深入理解Kafka
Posted YaoYong_BigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解Kafka相关的知识,希望对你有一定的参考价值。
一、概述
Kafka是一个分布式的基于发布、订阅的消息系统,有着强大的消息处理能力,相比与其他消息系统,具有以下特性:
- 快速数据持久化,实现了O(1)时间复杂度的数据持久化能力。
- 高吞吐,能在普通的服务器上达到10W每秒的吞吐速率。
- 高可靠,消息持久化以及副本系统的机制保证了消息的可靠性,消息可以多次消费。
- 高扩展,与其他分布式系统一样,所有组件均支持分布式、自动实现负载均衡,可以快速便捷的扩容系统。
- 离线与实时处理能力并存,提供了在线与离线的消息处理能力。
正是因其具有这些的优秀特性而广泛用于应用解耦、流量削峰、异步消息等场景,比如消息中间件、日志聚合、流处理等等。
二、主题与日志
1.主题
主题是存储消息的一个逻辑概念,可以简单理解为一类消息的集合,由使用方去创建。Kafka中的主题一般会有多个订阅者去消费对应主题的消息,也可以存在多个生产者往主题中写入消息。

每个主题又可以划分成多个分区,每个分区存储不同的消息。当消息添加至分区时,会为其分配一个位移offset(从0开始递增),并保证分区上唯一,消息在分区上的顺序由offset保证,即同一个分区内的消息是有序的,如下图所示:
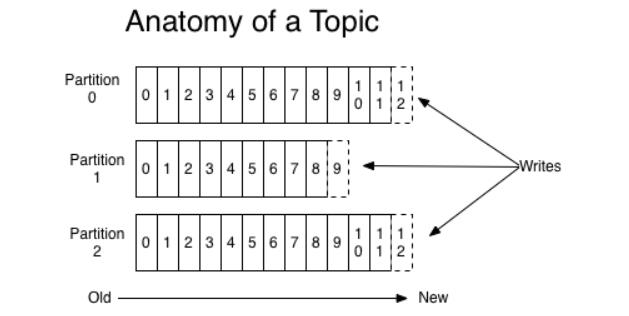
同一个主题的不同分区会分配在不同的节点上(broker),分区时保证Kafka集群具有水平扩展的基础。
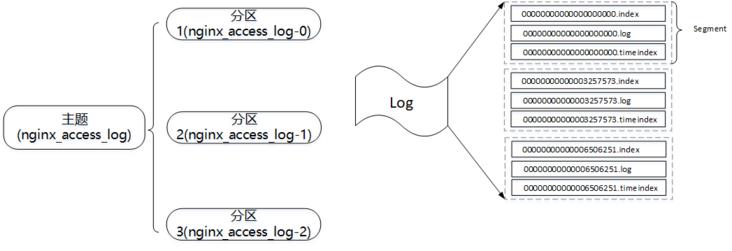
以主题nginx_access_log为例,分区数为3,如上图所示。分区在逻辑上对应一个日志(Log),物理上对应的是一个文件夹。
drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx\\_access\\_log-0/
drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx\\_access\\_log-1/
drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx\\_access\\_log-2/消息写入分区时,实际上是将消息写入分区所在的文件夹中。日志又分成多个分片(Segment),每个分片由日志文件与索引文件组成,每个分片大小是有限的(在kafka集群的配置文件log.segment.bytes配置,默认为1073741824byte,即1GB),当分片大小超过限制则会重新创建一个新的分片,外界消息的写入只会写入最新的一个分片(顺序IO)。
\\-rw-r--r-- 1 root root 1835920 10月 11 19:18 00000000000000000000.index
\\-rw-r--r-- 1 root root 1073741684 10月 11 19:18 00000000000000000000.log
\\-rw-r--r-- 1 root root 2737884 10月 11 19:18 00000000000000000000.timeindex
\\-rw-r--r-- 1 root root 1828296 10月 11 19:30 00000000000003257573.index
\\-rw-r--r-- 1 root root 1073741513 10月 11 19:30 00000000000003257573.log
\\-rw-r--r-- 1 root root 2725512 10月 11 19:30 00000000000003257573.timeindex
\\-rw-r--r-- 1 root root 1834744 10月 11 19:42 00000000000006506251.index
\\-rw-r--r-- 1 root root 1073741771 10月 11 19:42 00000000000006506251.log
\\-rw-r--r-- 1 root root 2736072 10月 11 19:42 00000000000006506251.timeindex
\\-rw-r--r-- 1 root root 1832152 10月 11 19:54 00000000000009751854.index
\\-rw-r--r-- 1 root root 1073740984 10月 11 19:54 00000000000009751854.log
\\-rw-r--r-- 1 root root 2731572 10月 11 19:54 00000000000009751854.timeindex
\\-rw-r--r-- 1 root root 1808792 10月 11 20:06 00000000000012999310.index
\\-rw-r--r-- 1 root root 1073741584 10月 11 20:06 00000000000012999310.log
\\-rw-r--r-- 1 root root 10 10月 11 19:54 00000000000012999310.snapshot
\\-rw-r--r-- 1 root root 2694564 10月 11 20:06 00000000000012999310.timeindex
\\-rw-r--r-- 1 root root 10485760 10月 11 20:09 00000000000016260431.index
\\-rw-r--r-- 1 root root 278255892 10月 11 20:09 00000000000016260431.log
\\-rw-r--r-- 1 root root 10 10月 11 20:06 00000000000016260431.snapshot
\\-rw-r--r-- 1 root root 10485756 10月 11 20:09 00000000000016260431.timeindex
\\-rw-r--r-- 1 root root 8 10月 11 19:03 leader-epoch-checkpoint一个分片包含多个不同后缀的日志文件,分片中的第一个消息的offset将作为该分片的基准偏移量,偏移量固定长度为20,不够前面补齐0,然后将其作为索引文件以及日志文件的文件名,如00000000000003257573.index、00000000000003257573.log、00000000000003257573.timeindex、相同文件名的文件组成一个分片(忽略后缀名),除了.index、.timeindex、 .log后缀的日志文件外其他日志文件,对应含义如下:
| 文件类型 | 作用 |
| .index | 偏移量索引文件,记录<相对位移,起始地址>映射关系,其中相对位移表示该分片的第一个消息,从1开始计算,起始地址表示对应相对位移消息在分片.log文件的起始地址 |
| .timeindex | 时间戳索引文件,记录<时间戳,相对位移>映射关系 |
| .log | 日志文件,存储消息的详细信息 |
| .snaphot | 快照文件 |
| .deleted | 分片文件删除时会先将该分片的所有文件加上.delete后缀,然后有delete-file任务延迟删除这些文件(file.delete.delay.ms可以设置延时删除的的时间) |
