日常爬虫学习进阶:百度翻译的秘密(2021版)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日常爬虫学习进阶:百度翻译的秘密(2021版)相关的知识,希望对你有一定的参考价值。
序言
许久不更,省身自愧。假期里事情没做成几件,跑些步也把膝盖搞得残废,年关将至,且以陋文一篇辞旧迎新。
近期想到可以积累一些双语语料以备后用,于是去尝试去一些在线翻译寻求资源,总结下来还是百度翻译的查询结果相对完全(相对于Google翻译和有道翻译),除了能提供相当数量的双语例句外,还有同义词辨析以及来自WordNet的完整词义列表。
-
以查询单词take为例:👇
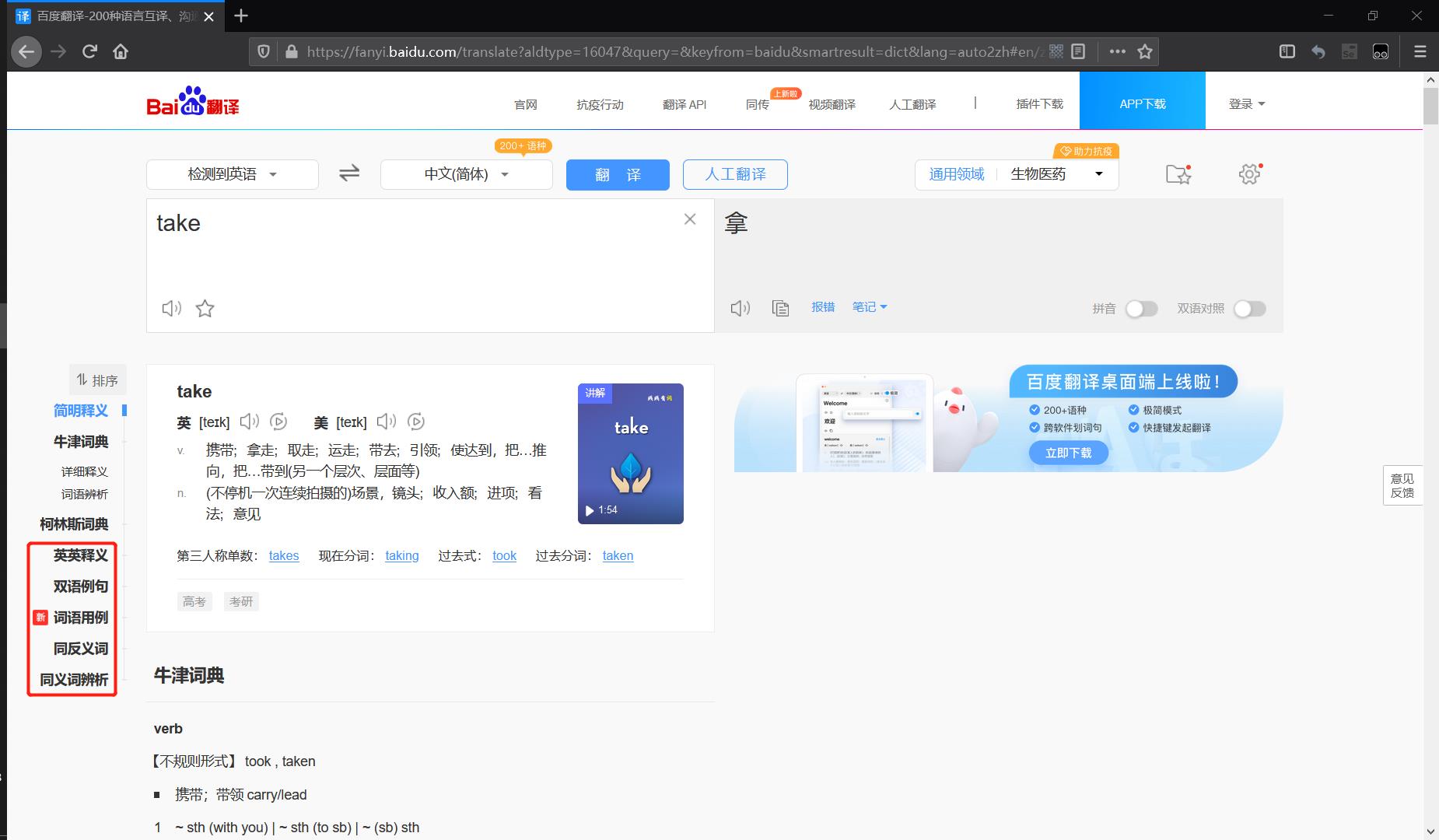
-
英英释义:一共42种不同的释义结果,可用于语义消歧任务,其数据来源于WordNet,也是语义消歧任务的常用外部知识源。👇
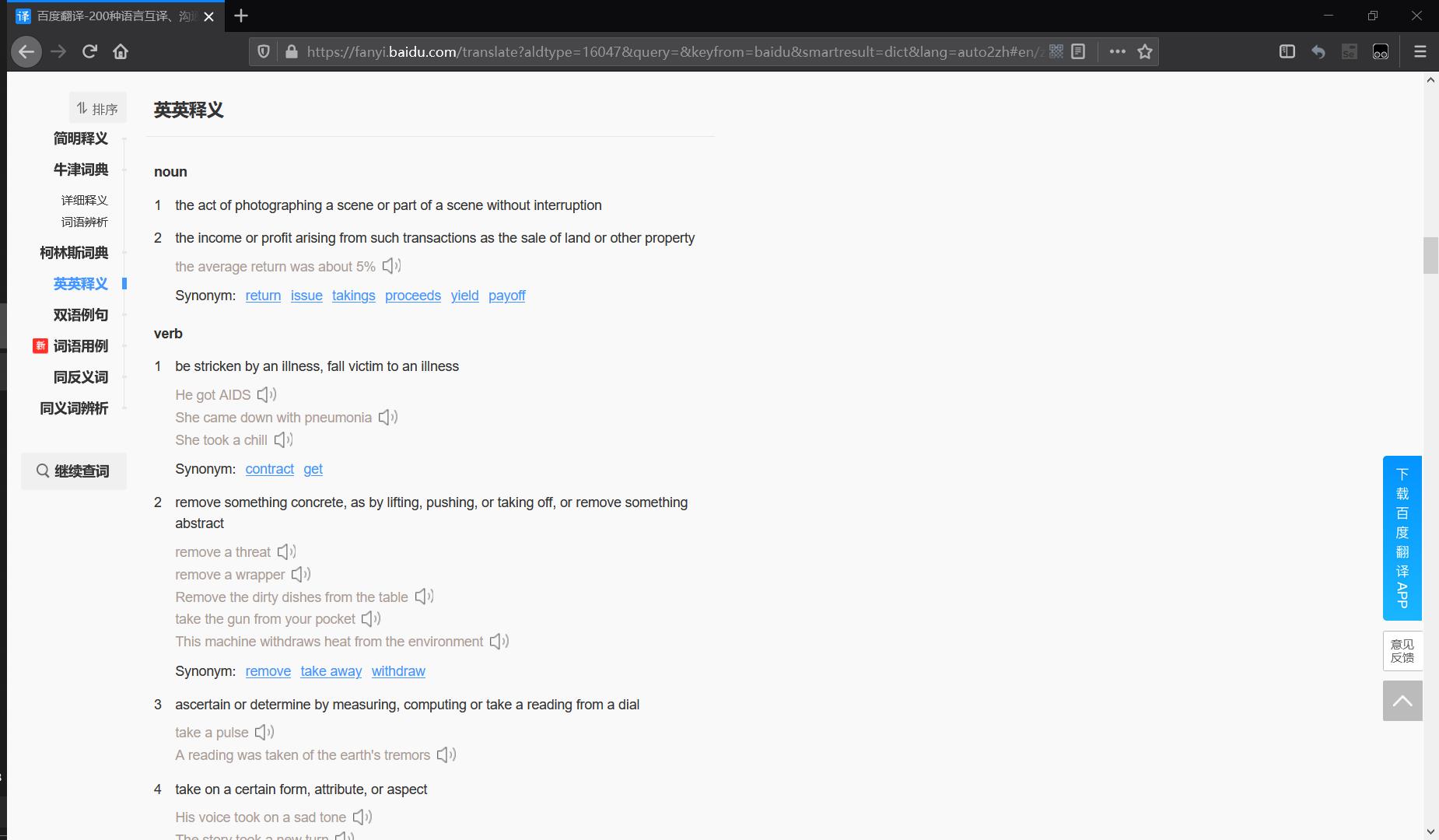
-
双语例句:最直接的想法可以作为机器翻译任务的数据源,注意到这里的双语例句中的take是带有词义标注的,所以用途可能会更为广泛。👇
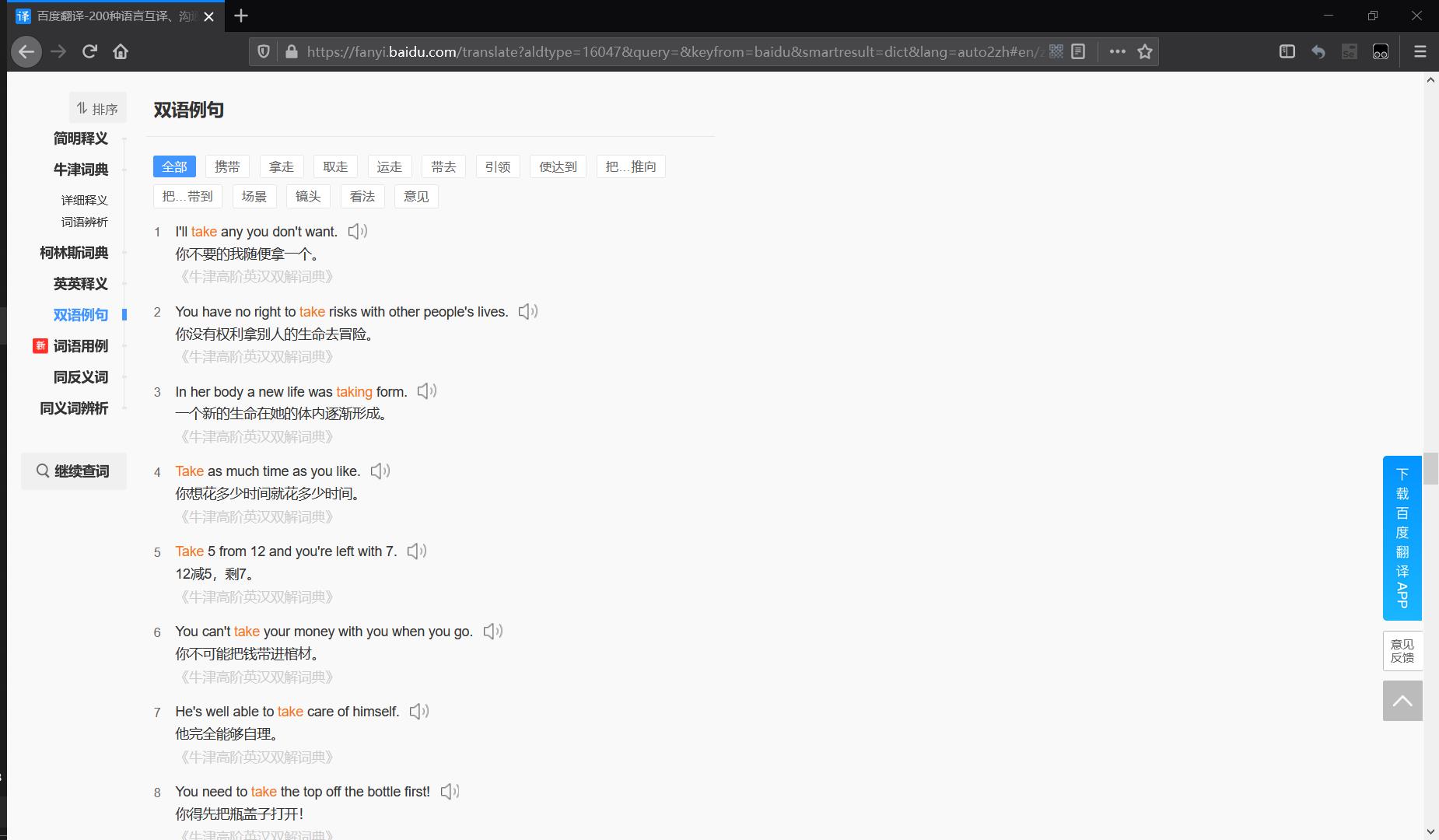
-
其他几个栏目下的数据笔者简单概括,不再截图赘述:
-
词语用例即一些常用搭配,如take after,take in等,虽然take有非常多的常用搭配,而且有些搭配还有很多的不同释义,笔者认为这些常用搭配的短语在英文语句分词时应当作为整体考虑,因为拆分下来可能并不能找到适合的take语义与其匹配,并且短语后的介词可能也不是其本身的含义。
- 以短语搭配take in为例,常用释义为收留,其他还有 吸收,理解,改小 等含义,显然拆分为take与in后并不能体现这些释义,因此take in就应当视为一个单词考虑。
- 好在并不是所有单词都有如此多的常见搭配,可能通过枚举解决此类问题,通过更加合理的预训练,这样可能会使得模型在一些下游任务的表现得到提升。
-
同反义词以及同义词辨析是百度翻译与其他几个在线翻译最大的突出点,有道翻译没有这一项数据,Google翻译则过于简略缺少例句参考,百度翻译在这一项中除了有同义词的例举释义外,也给出了双语例句作为参考。假设某种任务是让机器辨析某个英文句子中的单词(如take)是否可以用其他类似单词替代(如常见的同义词grasp,capture,hold等),这就可以作为一个可能的数据增强来源。
-
-
既然有如此多具有潜在利用价值的数据可供挖掘,那么如何获取就是关键问题了,当然百度作为巨头自然会对公开数据进行一些加密,笔者通过半天的摸索,基本弄得非常明白,以为爬取思路很有趣味,非常值得借鉴与参考,不辞繁琐且与众友分享一二。
