大数据集群硬盘资源监控
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据集群硬盘资源监控相关的知识,希望对你有一定的参考价值。
文章目录
需求
- 统计集群服务器硬盘每日增量
- 统计HDFS每天数据增量
- 统计数仓每天数据增量
- 统计数仓ODS层和DWD层每天数据增量
硬盘资源监控命令
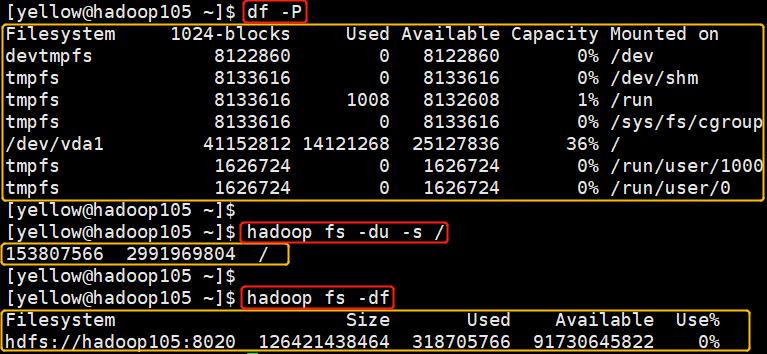
| 监控项 | 命令 | 默认单位 |
|---|---|---|
| 某服务器硬盘使用量 | df | KB |
| HDFS总使用量 | hadoop fs -df | B |
| HDFS上某个文件夹的大小 | hadoop fs -du -s / | B |
代码

Python用于获取和处理数据,mysql用于存储数据
选择MySQL8原因:8版本支持WITH AS和窗口函数
选择Python2原因:CentOS7自带Python2,免安装
MySQL
安装MySQL8
https://blog.csdn.net/Yellow_python/article/details/104184171
建表
建库
CREATE DATABASE data_management;
USE data_management;
建表
CREATE TABLE item_info(
item_id INT PRIMARY KEY COMMENT '监控项ID',
item_name VARCHAR(255) NOT NULL COMMENT '监控项名称',
item_unit VARCHAR(63) DEFAULT NULL COMMENT '计量单位'
)COMMENT='监控项信息表';
CREATE TABLE item_records(
item_id INT NOT NULL COMMENT '监控项ID',
monitoring_time DATETIME NOT NULL COMMENT '监测时间',
monitoring_value BIGINT NOT NULL COMMENT '监测值',
PRIMARY KEY(item_id,monitoring_time)
)COMMENT='监控项流水表';
插入数据
INSERT item_info VALUES
(1,'HDFS数据总使用量','B'),
(2,'数仓占用量(含副本)','B'),
(3,'数仓ODS层占用量(含副本)','B'),
(4,'数仓DWD层占用量(含副本)','B'),
(5,'hadoop105服务器硬盘使用','KB'),
(6,'hadoop106服务器硬盘使用','KB'),
(7,'hadoop107服务器硬盘使用','KB');
创建视图
视图 便于 查看每日环比增量 以及 提供数据接口
CREATE OR REPLACE VIEW hdfs_ymd AS
-- 最近30天,HDFS每天总硬盘使用(平均值)
WITH hdfs_used_ymd AS(
SELECT
DATE(monitoring_time) AS ymd,
AVG(monitoring_value) AS b
FROM item_records
WHERE item_id=1 AND DATEDIFF(NOW(),monitoring_time)<31
GROUP BY DATE(monitoring_time))
-- 计算每天变化量
SELECT
t1.ymd AS ymd,
t1.b/1024/1024/1024 AS gb,
(t1.b-t2.b)/1024/1024/1024 AS increase
FROM hdfs_used_ymd t1
INNER JOIN hdfs_used_ymd t2
ON t1.ymd=DATE_ADD(t2.ymd,INTERVAL 1 DAY)
ORDER BY ymd;
-- 最近30天所有服务器硬盘总使用及变化
CREATE OR REPLACE VIEW df_ymd AS
WITH
-- 筛选监控项目:服务器硬盘使用
df_id AS(
SELECT item_id FROM item_info
WHERE item_name LIKE '%服务器硬盘使用'),
-- 筛选最近30天
r30 AS(
SELECT
item_id,
DATE(monitoring_time) AS ymd,
monitoring_value
FROM item_records
WHERE DATEDIFF(NOW(),monitoring_time)<31),
-- 最近30天各服务器硬盘使用(平均值)
df_used_hosts_ymd AS(
SELECT
r30.ymd AS ymd,
AVG(r30.monitoring_value) AS kb
FROM df_id LEFT JOIN r30 ON df_id.item_id=r30.item_id
GROUP BY r30.ymd,df_id.item_id),
-- 最近30天所有服务器硬盘使用总和
df_used_ymd AS(
SELECT ymd,SUM(kb) AS kb
FROM df_used_hosts_ymd
GROUP BY ymd)
-- 计算每日增量
SELECT
ymd,
kb/1048576 AS gb,
(kb-LAG(kb,1,NULL)OVER(ORDER BY ymd))/1048576 AS increase
FROM df_used_ymd;
创建一个元数据表,存储视图信息
CREATE TABLE metadata_view(
metadata_name VARCHAR(255) PRIMARY KEY COMMENT '元数据名称',
explanation VARCHAR(255) NOT NULL COMMENT '元数据说明'
)COMMENT='视图的元数据信息';
-- 创建视图后,写入视图说明
INSERT metadata_view VALUES
('hdfs_ymd','最近30天,HDFS每天总使用量及每日增量'),
('hdfs_ymd.increase','每日增量'),
('df_ymd','最近30天,所有服务器硬盘使用及每日增量之和'),
('df_ymd.increase','每日增量');
Python2
注意:Python2脚本和MySQL8要在同一台服务器,便于执行
