Tutorial: Knowledge Distillation
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tutorial: Knowledge Distillation相关的知识,希望对你有一定的参考价值。
概述
Knowledge Distillation(KD)一般指利用一个大的teacher网络作为监督,帮助一个小的student网络进行学习,主要用于模型压缩。
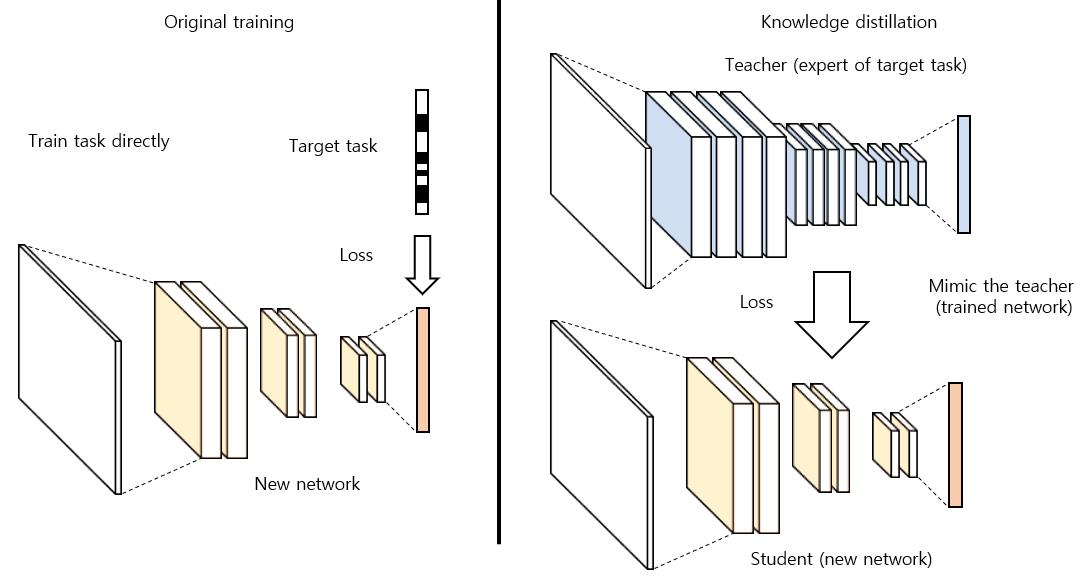
其方法主要分为两大类
- Output Distillation
- Feature Distillation
Output Distillation
Motivation
主要拉近teacher和student最终输出的距离,参考论文:Distilling the Knowledge in a Neural Network
one-hot label会将所有不正确的类别概率都设置为0,而一个模型预测出来的结果,这些不正确的类别概率是有不同的,他们之间概率的相对大小其实蕴含了更多的信息,代表着模型是如何泛化判别的。
比如一辆轿车,一个模型预测出的概率向量中,更有可能卡车和轿车的概率相当,而猫的概率则很小,这其实给出了比one hot label更多的信息即轿车和卡车更像,而和猫不像。
Method
Loss = CrossEntropy(softmax(predict), one hot label) + alpha * T * T * CrossEntropy(softmax(predict/T), soft target)
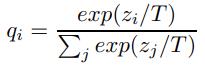
T作为一个超参,当T很大时,qi会更加soft,比如T趋于无穷大,则qi=(1/n, 1/n…)
alpha为权衡task loss和output distillation loss
Advantage
- 对于hard sample,提供了样本的难易程度的监督(如上述例子一样,轿车和卡车比较容易混淆)
- 对于easy sample,平滑label,起到正则化作用,避免过拟合