目录
思路解析
1 朴素的页面源代码爬取
让我们回头再来看一下查询take单词的页面:👇

可以看到网址上清楚得记录了#en/zh/take,显然这表示我们在从英文(en)翻译到中文(zh),需要翻译的文本是take,且所有需要爬取的数据都在这个页面上(以双语例句为例可以看到包含在标签sample-source中):👇
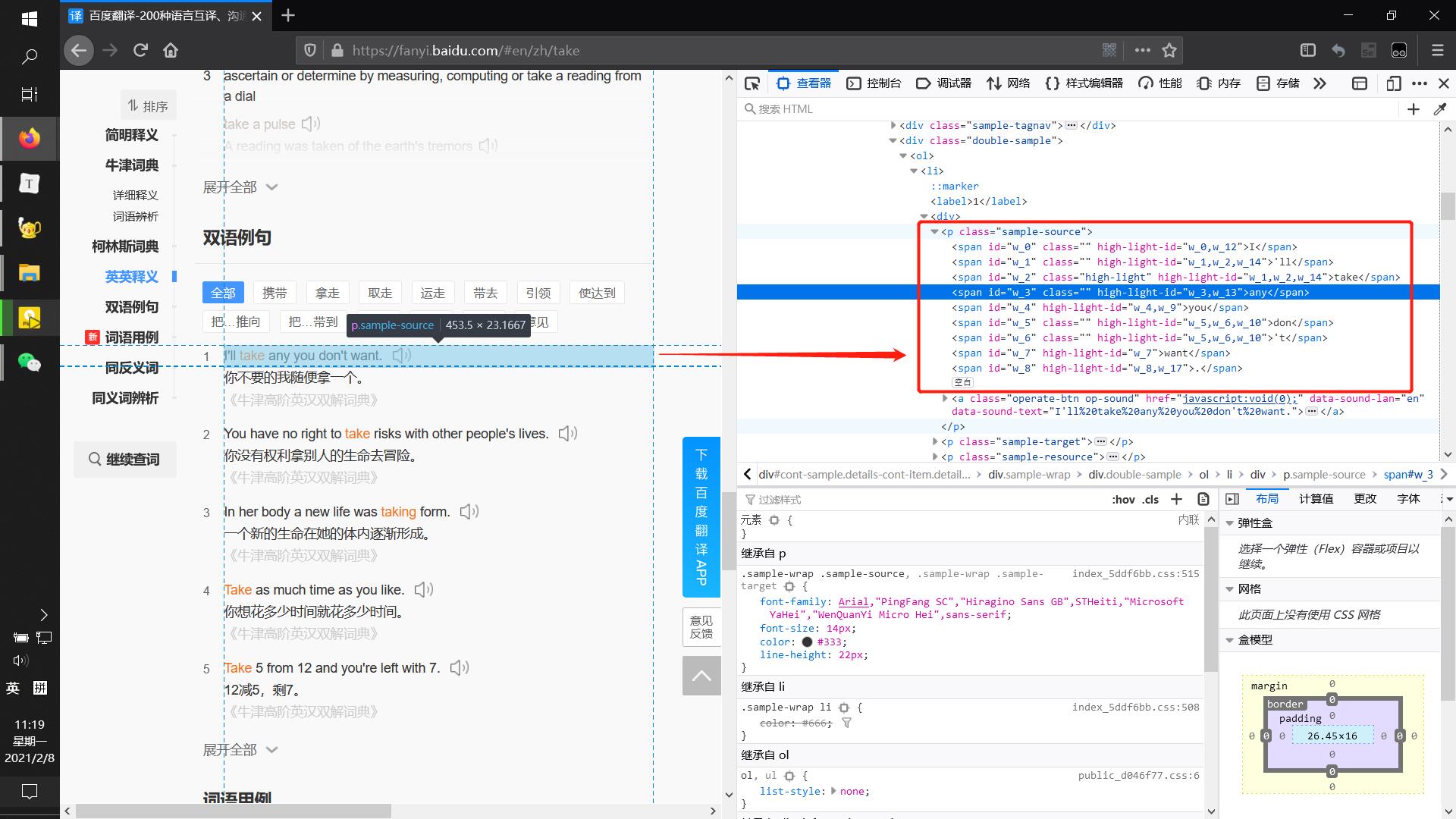
似乎问题非常简单,直接获取该页面上的页面源代码即可解决:👇
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import requests
word = 'take'
url = 'https://fanyi.baidu.com/#en/zh/' + word
headers = 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0'
r = requests.get(url, headers=headers)
html = r.text
with open('baidufanyi_.html'.format(word), 'w', encoding='utf8') as f:
f.write(html)
我们将得到的页面源代码写出到外部文件,查找sample-source标签后失望的发现这里面写得都是一些模板语言,缺乏数据填充,并没有需要的东西:👇
此路不通,须当另辟蹊径,也许之后还会回到这段朴素的页面源代码上呢?所谓返璞归真,约莫如此罢。
2 试试抓取数据包
既然页面源代码上显示为需要数据填充的模板语言,那么前端必然是向后端发起了数据请求,通过抓包应当可以获得需要的数据。👇
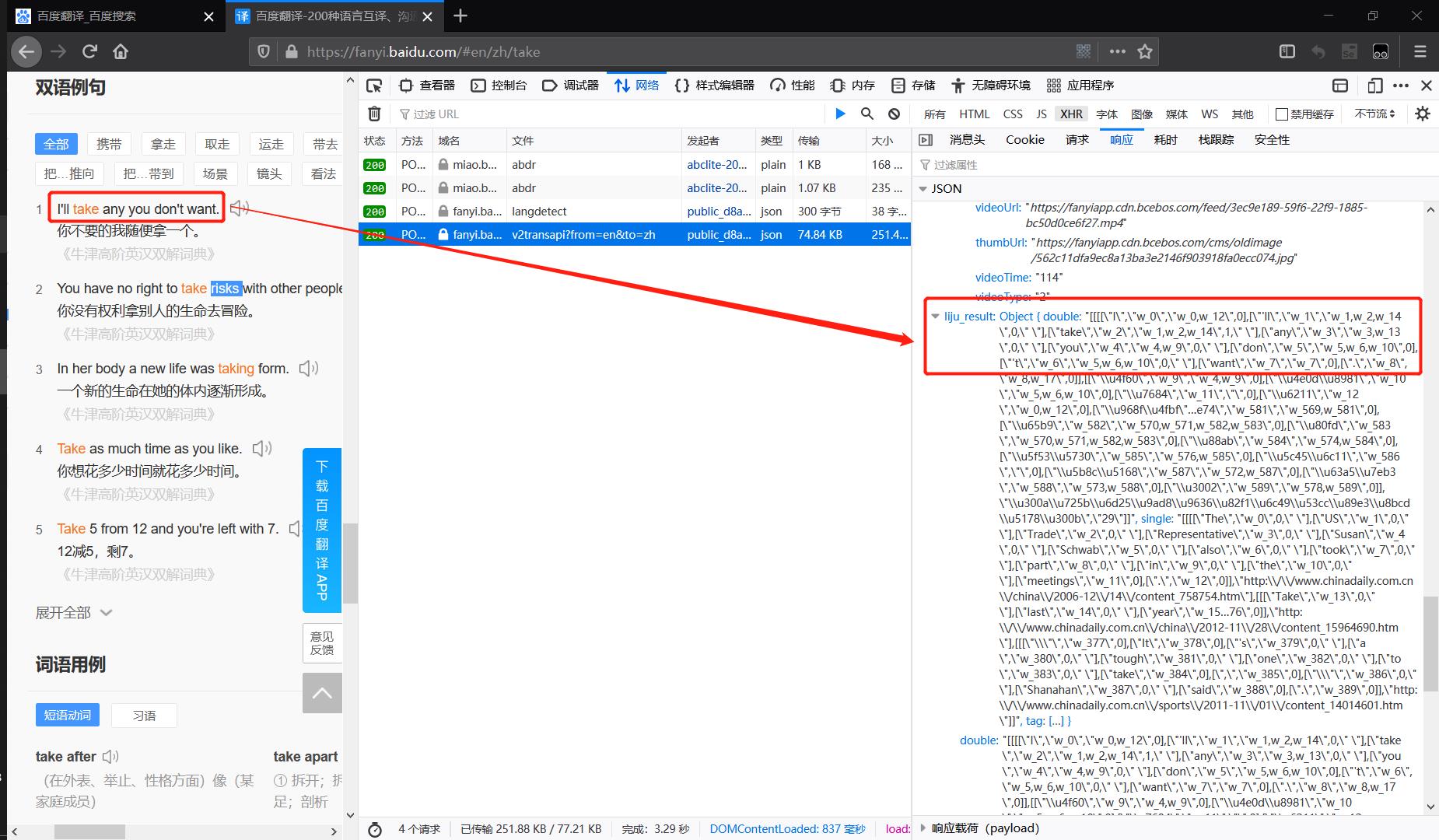
不出所料在XHR监听中我们看到了v2transapi?from=en&to=zh这个数据包,通过上图对应照勉强可以看出右边红框中的json数据就是左边的例句 I’ll take any you don’t want.。
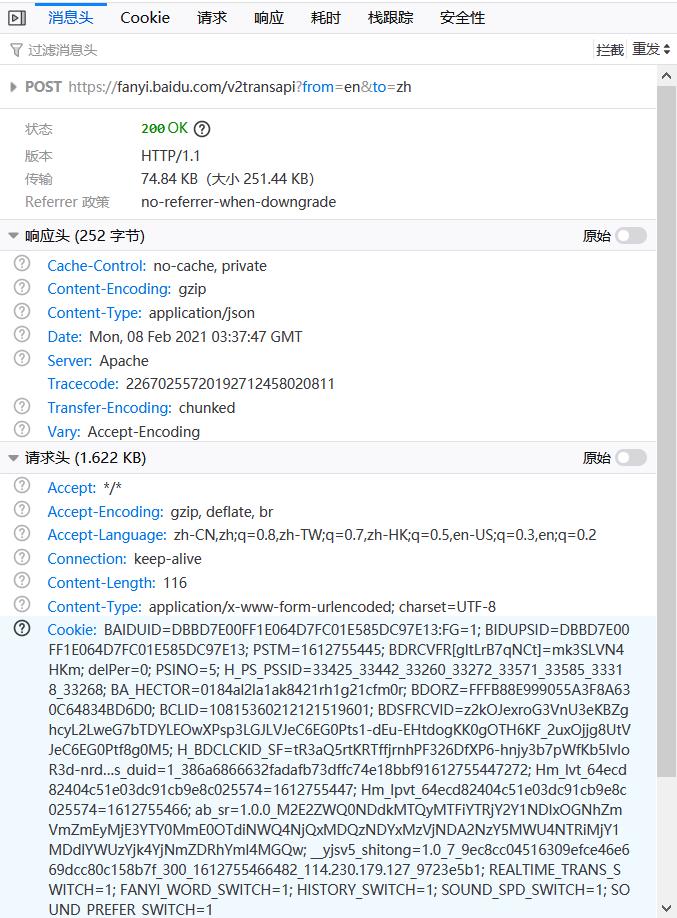
查看消息头可以发现这是一个POST请求(左图),表单数据(右图)也非常简单:👇
- 注:Cookie没有打码大家也别深究了,截屏中没有登录百度账号,所以Cookie里面没有什么有用的信息,事实上百度翻译爬取中Cookie是必要的,后文中将会在页面javascript中看到这一点,为了便于后续代码运行,本文使用明文Cookie。