| .cleaned | 日志清理时临时文件 |
| .swap | Log Compaction 之后的临时文件 |
| .leader-epoch-checkpoint | 保存了每一任leader开始写入消息时的offset; 会定时更新, follower被选为leader时会根据这个确定哪些消息可用 |
2.日志索引
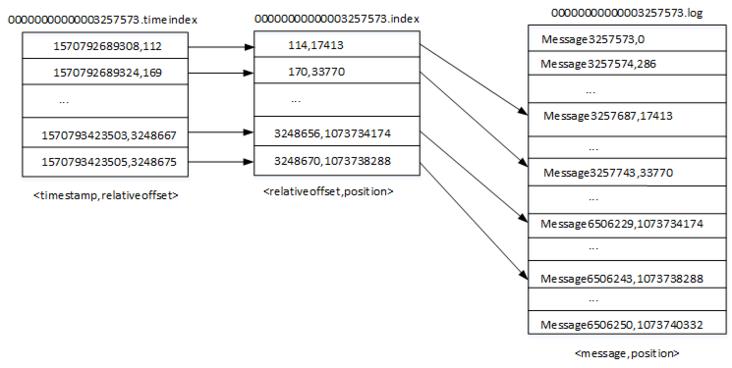
首先介绍下.index文件,这里以文件00000000000003257573.index为例,首先我们可以通过以下命令查看该索引文件的内容,我们可以看到输出结构为<offset,position>,实际上索引文件中保存的并不是offset而是相对位移,比如第一条消息的相对位移则为0,格式化输出时加上了基准偏移量,如上图所示,<114,17413>表示该分片相对位移为114的消息,其位移为3257573+114,即3257687,position表示对应offset在.log文件的物理地址,通过.index索引文件则可以获取对应offset所在的物理地址。索引采用稀疏索引的方式构建,并不保证分片中的每个消息都在索引文件有映射关系(.timeindex索引也是类似),主要是为了节省磁盘空间、内存空间,因为索引文件最终会映射到内存中。
\\# 查看该分片索引文件的前10条记录
bin/kafka-dump-log.sh \\--files /tmp/kafka-logs/nginx\\_access\\_log-1/00000000000003257573.index |head \\-n 10
Dumping /tmp/kafka-logs/nginx\\_access\\_log-1/00000000000003257573.index
offset: 3257687 position: 17413
offset: 3257743 position: 33770
offset: 3257799 position: 50127
offset: 3257818 position: 66484
offset: 3257819 position: 72074
offset: 3257871 position: 87281
offset: 3257884 position: 91444
offset: 3257896 position: 95884
offset: 3257917 position: 100845
\\# 查看该分片索引文件的后10条记录
$ bin/kafka-dump-log.sh \\--files /tmp/kafka-logs/nginx\\_access\\_log-1/00000000000003257573.index |tail \\-n 10
offset: 6506124 position: 1073698512
offset: 6506137 position: 1073702918
offset: 6506150 position: 1073707263
offset: 6506162 position: 1073711499
offset: 6506176 position: 1073716197
offset: 6506188 position: 1073720433
offset: 6506205 position: 1073725654
offset: 6506217 position: 1073730060
offset: 6506229 position: 1073734174
offset: 6506243 position: 1073738288比如查看offset为
6506155的消息:首先根据offset找到对应的分片,6506155所对应的分片为00000000000003257573,然后通过二分法在00000000000003257573.index文件中找到不大于6506155的最大索引值,得到<offset: 6506150, position: 1073707263>,然后从00000000000003257573.log的1073707263位置开始顺序扫描找到offset为650155的消息
说明:Kafka 中的索引文件以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项。每当写入一定量(由 broker 端参数 log.index.interval.bytes 指定,默认值为 4096,即 4KB)的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes 的值,对应地可以缩小或增加索引项的密度。稀疏索引通过 MappedByteBuffer 将索引文件映射到内存中,以加快索引的查询速度。
Kafka从0.10.0.0版本起,为分片日志文件中新增了一个.timeindex的索引文件,可以根据时间戳定位消息。同样我们可以通过脚本kafka-dump-log.sh查看时间索引的文件内容。
\\# 查看该分片时间索引文件的前10条记录
bin/kafka-dump-log.sh \\--files /tmp/kafka-logs/nginx\\_access\\_log-1/00000000000003257573.timeindex |head \\-n 10
Dumping /tmp/kafka-logs/nginx\\_access\\_log-1/00000000000003257573.timeindex
timestamp: 1570792689308 offset: 3257685
timestamp: 1570792689324 offset: 3257742
timestamp: 1570792689345 offset: 3257795
timestamp: 1570792689348 offset: 3257813
timestamp: 1570792689357 offset: 3257867
timestamp: 1570792689361 offset: 3257881
timestamp: 1570792689364 offset: 3257896
timestamp: 1570792689368 offset: 3257915
timestamp: 1570792689369 offset: 3257927
\\# 查看该分片时间索引文件的前10条记录
bin/kafka-dump-log.sh \\--files /tmp/kafka-logs/nginx\\_access\\_log-1/00000000000003257573.timeindex |tail \\-n 10
Dumping /tmp/kafka-logs/nginx\\_access\\_log-1/00000000000003257573.timeindex
timestamp: 1570793423474 offset: 6506136
timestamp: 1570793423477 offset: 6506150
timestamp: 1570793423481 offset: 6506159
timestamp: 1570793423485 offset: 6506176
timestamp: 1570793423489 offset: 6506188
timestamp: 1570793423493 offset: 6506204