mysql -e
执行用户:非root
#!/usr/bin/python2
# coding=utf-8
from os import system
from subprocess import check_output
def execute(cmd):
"""执行Linux命令"""
print(cmd)
system(cmd)
def evaluate(cmd):
"""执行Linux命令并获取返回值,Python2返回值类型为str"""
print(cmd)
return check_output(cmd, shell=True).strip()
class Mysql:
def __init__(self, password, user='root', host=None, database=None):
self.cmd = 'sudo mysql -u"" -p"" '.format(user, password)
if host:
self.cmd += '-h"" '.format(host)
if database:
self.cmd += '-D"" '.format(database)
def e(self, sql):
return self.cmd + '-e""'.format(sql)
def insert(self, dt, tb):
ls = [(k, v) for k, v in dt.items() if v is not None]
sql = 'INSERT %s (' % tb + ','.join(i[0] for i in ls) + \\
') VALUES (' + ','.join('%r' % i[1] for i in ls) + ')'
execute(self.e(sql))
if __name__ == '__main__':
from re import split
# 要监控的HDFS文件夹,Key对应MySQL表.item_info的item_id
HDFS_PATH =
2: '/user/hive/warehouse/ec.db',
3: '/user/hive/warehouse/ec.db/ods',
4: '/user/hive/warehouse/ec.db/dwd',
# 要监控的节点硬盘,Key对应MySQL表.item_info的item_id
HOSTNAMES =
5: 'hadoop105',
6: 'hadoop106',
7: 'hadoop107',
def _now():
return evaluate('date +"%Y-%m-%d %H:%M:%S"')
def _mysql_formatting(a, b, c):
"""数据写入MySQL的字段格式"""
return 'item_id': a, 'monitoring_time': b, 'monitoring_value': c
def hadoop_fs_df():
"""查询HDFS数据量"""
result = evaluate('hadoop fs -df')
now = _now()
print(result)
dt = k: v for k, v in zip(*(split(r'\\s+', line) for line in result.split('\\n')))
return _mysql_formatting(1, now, int(dt['Used']))
def hadoop_fs_du(item_id=2):
"""查询HDFS文件夹大小"""
result = evaluate('hadoop fs -du -s ' + HDFS_PATH[item_id])
now = _now()
print(result)
value = split(r'\\s+', result)[1]
return _mysql_formatting(item_id, now, int(value))
def hadoop_fs_du_ods():
"""查询ODS层文件夹大小"""
return hadoop_fs_du(3)
def hadoop_fs_du_dwd():
"""查询DWD层文件夹大小"""
return hadoop_fs_du(4)
def df(item_id):
"""查询指定服务器硬盘使用,执行用户具有sudo权限,集群之间root用户可免密登录"""
hostname = HOSTNAMES[item_id]
cmd = 'sudo ssh df /'.format(hostname)
result = evaluate(cmd)
print(result)
now = _now()
dt = k: v for k, v in zip(*(split(r'\\s+', line) for line in result.split('\\n')))
return _mysql_formatting(item_id, now, int(dt['Used']))
def df_hadoop105():
"""查询hadoop105服务器硬盘使用"""
return df(5)
def df_hadoop106():
"""查询hadoop106服务器硬盘使用"""
return df(6)
def df_hadoop107():
"""查询hadoop107服务器硬盘使用"""
return df(7)
db = Mysql(
password='密码',
database='data_management')
TABLE = 'item_records'
db.insert(hadoop_fs_df(), TABLE)
db.insert(hadoop_fs_du(), TABLE)
db.insert(hadoop_fs_du_ods(), TABLE)
db.insert(hadoop_fs_du_dwd(), TABLE)
db.insert(df_hadoop105(), TABLE)
db.insert(df_hadoop106(), TABLE)
db.insert(df_hadoop107(), TABLE)
定时任务
crontab -e
# 每天跑一次
0 0 * * * python2 脚本路径.py
补充
原本使用Python3,代码保留
3版本优势:代码阅读性和维护性更好,开发效率更高