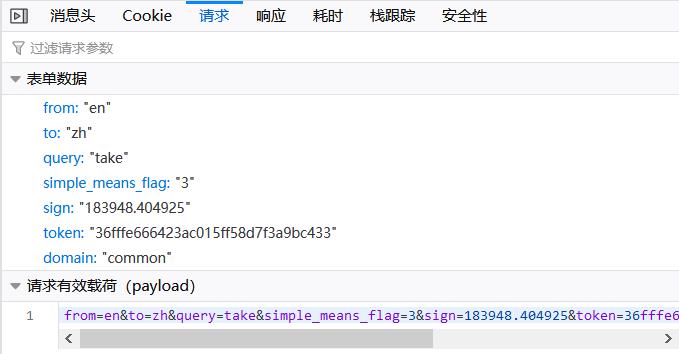
问题似乎又解决了,让我们来试试是否可行:👇
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import json
import requests
word = 'take'
url = 'https://fanyi.baidu.com/v2transapi'
formdata =
'from' : 'en',
'to' : 'zh',
'query' : word,
'simple_means_flag' : '3',
'sign' : '183948.404925',
'token' : '36fffe666423ac015ff58d7f3a9bc433',
'domain' : 'common',
headers =
'Host': 'fanyi.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Content-Length': '116',
'Origin': 'https://fanyi.baidu.com',
'Connection': 'keep-alive',
'Referer': 'https://fanyi.baidu.com/',
'Cookie': 'BAIDUID=DBBD7E00FF1E064D7FC01E585DC97E13:FG=1; BIDUPSID=DBBD7E00FF1E064D7FC01E585DC97E13; PSTM=1612755445; BDRCVFR[gltLrB7qNCt]=mk3SLVN4HKm; delPer=0; PSINO=5; H_PS_PSSID=33425_33442_33260_33272_33571_33585_33318_33268; BA_HECTOR=0184al2la1ak8421rh1g21cfm0r; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; BCLID=10815360212121519601; BDSFRCVID=z2kOJexroG3VnU3eKBZghcyL2LweG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tR3aQ5rtKRTffjrnhPF326DfXP6-hnjy3b7pWfKb5lvIoR3d-nrdDxAWbttf5q3RymJ42-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvD--g3-AqBM5