像尺寸;然而,他们通常对所有图像尺寸保持相同的正则化,导致准确性下降。
- 本文认为,对不同的图像尺寸保持相同的正则化并不理想:对于同一个网络,小的图像尺寸导致网络容量小,因此需要弱的正则化;反之,大的图像尺寸需要更强的正则化来对抗过拟合。
- 基于这一见解,本文提出了一种改进的渐进式学习方法:在早期训练时代,用小的图像尺寸和弱的正则化训练网络(例如,dropout and data augmentation),然后逐渐增加图像尺寸并增加更强的正则化。
- 建立在渐进式调整大小的基础上(Howard,2018),但通过动态调整正则化,本文的方法可以加快训练速度而不会导致准确率下降。
- 通过改进的渐进式学习,本文的EfficientNetV2在ImageNet、CIFAR-10、CIFAR100、Cars和Flowers数据集上取得了优异的成绩。在ImageNet上,本文达到了85.7%的最高准确率,同时训练速度比以前的模型快3-9倍,体积也小了6.8倍。
- 本文的EfficientNetV2和渐进式学习也使研究者们更容易在更大的数据集上训练模型。例如,ImageNet21k(Russakovsky等人,2015)比ImageNet ILSVRC2012大10倍左右,但本文的EfficientNetV2可以在两天内使用32个TPUv3内核的中等计算资源完成训练。
- 通过在公开的ImageNet21k上进行预训练,本文的EfficientNetV2在ImageNet ILSVRC2012上达到了87.3%的最高准确率,比最近的ViT-L/16的准确率高出2.0%,而训练速度则是其5-11倍。
- 本文的贡献有三方面。
- 本文介绍EfficientNetV2,一个新的更小更快的模型系列。通过本文的训练感知NAS和扩展,EfficientNetV2在训练速度和参数效率方面都超过了以前的模型。
- 本文提出了一种改进的渐进式学习方法,它随着图像大小自适应地调整正则化。它加快了训练速度,并同时提高了准确性。
- 与现有技术相比,本文在ImageNet、CIFAR、Cars和Flowers数据集上证明了高达11倍的训练速度(与V2-M和V1-B7进行的比较)和高达6.8倍的参数效率。
Related work
Training and parameter efficiency:
- 许多工作,如DenseNet(Huang等人,2017)和EfficientNet(Tan & Le,2019a),关注参数效率,旨在以更少的参数实现更好的准确性。一些较新的工作旨在提高训练或推理速度,而不是参数效率。例如,RegNet(2020)、ResNeSt(2020)、TResNet(2020)和EfficientNet-X(2021)侧重于GPU和/或TPU推理速度;NFNets(2021)和BoTNets(2021)侧重于提高训练速度。然而,他们的训练或推理速度往往是以更多的参数为代价的。本文旨在比现有技术大幅提高训练速度和参数效率。
Progressive training:
- 之前的工作提出了不同种类的渐进式训练,动态地改变训练设置或网络,用于GANs(Karras等人,2018)、转移学习(Karras等人,2018)、对抗学习(Yu等人,2019)和语言模型(Press等人,2021)。渐进式调整大小(Howard,2018)大多与本文的方法有关,旨在提高训练速度。然而,它通常以准确性下降为代价。另一项密切相关的工作是Mix&Match(Hoffer等人,2019),它为每个批次随机采样不同的图像大小。
- 渐进式调整大小和Mix&Match都对所有图像大小使用相同的正则化,导致准确性下降。在本文中,主要区别是也要自适应地调整正则化,这样就可以同时提高训练速度和准确率。本文的方法也部分受到了curriculum learning(Bengio等人,2009)的启发,它将训练实例从易到难进行了安排。本文的方法也是通过添加更多的正则化来逐渐增加学习难度,但不会选择性地挑选训练例子。
Neural architecture search (NAS):
