Kubernetes 系列CNI 与网络流量模型
Posted 范桂飓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes 系列CNI 与网络流量模型相关的知识,希望对你有一定的参考价值。
目录
文章目录
- 目录
- Kubernetes Network 中的 IP 地址类型
- Kubernetes 的网络流量模型
- CNI
- CNI 的使用示例
- Flannel CNI
- Calico
- MACVLAN
- HOST-DEVICE
- Weave
Kubernetes Network 中的 IP 地址类型
Kubernetes 网络中涉及以下几种类型的 IP 地址:
-
Node IP:宿主机 IP 地址。
-
Pod IP:Pod 是 Kubernetes 的最小部署单元,Pod 下可以包含若干个 Containers,但是 Container 没有独立的 IP 地址,它们共享 Pod 的 IP 地址和 Ports 区间。
-
Cluster IP:这里所述 Cluster 并非 Kubernetes Cluster,而是 Kubernetes Service 的 IP 地址。外部网络是无法访问该地址的,只有 Kubernetes Cluster 内部才能访问。因为 Cluster IP 是一个虚拟的 IP 地址,即:没有网络设备为这个 IP 地址负责。在 Kubernetes 内部使用了 IPtables 规则来重定向到其本地端口,再均衡到后端的 Pods;
-
Public IP:因为 Cluster IP 能在 Kubernetes Cluster Internal 访问,属于应用程序内部的层级。如果希望将这个 Service 为 Kubernetes Cluster External 的客户端提供访问,就需要为这个 Service 提供一个 Public IP。
Kubernetes 的网络流量模型
同 Pod 内部的 Containers 间的通信(Container 模式)
Pod 内部的 Containers 通过 localhost 进行通信,它们使用了同一个 Network Namespace。对 Container 而言,hostname 就是 Pod 的名称。
Pod 内部的 Containers 共享同一个 IP 地址和端口区间,所以要为每个可以建立连接的 Container 分配不同的 Port 号。也就是说,Pod 中的 “应用” 需要自己协调端口号的分配和使用。
- 例如:创建一个 Pod ,包含两个 Containers。
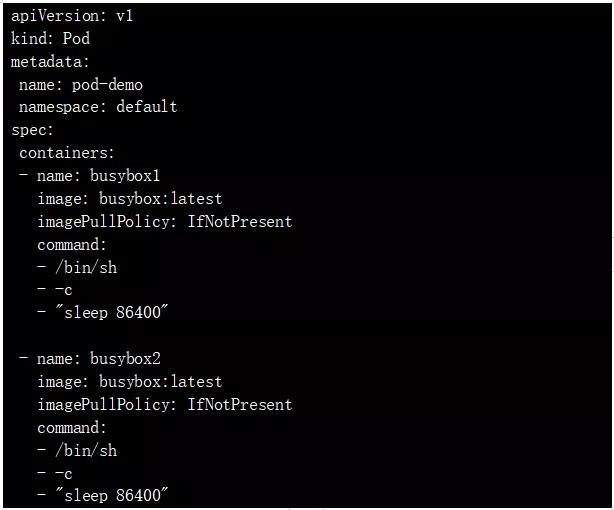


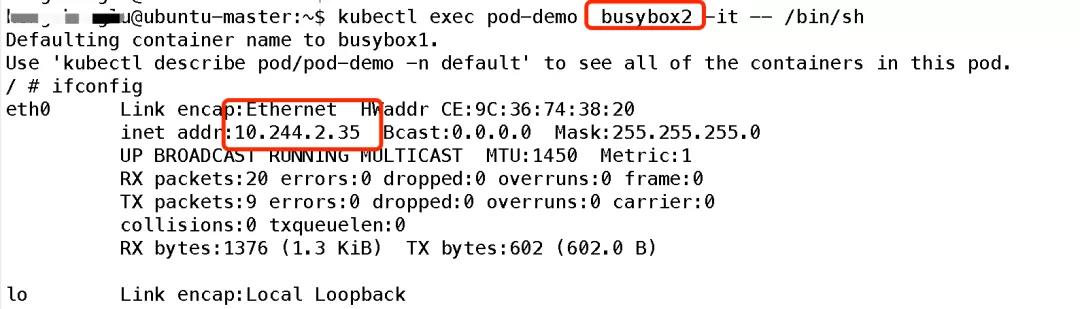
可以看到同一个 Pod 下属的两个 Containers 共享了 IP 地址。


可以看见,同一个 Pod 下属的两个 Containers 不能占有同一个 Port 号,因为 Port 区间也是共享的。
所以,我们可以将 Pod 理解为一个小型的 “操作系统沙盒”,两个进程可以使用同一个操作系统 IP 地址,自然也就不可以使用同一个 Port 号了。
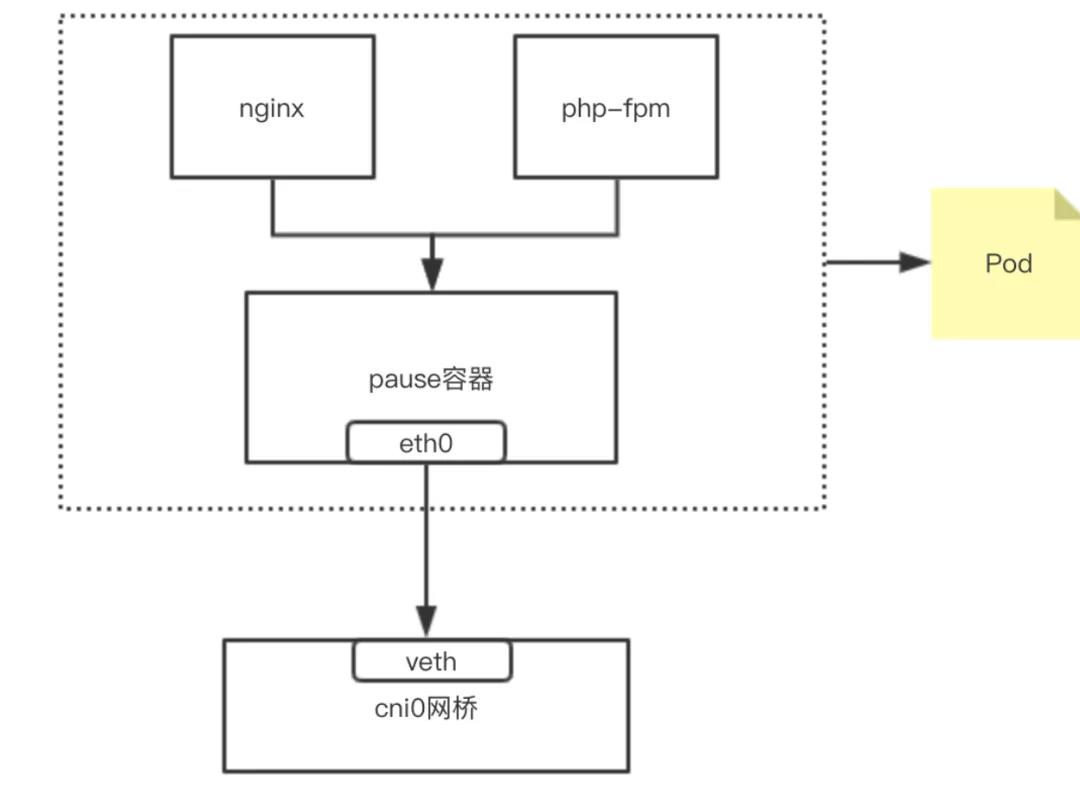
实现原理:同一个 Pod 内的 Containers 处于同一个 Network Namespace,因此使用了相同的 IP 地址和 Port 区间。该 Namespace 是由一个名为 Pause Container 实现的,每当一个 Pod 被创建,首先会创建一个 Pause Container。
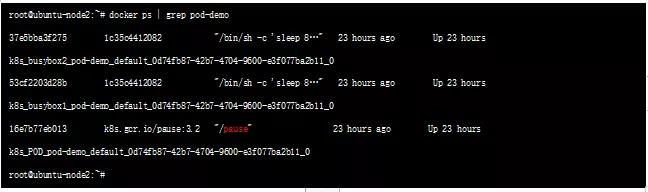
后续所有新的普通 Containers 都通过过共享 Pause Container 的网络栈,实现与外部 Pod 进行通信。因此,对于同 Pod 下属的 Containers 而言,它们看到的网络视图是一样的。上述我们在 Container 中看的 IP 地址,实际就是 Pause Container 的 IP 地址,通过控制 Pause Container 的网络协议栈就可以影响所有同属 Pod 下的 Container 的网络协议栈了。
这种新创建的容器和已经存在的一个容器(Pause)共享一个 Network Namespace(而不是和宿主机共享)的模式,就是常说的 Container 模式。
同 Node 内部的 Pods 间的通信(Host Virtual Network 模式)
每个 Node 上的每个 Pod 都有自己专属的 Network Namespace,由此实现 Container 模型网络的隔离。而两个 Pod 之间,即:两个 Network Namespace 之间希望进行通信的话,就需要使用到 Linux 操作系统的网络虚拟化技术 —— Veth Pair(虚拟网线)了。
但是,如果有多个 Pod 都需要两两建立 Veth Pair 的话,扩展性就会非常的差,假如:有 N 个 Pod,就需要创建 n(n-1)/2 个 Veth Pair。可见,除了 Veth Pair(虚拟网线)之外,我们还需要一个二层的 “集线” 设备 —— Linux Bridge(虚拟交换机)。