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIE3-oJqCLaMItR3f; __yjs_duid=1_386a6866632fadafb73dffc74e18bbf91612755447272; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1612755447; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1612755466; ab_sr=1.0.0_M2E2ZWQ0NDdkMTQyMTFiYTRjY2Y1NDIxOGNhZmVmZmEyMjE3YTY0MmE0OTdiNWQ4NjQxMDQzNDYxMzVjNDA2NzY5MWU4NTRiMjY1MDdlYWUzYjk4YjNmZDRhYmI4MGQw; __yjsv5_shitong=1.0_7_9ec8cc04516309efce46e669dcc80c158b7f_300_1612755466482_114.230.179.127_9723e5b1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1',
r = requests.post(url, data=formdata, headers=headers)
with open('transapi_.json'.format(word), 'w', encoding='utf8') as f:
json.dump(r.json(), f)
这里同样将POST请求得到的json数据导出到外部文件中,可以看到非常完整的页面数据,虽然看起来很乱,但是笔者可以肯定的说页面上所有有用的信息,包括双语例句,同义词辨析等等条目都包含在这段json中了,至于如何解析出可用的数据,那就是后话了。👇
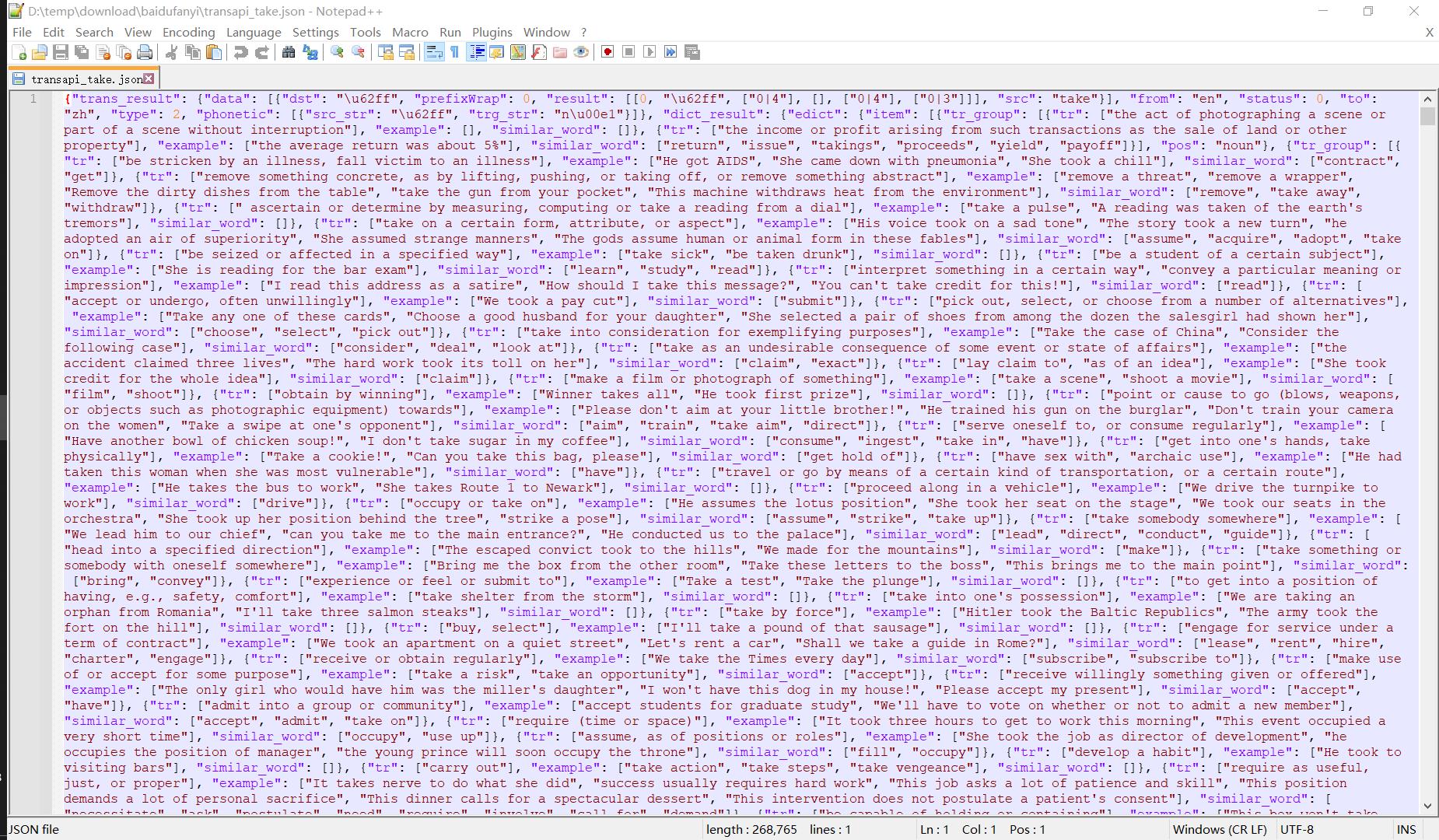
大功告成!让我们用上面的代码再试试其他单词的查询结果吧,将上述代码第8行的word = 'take'修正为word = 'get'试试:👇
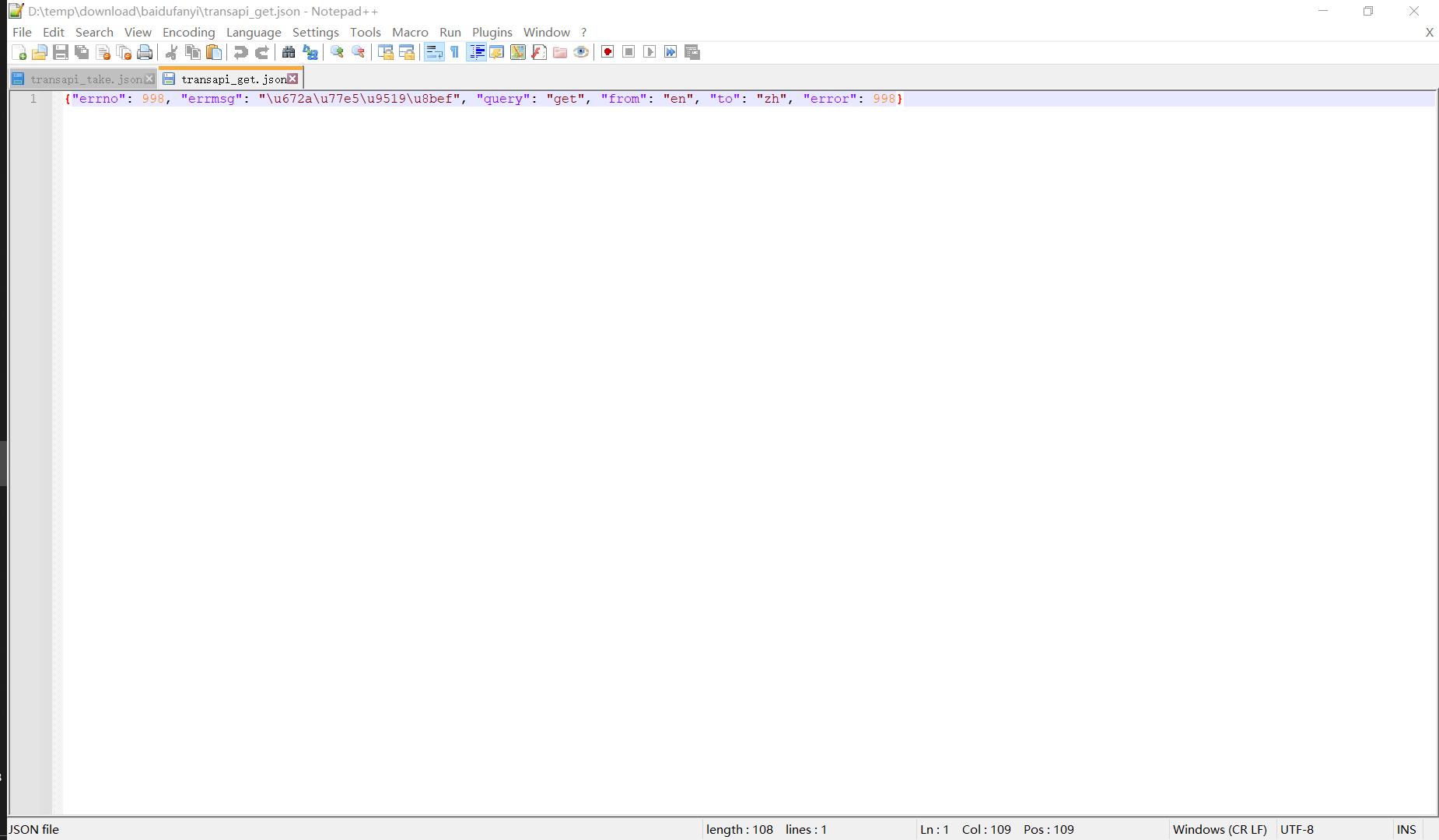
显然问题没有那么简单,替换成新的单词就无法适用这个方法,回头我们再来看看这张表单数据,里面有两个字段非常令人在意:👇
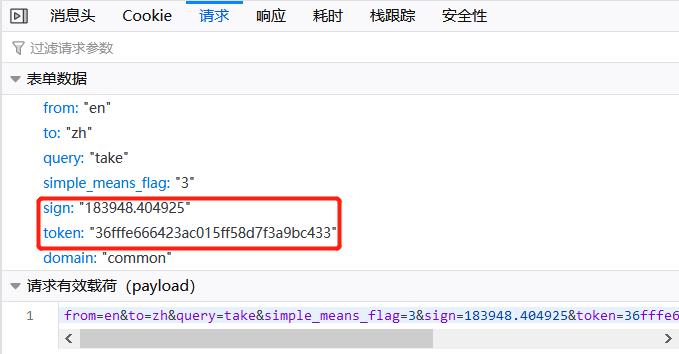
这个sign和token我们并不知道它们是如何生成的,但是我们可以推断这是用于认证而加密得到的字符串,因此必须弄明白这两个字段从何而来,才能彻底解决百度翻译结果的爬取问题。
3 如何生成字段sign与token?
