linux 内核网络发送技术栈
Posted 为了维护世界和平_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux 内核网络发送技术栈相关的知识,希望对你有一定的参考价值。
目录
网络发送过程
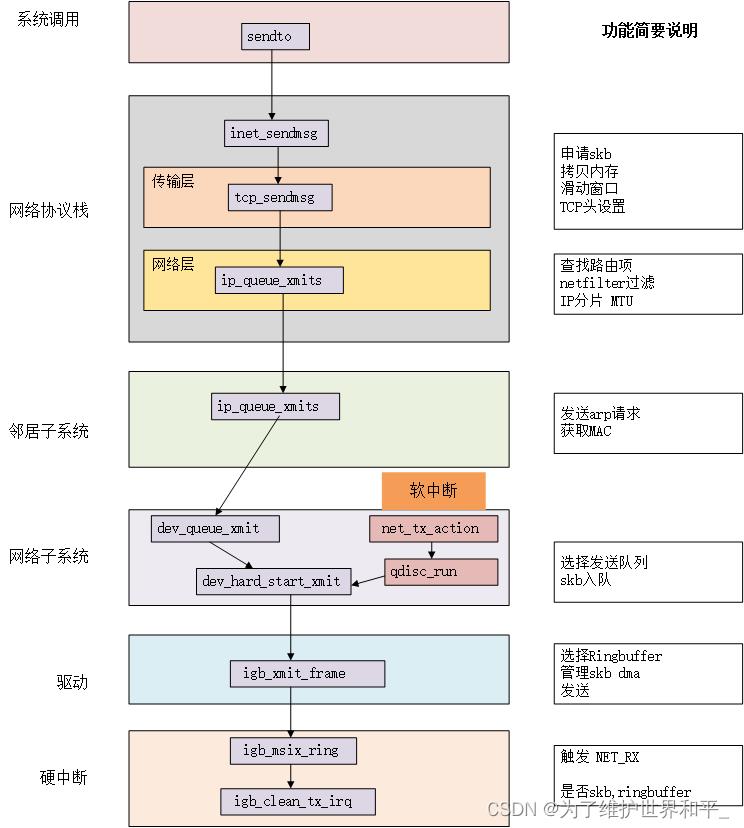
邻居子系统后继续
软中断调度
软中断的条件:系统发送网络包不够用的时候,调用__netif_schedule
void __netif_schedule(struct Qdisc *q)
if (!test_and_set_bit(__QDISC_STATE_SCHED, &q->state))
__netif_reschedule(q);
static void __netif_reschedule(struct Qdisc *q)
struct softnet_data *sd;
unsigned long flags;
local_irq_save(flags);
sd = this_cpu_ptr(&softnet_data);
q->next_sched = NULL;
*sd->output_queue_tailp = q;
sd->output_queue_tailp = &q->next_sched;
raise_softirq_irqoff(NET_TX_SOFTIRQ);
local_irq_restore(flags);
发出 NET_TX_SOFTIRQ 类型软中断。
会进⼊到 net_tx_action 函数,在该函数中能获取到发送队列,并也最终调⽤到驱动程序⾥的⼊⼝函数 dev_hard_start_xmit。
发送数据消耗的CPU显示在si里,不会消耗用户进程的系统时间
static __latent_entropy void net_tx_action(struct softirq_action *h)
//通过softnet_data 获取发送队列
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
//如果output queue上有qdisc
if (sd->output_queue)
local_irq_disable();
//指向第一个qdisc
head = sd->output_queue;
//遍历qdsic
while (head)
struct Qdisc *q = head;
spinlock_t *root_lock = NULL;
head = head->next_sched;
//发送数据,与用户态一样,调用qdisc_restart=>sch_direct_xmit->dev_hard_start_xmit
qdisc_run(q);
xfrm_dev_backlog(sd);
- 进程内核态在调用__netif_reschedule的时候,把发送队列写到softnet_data的output_queue里了。
- 软中断会调用softnet_data获取数据。
- 软中断循环遍历sd->output_queue发送数据帧
- qdisc_run(q) 调用qdisc_restart=>sch_direct_xmit->dev_hard_start_xmit
网卡驱动发送
struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev,
struct netdev_queue *txq, int *ret)
struct sk_buff *skb = first;
int rc = NETDEV_TX_OK;
while (skb)
struct sk_buff *next = skb->next;
skb_mark_not_on_list(skb);
rc = xmit_one(skb, dev, txq, next != NULL);
...
