linux 内核网络发送技术栈
Posted 为了维护世界和平_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux 内核网络发送技术栈相关的知识,希望对你有一定的参考价值。
目录
数据包发送过程
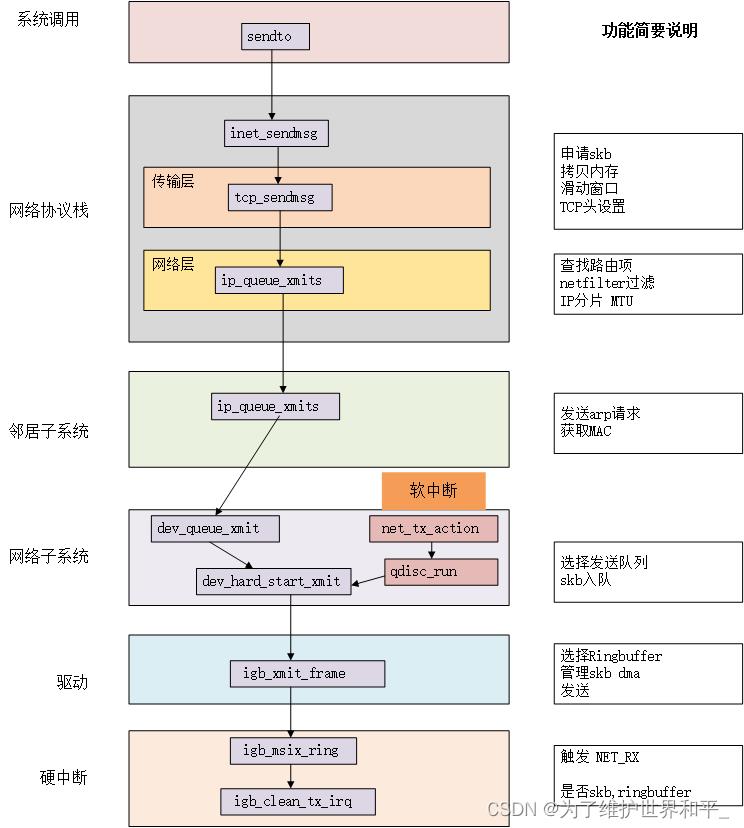
- 系统调用send发送数据
- 内核中内存拷贝
- 协议处理
- 送入驱动RingBuffer
- 中断通知发送完成
- 清理RingBuffer
应用层
send函数调用
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len,
unsigned int, flags, struct sockaddr __user *, addr,
int, addr_len)
return __sys_sendto(fd, buff, len, flags, addr, addr_len);
int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags,
struct sockaddr __user *addr, int addr_len)
//根据fd查找到socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
msg.msg_name = NULL;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
//发送数据
err = sock_sendmsg(sock, &msg);
关键:在内核中把socket找出来
依次调用关系
sock_sendmsg
sock_sendmsg_nosec
inet_sendmsg
tcp_sendmsg
tcp_sendmsg_locked
传输层TCP
tcp协议栈的处理
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
while (msg_data_left(msg))
int copy = 0;
//获取发送队列 获取socket发送队列中的最后一个skb
skb = tcp_write_queue_tail(sk);
new_segment:
first_skb = tcp_rtx_and_write_queues_empty(sk);
//申请skb
skb = sk_stream_alloc_skb(sk, 0, sk->sk_allocation,
first_skb);
//把skb挂载到socket的发送队列上
skb_entail(sk, skb);
copy = size_goal;
//skb中有足够的空间
if (skb_availroom(skb) > 0 && !zc)
//拷贝数据到内核空间;msg_iter是用户空间的数据地址
err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy);
//申请内核内存并拷贝,判断的是未发送的数据是否已经超过最大窗口的一半了,条件满足的,这次的用户发送的数据只是拷贝到内核
if (forced_push(tp))
tcp_mark_push(tp, skb);//序号变更
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
- 找到发送队列skb
- 申请skb并加入队列sk
- 拷贝用户数据到sk上
- 发送判断(未发送的数据数据是否已经超过最⼤窗⼝的⼀半了)-》发送
static inline bool before(__u32 seq1, __u32 seq2)
return (__s32)(seq1-seq2) < 0;
#define after(seq2, seq1) before(seq1, seq2)
static inline bool forced_push(const struct tcp_sock *tp)
return after(tp->write_seq, tp->pushed_seq + (tp->max_window >> 1));
传输层发送
__tcp_push_pending_frames,tcp_push_one都调用 tcp_write_xmit
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
//循环获取待发送的skb,滑动窗口,拥塞控制
while ((skb = tcp_send_head(sk)))
//滑动窗口相关信息
cwnd_quota = tcp_cwnd_test(tp, skb);
//开启发送
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
循环获取待发送skb
滑动窗口管理
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt)
if (clone_it)
tcp_skb_tsorted_save(oskb)
//克隆新skb出来,最后在网卡发送完成后,skb会被释放掉。TCP支持重传,在接收对方ACK前,是不能删除的
if (unlikely(skb_cloned(oskb)))
skb = pskb_copy(oskb, gfp_mask);
else
skb = skb_clone(oskb, gfp_mask);
tcp_skb_tsorted_restore(oskb);
//封装tcp头
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(rcv_nxt);
//网络层发送接口
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
- clone skb,因为数据到达网卡发送完成后才释放skb,而TCP支持重传在收到对方ACK之前不能删除skb
- 设置TCP头信息,指针指向TCP合适的位置
queue_xmit绑定
const struct inet_connection_sock_af_ops ipv4_specific =