我们继续做抓包工作,不过这次我们试试监听JS中的数据:👇
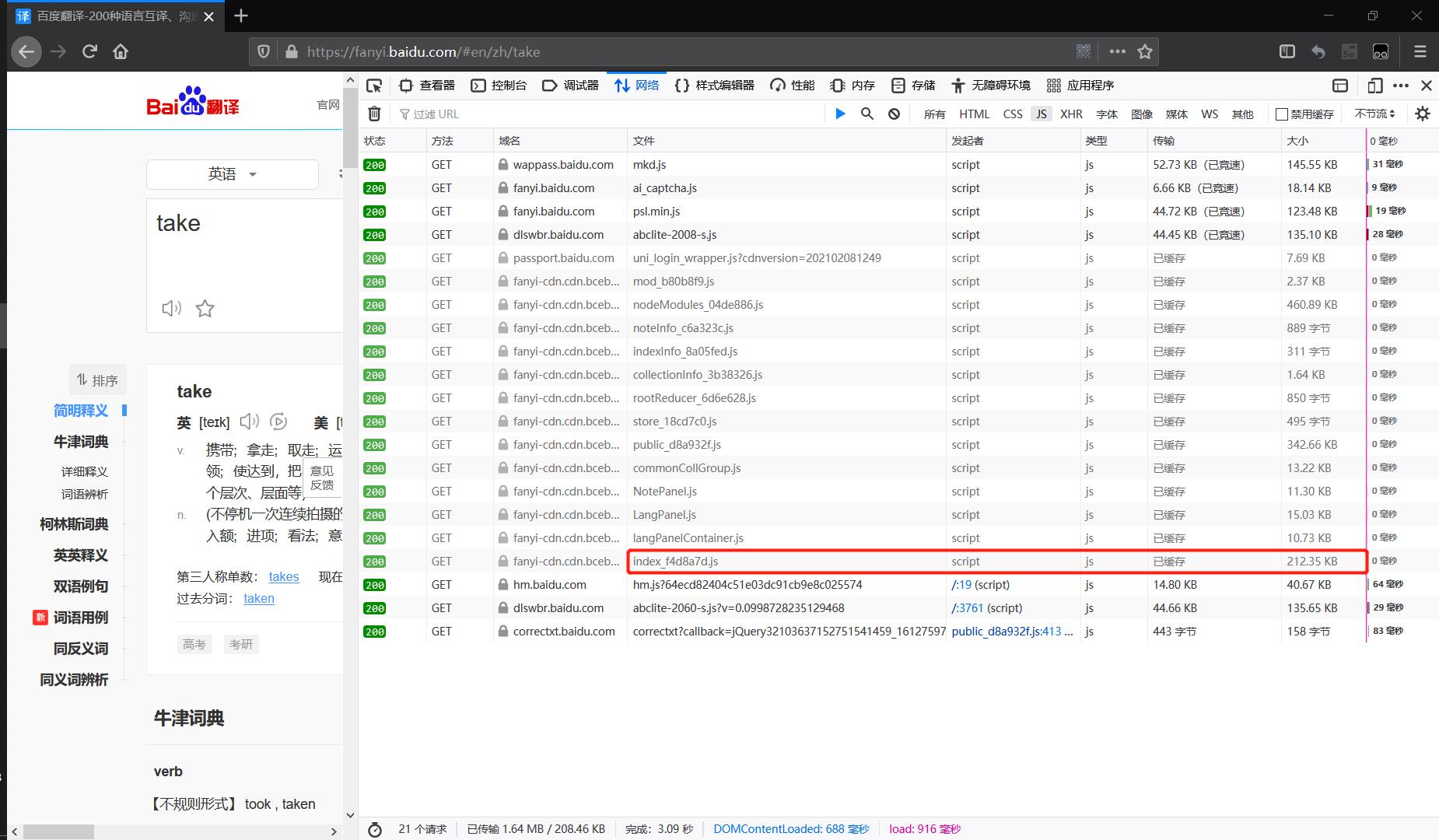
很不幸地,我们又看到一大堆的JS文件,而且从数据包的大小来看还都是些又臭又长的JS代码,如何从这些定位到我们需要的JS文件,再从文件中定位到字段sign与token的生成逻辑?这里笔者分享自己的定位思路:
- ① 首先先看这里21个
JS文件的文件名一列,像NotePanel.js,LangPanel.js一看就是页面风格设计的JS文件,ai_captcha.js是一个智能验证(显然这里的sign与token并不是很智能),直接可以排除; - ② 接下来看
JS文件的文件大小一列,一般来说,那种几kb都不到的JS文件里都是一些功能性的小工具,或是存放一些小规模的静态数据,基本可以忽略; - ③ 然后看
JS文件的加载时间一列,注意到这个页面上的数据当时就完全加载了,如果JS文件都加载得这么慢,那么利用这段JS还要接着去请求后端数据岂不是会慢得离谱,因此可以只考察那些0毫秒的JS文件。 - ④ 最后,上面三个策略只是缩小筛选范围,最重要的是这一点,即便不用上面三点的方法也能迅速确定到上图红框中的
JS文件:试想,那个包含了向后端请求数据的JS文件中一定会有什么?必然会包含表单数据!表单数据中有什么?表单数据中有'sign'和'token'这两个字符串!所以只要下载(或直接复制)每个JS文件的代码,然后全文搜索sign或token,即可确定哪个JS文件中有我们想看的逻辑。
至此,可以定位到这个index_f4d8a7d.js文件(文件名的后缀f4d8a7d可能随时间推移会变化),注意到走遍红框中有sign和token两个字段:👇
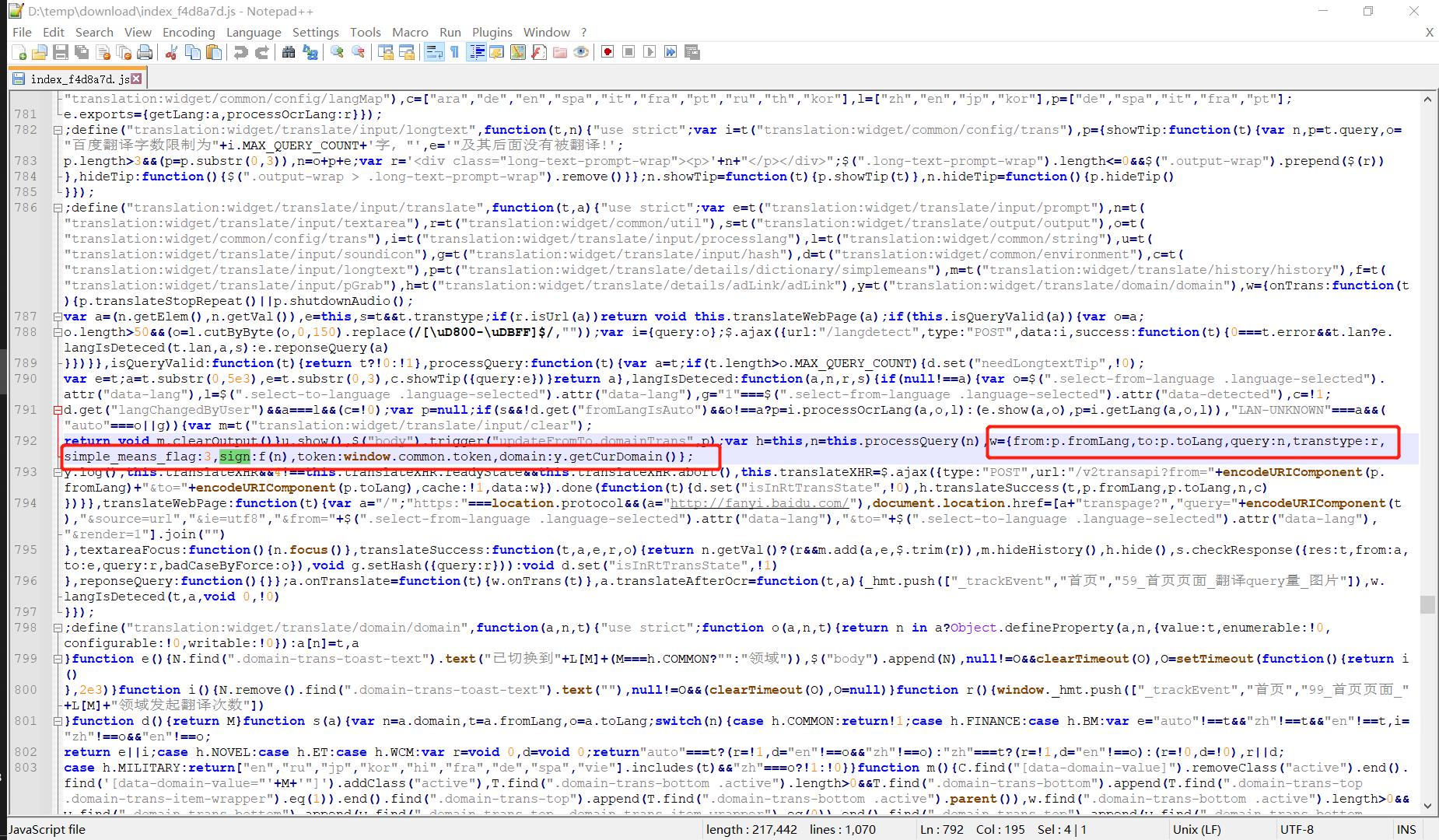
我们将红框中的这段代码复制到下面的框中优化格式查看:👇
w =
from : p.fromLang,
to : p.toLang,
query : n,
transtype : r,
simple_means_flag : 3,
sign : f(n),
token : window.common.token,
domain : y.getCurDomain()
这与上文中的表单数据基本吻合,可能多了一个transtype字段,不过这并不重要,因为我们只关心sign和token两个字段的生成逻辑,接下来我们分别就两个字段的生成逻辑代码进行定位。
3.1 生成token的逻辑
首先从较为简单的token开始,它的值为window.common.token,显然不是所有的变量都叫window,所谓window就是页面的全局变量,通常可以在页面源代码中找到它的定义,即使不能,它的位置也一般在像这种以index为前缀的JS文件中(如果不是当我没说,最坏的结果应该是藏在之前JS抓包的其他JS文件中了)。