timestamp: 1570793423496 offset: 6506214
timestamp: 1570793423500 offset: 6506228
timestamp: 1570793423503 offset: 6506240
timestamp: 1570793423505 offset: 6506248比如我想查看时间戳
1570793423501开始的消息:1.首先定位分片,将1570793423501与每个分片的最大时间戳进行对比(最大时间戳取时间索引文件的最后一条记录时间,如果时间为0则取该日志分段的最近修改时间),直到找到大于或等于1570793423501的日志分段,因此会定位到时间索引文件00000000000003257573.timeindex,其最大时间戳为1570793423505;2.通过二分法找到大于或等于1570793423501的最大索引项,即<timestamp: 1570793423503 offset: 6506240>(6506240为offset,相对位移为3247667);3.根据相对位移3247667去索引文件中找到不大于该相对位移的最大索引值<3248656,1073734174>;4.从日志文件00000000000003257573.log的1073734174位置处开始扫描,查找不小于1570793423501的数据。
3.日志删除
与其他消息中间件不同的是,Kafka集群中的消息不会因为消费与否而删除,跟日志一样消息最终会落盘,并提供对应的策略周期性(通过参数log.retention.check.interval.ms来设置,默认为5分钟)执行删除或者压缩操作(broker配置文件log.cleanup.policy参数如果为“delete”则执行删除操作,如果为“compact”则执行压缩操作,默认为“delete”)。
3.1 基于时间的日志删除
| 参数 | 默认值 | 说明 |
|---|---|---|
| log.retention.hours | 168 | 日志保留时间(小时) |
| log.retention.minutes | 无 | 日志保留时间(分钟),优先级大于小时 |
| log.retention.ms | 无 | 日志保留时间(毫秒),优先级大于分钟 |
当消息在集群保留时间超过设定阈值(log.retention.hours,默认为168小时,即七天),则需要进行删除。这里会根据分片日志的最大时间戳来判断该分片的时间是否满足删除条件,最大时间戳首先会选取时间戳索引文件中的最后一条索引记录,如果对应的时间戳值大于0则取该值,否则为最近一次修改时间。
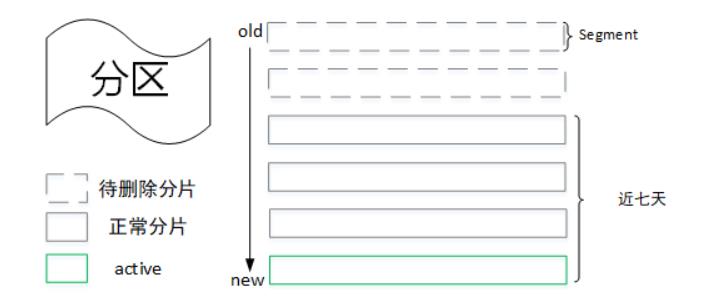
这里不直接选取最后修改时间的原因是避免分片日志的文件被无意篡改而导致其时间不准。
如果恰好该分区下的所有日志分片均已过期,那么会先生成一个新的日志分片作为新消息的写入文件,然后再执行删除参数。
3.2 基于空间的日志删除
| 参数 | 默认值 | 说明 |
|---|---|---|
| log.retention.bytes | 1073741824(即1G),默认未开启,即无穷大 | 日志文件总大小,并不是指单个分片的大小 |
| log.segment.bytes | 1073741824(即1G) | 单个日志分片大小 |
首先会计算待删除的日志大小diff(totalSize-log.rentention.bytes),然后从最旧的一个分片开始查看可以执行删除操作的文件集合(如果diff-segment.size>=0,则满足删除条件),最后执行删除操作。
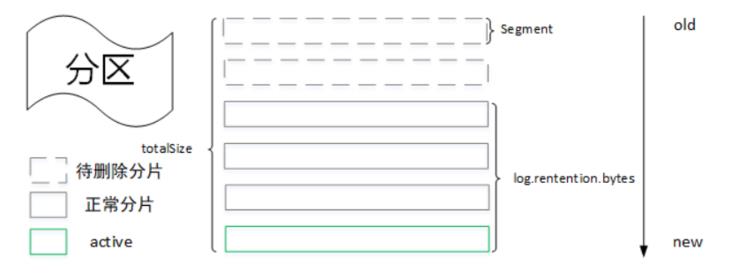
3.3 基于日志起始偏移量的日志删除

一般情况下,日志文件的起始偏移量(logStartOffset)会等于第一个日志分段的baseOffset,但是其值会因为删除消息请求而增长,logStartOffset的值实际上是日志集合中的最小消息,而小于这个值的消息都会被清理掉。如上图所示,我们假设logStartOffset=7421048,日志删除流程如下:
- 从最旧的日志分片开始遍历,判断其下一个分片的baseOffset是否小于或等于logStartOffset值,如果满足,则需要删除,因此第一个分片会被删除。
- 分片二的下一个分片baseOffset=6506251<7421048,所以分片二也需要删除。
- 分片三的下一个分片baseOffset=9751854>7421048,所以分片三不会被删除。
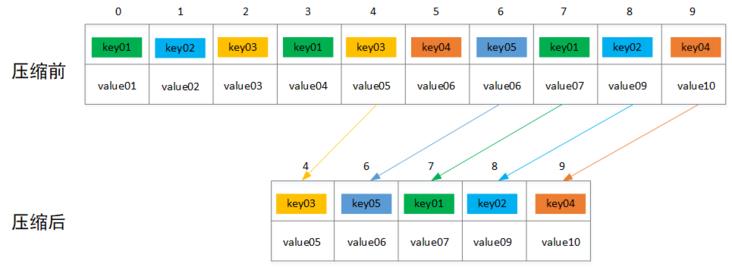
4.日志压缩
前面提到当broker配置文件log.cleanup.policy参数值设置为“compact”时,则会执行压缩操作,这里的压缩跟普通意义的压缩不一样,这里的压缩是指将相同key的消息只保留最后一个版本的value值,如下图所示,压缩之前offset是连续递增,压缩之后offset递增可能不连续,只保留5条消息记录。
Kafka日志目录下cleaner-offset-checkpoint文件,用来记录每个主题的每个分区中已经清理的偏移量,通过这个偏移量可以将分区中的日志文件分成两个部分:clean表示已经压缩过;dirty表示还未进行压缩,如下图所示(active segment不会参与日志的压缩操作,因为会有新的数据写入该文件)。

\\-rw-r--r-- 1 root root 4 10月 11 19:02 cleaner-offset-checkpoint
drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx\\_access\\_log-0/
drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx\\_access\\_log-1/
drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx\\_access\\_log-2/
\\-rw-r--r-- 1 root root 0 9月 18 09:50 .lock
\\-rw-r--r-- 1 root root 4 10月 16 11:19 log-start-offset-checkpoint
\\-rw-r--r-- 1 root root 54 9月 18 09:50 meta.properties
\\-rw-r--r-- 1 root root 1518 10月 16 11:19 recovery-point-offset-checkpoint
\\-rw-r--r-- 1 root root 1518 10月 16 11:19 replication-offset-checkpoint
#cat cleaner-offset-checkpoint
nginx\\_access\\_log 0 5033168
nginx\\_access\\_log 1 5033166
nginx\\_access\\_log 2 5033168日志压缩时会根据dirty部分数据占日志文件的比例(cleanableRatio)来判断优先压缩的日志,然后为dirty部分的数据建立key与offset映射关系(保存对应key的最大offset)存入SkimpyoffsetMap中,然后复制segment分段中的数据,只保留SkimpyoffsetMap中记录的消息,压缩之后的相关日志文件大小会减少,为了避免出现过小的日志文件与索引文件,压缩时会对所有的segment进行分组(一个组的分片大小不会超过设置的log.segment.bytes值大小),同一个分组的多个分片日志压缩之后变成一个分片。
