Hadoop--09----Hadoop序列化
Posted 高高for 循环
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop--09----Hadoop序列化相关的知识,希望对你有一定的参考价值。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
Hadoop序列化

1.序列化概述


2. 自定义 bean对象实现序列化接口(Writable)


具体实现 bean对象序列化 步骤如下 7步


序列化案例实操
1)需求


2)需求分析

3)编写流量统计的Bean 对象
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1、定义类实现writable接口
* 2、重写序列化和反序列化方法
* 3、重写空参构造
* 4、toString方法
*/
public class FlowBean implements Writable
private long upFlow; // 上行流量
private long downFlow; // 下行流量
private long sumFlow; // 总流量
// 空参构造
public FlowBean()
public long getUpFlow()
return upFlow;
public void setUpFlow(long upFlow)
this.upFlow = upFlow;
public long getDownFlow()
return downFlow;
public void setDownFlow(long downFlow)
this.downFlow = downFlow;
public long getSumFlow()
return sumFlow;
public void setSumFlow(long sumFlow)
this.sumFlow = sumFlow;
public void setSumFlow()
this.sumFlow = this.upFlow + this.downFlow;
@Override
public void write(DataOutput out) throws IOException
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
@Override
public void readFields(DataInput in) throws IOException
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
@Override
public String toString()
return upFlow + "\\t" + downFlow + "\\t" + sumFlow;
4)编写 Mapper类
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean>
private Text outK = new Text();
private FlowBean outV = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
// 1 获取一行
// 1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200
String line = value.toString();
// 2 切割
// 1,13736230513,192.196.100.1,www.atguigu.com,2481,24681,200 7 - 3= 4
// 2 13846544121 192.196.100.2 264 0 200 6 - 3 = 3
String[] split = line.split("\\t");
// 3 抓取想要的数据
// 手机号:13736230513
// 上行流量和下行流量:2481,24681
String phone = split[1];
String up = split[split.length - 3];
String down = split[split.length - 2];
// 4封装
outK.set(phone);
outV.setUpFlow(Long.parseLong(up));
outV.setDownFlow(Long.parseLong(down));
outV.setSumFlow();
// 5 写出
context.write(outK, outV);
5)编写 Reducer类
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text, FlowBean,Text, FlowBean>
private FlowBean outV = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException
// 1 遍历集合累加值
long totalUp = 0;
long totaldown = 0;
for (FlowBean value : values)
totalUp += value.getUpFlow();
totaldown += value.getDownFlow();
// 2 封装outk, outv
outV.setUpFlow(totalUp);
outV.setDownFlow(totaldown);
outV.setSumFlow();
// 3 写出
context.write(key, outV);
6)编写 Driver驱动类
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
// 1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar
job.setJarByClass(FlowDriver.class);
// 3 关联mapper 和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 4 设置mapper 输出的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 5 设置最终数据输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 6 设置数据的输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\\\input\\\\inputflow"));
FileOutputFormat.setOutputPath(job, new Path("D:\\\\hadoop\\\\output4"));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
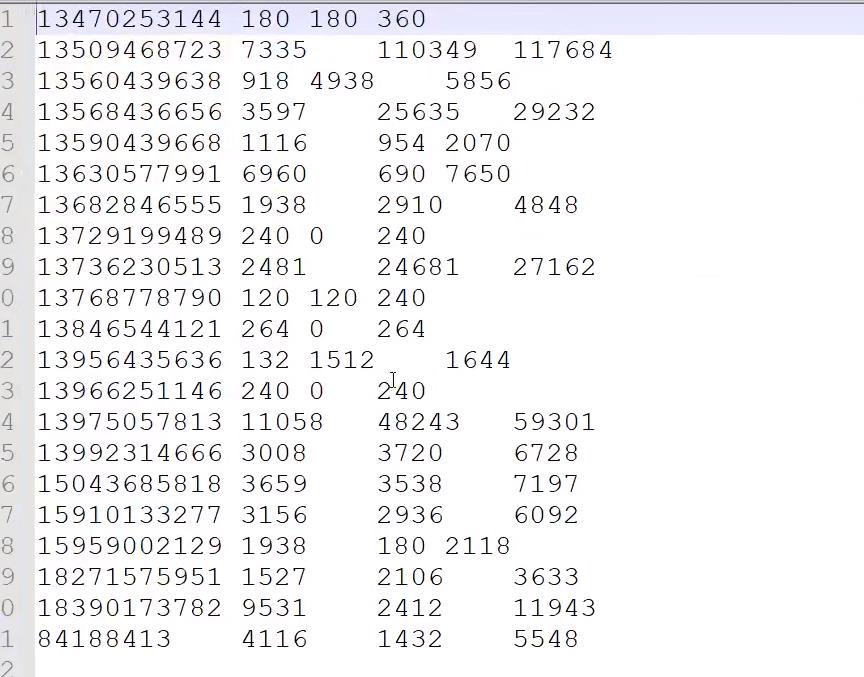
7)测试
需求

输入数据

输出结果

以上是关于Hadoop--09----Hadoop序列化的主要内容,如果未能解决你的问题,请参考以下文章