此时我们回到1 朴素的页面源代码爬取章节中的页面源代码里,用相同的代码拿到页面源代码再看看:👇(完全相同,当然其实这里已经可以直接请求https://fanyi.baidu.com/即可,无需带上后面的“查询字符串”了。)
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import requests
word = 'take'
url = 'https://fanyi.baidu.com/#en/zh/' + word
headers = 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0'
r = requests.get(url, headers=headers)
html = r.text
with open('baidufanyi_.html'.format(word), 'w', encoding='utf8') as f:
f.write(html)
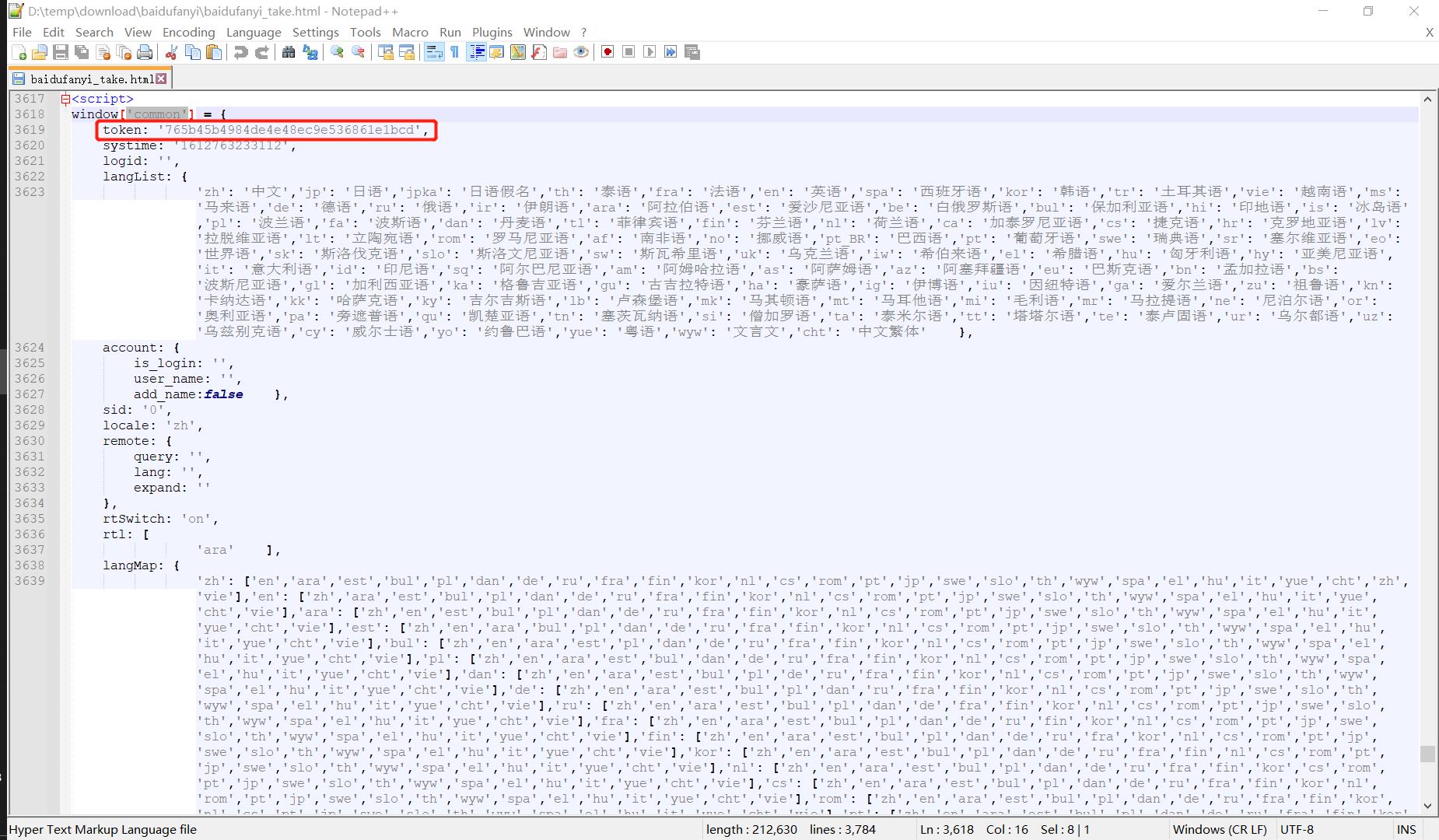
在导出的外部文件中搜索common即可定位到下面的页面源代码中的<script>部分:👇
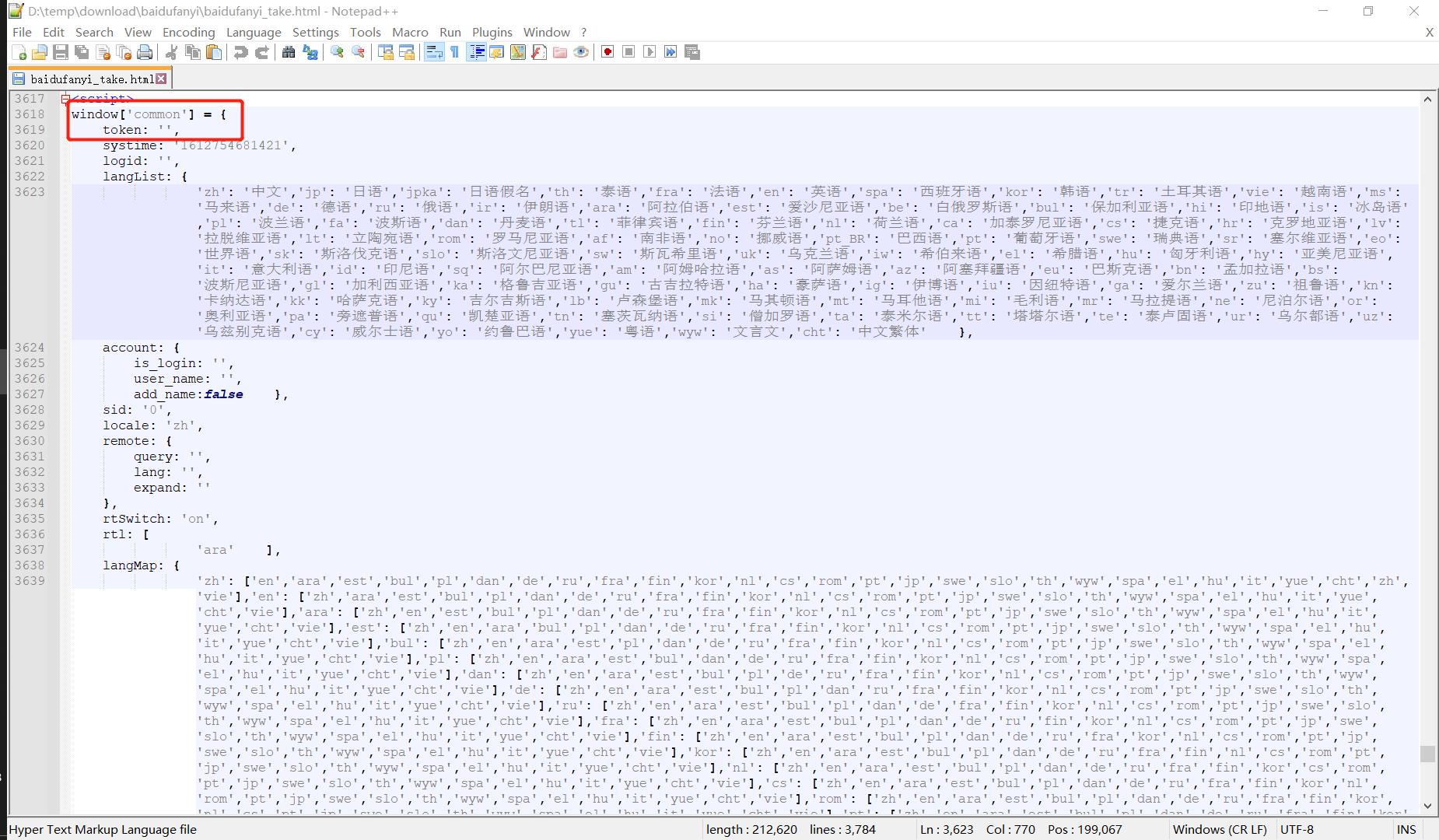
似乎运气不太好,window.common.token竟然是一个空字符串,别急,再往下面拉几行看看:👇
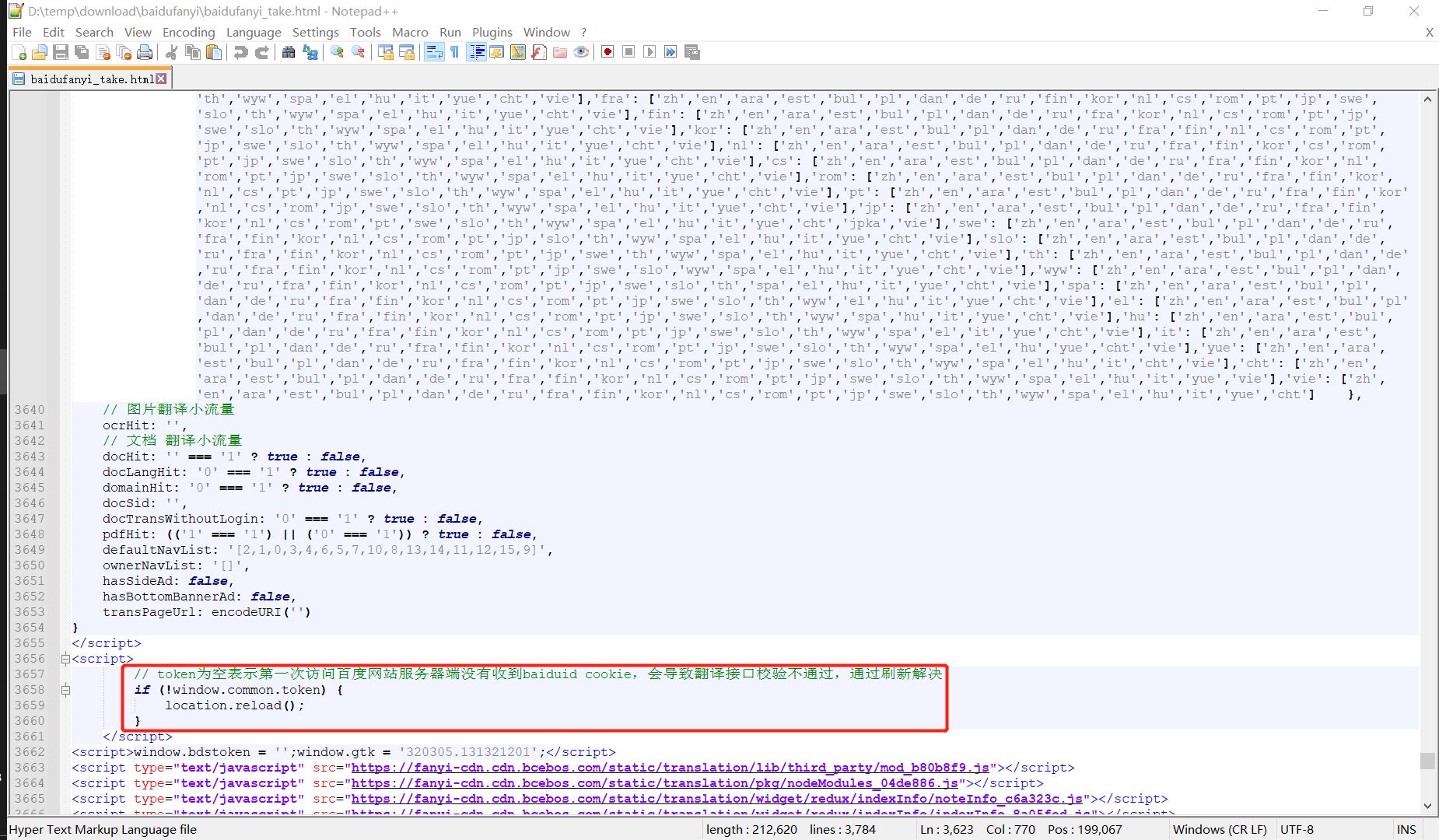
token为空表示第一次访问百度网站服务器端没有收到baiduid cookie,会导致翻译接口校验不通过,通过刷新解决
原来这里需要带上Cookie访问才能得到token的值,值得注意的是,这里的请求头与上文POST请求时请求头并不完全相同,是不可以直接套用的,通过访问https://fanyi.baidu.com/后抓包HTML,取得下图中的请求头即可:👇
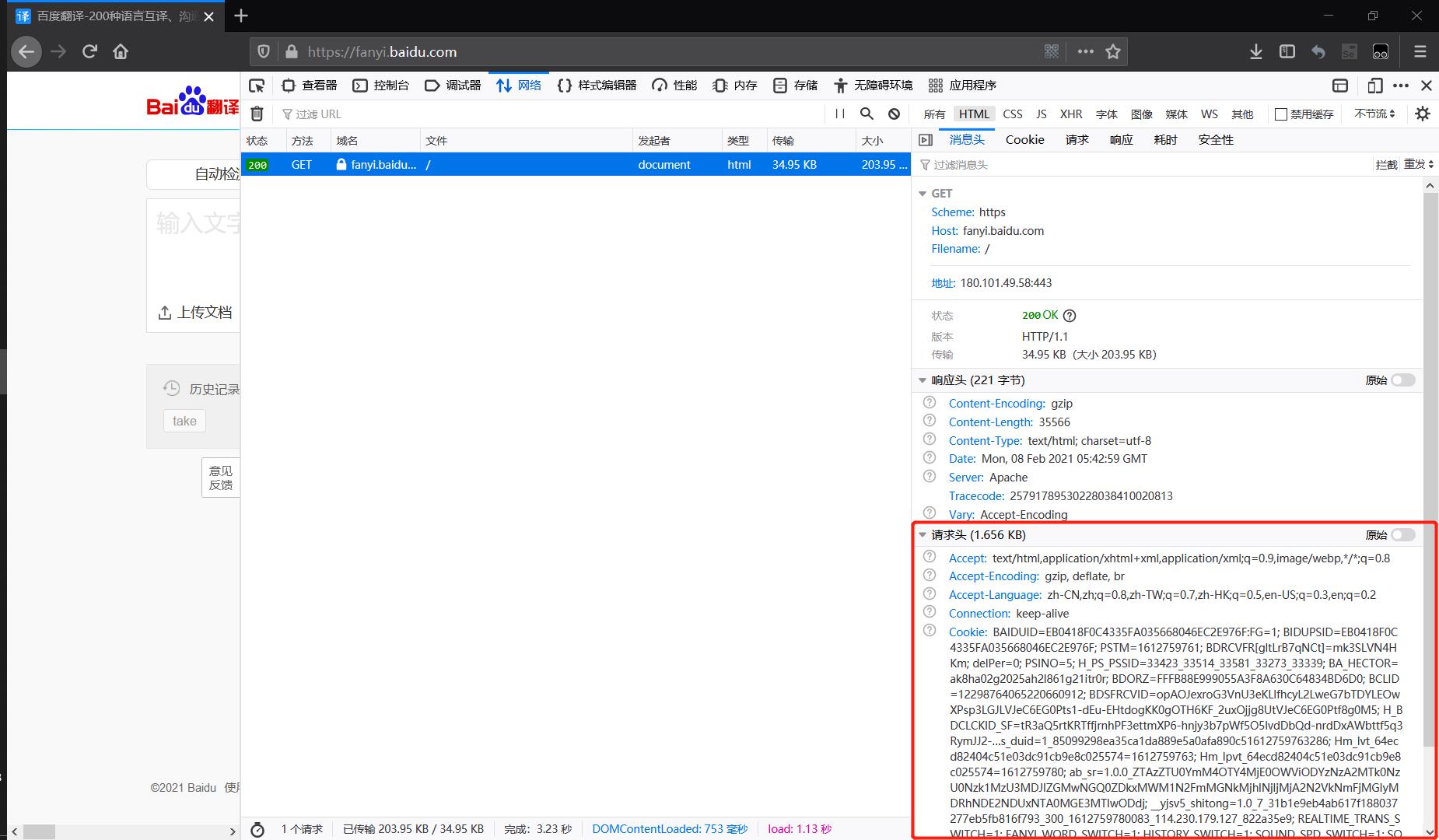
此时我们加入完整的请求头再来一遍:👇
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import requests
word = 'take'
url = 'https://fanyi.baidu.com/#en/zh/' + word
headers =
'Host' : 'fanyi.baidu.com',