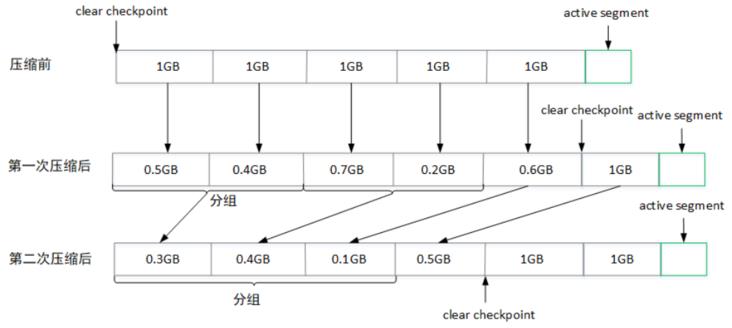
如上图所示,所有消息都还没压缩前
clear checkpoint值为0,表示该分区的数据还没进行压缩,第一次压缩后,之前每个分片的日志文件大小都有所减少,同时会移动clear checkpoint的位置到这一次压缩结束的offset值。第二次压缩时,会将前两个分片0.5GB,0.4GB组成一个分组,0.7GB,0.2GB组成一个分组进行压缩,以此类推。
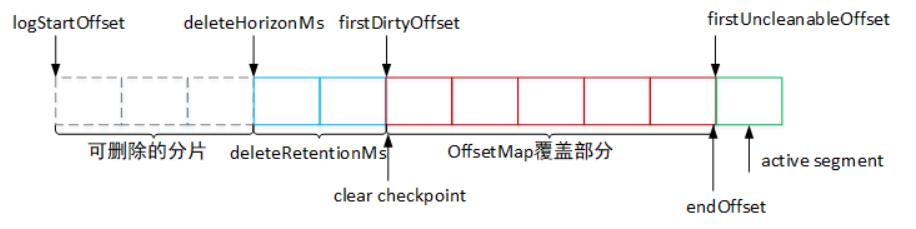
如上图所示,日志压缩的主要流程如下:
- 计算
deleteHorizonMs值:当某个消息的value值为空时,该消息会被保留一段时间,超时之后会在下一次的得日志压缩中被删除,所以这里会计算deleteHorizonMs,根据该值确定可以删除value值为空的日志分片。(deleteHorizonMs = clean部分的最后一个分片的lastModifiedTime - deleteRetionMs,deleteRetionMs通过配置文件log.cleaner.delete.retention.ms配置,默认为24小时)。- 确定压缩dirty部分的offset范围[firstDirtyOffset,endOffset):其中
firstDirtyOffset表示dirty的起始位移,一般会等于clear checkpoint值,firstUncleanableOffset表示不能清理的最小位移,一般会等于活跃分片的baseOffset,然后从firstDirtyOffset位置开始遍历日志分片,并填充key与offset的映射关系至SkimpyoffsetMap中,当该map被填充满或到达上限firstUncleanableOffset时,就可以确定日志压缩上限endOffset。- 将[logStartOffset,endOffset)中的日志分片进行分组,然后按照分组的方式进行压缩。
三、副本
kafka支持消息的冗余备份,可以设置对应主题的副本数(--replication-factor参数设置主题的副本数可在创建主题的时候指定,offsets.topic.replication.factor设置消费主题_consumer_offsets副本数,默认为3),每个副本包含的消息一样(但不是完全一致,可能从副本的数据较主副本稍微有些落后)。每个分区的副本集合中会有一个副本被选举为主副本(leader),其他为从副本,所有的读写请求由主副本对外提供,从副本负责将主副本的数据同步到自己所属分区,如果主副本所在分区宕机,则会重新选举出新的主副本对外提供服务。
1.ISR集合
ISR(In-Sync Replica)集合,表示目前可以用的副本集合,每个分区中的leader副本会维护此分区的ISR集合。这里的可用是指从副本的消息量与主副本的消息量相差不大,加入至ISR集合中的副本必须满足以下几个条件:
- 副本所在节点需要与ZooKeeper维持心跳。
- 从副本的最后一条消息的offset需要与主副本的最后一条消息offset差值不超过设定阈值(
replica.lag.max.messages)或者副本的LEO落后于主副本的LEO时长不大于设定阈值(replica.lag.time.max.ms),官方推荐使用后者判断,并在新版本kafka0.10.0移除了replica.lag.max.messages参数。
如果从副本不满足以上的任意条件,则会将其提出ISR集合,当其再次满足以上条件之后又会被重新加入集合中。ISR的引入主要是解决同步副本与异步复制两种方案各自的缺陷(同步副本中如果有个副本宕机或者超时就会拖慢该副本组的整体性能;如果仅仅使用异步副本,当所有的副本消息均远落后于主副本时,一旦主副本宕机重新选举,那么就会存在消息丢失情况)。
2.HW&LEO
HW(High Watermark)是一个比较特殊的offset标记,消费端消费时只能拉取到小于HW的消息而HW及之后的消息对于消费者来说是不可见的,该值由主副本管理,当ISR集合中的全部从副本都拉取到HW指定消息之后,主副本会将HW值+1,即指向下一个offset位移,这样可以保证HW之前消息的可靠性。

LEO(Log End Offset)表示当前副本最新消息的下一个offset,所有副本都存在这样一个标记,如果是主副本,当生产端往其追加消息时,会将其值+1。当从副本从主副本成功拉取到消息时,其值也会增加。
HW(High Watermark):俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。分区 ISR 集合中的每个副本都会维护自身的 LEO(Log End Offset):俗称日志末端位移,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
LEO:该副本底层 log文件下一条要写入的消息的位移,例如 LEO=10则当前文件已经写了了10条消息,位移是[0,10)。
HW:所有分区已提交的的位移,一般HW<=LEO。
多副本下,各个副本中的 HW和 LEO的演变过程:
某个分区有3个副本分别位于 broker0、broker1 和 broker2 节点中,假设 broker0 上的副本1为当前分区的 Leader 副本,那么副本2和副本3就是 Follower 副本,整个消息追加的过程可以概括如下:
【1】生产者客户端发送消息至 Leader 副本(副本1)中;
【2】消息被追加到 Leader 副本的本地日志,并且会更新日志的偏移量。
【3】Follower 副本(副本2和副本3)向 Leader 副本请求同步数据。
【4】Leader 副本所在的服务器读取本地日志,并更新对应拉取的 Follower 副本的信息。
【5】Leader 副本所在的服务器将拉取结果返回给 Follower 副本。
【6】Follower 副本收到 Leader 副本返回的拉取结果,将消息追加到本地日志中,并更新日志的偏移量信息。
某一时刻,Leader 副本的 LEO 增加至5,并且所有副本的 HW 还都为0。
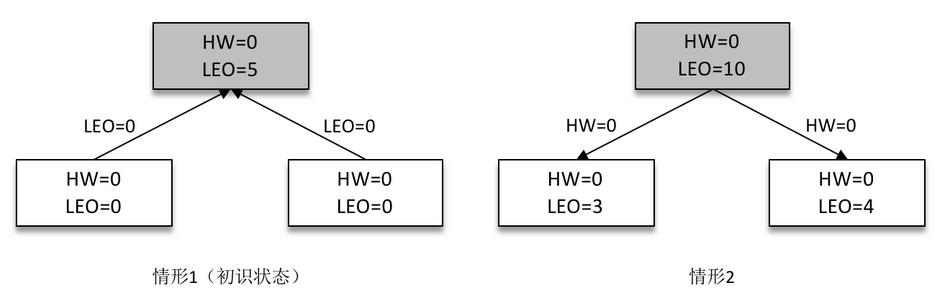
之后 Follower 副本(不带阴影的方框)向 Leader 副本拉取消息,在拉取的请求中会带有自身的 LEO 信息,这个 LEO 信息对应的是 FetchRequest 请求中的 fetch_offset。Leader 副本返回给 Follower 副本相应的消息,并且还带有自身的 HW 信息,如上图(右)所示,这个 HW 信息对应的是 FetchResponse 中的 high_watermark。
此时两个 Follower 副本各自拉取到了消息,并更新各自的 LEO 为3和4。与此同时,Follower 副本还会更新自己的 HW,更新 HW 的算法是比较当前 LEO 和 Leader 副本中传送过来的 HW的值,取较小值作为自己的 HW 值。当前两个 Follower 副本的 HW 都等于0(min(0,0) = 0)。
接下来 Follower 副本再次请求拉取 Leader 副本中的消息,如下图(左)所示。
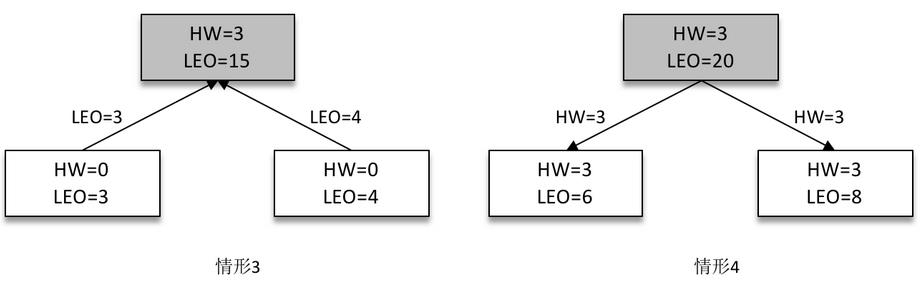