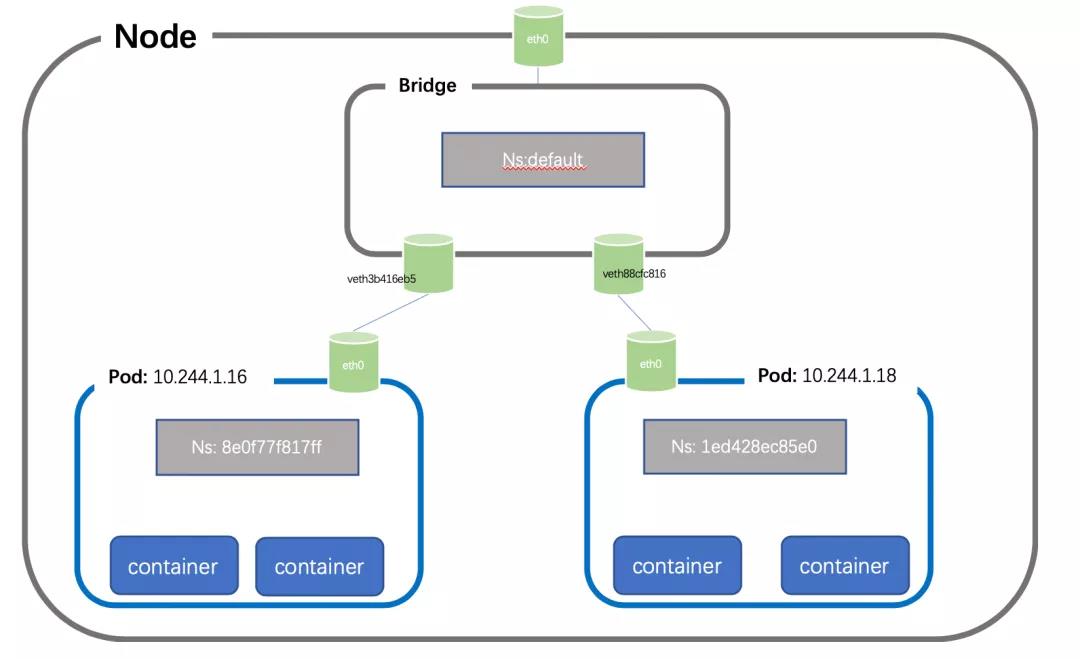
举个例子:创建位于同一个 Node 下属的 Pod1 和 Pod2,IP 地址分别为:10.244.1.16、10.244.1.18。

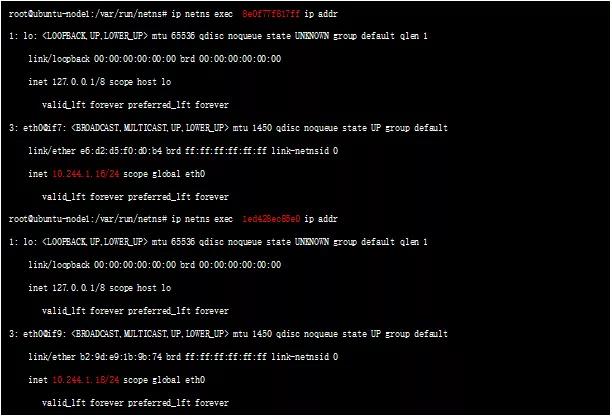
查看 Node 下的 Network Namespace:


分别查询两个 Network Namespace 下的 Network Interfaces:
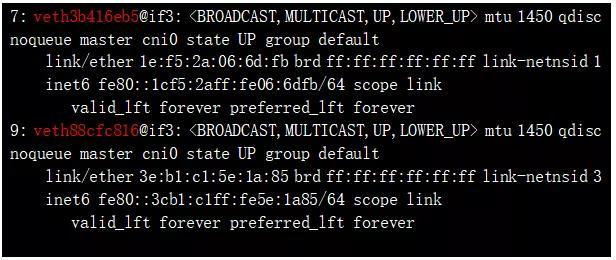
可见,Pod1、Pod2 内部的 Veth Pair 的一端分别是 3: eth0@if7、3: eth0@if9;另一端则位于 default Network Namespace,分别为 7: veth3b416eb2@if3、9: veth88cfc816@if3。注意:interface ID 和 ifID 刚刚好是两端对称的,以此来进行辨识。当然了,Bridge 也同样存在于 default Network Namespace。
这种借助于 Linux 操作系统原生的网络虚拟化技术实现的两个本地 Pods 之间的网络通信方式,称为 Host Virtual Network 模式。
跨 Nodes 间的 Pods 间的通信(SDN 模式)
总的来说,跨主机通信无非两种方式:
- Overlay 隧道互通:Nodes 之间通过 Over the Physical 网络互通,e.g. OvS、Flannel 和 Weave。
- Underlay 直接互通:Nodes 之间通过物理网络互通,e.g. Calico 的 Direct 模式、macvlan。
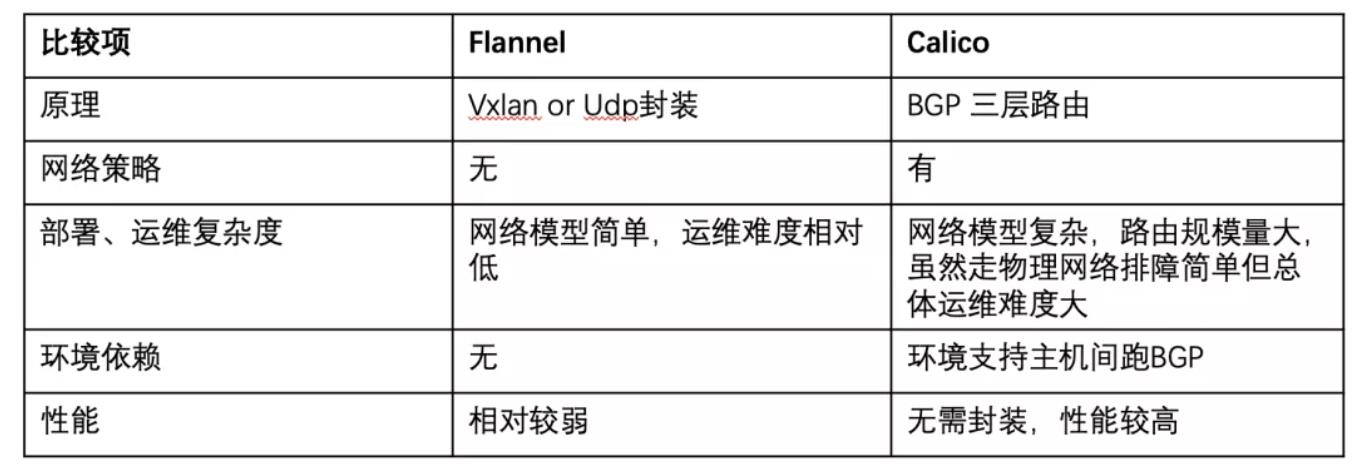
从网络角度对 Flannel 和 Calico 进行简单对比。可见,对性能敏感、策略需求较高时偏向于 Calico 方案。否则,采用 Flannel 会是更好的选择;
Service 的 Cluster IP 和外部网络间的通信
Service 之于集群内部 Pods 之间的通信
Pod 间可以直接通过 IP 地址通信,但前提是 Pod 知道对方的 IP。在 Kubernetes Cluster 中,Pod 可能会频繁地销毁和创建,也就是说 Pod 的 IP 不是固定的。为了解决这个问题,Kubernetes Service 作为访问 Pod 的上层抽象。无论后端的 Pod 如何变化,Service 都作为稳定的前端对外提供服务。同时,Service 还提供了高可用和负载均衡功能,负责将请求转发给正确的 Pod。
Service 之于集群外部与 Pod 的通信
无论是 Pod IP 还是 Service 的 Cluster IP,它们都是只能在 Kubernetes Cluster 内部可见的私有 IP 地址。Kubernetes 提供了两种方式可以让外部网络访问 Service 的 Cluster IP,继而与 Pod 进行通信:
-
NodePort:Service 通过 Node 的静态端口对外提供服务,外部网络可以通过 NodeIP:NodePort 访问 Service,根据不同的 NodePort 可以访问不同的 Service。
-
LoadBalancer:Service 利用自建的负载均衡器(反向代理)将流量导向 Service,例如:nginx、OpenStack Octavia、Cloud Provider(GCP、AWS、 Azure)等。
CNI
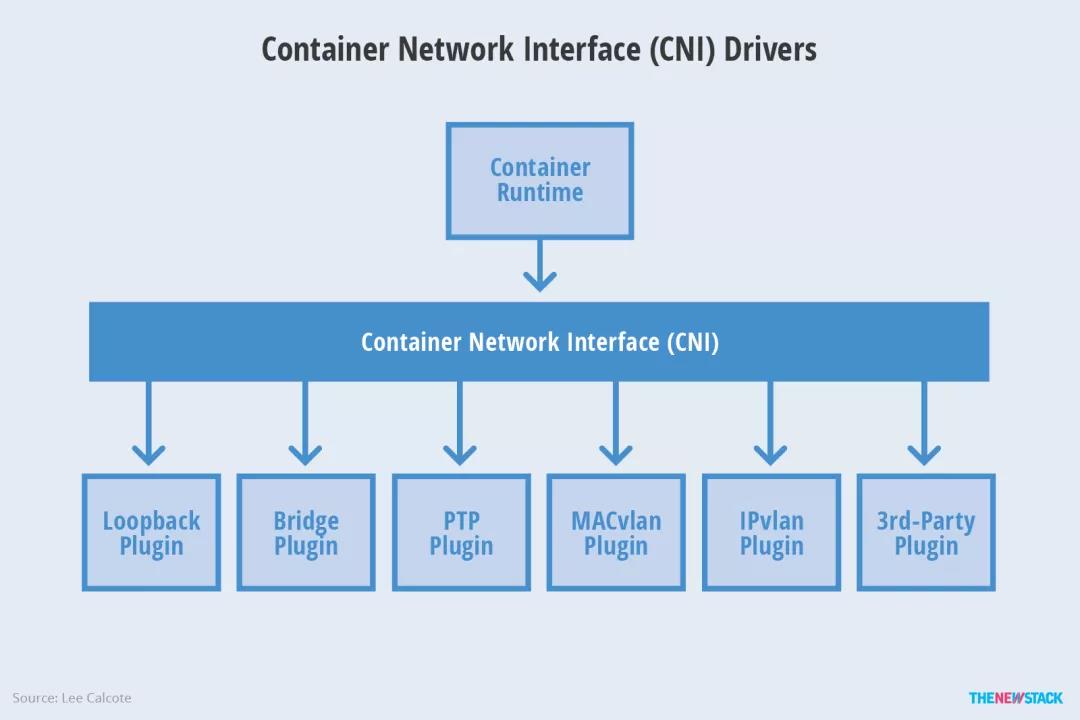
CNI(Container Network Interface,容器网络的 API 接口),是 Google 和 CoreOS 联合定制的网络标准,它是在 RKT 网络提议的基础上发展起来的,综合考虑了灵活性、扩展性、IP 分配、多网卡等因素。Kubernetes 网络的发展方向是希望通过插件的方式来集成不同的网络方案, CNI 就是这一努力的结果。
CNI 旨在为容器平台提供网络的标准化,为解决容器网络连接和容器销毁时的资源释放,提供了一套框架。所以 CNI 可以支持大量不同的网络模式,并且容易实现。不同的容器平台(e.g. Kubernetes、Mesos 和 RKT)能够通过相同的接口调用不同的网络组件。
CNI 规范重要的几点:
- CNI 插件负责连接容器(Linux network namespace)
- CNI 的网络定义以 JSON 的格式存储。
- 有关网络的配置通过 STDIN 的方式传递给 CNI 插件,其他的参数通过环境变量的方式传递。
- CNI 插件是以可执行文件的方式实现的。
CNI 定义了两个组件,具体的事情都是插件来实现的,包括:创建容器网络空间(network namespace)、把网络接口(interface)放到对应的网络空间、给网络接口分配 IP 等。
- 容器管理系统。
- 网络插件。
CNI 插件通常有 3 种实现模式:
- Overlay:靠隧道打通,不依赖底层网络;
- Underlay:靠底层网络打通,强依赖底层网络;
- 路由:靠路由打通,部分依赖底层网络;
常见的 CNI 网络插件方案有:
-
Calico(性能好、灵活性最强,目前的企业级主流):是一个基于 BGP 路由协议的纯 L3 的数据中心网络方案(不需要 Overlay),提供简单,可扩展的网络。除了可扩展的网络, Calico 还提供策略隔离。
-
Flannel(最成熟、最简单的选择):基于 Linux TUN/TAP,使用 UDP 封装 IP 数据包的方式来创建 Overlay 网络,并借助 etcd 来维护网络资源的分配情况,是一种简单易用的 Overlay 网络方案。
-
Weave Net:支持多主机容器网络,可以跨越不同的云网络配置。独有的功能,是对整个网络的简单加密,会增加网络开销。
-
Cilium:是一个开源软件,基于 Linux Kernel BPF 技术,可以在 Linux Kernel 内部动态地插入具有安全性、可见性的网络控制逻辑。
-
kopeio-networking:是专为 Kubernetes 而设计的网络方案,充分利用了 Kubernetes API,因此更简单,更可靠。
-
kube-router:也是专为 Kubernetes 打造的专用网络解决方案,旨在提供操作简单性和性能。


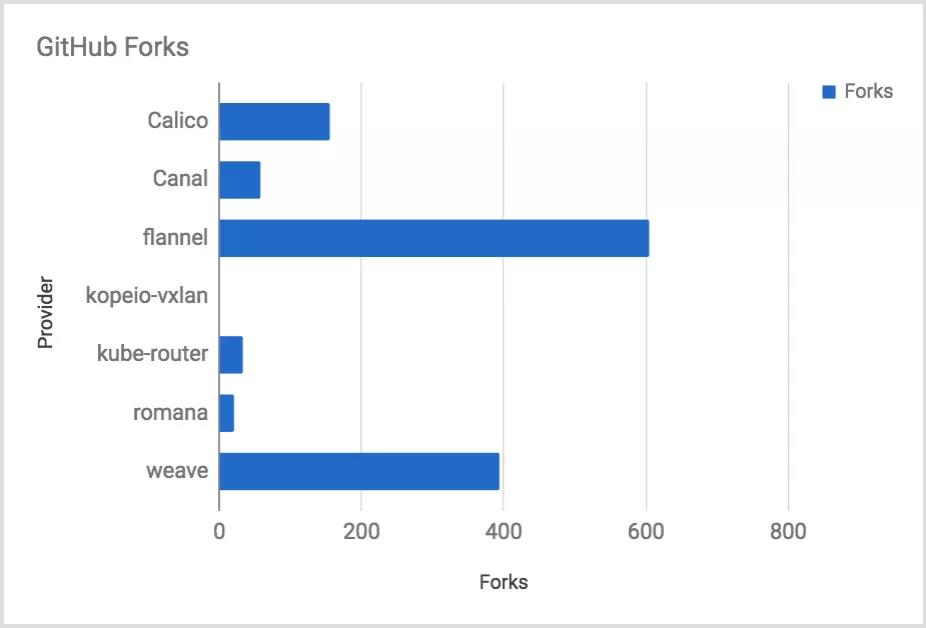
CNI 插件项目 Forks 数量比较:
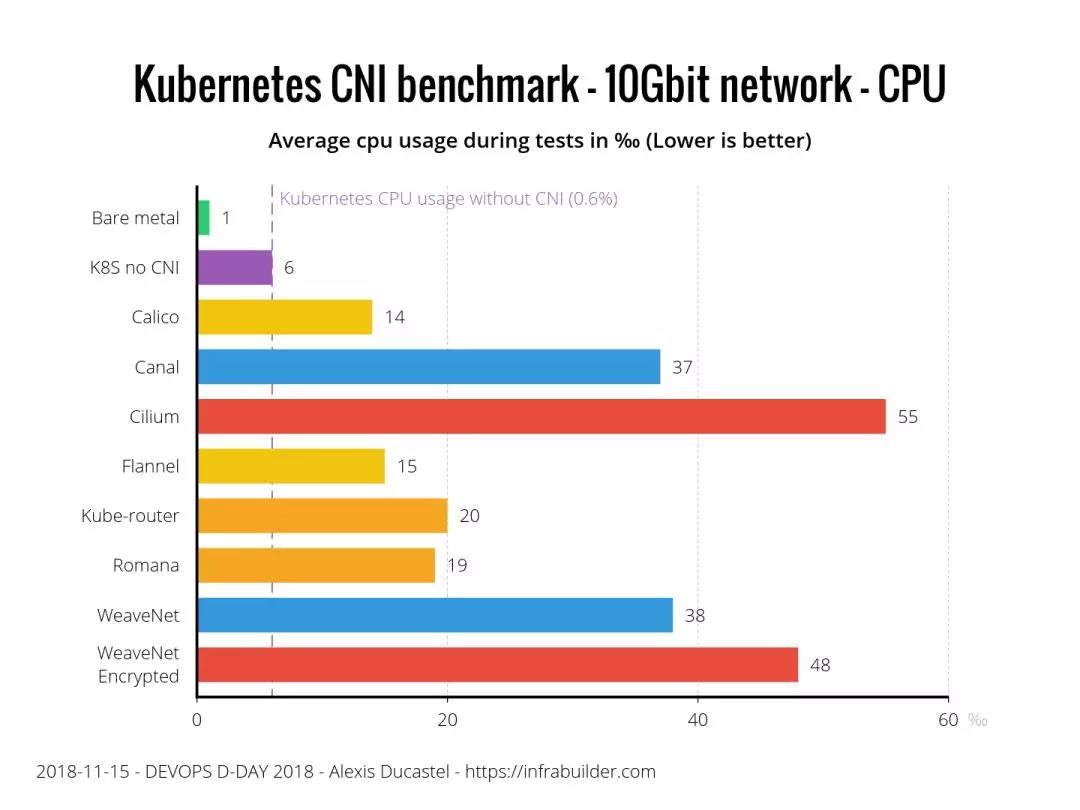
CNI 插件项目 10Gbit 网络下的 CPU 消耗比较:
CNI 的使用示例
使用 Bridge Plugin 作为示例。
- 下载源码:
cd cni/
curl -O -L https://github.com/containernetworking/cni/releases/download/v0.4.0/cni-amd64-v0.4.0.tgz
tar -xzvf cni-amd64-v0.4.0.tgz
- 创建 Network Namespace:
ip netns add 1234567890
- 新增 CNI Bridge Plugin 的配置文件:
cat > mybridge.conf <<"EOF"
"cniVersion": "0.2.0", # CNI 规范的版本
"name": "mybridge", # 网络的名字
"type": "bridge", # 使用 CNI 的 Bridge Plugin
"bridge": "cni_bridge0",
"isGateway": true, # 如果是 true,为网桥分配 IP 地址,以便连接到它的容器可以将其作为网关。
"ipMasq": true, # 在插件支持的情况下,设置 IP 伪装。
"hairpinMode":true, # 让网络设备能够让数据包从一个端口发进来一个端口发出去。
"ipam":
"type": "host-local", # IPAM 可执行文件的名字。
"subnet": "10.15.20.0/24", # 要分配给容器的子网。
"routes": [ # 子网路由。
"dst": "0.0.0.0/0" ,
"dst": "1.1.1.1/32", "gw":"10.15.20.1"
]
EOF
- 将 Pod Network 加入到 Network Namespace 中:
$ cd cni
$ CNI_COMMAND=ADD
$ CNI_CONTAINERID=1234567890
$ CNI_NETNS=/var/run/netns/1234567890
$ CNI_IFNAME=eth12
$ CNI_PATH=`pwd`
$ .cni/bin/bridge < mybridge.conf
2020/03/02 22:14:57 Error retriving last reserved ip: Failed to retrieve last reserved ip: open /var/lib/cni/networks/mybridge/last_reserved_ip: no such file or directory
"ip4":
"ip": "10.15.20.2/24",
"gateway": "10.15.20.1",
"routes": [
"dst": "0.0.0.0/0"
,
"dst": "1.1.1.1/32",
"gw": "10.15.20.1"
]
,
"dns":
- 查看 Network Namespace 的网络配置:
$ ip netns exec 1234567890 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: eth12@if1137099: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 0a:58:0a:0f:14:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.15.20.2/24 scope global eth12