2版本优势:移植性更好,复制可用,不需要装环境
from time import strftime
from subprocess import check_output
from re import split
from pymysql.connections import Connection # conda install pymysql
# 要监控的HDFS文件夹,Key对应MySQL表item_info的item_id
HDFS_PATH =
2: '/user/hive/warehouse/ec.db',
3: '/user/hive/warehouse/ec.db/ods',
4: '/user/hive/warehouse/ec.db/dwd',
# 要监控的节点硬盘,Key对应MySQL表item_info的item_id
HOSTNAMES =
5: 'hadoop105',
6: 'hadoop106',
7: 'hadoop107',
def _cmd(command) -> str:
"""指定用户执行Shell命令,并返回结果"""
return check_output('sudo -i -u yellow ' + command, shell=True).decode().strip()
def _mysql_formatting(a: int, b: str, c: int) -> dict:
"""数据写入MySQL的字段格式"""
return 'item_id': a, 'monitoring_time': b, 'monitoring_value': c
def _now() -> str:
return strftime('%Y-%m-%d %H:%M:%S')
def hadoop_fs_df() -> dict:
"""查询HDFS数据量"""
result = _cmd('hadoop fs -df')
now = _now()
dt = k: v for k, v in zip(*(split(r'\\s+', line) for line in result.split('\\n')))
print(dt)
return _mysql_formatting(1, now, int(dt['Used']))
def hadoop_fs_du(item_id=2) -> dict:
"""查询HDFS文件夹大小"""
result = _cmd('hadoop fs -du -s ' + HDFS_PATH[item_id])
now = _now()
print(result)
value = split(r'\\s+', result)[1]
return _mysql_formatting(item_id, now, int(value))
def hadoop_fs_du_ods() -> dict:
"""查询ODS层文件夹大小"""
return hadoop_fs_du(3)
def hadoop_fs_du_dwd() -> dict:
"""查询DWD层文件夹大小"""
return hadoop_fs_du(4)
def df(item_id) -> dict:
"""查询指定服务器硬盘使用,执行用户具有sudo权限,集群之间root用户可免密登录"""
hostname = HOSTNAMES[item_id]
cmd = 'sudo ssh df /'.format(hostname)
print(cmd)
result = _cmd(cmd)
now = _now()
dt = k: v for k, v in zip(*(split(r'\\s+', line) for line in result.split('\\n')))
print(dt)
return _mysql_formatting(item_id, now, int(dt['Used']))
def df_hadoop105() -> dict:
"""查询hadoop105服务器硬盘使用"""
return df(5)
def df_hadoop106() -> dict:
"""查询hadoop106服务器硬盘使用"""
return df(6)
def df_hadoop107() -> dict:
"""查询hadoop107服务器硬盘使用"""
return df(7)
class Mysql:
def __init__(self, host, database, password, user='root'):
self.db = Connection(
user=user,
password=password,
host=host,
database=database,
port=3306,
charset='UTF8')
self.cursor = self.db.cursor()
def __del__(self):
self.cursor.close()
self.db.close()
def commit(self, sql):
print(sql)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
print(e)
def insert(self, dt, tb):
ls = [(k, v) for k, v in dt.items() if v is not None]
sql = 'INSERT %s (' % tb + ','.join(i[0] for i in ls) + \\
') VALUES (' + ','.join('%r' % i[1] for i in ls) + ')'
self.commit(sql)
if __name__ == '__main__':
db = Mysql(
host='hadoop107',
password='密码',
database='data_management')
TABLE = 'item_records'
db.insert(hadoop_fs_df(), TABLE)
db.insert(hadoop_fs_du(), TABLE)
db.insert(hadoop_fs_du_ods(), TABLE)
db.insert(hadoop_fs_du_dwd(), TABLE)
db.insert(df_hadoop105(), TABLE