此时 Leader 副本收到来自 Follower 副本的 FetchRequest 请求,其中带有 LEO 的相关信息,选取其中的最小值作为新的 HW,即 min(15,3,4)=3。然后连同消息和 HW 一起返回 FetchResponse 给 Follower 副本,如上图(右)所示。注意 Leader 副本的 HW 是一个很重要的东西,因为它直接影响了分区数据对消费者的可见性。两个 Follower 副本在收到新的消息之后更新 LEO 并且更新自己的 HW 为3(min(LEO,3)=3)。
2.1 从副本更新LEO与HW

从副本的数据是来自主副本,通过向主副本发送fetch请求获取数据,从副本的LEO值会保存在两个地方,一个是自身所在的节点),一个是主副本所在节点,自身节点保存LEO主要是为了更新自身的HW值,主副本保存从副本的LEO也是为了更新其HW。当从副本每写入一条新消息就会增加其自身的LEO,主副本收到从副本的fetch请求,会先从自身的日志中读取对应数据,在数据返回给从副本之前会先去更新其保存的从副本LEO值。一旦从副本数据写入完成,就会尝试更新自己的HW值,比较LEO与fetch响应中主副本的返回HW,取最小值作为新的HW值。
2.2 主副本更新LEO与HW
主副本有日志写入时就会更新其自身的LEO值,与从副本类似。而主副本的HW值是分区的HW值,决定分区数据对应消费端的可见性,以下四种情况,主副本会尝试更新其HW值:
- 副本成为主副本:当某个副本成为主副本时,kafka会尝试更新分区的HW值。
- broker出现奔溃导致副本被踢出ISR集合:如果有broker节点奔溃则会看是否影响对应分区,然后会去检查分区的HW值是否需要更新。
- 生成端往主副本写入消息时:消息写入会增加其LEO值,此时会查看是否需要修改HW值。
- 主副本接受到从副本的fetch请求时:主副本在处理从副本的fetch请求时会尝试更新分区HW值。
前面是去尝试更新HW,但是不一定会更新,主副本上保存着从副本的LEO值与自身的LEO值,这里会比较所有满足条件的副本LEO值,并选择最小的LEO值最为分区的HW值,其中满足条件的副本是指满足以下两个条件之一:
- 副本在ISR集合中
- 副本的LEO落后于主副本的LEO时长不大于设定阈值(replica.lag.time.max.ms,默认为10s)
3.数据丢失场景
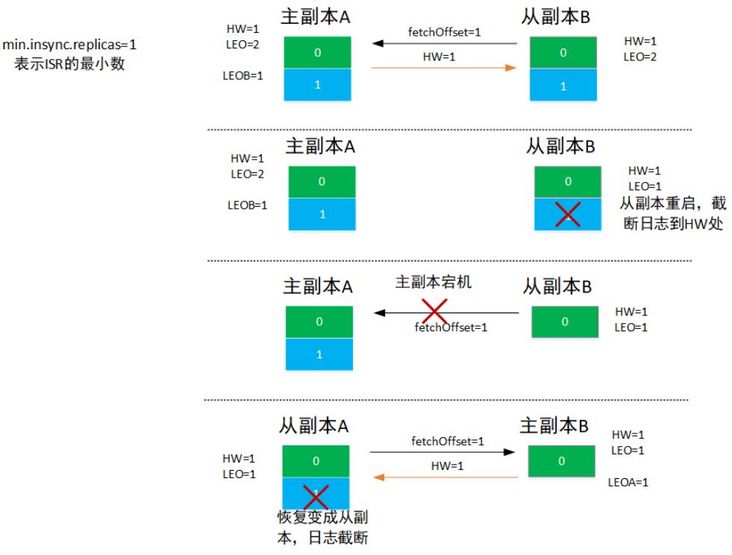
前面提到如果仅仅依赖HW来进行日志截断以及水位的判断会存在问题,如上图所示,假定存在两个副本A、副本B,最开始A为主副本,B为从副本,且参数min.insync.replicas=1,即ISR只有一个副本时也会返回成功:
- 初始情况为主副本A已经写入了两条消息,对应HW=1,LEO=2,LEOB=1,从副本B写入了一条消息,对应HW=1,LEO=1。
- 此时从副本B向主副本A发起fetchOffset=1请求,主副本收到请求之后更新LEOB=1,表示副本B已经收到了消息0,然后尝试更新HW值,
min(LEO,LEOB)=1,即不需要更新,然后将消息1以及当前分区HW=1返回给从副本B,从副本B收到响应之后写入日志并更新LEO=2,然后更新其HW=1,虽然已经写入了两条消息,但是HW值需要在下一轮的请求才会更新为2。 - 此时从副本B重启,重启之后会根据HW值进行日志截断,即消息1会被删除。
- 从副本B向主副本A发送fetchOffset=1请求,如果此时主副本A没有什么异常,则跟第二步骤一样没有什么问题,假设此时主副本也宕机了,那么从副本B会变成主副本。
- 当副本A恢复之后会变成从副本并根据HW值进行日志截断,即把消息1丢失,此时消息1就永久丢失了。
4.数据不一致场景

如图所示,假定存在两个副本A、副本B,最开始A为主副本,B为从副本,且参数min.insync.replicas=1,即ISR只有一个副本时也会返回成功:
- 初始状态为主副本A已经写入了两条消息对应HW=1,LEO=2,LEOB=1,从副本B也同步了两条消息,对应HW=1,LEO=2。
- 此时从副本B向主副本发送fetchOffset=2请求,主副本A在收到请求后更新分区HW=2并将该值返回给从副本B,如果此时从副本B宕机则会导致HW值写入失败。
- 我们假设此时主副本A也宕机了,从副本B先恢复并成为主副本,此时会发生日志截断,只保留消息0,然后对外提供服务,假设外部写入了一个消息1(这个消息与之前的消息1不一样,用不同的颜色标识不同消息)。
- 等副本A起来之后会变成从副本,不会发生日志截断,因为HW=2,但是对应位移1的消息其实是不一致的
5.leader epoch机制
HW值被用于衡量副本备份成功与否以及出现失败情况时候的日志截断依据可能会导致数据丢失与数据不一致情况,因此在新版的Kafka(0.11.0.0)引入了leader epoch概念,leader epoch表示一个键值对<epoch, offset>,其中epoch表示leader主副本的版本号,从0开始编码,当leader每变更一次就会+1,offset表示该epoch版本的主副本写入第一条消息的位置,比如<0,0>表示第一个主副本从位移0开始写入消息,<1,100>表示第二个主副本版本号为1并从位移100开始写入消息,主副本会将该信息保存在缓存中并定期写入到checkpoint文件中,每次发生主副本切换都会去从缓存中查询该信息,下面简单介绍下leader epoch的工作原理:
- 每条消息会都包含一个4字节的leader epoch number值
- 每个log目录都会创建一个leader epoch sequence文件用来存放主副本版本号以及开始位移。
- 当一个副本成为主副本之后,会在leader epoch sequence文件末尾添加一条新的记录,然后每条新的消息就会变成新的leader epoch值。
-
当某个副本宕机重启之后,会进行以下操作:
- 从leader epoch sequence文件中恢复所有的leader epoch。
- 向分区主副本发送LeaderEpoch请求,请求包含了从副本的leader epoch sequence文件中的最新leader epoch值。
- 主副本返回从副本对应LeaderEpoch的lastOffset,返回的lastOffset分为两种情况,一种是返回比从副本请求中leader epoch版本大1的开始位移,另外一种是与请求中的leader epoch相等则直接返回当前主副本的LEO值。
- 如果从副本的leader epoch开始位移大于从leader中返回的lastOffset,那么会将从副本的leader epoch sequence值保持跟主副本一致。
- 从副本截断本地消息到主副本返回的LastOffset所在位移处。
- 从副本开始从主副本开始拉取数据。
- 在获取数据时,如果从副本发现消息中的leader epoch值比自身的最新leader epoch值大,则会将该leader epoch 值写到leader epoch sequence文件,然后继续同步文件。
下面看下leader epoch机制如何避免前面提到的两种异常场景:
5.1 数据丢失场景解决
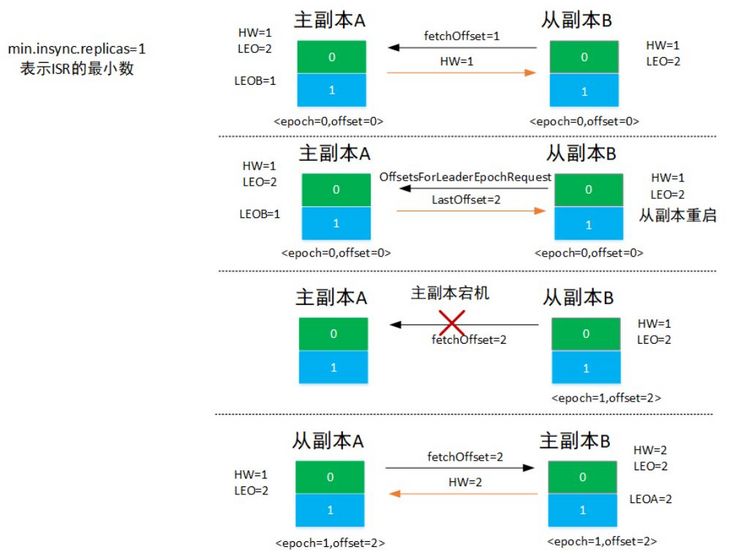
- 如图所示,当从副本B重启之后向主副本A发送
offsetsForLeaderEpochRequest,epoch主从副本相等,则A返回当前的LEO=2,从副本B中没有任何大于2的位移,因此不需要截断。 - 当从副本B向主副本A发送fetchoffset=2请求时,A宕机,所以从副本B成为主副本,并更新epoch值为<epoch=1, offset=2>,HW值更新为2。