.queue_xmit = ip_queue_xmit,
.send_check = tcp_v4_send_check,
网络层
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos)
//检测socket中是否有缓存的路由表
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (!rt)
//没有缓存则展开查找路由项,并缓存到socket中
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS_TOS(sk, tos),
sk->sk_bound_dev_if);
sk_setup_caps(sk, &rt->dst);
//为skb设置路由表
skb_dst_set_noref(skb, &rt->dst);
//设置IP header
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
//发送
res = ip_local_out(net, sk, skb);
...
- 查找并设置路由表:查找网络中应该通过哪个网卡发送出去,查找到后缓存到socket上,下次再发送数据就不需要查了。
- 设置IP头 ,调整指针位置
int ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
int err;
//netfilter过滤,如果iptables设置了一些规则,这里将检测是否命中规则
err = __ip_local_out(net, sk, skb);
//发送数据
if (likely(err == 1))
err = dst_output(net, sk, skb);
return err;
netfilter过滤,如果iptables设置了一些规则,规则越多CPU处理时间越长
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, indev, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
static int __ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
unsigned int mtu;
mtu = ip_skb_dst_mtu(sk, skb);
if (skb_is_gso(skb))
return ip_finish_output_gso(net, sk, skb, mtu);
//大于mtu 需要进行分片
if (skb->len > mtu || (IPCB(skb)->flags & IPSKB_FRAG_PMTU))
return ip_fragment(net, sk, skb, mtu, ip_finish_output2);
return ip_finish_output2(net, sk, skb);
大于MTU进行分片 ,分片的影响:
- 额外的切分处理;
- 一个分片丢失,真个包都需要重传
//邻居子系统
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
if (!IS_ERR(neigh))
int res;
sock_confirm_neigh(skb, neigh);
neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
if (!IS_ERR(neigh))
sock_confirm_neigh(skb, neigh);
res = neigh_output(neigh, skb, is_v6gw);
邻居子系统
邻居⼦系统是位于⽹络层和数据链路层中间的⼀个系统。 作⽤: 让⽹络层不必关⼼下层的地址信息, 让下层来决定发送到哪个 MAC 地址 方法: 在邻居⼦系统⾥主要是查找或者创建邻居项,在创造邻居项的时候,有可能会发出实际的 arp 请求。然后封装⼀下 MAC 头,将发送过程再传递到更下层的⽹络设备⼦系统。static inline struct neighbour *ip_neigh_for_gw(struct rtable *rt,
struct sk_buff *skb,
bool *is_v6gw)
if (likely(rt->rt_gw_family == AF_INET))
neigh = ip_neigh_gw4(dev, rt->rt_gw4);
else if (rt->rt_gw_family == AF_INET6)
neigh = ip_neigh_gw6(dev, &rt->rt_gw6);
*is_v6gw = true;
else
neigh = ip_neigh_gw4(dev, ip_hdr(skb)->daddr);
return neigh;
AF_INET 与 AF_INET6不同的分支 看一下AF_INET的情况
static inline struct neighbour *ip_neigh_gw4(struct net_device *dev,
__be32 daddr)
struct neighbour *neigh;
//arp缓存中查找信息,下一跳IP地址daddr
neigh = __ipv4_neigh_lookup_noref(dev, daddr);
if (unlikely(!neigh))//找不到就创建
neigh = __neigh_create(&arp_tbl, &daddr, dev, false);
return neigh;
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb)
int rc = 0;
//触发arp请求
if (!neigh_event_send(neigh, skb))
do
__skb_pull(skb, skb_network_offset(skb));
seq = read_seqbegin(&neigh->ha_lock);