valid_lft forever preferred_lft forever
inet6 fe80::34da:9fff:febe:f332/64 scope link
valid_lft forever preferred_lft forever
$ ip netns exec 1234567890 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.15.20.1 0.0.0.0 UG 0 0 0 eth12
1.1.1.1 10.15.20.1 255.255.255.255 UGH 0 0 0 eth12
10.15.20.0 0.0.0.0 255.255.255.0 U 0 0 0 eth12
$ ip netns exec 1234567890 ifconfig
eth12: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.15.20.2 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::34da:9fff:febe:f332 prefixlen 64 scopeid 0x20<link>
ether 0a:58:0a:0f:14:02 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 9 bytes 738 (738.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Flannel CNI
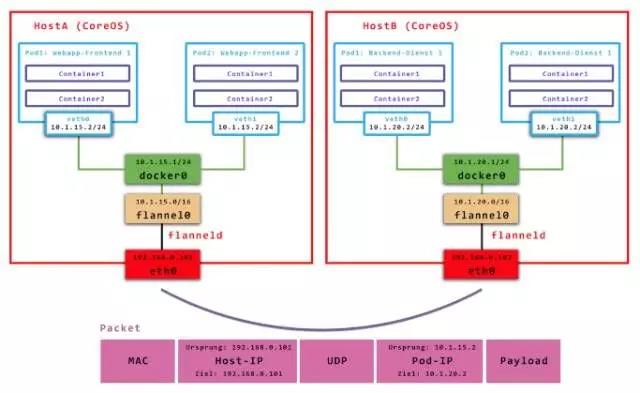
Flannel 是 Kubernetes 最成熟、最简单的 CNI,由 CoreOS 推出用于解决容器集群跨主机通讯的 Overlay 网络解决方案。也就是将 TCP 数据包装在另一种网络包里面进行路由转发和通信,目前已支持 UDP、VXLAN、AWS VPC、GCE 路由等数据转发方式,其中以 VXLAN 技术最为流行,很多数据中心在考虑引入容器时,也考虑将网络切换到 Flannel 的 VXLAN 网络中来。
Flannel 为每个主机分配一个 Subnet,容器从此 Subnet 中分配 IP,这些 IP 可在主机间路由,容器间无需 NAT 和端口映射就可以跨主机通讯。Flannel 让集群中不同节点主机创建容器时都具有全集群唯一虚拟 IP 地址,并连通主机节点网络。Flannel 可为集群中所有节点重新规划 IP 地址使用规则,从而使得不同节点上的容器能够获得 “同属一个内网” 且 “不重复的” 的 IP 地址,让不同节点上的容器能够直接通过内网 IP 通信,网络封装部分对容器是不可见的。源主机服务将原本数据内容 UDP 封装后根据自己的路由表投递给目的节点,数据到达以后被解包,然后直接进入目的节点虚拟网卡,然后直接达到目的主机容器虚拟网卡,实现网络通信目的。
Flannel 虽然对网络要求较高,要引入封装技术,转发效率也受到影响,但是却可以平滑过渡到 SDN 网络,VXLAN 技术可以和 SDN 很好地结合起来,值得整个网络实现自动化部署,智能化运维和管理,较适合于新建数据中心网络部署。
Flannel 支持通过 Backend 来选择 L3 Overlay 类型。例如:
"Network": "10.0.0.0/8",
"SubnetLen": 20,
"SubnetMin": "10.10.0.0",
"SubnetMax": "10.99.0.0",
"Backend":
"Type": "udp",
"Port": 7890
Flannel 支持以下类型的 Backend:
-
UDP 模式(性能损失:30%,不建议使用):使用设备 flannel.0 进行封包解包,由于不是 Kernel 原生支持,所以需要频繁地内核态/用户态间切换,性能非常差。默认使用 8285 端口。
-
VxLAN 模式(性能损失:20%):使用 flannel.1 进行封装/解封装,Kernel 原生支持,性能较强。默认使用 8472 端口。要求同一个 Node 下各个 Pods 属于同一个 Subnet,不同 Nodes 下的 Pods 属于不同的 Subnets。
-
host-gw 模式(性能损失:10%):无需 flannel.1 这样的中间设备,直接把 Node 当作 Subnet 的下一跳地址,性能最强。但要求不同的 Nodes 需要处于同一网段,因此不支持跨网络,不适合大规模部署。
-
AWS VPC 模式:使用 Amazon VPC route table 创建路由,适用于 AWS 上运行的容器。
-
GCE 模式:使用 Google Compute Engine Network 创建路由,所有 Instances 需要开启 IP forwarding,适用于 GCE 上运行的容器。
-
ALI VPC 模式:使用阿里云 VPC route table 创建路由,适用于阿里云上运行的容器。
Kubernetes 集成 Flannel CNI