- 通过自动化网络设计过程,NAS已被用于优化图像分类(Zoph等人,2018)、物体检测(Chen等人,2019;Tan等人,2020)、分割(Liu等人,2019)、超参数(Dong等人,2020)以及其他应用(Elsken等人,2019)的网络架构。以前的NAS工作大多集中在提高FLOPs效率或推理效率。与之前的工作不同,本文使用NAS来优化训练和参数效率。
EfficientNetV2 Architecture Design
- 研究了EfficientNet(Tan & Le, 2019a)的训练瓶颈,并介绍了本文的训练感知NAS和扩展,以及EfficientNetV2模型。
Review of EfficientNet
- EfficientNet(Tan & Le,2019a)是一个针对FLOPs和参数效率优化的模型系列。它利用NAS寻找在精度和FLOPs上有较好权衡的基线EfficientNet-B0。然后用复合扩展策略对基线模型进行扩展,得到B1-B7模型系列。虽然最近的一些作品声称在训练或推理速度上有很大的提高,但它们在参数和FLOPs效率方面往往不如EfficientNet(下表)。在本文中,本文的目标是在保持参数效率的同时提高训练速度。
-
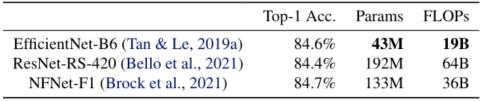
-
EfficientNets have good parameter and FLOPs efficiency.
-
Understanding Training Efficiency
- 本文研究了EfficientNet(Tan & Le, 2019a)的训练瓶颈,此后也被称为EfficientNetV1,以及一些简单的技术来提高训练速度。
Training with very large image sizes is slow:
- 正如之前的工作(Designing network design spaces,2020)所指出的,EfficientNet的大图像尺寸导致了大量的内存占用。由于GPU/TPU上的总内存是固定的,本文必须用较小的批处理量来训练这些模型,这大大减慢了训练速度。
- 一个简单的改进是应用FixRes(Touvron等人,2019),通过使用比推理更小的图像尺寸进行训练。如下表所示,较小的图像尺寸会导致较少的计算,并能实现大批量的计算,从而使训练速度提高2.2倍。
-

-
EfficientNet-B6在不同批次规模和图像大小下的准确性和训练吞吐量。OOM=out of memory
-
- 值得注意的是,正如(Touvron等人,2020;Brock等人,2021)所指出的,使用较小的图像尺寸进行训练也会带来稍好的准确性。但与(Touvron等人,2019)不同的是,本文在训练后没有对任何层进行微调。
- 本文将探索一种更先进的训练方法,在训练中逐步调整图像大小和正则化。
Depthwise convolutions are slow in early layers but effective in later stages:
- EfficientNet的另一个训练瓶颈来自于大量的深度卷积(Sifre,2014)。深度卷积比普通卷积有更少的参数和FLOPs,但它们往往不能充分利用现代加速器。最近,Fused-MBConv在(Efficientnet-edgetpu: Creating accelerator-optimized neural networks with automl, 2019)中被提出,后来又被用于(Gupta & Akin, 2020;Xiong等人,2020;Li等人,2021)以更好地利用移动或服务器加速器。如下图所示,它将MBConv(Sandler等人,2018;Tan & Le,2019a)中的深度conv3x3和扩展conv1x1替换为单一的规则conv3x3。
-
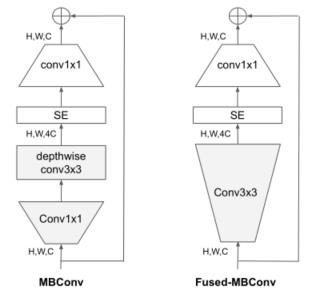
-
S t r u c t u r e o f M B C o n v a n d F u s e d − M B C o n v \\textcolorredStructure~ of~ MBConv~ and~ Fused-MBConv Structure of MBConv and Fused−MBConv.