- 当A恢复之后成为从副本,并向B发送fetcheOffset=2请求,B返回HW=2,则从副本A更新HW=2。
- 主副本B接受外界的写请求,从副本A向主副本A不断发起数据同步请求。
从上可以看出引入leader epoch值之后避免了前面提到的数据丢失情况,但是这里需要注意的是如果在上面的第一步,从副本B起来之后向主副本A发送offsetsForLeaderEpochRequest请求失败,即主副本A同时也宕机了,那么消息1就会丢失,具体可见下面数据不一致场景中有提到。
5.2 数据不一致场景解决

- 从副本B恢复之后向主副本A发送
offsetsForLeaderEpochRequest请求,由于主副本也宕机了,因此副本B将变成主副本并将消息1截断,此时接受到新消息1的写入。 - 副本A恢复之后变成从副本并向主副本A发送
offsetsForLeaderEpochRequest请求,请求的epoch值小于主副本B,因此主副本B会返回epoch=1时的开始位移,即lastoffset=1,因此从副本A会截断消息1。 - 从副本A从主副本B拉取消息,并更新epoch值<epoch=1, offset=1>。
可以看出epoch的引入避免的数据不一致,但是两个副本均宕机,则还是存在数据丢失的场景,前面的所有讨论都是建立在min.insync.replicas=1的前提下,因此需要在数据的可靠性与速度方面做权衡。
四、生产者
1.消息分区选择
生产者的作用主要是生产消息,将消息存入到Kafka对应主题的分区中,具体某个消息应该存入哪个分区,有以下三个策略决定(优先级由上到下,依次递减):
- 如果消息发送时指定了消息所属分区,则会直接发往指定分区。
- 如果没有指定消息分区,但是设置了消息的
key,则会根据key的哈希值选择分区。 - 如果前两者均不满足,则会采用轮询的方式选择分区。
2.ack参数设置及意义
生产端往kafka集群发送消息时,可以通过request.required.acks参数来设置数据的可靠性级别
- 1:默认为1,表示在ISR中的leader副本成功接收到数据并确认后再发送下一条消息,如果主节点宕机则可能出现数据丢失场景,详细分析可参考前面提到的副本章节。
- 0:表示生产端不需要等待节点的确认就可以继续发送下一批数据,这种情况下数据传输效率最高,但是数据的可靠性最低。
- -1:表示生产端需要等待ISR中的所有副本节点都收到数据之后才算消息写入成功,可靠性最高,但是性能最低,如果服务端的
min.insync.replicas值设置为1,那么在这种情况下允许ISR集合只有一个副本,因此也会存在数据丢失的情况。
3.幂等特性
所谓的幂等性,是指一次或者多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外),通俗一点的理解就是同一个操作任意执行多次产生的影响或效果与一次执行影响相同,幂等的关键在于服务端能否识别出请求是否重复,然后过滤掉这些重复请求,通常情况下需要以下信息来实现幂等特性:
- 唯一标识:判断某个请求是否重复,需要有一个唯一性标识,然后服务端就能根据这个唯一标识来判断是否为重复请求。
- 记录已经处理过的请求:服务端需要记录已经处理过的请求,然后根据唯一标识来判断是否是重复请求,如果已经处理过,则直接拒绝或者不做任何操作返回成功。
kafka中Producer端的幂等性是指当发送同一条消息时,消息在集群中只会被持久化一次,其幂等是在以下条件中才成立:
- 只能保证生产端在单个会话内的幂等,如果生产端因为某些原因意外挂掉然后重启,此时是没办法保证幂等的,因为这时没办法获取到之前的状态信息,即无法做到垮会话级别的幂等。
- 幂等性不能垮多个主题分区,只能保证单个分区内的幂等,涉及到多个消息分区时,中间的状态并没有同步。
如果要支持垮会话或者垮多个消息分区的情况,则需要使用kafka的事务性来实现。
为了实现生成端的幂等语义,引入了Producer ID(PID)与Sequence Number的概念:
- Producer ID(PID):每个生产者在初始化时都会分配一个唯一的PID,PID的分配对于用户来说是透明的。
- Sequence Number(序列号):对于给定的PID而言,序列号从0开始单调递增,每个主题分区均会产生一个独立序列号,生产者在发送消息时会给每条消息添加一个序列号。broker端缓存了已经提交消息的序列号,只有比缓存分区中最后提交消息的序列号大1的消息才会被接受,其他会被拒绝。
3.1 生产端消息发送流程
下面简单介绍下支持幂等的消息发送端工作流程:
1)生产端通过Kafkaproducer会将数据添加到RecordAccumulator中,数据添加时会判断是否需要新建一个ProducerBatch。
2)生产端后台启动发送线程,会判断当前的PID是否需要重置,重置的原因是因为某些消息分区的batch重试多次仍然失败最后因为超时而被移除,这个时候序列号无法连续,导致后续消息无法发送,因此会重置PID,并将相关缓存信息清空,这个时候消息会丢失。
3)发送线程判断是否需要新申请PID,如果需要则会阻塞直到获取到PID信息。
4)发送线程在调用sendProducerData()方法发送数据时,会进行以下判断:
- 判断主题分区是否可以继续发送、PID是否有效、如果是重试batch需要判断之前的batch是否发送完成,如果没有发送完成则会跳过当前主题分区的消息发送,直到前面的batch发送完成。
- 如果对应ProducerBatch没有分配对应的PID与序列号信息,则会在这里进行设置。
3.2 服务端消息接受流程
服务端(broker)在收到生产端发送的数据写请求之后,会进行一些判断来决定是否可以写入数据,这里也主要介绍关于幂等相关的操作流程。
1)如果请求设置了幂等特性,则会检查是否对ClusterResource有IdempotentWrite权限,如果没有,则会返回错误CLUSTER_AUTHORIZATION_FAILED。
2)检查是否有PID信息。
3)根据batch的序列号检查该batch是否重复,服务端会缓存每个PID对应主题分区的最近5个batch信息,如果有重复,则直接返回写入成功,但是不会执行真正的数据写入操作。
4)如果有PID且非重复batch,则进行以下操作:
- 判断该PID是否已经存在缓存中。
- 如果不存在则判断序列号是否是从0开始,如果是则表示为新的PID,在缓存中记录PID的信息(包括PID、epoch以及序列号信息),然后执行数据写入操作;如果不存在但是序列号不是从0开始,则直接返回错误,表示PID在服务端以及过期或者PID写的数据已经过期。
- 如果PID存在,则会检查PID的epoch版本是否与服务端一致,如果不一致且序列号不是从0开始,则返回错误。如果epoch不一致但是序列号是从0开始,则可以正常写入。
- 如果epoch版本一致,则会查询缓存中最近一次序列号是否连续,不连续则会返回错误,否则正常写入。
五、消费者
消费者主要是从Kafka集群拉取消息,然后进行相关的消费逻辑,消费者的消费进度由其自身控制,增加消费的灵活性,比如消费端可以控制重复消费某些消息或者跳过某些消息进行消费。
1.消费组
多个消费者可以组成一个消费组,每个消费者只属于一个消费组。消费组订阅主题的每个分区只会分配给该消费组中的某个消费者处理,不同的消费组之间彼此隔离无依赖。同一个消息只会被消费组中的一个消费者消费,如果想要让同一个消息被多个消费者消费,那么每个消费者需要属于不同的消费组,且对应消费组中只有该一个消费者,消费组的引入可以实现消费的“独占”或“广播”效果。