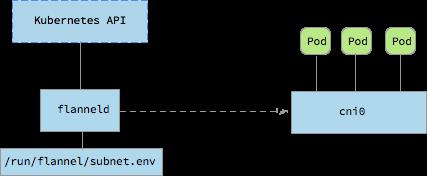
Flannel CNI 会将 Flannel 网络配置转换为 Linux Bridge(cniX/dockerX)网络配置,并调用 Bridge 给容器的 Network Namespace 配置网络。例如:
- Flannel 网络配置:
"name": "mynet",
"type": "flannel",
"delegate":
"bridge": "mynet0",
"mtu": 1400
- Linux Bridge(cniX/dockerX)网络配置:
"name": "mynet",
"type": "bridge",
"mtu": 1472,
"ipMasq": false,
"isGateway": true,
"ipam":
"type": "host-local",
"subnet": "10.1.17.0/24"
安装 Flannel CNI:
kube-controller-manager --allocate-node-cidrs=true --cluster-cidr=10.244.0.0/16。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
安装完毕后,会启动 flanneld Daemon,并配置 CNI 网络插件:
$ ps -ef | grep flannel | grep -v grep
root 8632 8611 0 6月16 ? 00:01:55 /opt/bin/flanneld --ip-masq --kube-subnet-mgr
$ cat /etc/cni/net.d/10-flannel.conf
"name": "cbr0",
"type": "flannel",
"delegate":
"isDefaultGateway": true
flanneld Daemon 启动后会自动连接 Kubernetes API,根据 node.Spec.PodCIDR 配置本地的 Flannel Subnet,并为容器创建 VxLAN 设备以及相关的子网路由。
$ cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1410
FLANNEL_IPMASQ=true
$ ip -d link show flannel.1
12: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1410 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 8e:5a:0d:07:0f:0d brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 local 10.146.0.2 dev ens4 srcport 0 0 dstport 8472 nolearning ageing 300 udpcsum addrgenmode eui64
UDP 模式
网络模型

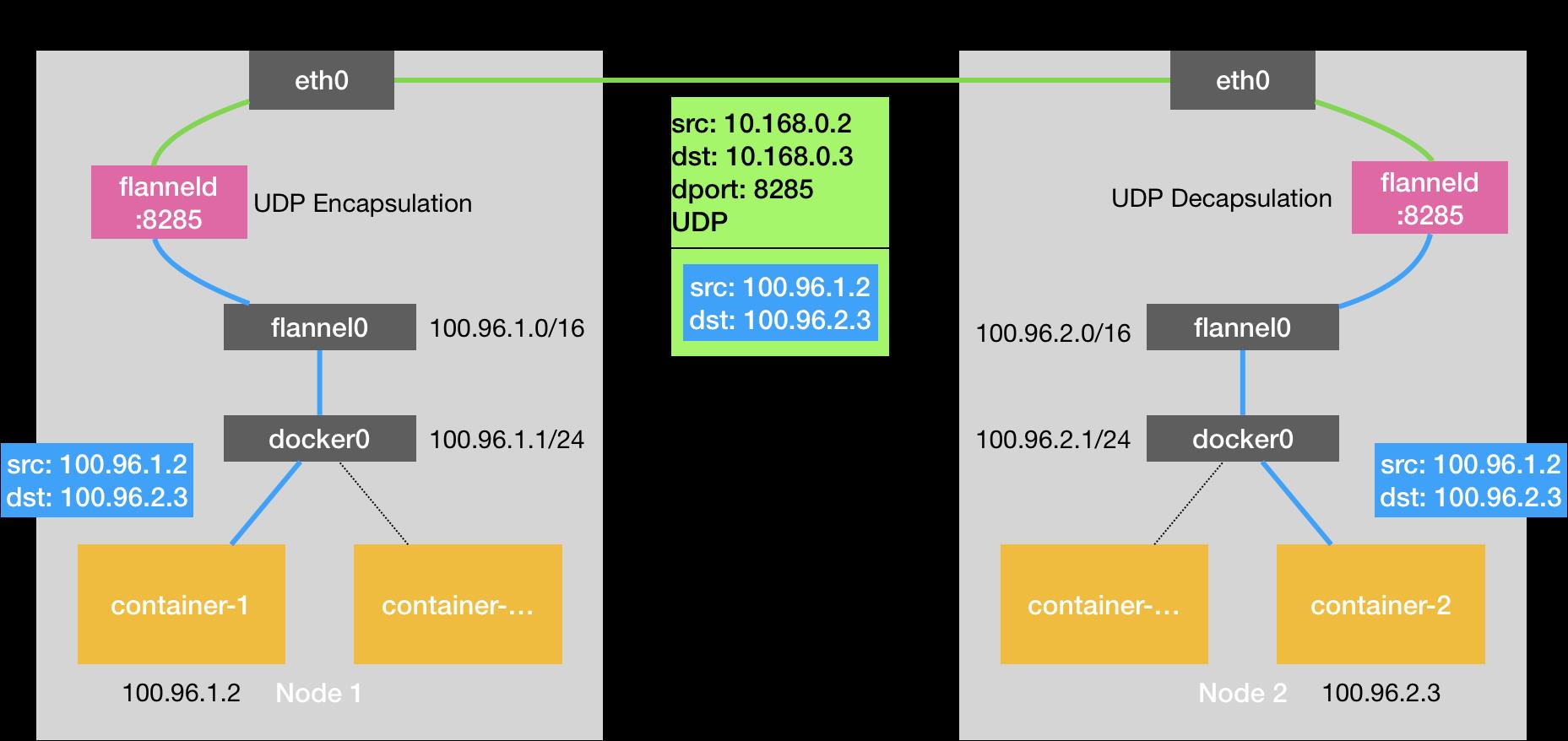
UDP 模式的核心就是通过 Linux TUN 设备 flannel0 来实现。TUN 设备是工作在三层的虚拟网络设备,功能是:在 Kernel 和用户态应用程序之间传递 IP 报文。由于,TUN 设备,仅在发出 IP 报文的过程中都需要经过多次的用户态到内核态的数据拷贝,所以性能非常差。
转发流程
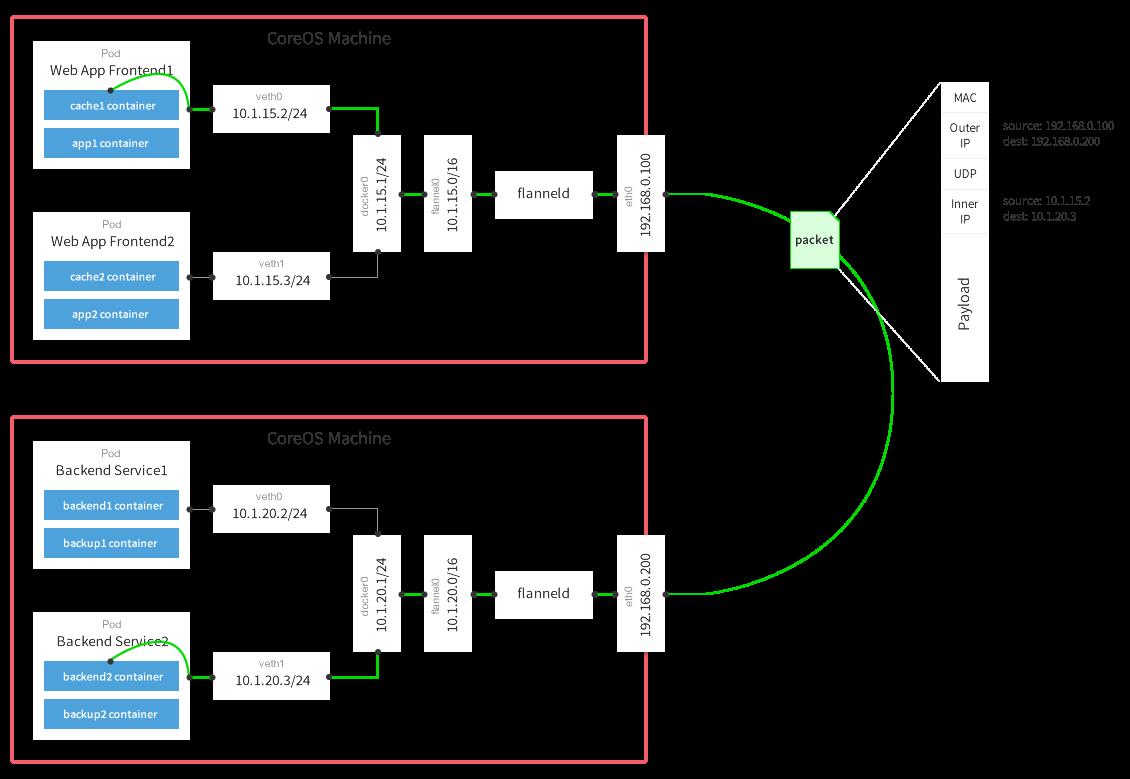
- 源容器向目标容器发送数据,数据首先发送给 docker0 网桥,查看源容器的路由表:
$ kubectl exec -it -p Podid -c ContainerId -- ip route
- docker0 网桥接受到数据后,docker0 的内核协议栈处理程序会读取这个数据包的目标地址,根据目标地址将数据包发送给下一个路由节点。docker0 首先将报文转交给 flannel.1 虚拟网卡处理。查看源容器 Local Node 的路由信息:
$ ip route
- flannel.1 接受到数据后,对数据进行封装,并发给 Local Node 的 eth0。
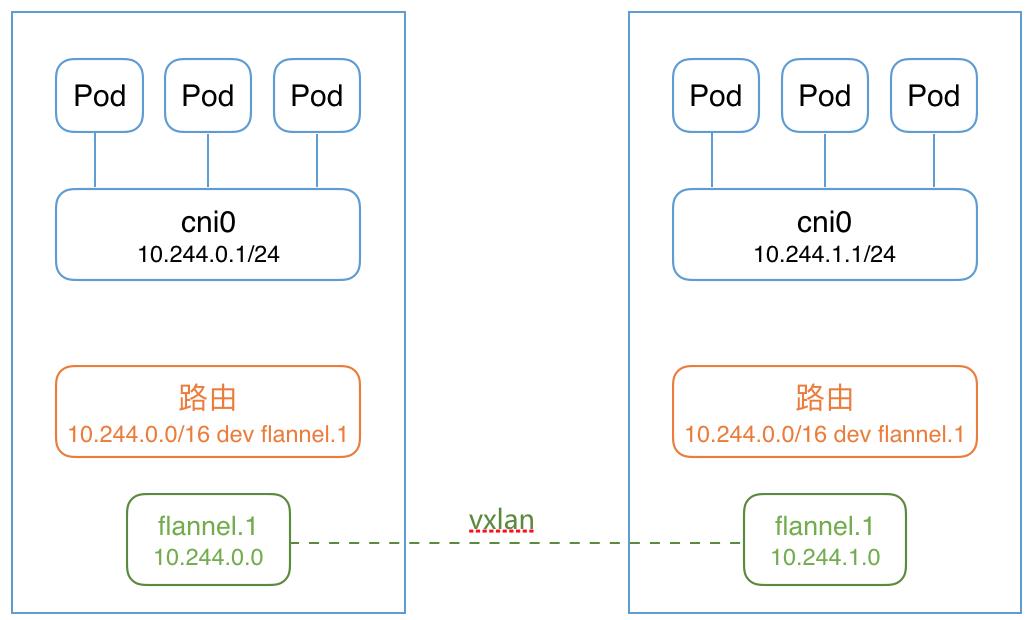
VxLAN 模式
网络模型
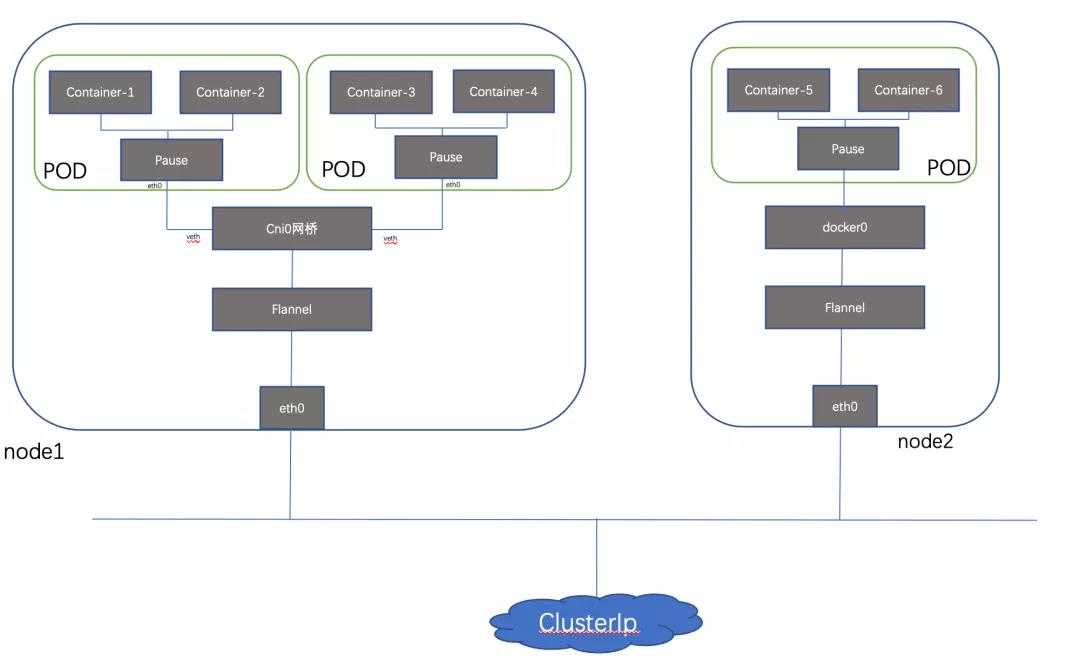
- flanneld Deamon:在每个 Node 中运行的 Agent 守护进程。它会为 Local Node 从 Cluster 的网络地址空间中获取一个 Subnet 网段。之后 Local Node 内所有 Pods 和 cni0/docker0 的 IP Address 都会将这个 Subnet 中分配。同时,flanneld 会监听 ETCD,为 flannel.1 提供 Overlay 报文封装时必要的 IP/MAC 等网络配置信息。
$ ps -ef | grep flanneld
...