函数调用关系
xmit_one
netdev_start_xmit
__netdev_start_xmit
static inline netdev_tx_t __netdev_start_xmit(const struct net_device_ops *ops,
struct sk_buff *skb, struct net_device *dev,
bool more)
__this_cpu_write(softnet_data.xmit.more, more);
return ops->ndo_start_xmit(skb, dev);
对于⽹络设备层定义的 ndo_start_xmit, igb 的实现函数是 igb_xmit_frame。在⽹卡驱动初始化的时候赋值
static const struct net_device_ops igb_netdev_ops =
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
继续看igb_xmit_frame
static netdev_tx_t igb_xmit_frame(struct sk_buff *skb,
struct net_device *netdev)
struct igb_adapter *adapter = netdev_priv(netdev);
return igb_xmit_frame_ring(skb, igb_tx_queue_mapping(adapter, skb));
调用igb_xmit_frame_ring
netdev_tx_t igb_xmit_frame_ring(struct sk_buff *skb,
struct igb_ring *tx_ring)
//获取TX Queue 中下⼀个可⽤缓冲区信息
first = &tx_ring->tx_buffer_info[tx_ring->next_to_use];
first->skb = skb;
first->bytecount = skb->len;
first->gso_segs = 1;
first->tx_flags = tx_flags;
first->protocol = protocol;
//准备发送数据
if (igb_tx_map(tx_ring, first, hdr_len))
//将skb数据映射到网卡可访问的内存DMA区域
static int igb_tx_map(struct igb_ring *tx_ring,
struct igb_tx_buffer *first,
const u8 hdr_len)
//获取下一个可用描述符指针
tx_desc = IGB_TX_DESC(tx_ring, i);
//为skb->data 构造内存映射,以运行设备通过DMA从RAM中读取数据
dma = dma_map_single(tx_ring->dev, skb->data, size, DMA_TO_DEVICE);
tx_buffer = first;
//遍历数据包所有分片,为SKB的每个分片生成有效映射
for (frag = &skb_shinfo(skb)->frags[0];; frag++)
tx_desc->read.cmd_type_len =
cpu_to_le32(cmd_type ^ IGB_MAX_DATA_PER_TXD);
tx_desc->read.olinfo_status = 0;
tx_desc->read.buffer_addr = cpu_to_le64(dma);
//设置最后一个descriptor
cmd_type |= size | IGB_TXD_DCMD;
tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type);
netdev_tx_sent_queue(txring_txq(tx_ring), first->bytecount);
dma_wmb();
first->next_to_watch = tx_desc;
dma_map_single为skb->data 构造内存映射,以运行设备通过DMA从RAM中读取数据
skb 的所有数据都映射到 DMA 地址后,触发发送。
补充:网卡启动
static int __igb_open(struct net_device *netdev, bool resuming)
//分配RingBuffer
//发送队列
err = igb_setup_all_tx_resources(adapter);
//接收队列
err = igb_setup_all_rx_resources(adapter);
//开启全部队列
netif_tx_start_all_queues(netdev);
igb_setup_all_tx_resources-> igb_setup_tx_resources
int igb_setup_tx_resources(struct igb_ring *tx_ring)
//申请igb_tx_buffer数组内存
tx_ring->tx_buffer_info = vmalloc(size);
//申请e1000_adv_tx_desc DMA数组内存
/* round up to nearest 4K */
tx_ring->size = tx_ring->count * sizeof(union e1000_adv_tx_desc);
tx_ring->size = ALIGN(tx_ring->size, 4096);
tx_ring->desc = dma_alloc_coherent(dev, tx_ring->size,
&tx_ring->dma, GFP_KERNEL);
...
static int igb_setup_all_tx_resources(struct igb_adapter *adapter)
struct pci_dev *pdev = adapter->pdev;
int i, err = 0;
//有几个队列就构造几个ringbuffer
for (i = 0; i < adapter->num_tx_queues; i++)
err = igb_setup_tx_resources(adapter->tx_ring[i]);
return err;
有两个数组需要注意
- igb_tx_buffer 数组:通过 vzalloc 申请的,是内核使⽤;
- e1000_adv_tx_desc 数组:硬件是可以通过 DMA 直接访问这块内存,通过dma_alloc_coherent 分配,这个数组是⽹卡硬件使⽤的。
之间的关系:
指向同⼀个 skb,内核和硬件就能共同访问同样的数据,内核往 skb ⾥写数据,⽹卡硬件负责发送。
发送完成硬中断
目的:清理内存,清理skb,清扫RingBuffer
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
硬中断触发的软中断是NET_RX_SOFTIRQ
static int igb_poll(struct napi_struct *napi, int budget)
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector, budget);
static bool igb_clean_tx_irq(struct igb_q_vector *q_vector, int napi_budget)
/* free the skb */
napi_consume_skb(tx_buffer->skb, napi_budget);
/* clear last DMA location and unmap remaining buffers */
while (tx_desc != eop_desc)
tx_buffer++;
tx_desc++;
i++;
if (unlikely(!i))
i -= tx_ring->count;
tx_buffer = tx_ring->tx_buffer_info;
tx_desc = IGB_TX_DESC(tx_ring, 0);
/* unmap any remaining paged data */
if (dma_unmap_len(tx_buffer, len))
dma_unmap_page(tx_ring->dev,
dma_unmap_addr(tx_buffer, dma),
dma_unmap_len(tx_buffer, len),
DMA_TO_DEVICE);
dma_unmap_len_set(tx_buffer, len, 0);
清理SKB,unmap DMA映射。
总结
1)/proc/softirqs中 RX 为什么比TX高很多
- 数据发送完,通过硬中断来通知发送完成。软中断无论是数据接收还是发送完毕,触发的都是NET_RX_SOFTIRQ。
- 对于发送方,数据在⽤户进程内核态处理了,只有系统态配额⽤尽才会发出NET_TX,让软中断上。所以NET_TX比较少。对于读方,都是经过NET_RX软中断。
2)内存拷贝操作
- 内存申请完skb后,将用户发送的数据拷贝到skb
- 传输层到网络层,每个skb克隆一个新的副本。为了重传,只有收到ACK才丢失
- 当IP层发现skb大于MTU时,申请额外的skb,将原来的skb拷贝为多个小的skb
参考
https://course.0voice.com/v1/course/intro?courseId=2&agentId=0
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于linux 内核网络发送技术栈的主要内容,如果未能解决你的问题,请参考以下文章