//neigh->ha 是MAC地址
err = dev_hard_header(skb, dev, ntohs(skb->protocol),
neigh->ha, NULL, skb->len);
while (read_seqretry(&neigh->ha_lock, seq));
if (err >= 0)
//发送
rc = dev_queue_xmit(skb);
else
goto out_kfree_skb;
- 当获取到硬件 MAC 地址以后,就可以封装 skb 的 MAC 头了
- 调⽤ dev_queue_xmit将 skb 传递给 Linux ⽹络设备⼦系统。
int dev_queue_xmit(struct sk_buff *skb)
return __dev_queue_xmit(skb, NULL);
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
skb_reset_mac_header(skb);
skb_update_prio(skb);
qdisc_pkt_len_init(skb);
//选择发送队列
txq = netdev_core_pick_tx(dev, skb, sb_dev);
//获取与次队列管理的排队规则
q = rcu_dereference_bh(txq->qdisc);
trace_net_dev_queue(skb);
//如果有队列,则调用__dev_xmit_skb继续处理数据
if (q->enqueue)
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
netdev_core_pick_tx->netdev_pick_tx
u16 netdev_pick_tx(struct net_device *dev, struct sk_buff *skb,
struct net_device *sb_dev)
struct sock *sk = skb->sk;
int queue_index = sk_tx_queue_get(sk);
sb_dev = sb_dev ? : dev;
if (queue_index < 0 || skb->ooo_okay ||
queue_index >= dev->real_num_tx_queues)
//获取xps
int new_index = get_xps_queue(dev, sb_dev, skb);
//自动计算
if (new_index < 0)
new_index = skb_tx_hash(dev, sb_dev, skb);
if (queue_index != new_index && sk &&
sk_fullsock(sk) &&
rcu_access_pointer(sk->sk_dst_cache))
sk_tx_queue_set(sk, new_index);
queue_index = new_index;
return queue_index;
获取与此队列关联的 qdisc,在 linux 上通过 tc 命令可以看到 qdisc 类型。
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
if ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) &&//绕开排队系统
qdisc_run_begin(q))
qdisc_bstats_update(q, skb);
if (sch_direct_xmit(skb, q, dev, txq, root_lock, true))
__qdisc_run(q);
qdisc_run_end(q);
rc = NET_XMIT_SUCCESS;
else //正常排队
rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK;
__qdisc_run(q);//开始发送
qdisc_run_end(q);
return rc;
void __qdisc_run(struct Qdisc *q)
int quota = dev_tx_weight;
int packets;
//从环形队列取出一个skb发送
while (qdisc_restart(q, &packets))
quota -= packets;//quota 用尽
if (quota <= 0)
__netif_schedule(q);//触发一次net_tx_softirq
break;
上述有两种情况,1)可以绕过排队系统;2)正常队列;
while 循环不断地从队列中取出 skb 并进⾏发送。- 占⽤的是⽤户进程的系统态时间(sy)。
- 当 quota ⽤尽或者其它进程需要 CPU 的时候才触发软中断进⾏发送
static inline bool qdisc_restart(struct Qdisc *q, int *packets)
/* Dequeue packet *///取出skb
skb = dequeue_skb(q, &validate, packets);
...
return sch_direct_xmit(skb, q, dev, txq, root_lock, validate);
qdisc_restart 从队列中取出⼀个 skb,并调⽤ sch_direct_xmit 继续发送
bool sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock, bool validate)
//调用驱动程序发送数据
skb = dev_hard_start_xmit(skb, dev, txq, &ret);
调用驱动程序dev_hard_start_xmit发送数据
参考
https://course.0voice.com/v1/course/intro?courseId=2&agentId=0
以上是关于linux 内核网络发送技术栈的主要内容,如果未能解决你的问题,请参考以下文章
突破Linux内核网络协议栈瓶颈的技术方案-dpdk+vpp