root 8632 8611 0 13:53 ? 00:00:39 /opt/bin/flanneld --ip-masq --kube-subnet-mgr
- cni0(Bridge 设备):由 flanneld 初始化创建。并且每创建一个 Pod,flanneld 都会创建一对 vEth Pair,其中一端是 Pod 中的 eth0,另一端则接入到 cni0 中。Pod 从 eth0 发出的流量都会发送到 cni0 上。
$ ethtool -i cni0
driver: bridge
version: 2.3
firmware-version: N/A
expansion-rom-version:
bus-info: N/A
supports-statistics: no
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
- flannel.1(VxLAN VTEP 设备):由 flanneld 初始化创建,并分配了 IP/MAC 地址,以及 VNI 1(默认),所以命名为 flannel.1。用于接受来自 cniX/dockerX Bridge 的数据,并完成 VxLAN 报文的封装/解封装。每个 Node 都会有一个 flannel.1 设备,不通 Node 间的 flannel.1 互相作为 VxLAN Tunnel 的 Endpoint。通过维护路由表,对接收到的数据进行转发。
$ ethtool -i flannel.1
driver: vxlan
version: 0.1
firmware-version:
expansion-rom-version:
bus-info:
supports-statistics: no
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
分配 IP 地址
flanneld Daemon 第一次启动时,会从 ETCD 获取 Cluster 配置的网段信息,为 Local Node 分配一个未使用的 Subnet 网段。flanneld 将分配给 Local Node 的 Subnet 网段信息写入 /run/flannel/subnet.env 文件。
$ cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.233.64.0/18
FLANNEL_SUBNET=10.233.64.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
cni0 Bridge 会根据 subnet.env Setup 的 ENV 来设置 IP 地址,作为 Subnet Gateway:
8: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether 52:7e:47:3a:c3:7e brd ff:ff:ff:ff:ff:ff
inet 10.233.64.1/24 brd 10.233.64.255 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::507e:47ff:fe3a:c37e/64 scope link
valid_lft forever preferred_lft forever
Local Node 上所有 Pods 的 IP 地址都从这个 Subnet IP Pool 分配,例如:
$ kubectl get pod -o wide | grep kube-cluster-1
...
fluentd-46vts 1/1 Running 2 36h 10.233.64.132 kube-cluster-1 <none> <none>
harbor-harbor-core-69fd799fd4-5b7z8 1/1 Running 7 31h 10.233.64.106 kube-cluster-1 <none> <none>
下发路由规则
flanneld Daemon 第一次启动时还会创建 flannel.1 VxLAN 隧道设备,并且 flanneld 还用于创建 Linux Kernel 的路由表。
- Local Node 内的 Pods 通信时,路由出口为 cni0。
$ route -ne
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
...
10.233.64.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
- 跨 Nodes 间的 Pods 通信时,路由出口为 flannel.1:其中 Destination 10.244.2.0 为 node2 的目的网段,出口为 flannel.1 完成 Overlay 隧道的封装/解封装。
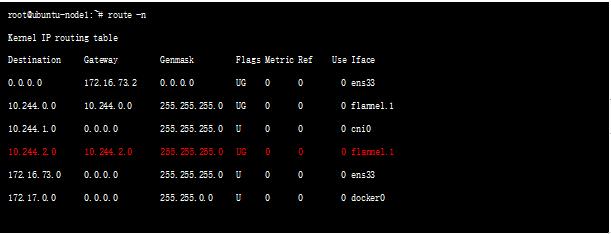
flanneld Daemon 从 ETCD 中获取到 Overlay 隧道封装的 MAC、IP、Tunnel ID 等网络配置信息。
例如:SourceIP 采用 Local Node IP,DestIP 采用 Remote Node IP,VxLAN 外层的 DestPort 为 UDP Port 8472。隧道的对端只需要监听这个 Port 即可,当该 Port 收到报文后将报文送到 flanned.1 进行解封装,得到原始报文后查询本地路由表,就可以找到 DestIP 的 Interface 为 cni0 了。
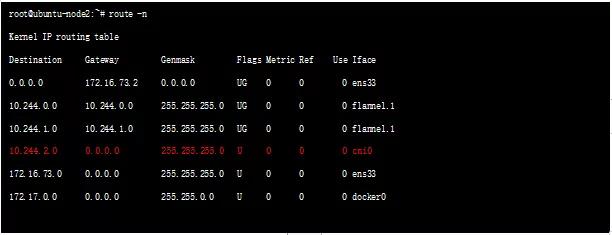
转发流程
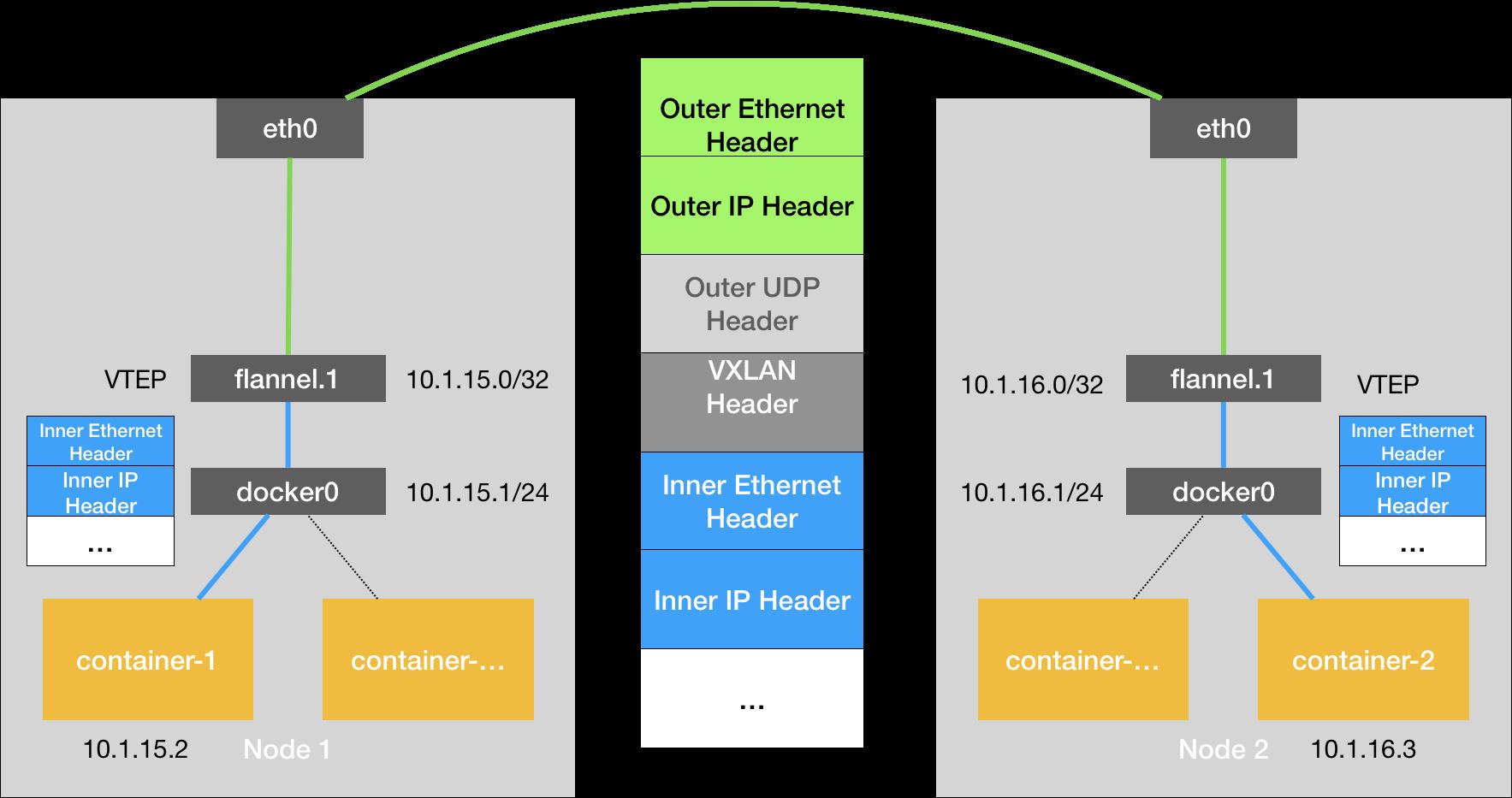
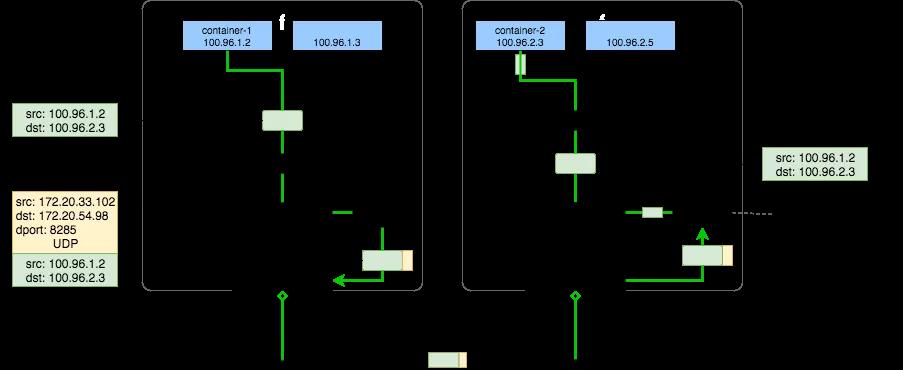