- 只拉进output距离,不受网络结构的限制
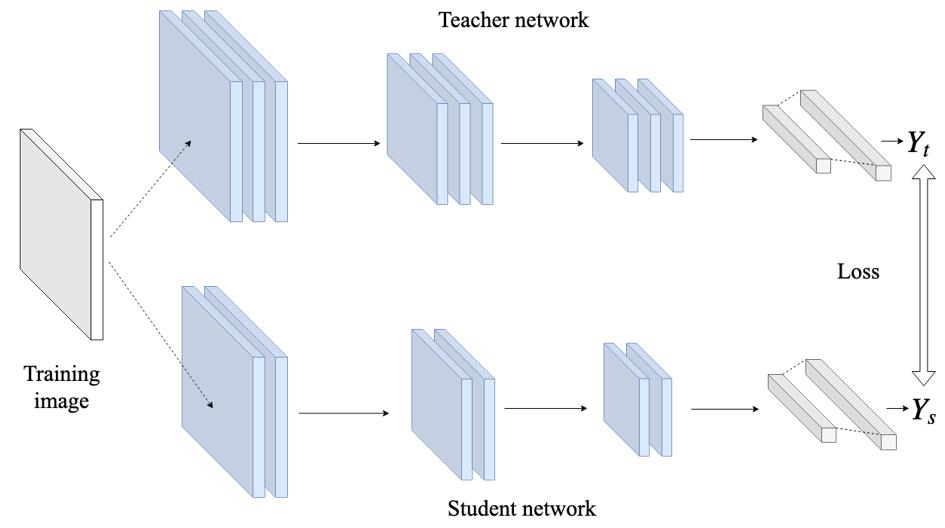
Feature Distillation
Motivation
在output distillation中仅拉进output的距离,有两个问题
- 很多时候一个好的网络其输出和GT差别不大,接近one-hot,可以通过调节T使该问题得到一定程度的缓解(增大T得到更加soft的label)
- student和teacher层数较多,仅在网络最终的输出处进行约束,不太容易对齐
基于以上两个问题,Yoshua Bengio等人提出了feature distillation
Method
Loss = L_task + alpha * L_output_distillation + beta * L_feature_distillation
L_feature_distillation = Distance(Transform_t(Feat_t), Transform_s(Feat_s))
feature distillation方法有4个方面可以设计
- feature的选取位置
- student feature的变换
- teacher feature的变换
- 距离的定义
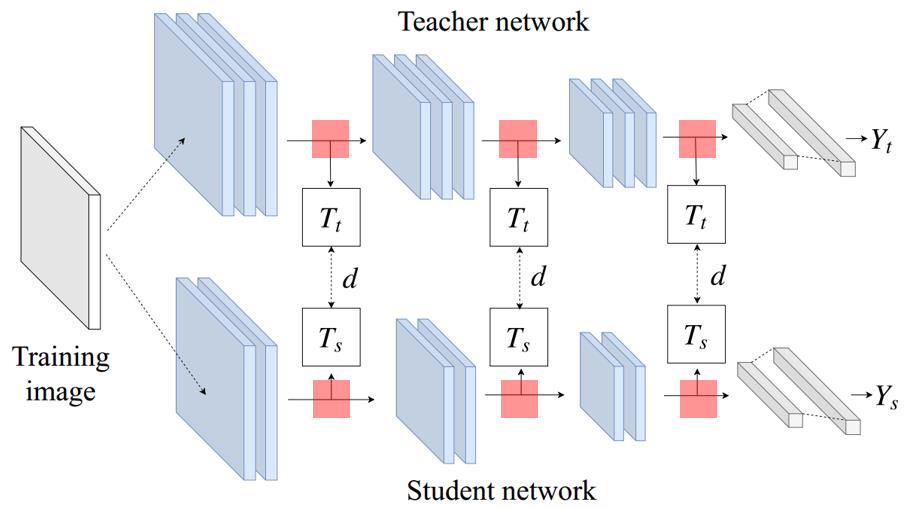
很多方法根据以上4各方面进行设计
1. FitNets
论文参考:FitNets: Hints for Thin Deep Nets
- feature的选取位置:不同的实验不同的选择,论文仅选择了一层feature进行对齐
- student feature的变换:1x1 conv
- teacher feature的变换:无
- 距离的定义:L2
2. Attention Transfer
论文参考:paying more attention to attention: improving the performance of convolutional neural networks via attention transfer - feature的选取位置:resnet每个阶段的最后一层卷积
- student feature的变换:channel通道求平方和后做L2 norm,hwc->h*w