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language' : 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding' : 'gzip, deflate, br',
'Connection' : 'keep-alive',
'Cookie' : 'BAIDUID=57D8DECD1001EDF4A260905A983072A9:FG=1; BIDUPSID=57D8DECD1001EDF4A260905A983072A9; PSTM=1612680499; BDRCVFR[gltLrB7qNCt]=mk3SLVN4HKm; delPer=0; PSINO=5; H_PS_PSSID=33425_33355_33273_33585; BA_HECTOR=2g8g240g0h00ak24451g1v39k0r; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1612680504,1612680509; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1612680509; __yjs_duid=1_57795229af6fbff1bde0f88f5beda8381612680504436; ab_sr=1.0.0_ZGQxNTEyYzNmYmM3YzA3ODgxMTIzNzhkNTQ2MDg4ODU2ZDAxODNlODQxZjJlYzdkNDNhNjhlYjIyNWNlZjIxNmIzOTE2YzgxNjJjMTExMzlkMWY5NWQzOTUxMTkzYWZi; __yjsv5_shitong=1.0_7_f89862c9f80b86296408413c2a5c443713a1_300_1612680509895_49.95.205.54_60776bff; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1',
'Upgrade-Insecure-Requests' : '1',
r = requests.get(url, headers=headers)
html = r.text
with open('baidufanyi_.html'.format(word), 'w', encoding='utf8') as f:
f.write(html)
重新查看导出的外部文件中的页面源代码,已经有token的值了:👇
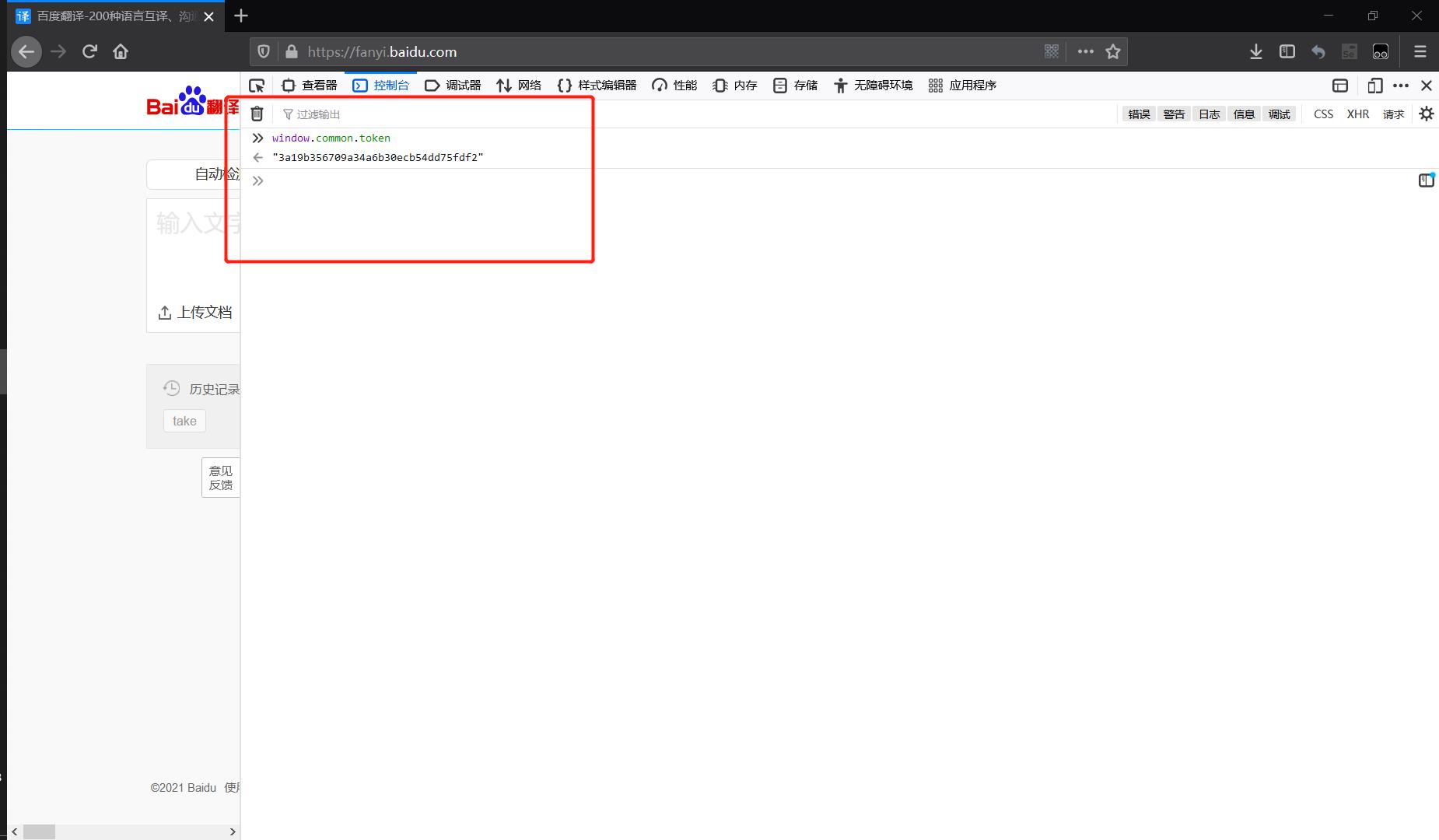
另外如果直接在浏览器的控制台中输入变量名也可以直接获取全局变量的值:👇
至此如何获取token的方法已经明晰,下文中笔者将给出如何取出这个token值的一种相对比较鲁棒的脚本方法(即如果页面源代码发生一些变化也能正确定位这个随机变化的token值)。