-
- 为了系统地比较这两个构件,本文在EfficientNet-B4中逐渐用Fused-MBConv替换原来的MBConv(下表)。
-
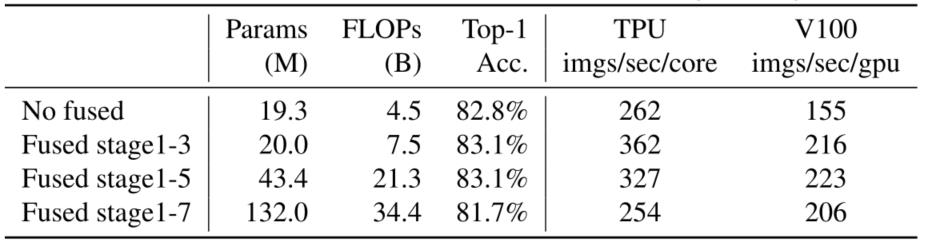
-
用Fused-MBConv替换MBConv。没有融合表示所有阶段都使用MBConv,融合阶段1-3表示在2,3,4阶段用融合-MBConv替换MBConv。
-
- 在 早 期 的 1 − 3 阶 段 , F u s e d − M B C o n v 可 以 提 高 训 练 速 度 , 且 对 参 数 和 F L O P s 的 开 销 很 小 \\textcolorpink在早期的1-3阶段,Fused-MBConv可以提高训练速度,且对参数和FLOPs的开销很小 在早期的1−3阶段,Fused−MBConv可以提高训练速度,且对参数和FLOPs的开销很小;但如果本文用Fused-MBConv替换所有的模块(第1-7阶段),那么它就会大大增加参数和FLOPs,同时也会降低训练的速度。找到MBConv和Fused-MBConv这两个构件的正确组合是不容易的,这促使本文利用神经结构搜索来自动搜索最佳组合。
Equally scaling up every stage is sub-optimal:
- EfficientNet使用一个简单的复合缩放规则对所有阶段进行平均缩放。例如,当深度系数为2时,那么网络中的所有阶段的层数将增加一倍。然而,这些阶段对训练速度和参数效率的贡献并不一样。
- 在本文中,将使用非均匀缩放策略,在后期阶段逐步增加层数。此外,EfficientNets会积极地扩大图像尺寸,导致大量的内存消耗和缓慢的训练。为了解决这个问题,本文略微修改了缩放规则,将最大图像尺寸限制在一个较小的数值。
Training-Aware NAS and Scaling
- 为此,本文已经了解了多种提高训练速度的设计选择。为了寻找这些选择的最佳组合,本文现在提出了一个训练感知的NAS。
NAS Search:
- 本文的训练感知NAS框架主要基于之前的NAS工作(Tan等人,2019;Tan & Le,2019a),但旨在共同优化现代加速器上的准确性、参数效率和训练效率。具体来说,本文使用EfficientNet作为骨干网络。本文的搜索空间是一个类似于(Tan等人,2019)的基于阶段的因子化空间,其中包括卷积运算类型MBConv,Fused-MBConv、层数、核大小3x3,5x5、扩展比1,4,6的设计选择。
- 另一方面,本文通过以下方式减少搜索空间大小:
- (1)删除不必要的搜索选项,如pooling skip ops,因为它们在原始EfficientNets中从未使用过;
- (2)重新使用骨干的相同通道大小,因为它们在(Tan & Le, 2019a)中已经被搜索过。
- 由于搜索空间较小,本文可以在规模与EfficientNetB4相当的更大的网络上应用强化学习(Tan等人,2019)或简单的随机搜索。具体来说,研究工作最多抽取1000个模型,用缩小的图像尺寸训练每个模型约10个epochs。
- 本文的搜索奖励结合了模型精度A、归一化训练步骤时间S和参数大小P ,使用简单的加权乘积 A ⋅ S w ⋅ P v A·S^w·P^v A⋅Sw⋅Pv,其中w = -0.07和v = -0.05是根据经验确定的,以平衡类似于(Tan等人,2019)的权衡因素。