- teacher feature的变换:channel通道求平方和后做L2 norm,hwc->h*w
- 距离的定义:L2
3. Similarity Preserve
论文参考:similarity-preserving knowledge distillation - feature的选取位置:resnet每个阶段的最后一层卷积
- student feature的变换:求batch中样本之间的特征相似度,即[b, hwc] * [ hwc, b] = b*b
- teacher feature的变换:求batch中样本之间的特征相似度,即[b, hwc] * [ hwc, b] = b*b
- 距离的定义:L2
稍稍解释下motivation,无论student还是teacher,其对两个类别一样的样本predict出来的特征相似度应该很高,如不同类别相似度应该很低。
这样做的好处是:student不用去mimic teacher的特征空间,只用在自己的特征空间做到相同类别物体相似度高,不同类别物体相似度低即好,因为有时候student容量很小,很难能够mimic teacher的特征空间
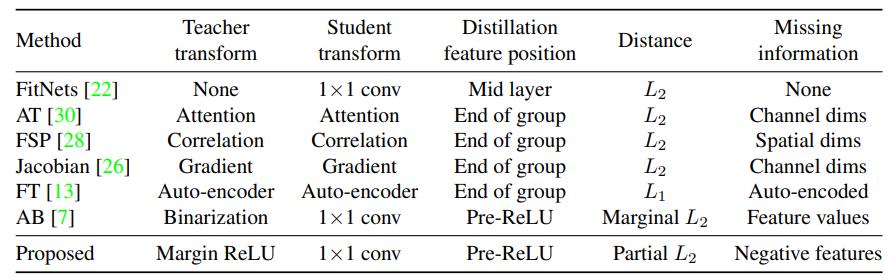
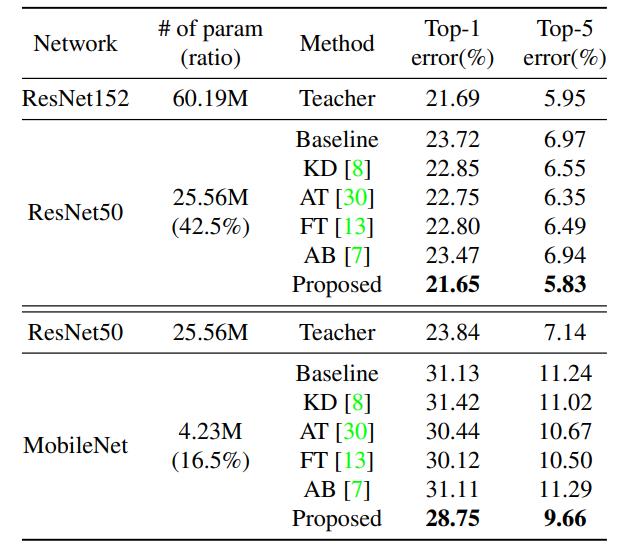
4. Overhaul Distillation
论文参考:A Comprehensive Overhaul of Feature Distillation - feature的选取位置:resnet每个阶段的最后一层卷积,注意是ReLU前
- student feature的变换:1x1 conv
- teacher feature的变换:margin ReLU,保留更多的正值,抑制一部分负值
- 距离的定义:partial L2
扩展
Knowledge最开始提出时,主要是针对分类任务,后续也有了很多针对Detection和Segmentation的蒸馏工作,列举两篇有代表性的
Detection
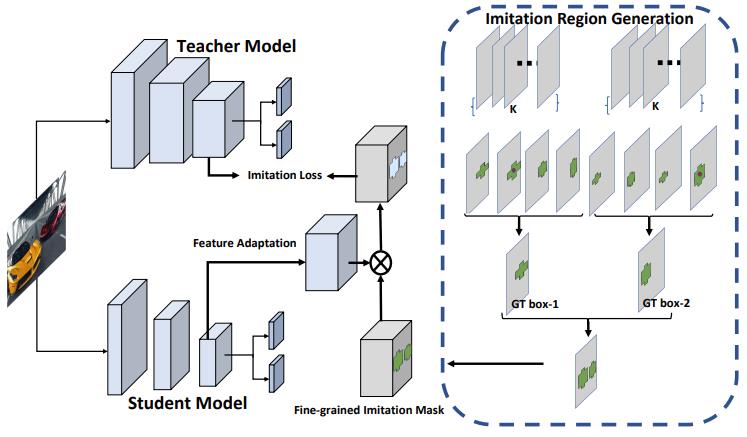