VxLAN 模式中,要求同一个 Node 下各个 Pods 属于同一个 Subnet,不同 Nodes 下的 Pods 属于不同的 Subnets。Subnet 与 Node 的对应关系储存在 ETCD 中,例如:Node1 Subnet 是 100.96.1.0/24,Pod1 是 100.96.1.2。
转发流程:
- 当 flanneld Daemon 处理从 Pod 传入到 flannel1 的 IP 报文时,就可以根据 dstIP(e.g. 100.96.2.3)匹配到对应的 Subnet(e.g. 100.96.2.0/24),然后从 ETCD 中找到这个 Subnet 对应的 Node IP(e.g. 10.168.0.3)。
- flanneld Daemon 在收到 container-1 给 container-2 的 IP 报文后,把这个报文直接封装在 VxLAN 报文里,发送给 Node2。
- 每个 Node 的 flanneld Deamon 都监听着 UDP 8285 端口,所以 flanneld 只要把 UDP 发给 Node2 的 8285 端口就行了。
- 最后,Node2 的 flanneld Deamon 再把 IP 报文发送给 flannel1,flannel1 再转发给 container-2。
报文协议栈:

host-gw 模式
host-gw(host gateway)是一种纯三层的网络方案,性能最高,即:Node 把自己的 Physical Interface 当做 Pods 的 Gateway 来使用,从而使跨 Nodes 上的 Pods 进行通信,这个性能比 VxLAN 高,因为它没有额外开销。不过他有个缺点,就是所有 Nodes 的 Physical Network 必须在同一个 LAN 中。

howt-gw 模式的工作原理,就是将每个 Flannel Subnet 的下一跳,设置成了该 Subnet 对应的 Node 的 IP 地址。即:Node 充当了这条容器通信路径的 Gateway,这正是 host-gw 的含义。
所有的 Subnet 和 Node 的关系信息,都保存在了 ETCD 中,flanneld Daemon 只需要 Watch 这些数据的变化,并实时更新路由表就行了。核心是 IP 报文在封装成二层数据桢的时候,使用路由表的 “下一跳” 设置上的 MAC 地址,这样可以经过二层网络到达 dst Node。
另外,如果两个 Pods 所在的不同 Nodes 处于在同一个 LAN 中,可以让 VxLAN 也支持 host-gw 的功能,即:直接通过物理网卡的网关路由转发,而不再使用隧道,从而提高了 VxLAN 的性能,这种 Flannel 的功能叫 directrouting。
Calico
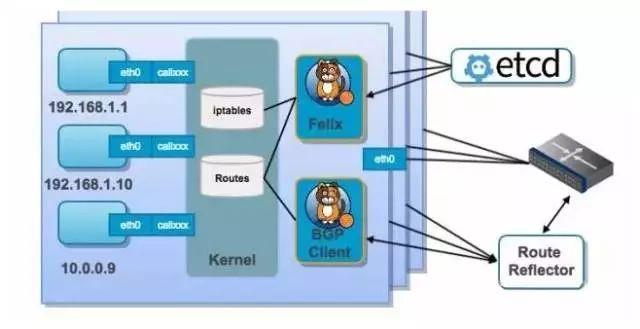
Callico 容器网络和其他虚拟网络最大的不同是:支持纯三层网络模型。三层通信模型表示每个容器都通过 IP 直接通信,要想路由工作能够正常,每个容器所在的主机节点必须有某种方法知道整个集群的路由信息,Callico 采用 BGP 路由协议,使得全网所有的 Node 和网络设备都记录到全网路由。
然而这种方式会产生很多的无效路由,对网络设备路由规格要求较大,整网不能有路由规格低的设备。另外,Callico 实现了从源容器经过源宿主机,经过数据中心路由,然后到达目的宿主机,最后分配到目的容器,整个过程中始终都是根据 BGP 协议进行路由转发,并没有进行封包,解包过程,这样转发效率就会快得多,这是 Callico 容器网络的技术优势。
Calico 的网络架构
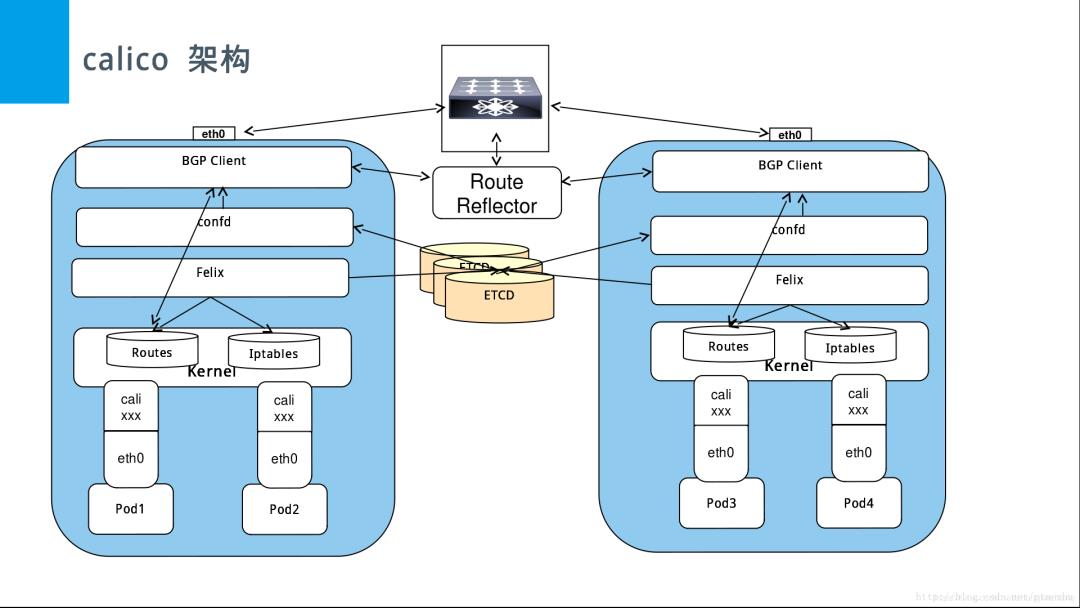
-
Felix(Calico Agent):运行在每个 Node 上的 Agent Daemon,为 Node 中的 Containers 配置网络信息。例如:IP 地址、路由规则、ACL 规则、iptables 规则等。
-
Bird(BGP Client):运行在每个 Node 上的 BGP Client。负责把 Felix 写入 Kernel 的 BGP 路由信息分发到整个 Calico 网络,确保 Node 间的通信的有效性;Bird Daemon 会监听由 Felix 注入的路由信息,当 Felix 将路由信息写入 Kernel TCP/IP Stack 的 L3 FIB 时,BGP Client 将通过 BGP 协议广播告诉其他 Nodes 完成 BGP 路由规则的收敛,从而实现网络互通。
-
BGP Route Reflector:大规模部署时使用,通过一个或者多个 BGP Route Reflector 来完成集中式的路由分发,可以自建 RR,也可以使用物理网络中的 RR。注意:如果大型网络中仅使用 BGP client 的全互联模式(node-to-node mesh)会导致规模限制,所有 BGP 节点总共需要维护 N^2 个连接。
-
Confd:监听 etcd 中的 BGP 配置和全局默认值的更改,例如:AS number、日志级别、IPAM 信息等。Confd 根据 etcd 中数据的更新动态生成 Bird 的配置文件,并且触发 Bird 重新加载新文件。
-
etcd:分布式键值存储,负责网络元数据的一致性,确保 Calico 网络状态的准确性;
-
calicoctl:命令行管理工具。
Calico 的网络模式
Underlay:
- Direct BGP 路由转发,跨 Node 的 Pods 之间使用 BGP 路由规则直接通信。
Overlay:
- IP-in-IP(Default)。
- VxLAN。
Direct BGP 路由模式
该模式下,Calico 在每个 Node 中,利用 Linux Kernel TCP/IP Stack 实现了一个高效的 BGP vRouter 来负责数据转发。小规模部署可以采用 BGP 全互联模式(node-to-node mesh),大规模部署可以采用 BGP 路由反射模式(Route Reflector)。