EfficientNetV2 Architecture:
-
下表显示了本文搜索到的模型EfficientNetV2-S的架构。
-
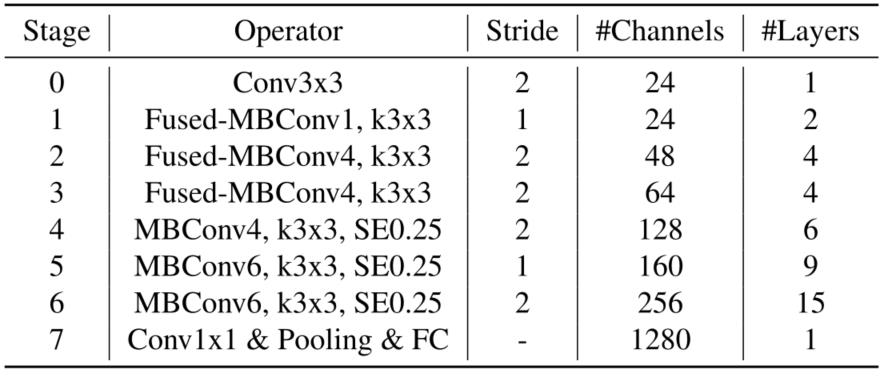
-
EfficientNetV2-S architecture -MBConv和FusedMBConv模块在上图中描述。
-
Stride就是步距,注意每个Stage中会重复堆叠Operator模块多次,只有第一个Opertator模块的步距是按照表格中Stride来设置的,其他的默认都是1。 #Channels表示该Stage输出的特征矩阵的Channels,#Layers表示该Stage重复堆叠Operator的次数。
- 原文链接:https://blog.csdn.net/qq_37541097/article/details/116933569
-
通过上表可以看到EfficientNetV2-S分为Stage0到Stage7(EfficientNetV1中是Stage1到Stage9)。Operator表示在当前Stage中使用的模块:
-
Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN -
Fused-MBConv模块名称后跟的
1,4表示expansion ratio,k3x3表示kenel_size为3x3。注意当expansion ratio等于1时是相当于没有expand conv的。注意当stride=1且输入输出Channels相等时才有shortcut连接。还需要注意的是,当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩残差分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。 -
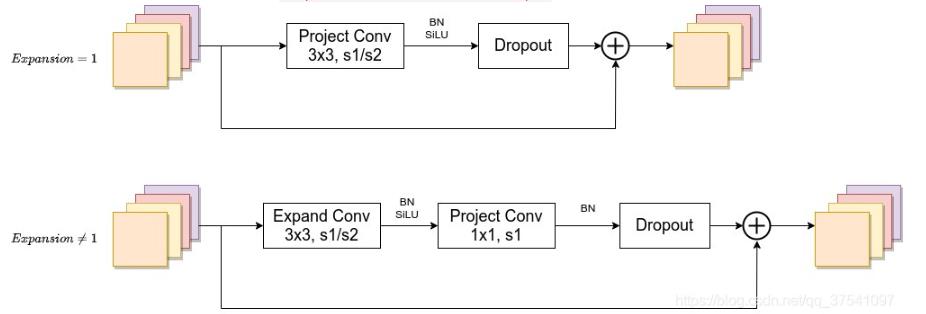
-
MBConv模块和V1中是一样的,其中模块名称后跟的4,6表示expansion ratio,SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的$\\frac14 $ 。注意当stride=1且输入输出Channels相等时才有shortcut连接。同样这里的Dropout层是Stochastic Depth。
-

-
-
-
与EfficientNet骨干网相比,本文搜索到的EfficientNetV2有几个主要区别:
- (1)第一个区别是EfficientNetV2在早期层广泛使用MBConv(Sandler等人,2018;Tan & Le,2019a)和新增加的fused-MBConv(Gupta & Tan,2019)。EfficientNetV2中除了使用到
MBConv模块外,还使用了Fused-MBConv模块(主要是在网络浅层中使用)。 - (2)EfficientNetV2倾向于为MBConv提供较小的扩展率,因为较小的扩展率往往有较少的内存访问开销。EfficientNetV2会使用较小的