- 消费组下可以有多个消费者,个数支持动态变化。
- 消费组订阅主题下的每个分区只会分配给消费组中的一个消费者。
- group.id标识消费组,相同则属于同一消费组。
- 不同消费组之间相互隔离互不影响。
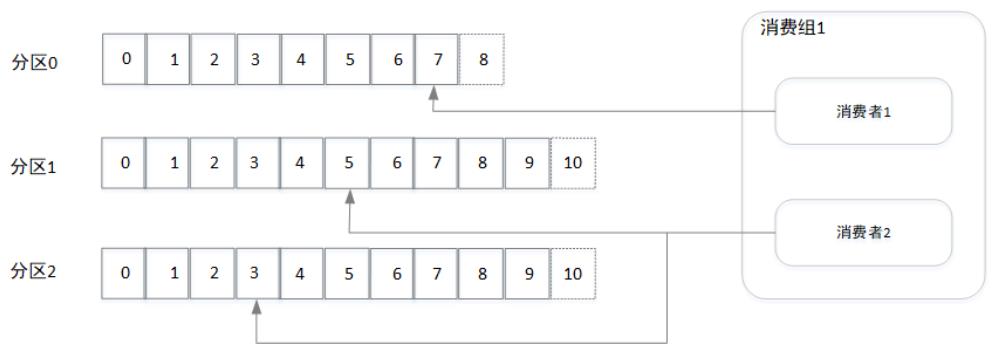
如图所示,消费组1中包含两个消费者,其中消费者1分配消费分区0,消费者2分配消费分区1与分区2。此外消费组的引入还支持消费者的水平扩展及故障转移,比如从上图我们可以看出消费者2的消费能力不足,相对消费者1来说消费进度比较落后,我们可以往消费组里面增加一个消费者以提高其整体的消费能力,如下图所示:
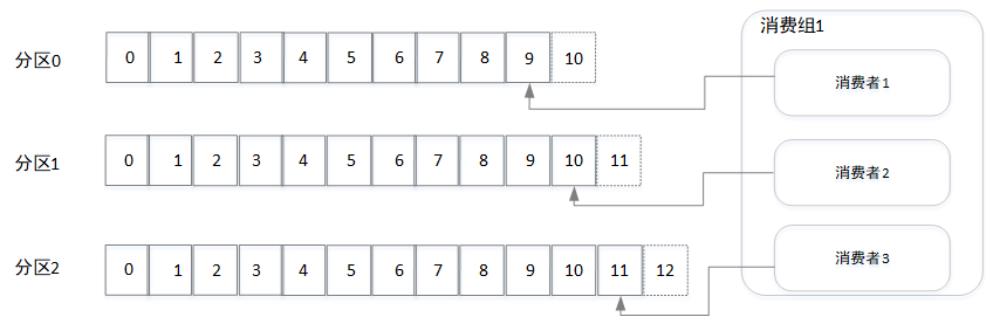
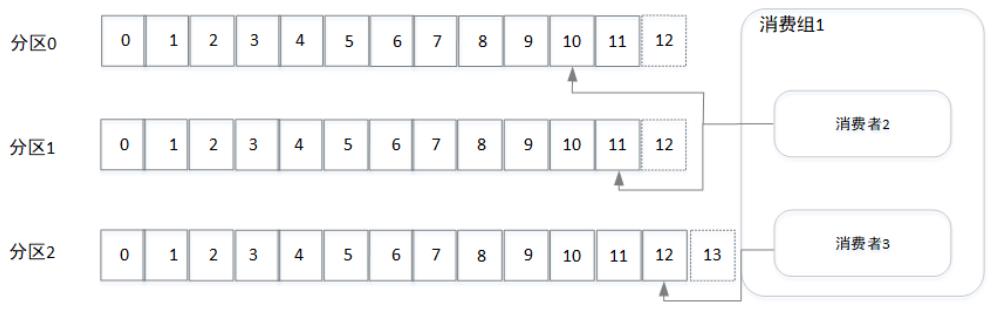
假设消费者1所在机器出现宕机,消费组会发送重平衡,假设将分区0分配给消费者2进行消费,如下图所示。同个消费组中消费者的个数不是越多越好,最大不能超过主题对应的分区数,如果超过则会出现超过的消费者分配不到分区的情况,因为分区一旦分配给消费者就不会再变动,除非组内消费者个数出现变动而发生重平衡。
2.消费位移
2.1 消费位移主题
Kafka 0.9开始将消费端的位移信息保存在集群的内部主题(__consumer_offsets)中,该主题默认为50个分区,每条日志项的格式都是:<TopicPartition, OffsetAndMetadata>,其key为主题分区主要存放主题、分区以及消费组信息,value为OffsetAndMetadata对象主要包括位移、位移提交时间、自定义元数据等信息。只有消费组往kafka中提交位移才会往这个主题中写入数据,如果消费端将消费位移信息保存在外部存储,则不会有消费位移信息,下面可以通过kafka-console-consumer.sh脚本查看主题消费位移信息。
\\# bin/kafka-console-consumer.sh --topic \\_\\_consumer\\_offsets --bootstrap-server localhost:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\\\\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
\\[consumer-group01,nginx\\_access\\_log,2\\]::OffsetAndMetadata(offset\\=17104625, leaderEpoch\\=Optional.\\[0\\], metadata\\=, commitTimestamp\\=1573475863555, expireTimestamp\\=None)
\\[consumer-group01,nginx\\_access\\_log,1\\]::OffsetAndMetadata(offset\\=17103024, leaderEpoch\\=Optional.\\[0\\], metadata\\=, commitTimestamp\\=1573475863555, expireTimestamp\\=None)
\\[consumer-group01,nginx\\_access\\_log,0\\]::OffsetAndMetadata(offset\\=17107771, leaderEpoch\\=Optional.\\[0\\], metadata\\=, commitTimestamp\\=1573475863555, expireTimestamp\\=None)2.2 消费位移自动提交
消费端可以通过设置参数enable.auto.commit来控制是自动提交还是手动,如果值为true则表示自动提交,在消费端的后台会定时的提交消费位移信息,时间间隔由auto.commit.interval.ms(默认为5秒)。
但是如果设置为自动提交会存在以下几个问题:
1)可能存在重复的位移数据提交到消费位移主题中,因为每隔5秒会往主题中写入一条消息,不管是否有新的消费记录,这样就会产生大量的同key消息,其实只需要一条,因此需要依赖前面提到日志压缩策略来清理数据。
2)重复消费,假设位移提交的时间间隔为5秒,那么在5秒内如果发生了rebalance,则所有的消费者会从上一次提交的位移处开始消费,那么期间消费的数据则会再次被消费。
2.3 消费位移手动提交
手动提交需要将enable.auto.commit值设置为false,然后由业务消费端来控制消费进度,手动提交又分为以下三种类型:
- 同步手动提交位移:如果调用的是同步提交方法
commitSync(),则会将poll拉取的最新位移提交到kafka集群,提交成功前会一直等待提交成功。 - 异步手动提交位移:调用异步提交方法
commitAsync(),在调用该方法之后会立刻返回,不会阻塞,然后可以通过回调函数执行相关的异常处理逻辑。 - 指定提交位移:指定位移提交也分为异步跟同步,传参为Map<TopicPartition, OffsetAndMetadata>,其中key为消息分区,value为位移对象。
3.分组协调者
分组协调者(Group Coordinator)是一个服务,kafka集群中的每个节点在启动时都会启动这样一个服务,该服务主要是用来存储消费分组相关的元数据信息,每个消费组均会选择一个协调者来负责组内各个分区的消费位移信息存储,选择的主要步骤如下:
- 首选确定消费组的位移信息存入哪个分区:前面提到默认的__consumer_offsets主题分区数为50,通过以下算法可以计算出对应消费组的位移信息应该存入哪个分区
partition = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)其中groupId为消费组的id,这个由消费端指定,groupMetadataTopicPartitionCount为主题分区数。 - 根据partition寻找该分区的leader所对应的节点broker,该broker的Coordinator即为该消费组的Coordinator。
4.重平衡机制
4.1 重平衡发生场景
以下几种场景均会触发重平衡操作:
1)新的消费者加入到消费组中。
2)消费者被动下线。比如消费者长时间的GC、网络延迟导致消费者长时间未向Group Coordinator发送心跳请求,均会认为该消费者已经下线并踢出。
3)消费者主动退出消费组。
4)消费组订阅的任意一个主题分区数出现变化。
5)消费者取消某个主题的订阅。
4.2 重平衡操作流程
重平衡的实现可以分为以下几个阶段:
1)查找Group Coordinator:消费者会从kafka集群中选择一个负载最小的节点发送GroupCoorinatorRequest请求,并处理返回响应GroupCoordinatorResponse。其中请求参数中包含消费组的id,响应中包含Coordinator所在节点id、host以及端口号信息。
2)Join group:当消费者拿到协调者的信息之后会往协调者发送加入消费组的请求JoinGroupRequest,当所有的消费者都发送该请求之后,协调者会从中选择一个消费者作为leader角色,然后将组内成员信息、订阅等信息发给消费者(响应格式JoinGroupResponse见下表),leader负责消费方案的分配。
JoinGroupRequest请求数据格式:
| 名称 | 类型 | 说明 |
