Knowledge Distillation via Route Constrained Optimization
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Knowledge Distillation via Route Constrained Optimization相关的知识,希望对你有一定的参考价值。
Motivation
已有的KD方法提升性能都是基于一个假设:teacher模型可以提供一种弱监督,且能被一个小student网络学习,但是实际上一个收敛的大网络表示空间很难被student学习,这会导致congruence loss很高
因此本文提出一种策略route constrained optimization,根据参数空间的route去选择teacher的参数,一步一步的指导student。
Method
Review


Mobilenet是S,res50是T,我们分别用10 40 120 240的resnet作为mobilenet的T,发现用越好的T,S loss越大,说明T越好,S越难学,不过性能确实是越来越好
RCO(Route Constrained Optimization)
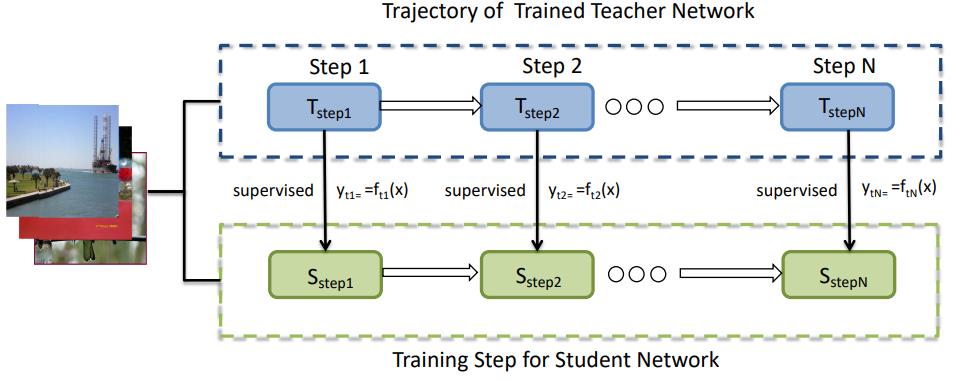
把网络中间的训练状态称为anchor points
算法流程:
- 训练T,得到不同训练状态的T,T1,T2…Tn
- 随时初始化S
- 用T1指导S,训练一段时间用T2指导S
- 直到用Tn指导完S,得到最终的S
注意这里何时切换T,后续需要讨论
Strategy for Selecting Anchor Points
- Equal Epoch Interval Strategy:每个T训练4个epoch,但是比较粗暴,没有考虑各个T学习的难度
- Greedy Search Strategy:
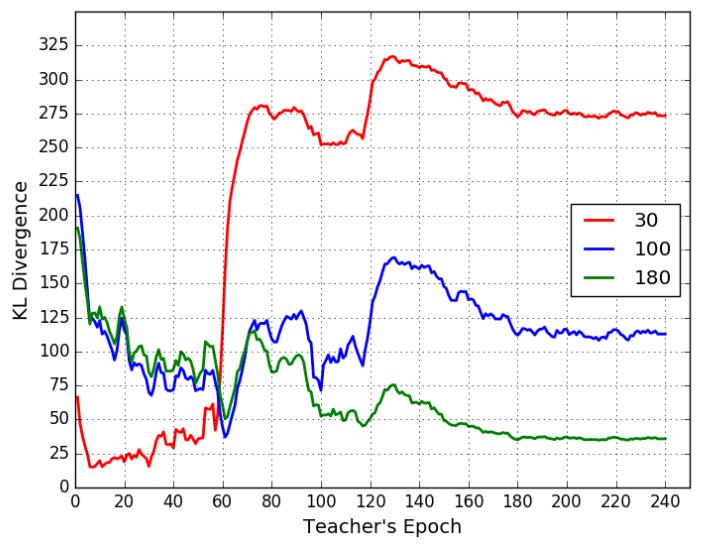
30 100 180分别代表用不同时刻的T作文指导训练得到的S,然后随机取1w张图,分别送入他们得到输出,然后同时也送入不同epoch的teacher(60 120减低学习率)得到output
然后计算出的KL散度结果可以画成上图,发现在teacher的前期,30指导的S能够比较好的学习,而到了后面30指导的S已经跟不上节奏了,尤其是每一次减低学习率的时候
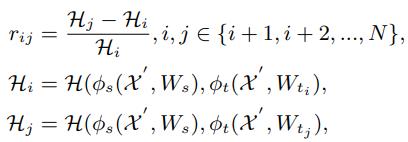
根据以上发现,本文提出一种策略
- 计算S和当前T以及下一个anchor point的T之间的KL距离(随机选一些验证集图片计算output)
- 当距离大于一定阈值后就换T
Experiment
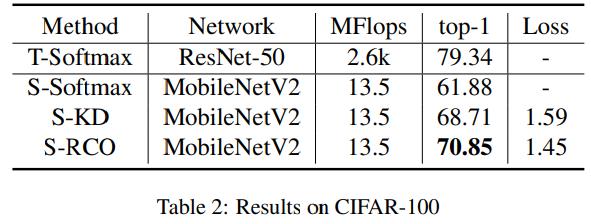
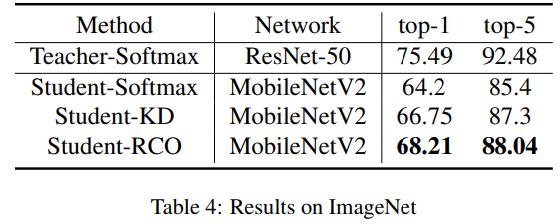

以上是关于Knowledge Distillation via Route Constrained Optimization的主要内容,如果未能解决你的问题,请参考以下文章