expansion ratio(MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3)比如4,上网络结构中的Fused-MBConv4中的4,在EfficientNetV1中基本都是6. 看V1网络结构中的MBConv6中的6,这样的好处是能够减少内存访问开销。 - (3)EfficientNetV2更倾向于较小的3x3内核尺寸,但它会增加更多的层来补偿较小的内核尺寸所导致的接受野的减少。V2中更偏向使用更小(3x3)的kernel_size,在EfficientNetV1中使用了很多5x5的kernel_size。通过上表可以看到使用的kernel_size全是3x3的,由于3x3的感受野是要比5x5小的,所以需要堆叠更多的层结构以增加感受野。
- (4)EfficientNetV2完全删除了原EfficientNet中的最后一个stride-1阶段,这可能是由于其参数大小和内存访问开销较大。
- (1)第一个区别是EfficientNetV2在早期层广泛使用MBConv(Sandler等人,2018;Tan & Le,2019a)和新增加的fused-MBConv(Gupta & Tan,2019)。EfficientNetV2中除了使用到
EfficientNetV2 Scaling:
- 本文采用与(Tan & Le, 2019a)类似的复合缩放法对EfficientNetV2-S进行扩展,得到EfficientNetV2-M/L,并进行了一些额外的优化:
- (1)本文将最大推理图像尺寸限制在480,因为非常大的图像往往会导致昂贵的内存和训练速度开销;
- (2)作为一种启发式方法,还在后期阶段逐步增加层数,以增加网络容量而不增加很多运行时间开销。
Training Speed Comparison:
- 图TPUv3上的ImageNet准确性和训练步骤时间比较了本文新的EfficientNetV2的训练步骤时间,其中所有模型都是在固定的图像尺寸下训练的,没有渐进式学习。对于EfficientNet(Tan & Le, 2019a),本文显示了两条曲线:一条是用原始推理尺寸训练的,另一条是用大约30%的小图像尺寸训练的,与EfficientNetV2和NFNet(Touvron等人, 2019; Brock等人, 2021)相同。
- 所有的模型都是用350个epochs来训练的,除了NFNets是用360个epochs来训练的,所以所有的模型都有类似的训练步骤。有趣的是,本文观察到,当训练得当时,EfficientNets仍然能实现相当强的性能权衡。
- 更重要的是,通过本文的训练感知NAS和扩展,本文提出的EfficientNetV2模型的训练速度比其他最近的模型快很多。这些结果也与本文的推理结果一致,如下图所示。
-
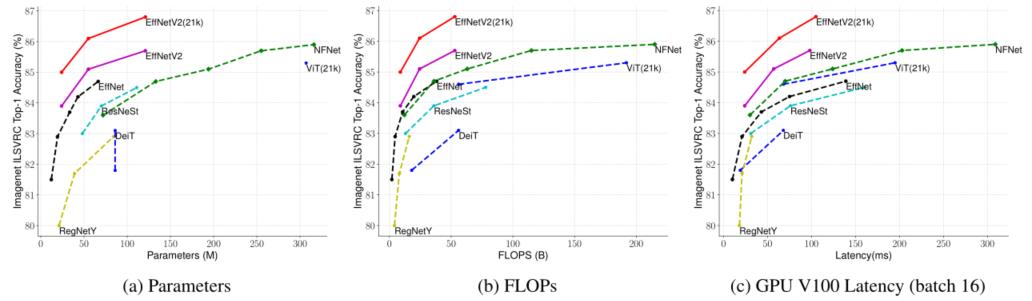
-
Model Size, FLOPs, and Inference Latency 延迟是在V100 GPU上以批处理量16来测量的。21k表示在ImageNet21k图像上的预训练,其他的只是在ImageNet ILSVRC2012上的训练。本文的EfficientNetV2的参数效率略高于EfficientNet,但推理运行速度快3倍。
-
Progressive Learning
Motivation