|---|---|---|
| group_id | String | 消费者id |
| seesion_timeout | int | 协调者超过session_timeout指定的时间没有收到心跳消息,则认为该消费者下线 |
| member_id | String | 协调者分配给消费者的id |
| protocol_type | String | 消费组实现的协议,默认为sonsumer |
| group_protocols | List | 包含此消费者支持的全部PartitionAssignor类型 |
| protocol_name | String | PartitionAssignor类型 |
| protocol_metadata | byte[] | 针对不同PartitionAssignor类型序列化后的消费者订阅信息,包含用户自定义数据userData |
JoinGroupResponse响应数据格式:
| 名称 | 类型 | 说明 |
|---|---|---|
| error_code | short | 错误码 |
| generation_id | int | 协调者分配的年代信息 |
| group_protocol | String | 协调者选择的PartitionAssignor类型 |
| leader_id | String | Leader的member_id |
| member_id | String | 协调者分配给消费者的id |
| members | Map集合 | 消费组中全部的消费者订阅信息 |
| member_metadata | byte[] | 对应消费者的订阅信息 |
Synchronizing Group State阶段:当leader消费者完成消费方案的分配后会发送SyncGroupRequest请求给协调者,其他非leader节点也会发送该请求,只是请求参数为空,然后协调者将分配结果作为响应SyncGroupResponse发给各个消费者,请求及相应的数据格式如下表所示:
SyncGroupRequest请求数据格式:
| 名称 | 类型 | 说明 |
|---|---|---|
| group_id | String | 消费组的id |
| generation_id | int | 消费组保存的年代信息 |
| member_id | String | 协调者分配的消费者id |
| member_assignment | byte[] | 分区分配结果 |
SyncGroupResponse响应数据格式:
| 名称 | 类型 | 说明 |
|---|---|---|
| error_code | short | 错误码 |
| member_assignment | byte[] | 分配给当前消费者的分区 |
4.3 分区分配策略
Kafka提供了三个分区分配策略:RangeAssignor、RoundRobinAssignor以及StickyAssignor,下面简单介绍下各个算法的实现。
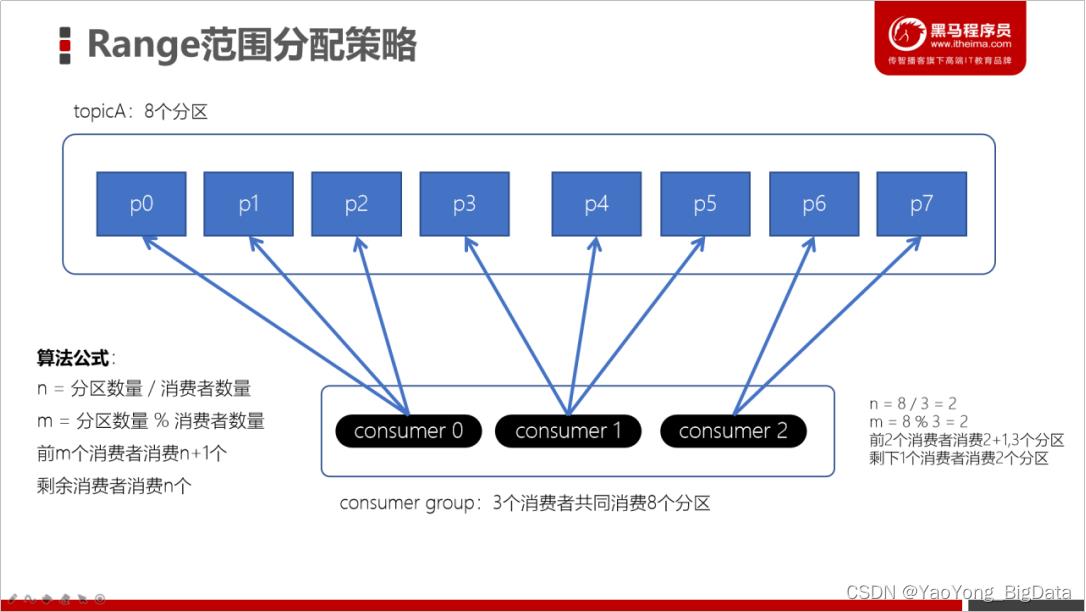
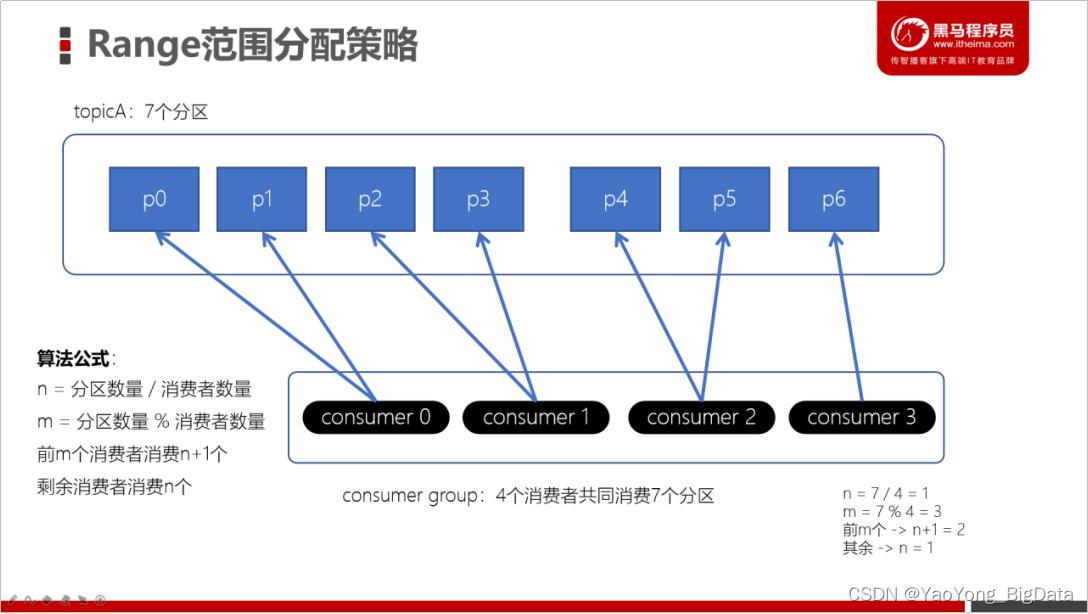
1)Range范围分配策略
Range范围分配策略是Kafka默认的分配策略,它可以确保每个消费者消费的分区数量是均衡的。
注意:Rangle范围分配策略是针对每个Topic的。
配置
配置消费者的partition.assignment.strategy为org.apache.kafka.clients.consumer.RangeAssignor。
算法公式
n = 分区数量 / 消费者数量
m = 分区数量 % 消费者数量
前m个消费者消费n+1个
剩余消费者消费n个
2)RoundRobin轮询策略
RoundRobinAssignor轮询策略是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序(topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区以此分配给每个消费者。
配置
配置消费者的partition.assignment.strategy为org.apache.kafka.clients.consumer.RoundRobinAssignor。
关于 Round Robin 重分配策略,其主要采用的是一种轮询的方式分配所有的分区,该策略主要实现的步骤如下。这里我们首先假设有三个 topic:t0、t1 和 t2,这三个 topic 拥有的分区数分别为 1、2 和 3,那么总共有六个分区,这六个分区分别为:t0-0、t1-0、t1-1、t2-0、t2-1 和 t2-2。这里假设我们有三个 consumer:C0、C1 和 C2,它们订阅情况为:C0 订阅 t0,C1 订阅 t0 和 t1,C2 订阅 t0、t1 和 t2。那么这些分区的分配步骤如下:
a.首先将所有的 partition 和 consumer 按照字典序进行排序,所谓的字典序,就是按照其名称的字符串顺序,那么上面的六个分区和三个 consumer 排序之后分别为:
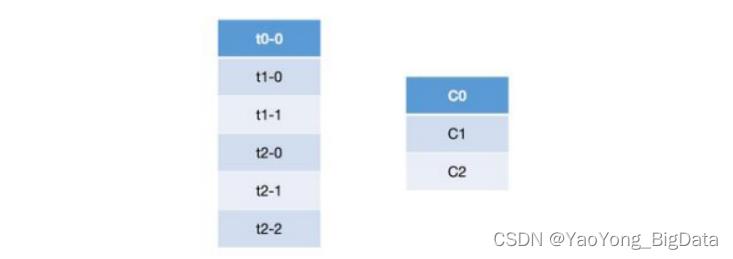
b.然后依次以按顺序轮询的方式将这六个分区分配给三个 consumer,如果当前 consumer 没有订阅当前分区所在的 topic,则轮询的判断下一个 consumer:
尝试将 t0-0 分配给 C0,由于 C0 订阅了 t0,因而可以分配成功;
尝试将 t1-0 分配给 C1,由于 C1 订阅了 t1,因而可以分配成功;
尝试将 t1-1 分配给 C2,由于 C2 订阅了 t1,因而可以分配成功;
尝试将 t2-0 分配给 C0,由于 C0 没有订阅 t2,因而会轮询下一个 consumer;
尝试将 t2-0 分配给 C1,由于 C1 没有订阅 t2,因而会轮询下一个 consumer;
尝试将 t2-0 分配给 C2,由于 C2 订阅了 t2,因而可以分配成功;
同理由于 t2-1 和 t2-2 所在的 topic 都没有被 C0 和 C1 所订阅,因而都不会分配成功,最终都会分配给 C2。
按照上述的步骤将所有的分区都分配完毕之后,最终分区的订阅情况如下:
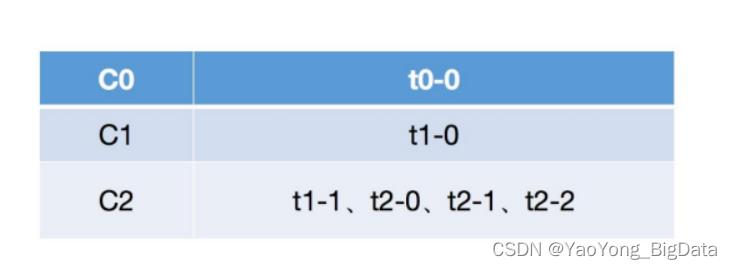
从上面的步骤分析可以看出,轮询的策略就是简单的将所有的partition和consumer按照字典序进行排序之后,然后依次将 partition 分配给各个 consumer,如果当前的 consumer 没有订阅当前的 partition,那么就会轮询下一个 consumer,直至最终将所有的分区都分配完毕。但是从上面的分配结果可以看出,轮询的方式会导致每个 consumer 所承载的分区数量不一致,从而导致各个 consumer 压力不均一。
3)Stricky粘性分配策略
kafka从0.11.x版本开始引入这种分配策略,它主要有两个目的:
a.分区的分配要尽可能均匀。
b.分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。
当发生分区重平衡,那么对于同一个分区而言,有可能之前的消费者和新指派的消费者不是同一个,之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。所以这种分配方式尽可能地让前后两次分以上是关于深入理解Kafka的主要内容,如果未能解决你的问题,请参考以下文章