论文参考 CVPR2019 Distilling Object Detectors with Fine-grained Feature Imitation
Motivation:
分类任务中因为图片一般仅包含主题物体,且所占比例比较大,因此做feature distillation是在整个feature上做的。而检测任务中会有很多物体,且所占图片比例较小,存在大量的背景。
如果整图feature做distillation,噪声太大,不易学习,因此本文提出仅在大概率出现物体的区域(根据RPN的输出可以获得该信息)做feature distillation
Method:
L_feature_distillation = Mask * Distance(Transform_t(Feat_t), Transform_s(Feat_s)),仅在mask选中的区域内做feature distillation
Segmentation
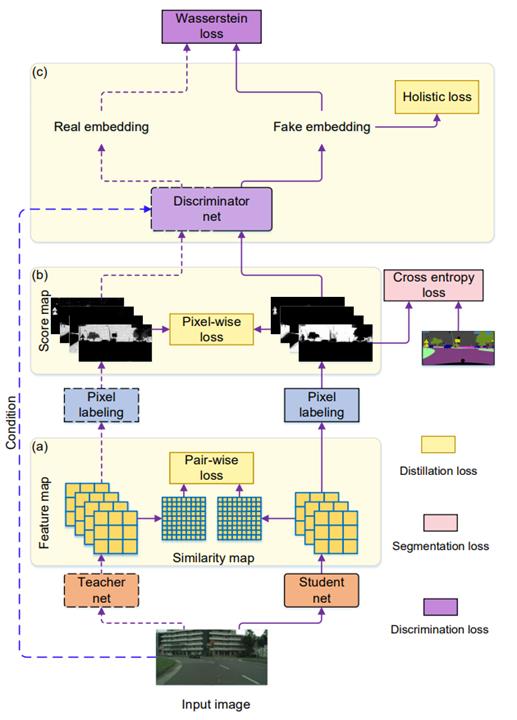
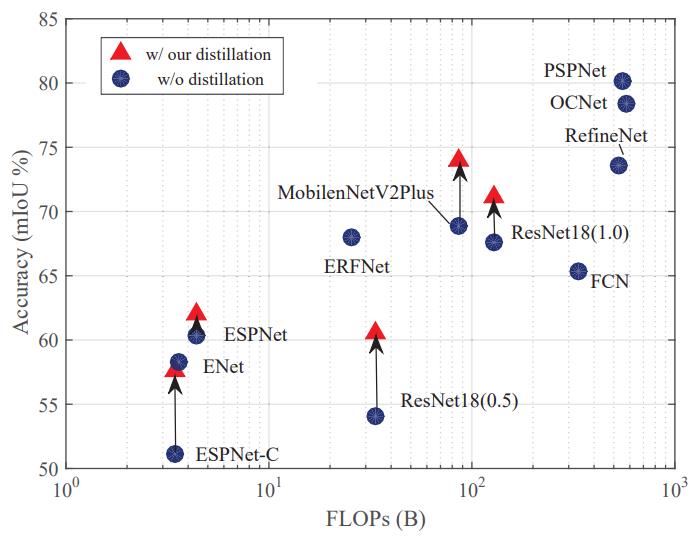
论文参考 CVPR 2019 Structured Knowledge Distillation for Semantic Segmentation
针对segmentation的任务特点: structured prediction,本文提出一种蒸馏方法挖掘其中的结构关系
- pair-wise distillation: 分别计算student、teacher各自feature中各像素的相似度矩阵,拉进相似度矩阵的L2距离,目的是使得学生在自己的特征空间中学习和teacher一致的structure,不用去mimic teacher的特征空间
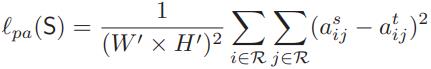
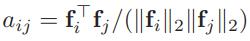
- holistic distillation: 受WGAN的启发,拉进student和teacher的score map的W距离
以上是关于Tutorial: Knowledge Distillation的主要内容,如果未能解决你的问题,请参考以下文章