- 正如上文所讨论的,图像大小对训练效率起着重要作用。除了FixRes(Touvron等人,2019),许多其他作品在训练过程中动态改变图像大小(Howard,2018;Hoffer等人,2019),但它们往往导致准确率下降。
- Accuracy的降低是不平衡的正则化
unbalanced regularization导致的。在训练不同尺寸的图像时,应该使用动态的正则方法(之前都是使用固定的正则方法)。 - 为了验证这个猜想,作者接着做了一些实验。在前面提到的搜索空间中采样并训练模型,训练过程中尝试使用不同的图像尺寸以及不同强度的数据增强
data augmentations。 - 当训练的图片尺寸较小时,使用较弱的数据增强
augmentation能够达到更好的结果;当训练的图像尺寸较大时,使用更强的数据增强能够达到更好的接果。 - 本文假设准确率的下降来自于不平衡的正则化:当用不同的图像尺寸进行训练时,也应该相应地调整正则化强度(而不是像以前的工作那样使用固定的正则化)。事实上,大型模型需要更强的正则化来对抗过拟合是很常见的:例如,EfficientNet-B7比B0使用更大的dropout和更强的数据增强。
- 在本文中,即使是相同的网络,较小的图像尺寸会导致较小的网络容量,因此需要较弱的正则化;反之,较大的图像尺寸会导致更多的计算,而容量较大,因此更容易出现过拟合。
- 为了验证本文的假设,训练了一个模型,从本文的搜索空间取样,用不同的图像大小和数据增强(下表)。
-
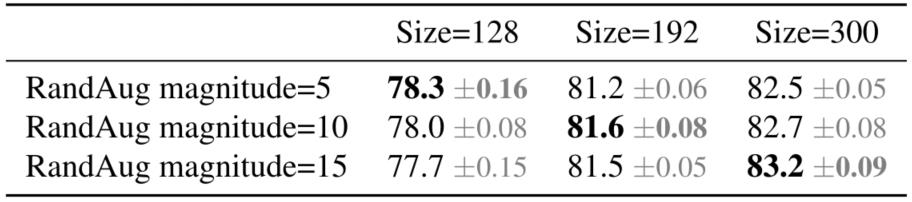
-
ImageNet前1名的准确性。本文使用RandAug(Cubuk等人,2020),并报告了3次运行的平均值和stdev。
-
当
Size=128,RandAug magnitude=5时效果最好;当Size=300,RandAug magnitude=15时效果最好
-
- 当图像尺寸较小时,它在弱增强的情况下具有最好的准确性;但对于较大的图像,它在强增强的情况下表现更好。这一见解促使本文在训练过程中随着图像大小自适应地调整正则化,从而导致本文改进的渐进式学习方法。
Progressive Learning with adaptive Regularization
-
图4说明了本文改进的渐进式学习的训练过程:在早期的训练时代,本文用较小的图像和弱的正则化来训练网络,这样网络可以很容易和快速地学习简单的表示。然后,本文逐渐增加图像大小,但也通过增加更强的正则化使学习更加困难。本文的方法是建立在(Howard,2018)的基础上,逐步改变图像大小,这里本文也自适应地调整正则化。
-

-
本文改进的渐进式学习的训练过程–它从小的图像尺寸和弱的正则化开始(epoch=1),然后用更大的图像尺寸和更强的正则化逐渐增加学习难度:更大的dropout rate、RandAugment幅度和混合比例(例如,epoch=300)。
-
-
形式上,假设整个训练共有N个步骤,目标图像大小为 S e S_e Se,有一个正则化幅度列表 Φ e = φ e k Φ_e = φ^k_e Φe以上是关于读点论文EfficientNetV2: Smaller Models and Faster Training 训练感知的神经架构搜索+自适应的渐近训练方法优化训练(TPU,大数据量)的主要内容,如果未能解决你的问题,请参考以下文章