此外,Calico 基于 iptables 还提供了丰富而灵活的 Network Policy,保证通过各个 Node 上的 ACLs 来提供多租户隔离、安全组以及其他可达性限制等功能。
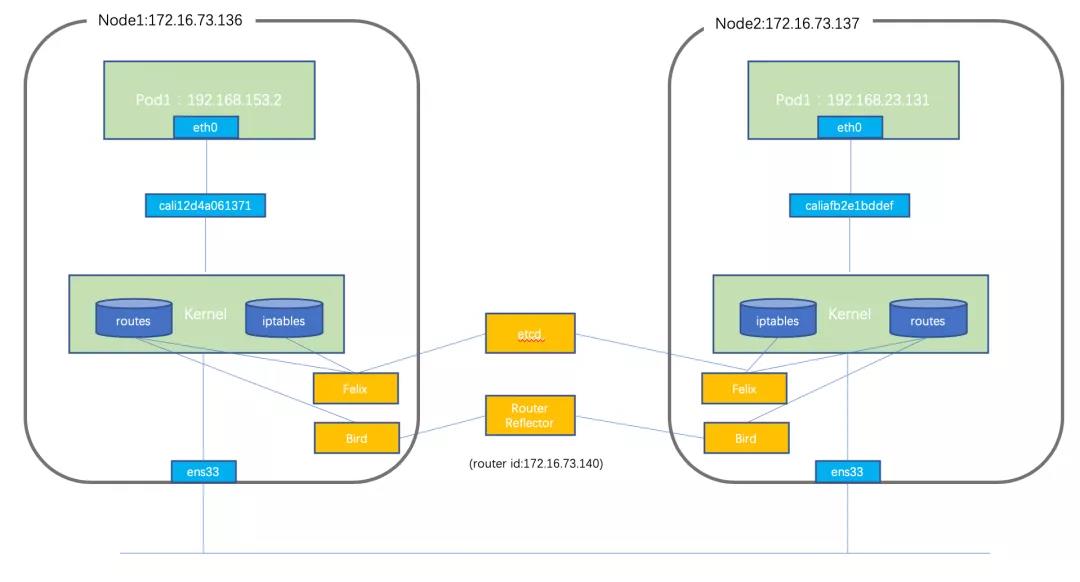
Nodes 之间通过 bird(BGP Client)和 RR(Route Reflector)来建立 BGP 邻居关系后,Node 再将本地的容器地址发送到 RR 从而反射到网络中的其它 Nodes 上。同样,其它 Nodes 的网络地址也会传送到本地,然后由 felix 进行管理并下发到 Host OS 的路由表中。
如此的,所有的 Nodes 和网络中间件都会收敛彼此的路由信息。当数据包先从 Veth Pair 的一端发出,到达 Node 上的以 Cali 为前缀的虚拟网卡上,也就到达了 Host 的内核网络协议栈。然后查询路由表直接通过 Underlay 转发。
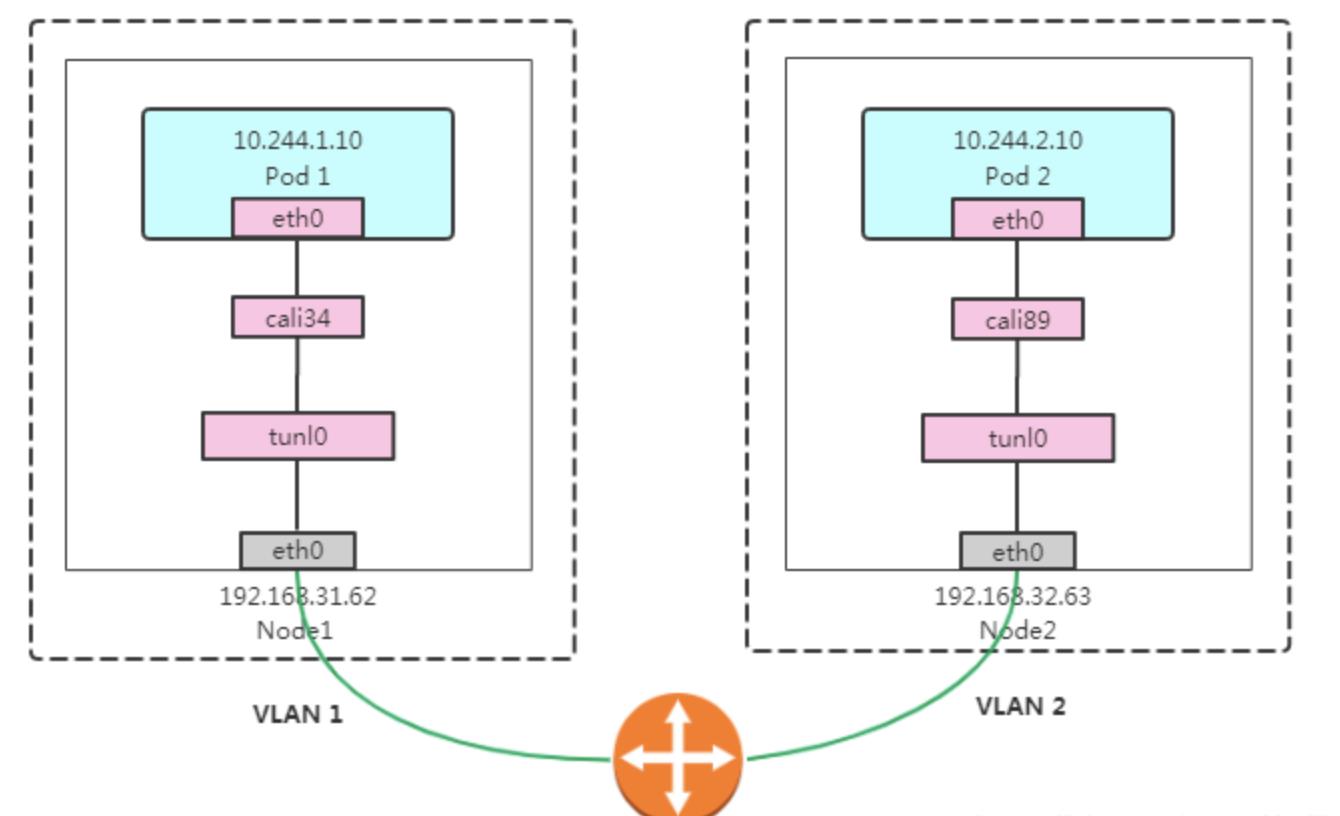
IPIP 模式
IP-in-IP 是 Linux Kernel 的一个 Tunnel Module,表现为一个 tunl0 设备,可以对 IP 数据包进行隧道封装与解封装。
MACVLAN
MACVLAN 是 Linux Kernel 比较新的特性,允许在主机的一个网络接口上配置多个虚拟的网络接口,这些网络 interface 有自己独立的 MAC 地址,也可以配置上 IP 地址进行通信。macvlan 下的虚拟机或者容器网络和主机在同一个网段中,共享同一个广播域。macvlan 和 bridge 比较相似,但因为它省去了 bridge 的存在,所以配置和调试起来比较简单,而且效率也相对高。除此之外,macvlan 自身也完美支持 VLAN。
使用 MACVLAN CNI
基于 Linux Kernel MACVLAN feature,将 VNI 子接口交给 Pod 使用,作为 Pod Network Namespace 的一个 Interface。
- 下载 CNI:https://github.com/containernetworking/plugins/releases
- 把 CNI 的 binary 放置到每个 Node 的 /opt/cni/bin/。
- 为每个 Node 配置 kubelet:
$ vi /etc/kubernetes/kubelet
...
KUBELET_ARGS="--network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin"
- MACVLAN CNI 的配置文件:
"name": "macvlannet",
"type": "macvlan",
"master": "ens33",
"mode": "vepa",
"isGateway": true,
"ipMasq": false,
"ipam":
"type": "host-local",
"subnet": "192.168.166.0/24",
"rangeStart": "192.168.166.21",
"rangeEnd": "192.168.166.29",
"gateway": "192.168.166.2",
"routes": [
"dst": "0.0.0.0/0"
]
HOST-DEVICE
host-device CNI 的作用就是把 Physical Network Interface 直接交给 Pod 使用。
实现很简单,做了 2 件事情:
- 收到 ADD 命令时,bin/host-device 根据命令参数,将网卡移入到指定的 Network Namespace。
- 收到 DEL 命令时,bin/host-device 根据命令参数,将网卡从指定的 Network Namespace 移出到 Root Namespace。
原理也比较简单,使用下述指令就可以做到,将 dev “移动” 到指定的 Network Namespace 中:
$ ip a
...
3: ens8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 52:54:00:5e:1f:f5 brd ff:ff:ff:ff:ff:ff
$ ip netns add test
$ ip link set dev ens8 netns test
$ ip netns exec test ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
3: ens8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 52:54:00:5e:1f:f5 brd ff:ff:ff:ff:ff:ff
使用 HOST-DEVICE CNI
- 新增 host-device CNI 的配置文件:
cat > myhost-device.conf <<"EOF"
"cniVersion": "0.3.1",
"type": "host-device",
"device": "ens8",
"name": "host"
EOF
- 使用 host-device CNI 将 host-device 加到 Network Namespace 中:
export CNI_COMMAND=ADD
export CNI_NETNS=/var/run/netns/test
export CNI_IFNAME=eth0
以上是关于Kubernetes 系列CNI 与网络流量模型的主要内容,如果未能解决你的问题,请参考以下文章
16.kubernetes笔记 CNI网络插件(二) Calico介绍
《Kubernetes网络权威指南》读书笔记 | 打通CNI与Kubernetes:Kubernetes网络驱动