3.2 生成sign的逻辑
w =
from : p.fromLang,
to : p.toLang,
query : n,
transtype : r,
simple_means_flag : 3,
sign : f(n),
token : window.common.token,
domain : y.getCurDomain()
sign的值为f(n),想要在这个200多kb的JS文件中找到某个函数逻辑,似乎全文阅读一遍是不现实的,而且f(n)一看就是局部定义的函数,是无法通过控制台输出看到结果的。
不过好消息是我们可以直接看出这个函数f的参数是什么:参数为n,而n恰好是字段query的值,即查询的单词(take),这可能算是迷茫中的慰藉了。
接下来的工作就相对偏于经验了,而这本身也是爬虫的魅力所在,因为每一个爬虫都可能是不一样的,同样,在这里适用的逻辑溯源思路并不一定能用在其他复杂爬虫上。笔者仅将自己的思路作为分享。
- ① 首先往找到的表单上方溯寻,找到最近的一个
f的位置(这里如果你是用的相对高级的编辑器,只需要用鼠标框住f,则所有的整词f都会高亮出来,非常便于寻找),如下图中上边两个红框所示:👇
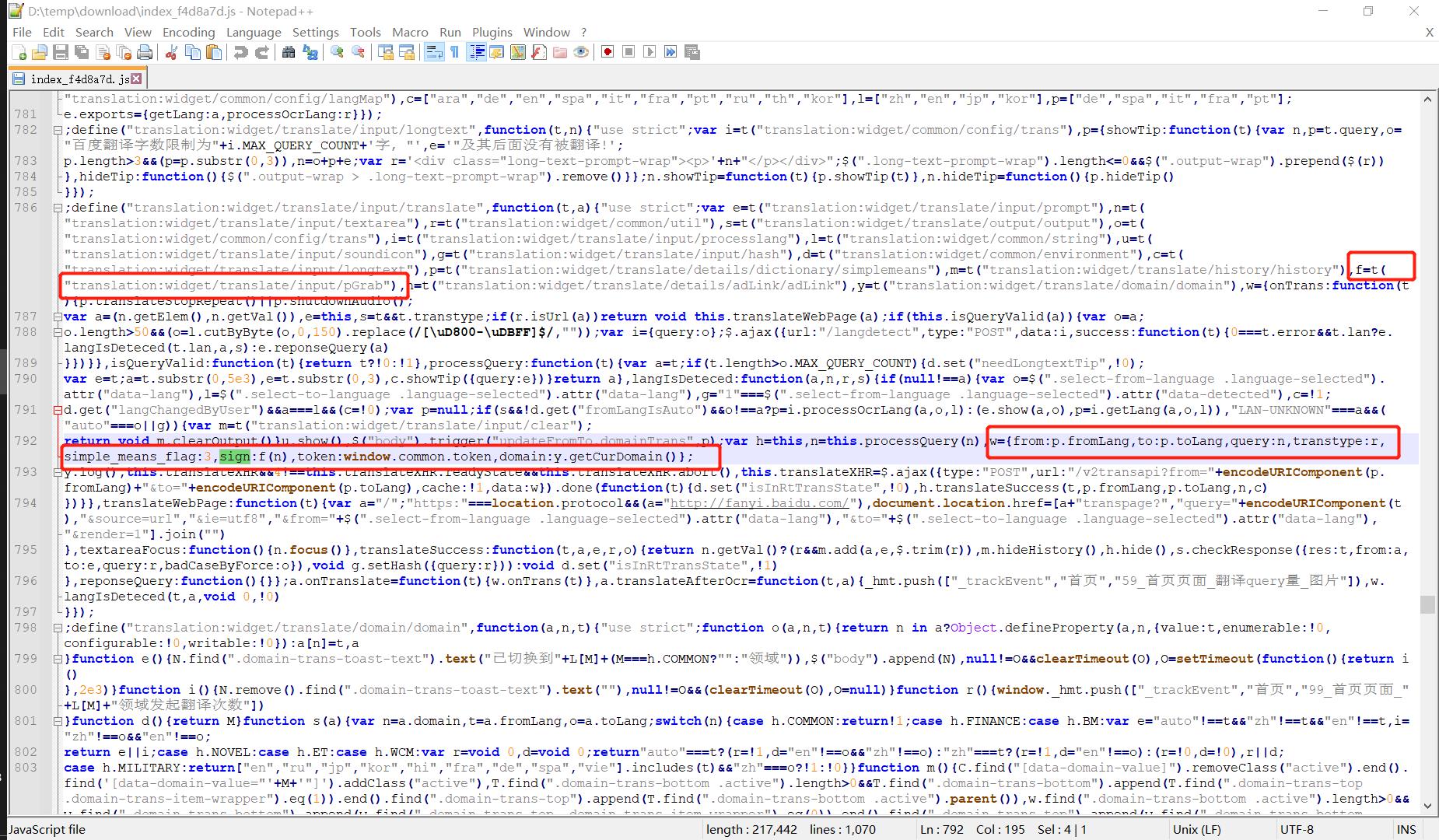
- ② 上图中可以看到
f函数是由一个t函数定义得到的,一段JS代码中这里乱七八糟的t函数会有很多,不过这个t函数的参数并不多见:translation:widget/translate/input/pGrab,似乎是一段路由,试着全文搜索这段路由字符串,于是从700多行的表单数据我们找到了200多行处的特征路由字符串:👇(红框中为一个完整的函数体)
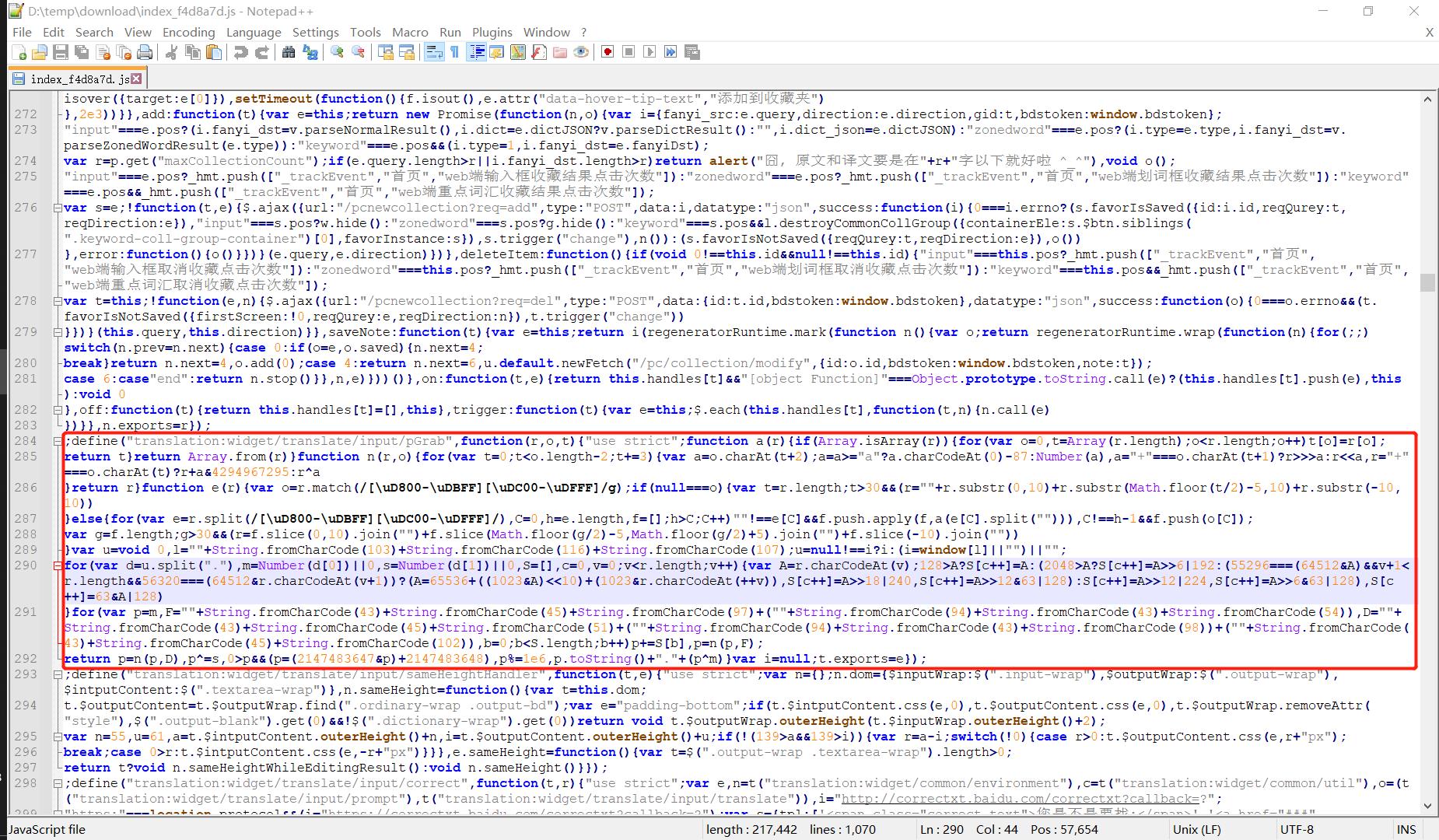
-
③ 显然
translation:widget/translate/input/pGrab被定义为一个方法的接口路由,推测所谓的t函数可能是调用这个接口方法,上图红框中是一个完整的函数体,可以推断f(n)的逻辑就在这个红框中了。简单整理一下这段JS代码:👇;define( "translation:widget/translate/input/pGrab", function(r,o,t) "use strict"; function a(r) if(Array.isArray(r)) for(var o=0,t=Array(r.length);o<r.length;o++) t[o]=r[o]; return t return Array.from(r) function n(r,o) for(var t=0;t<o.length-2;t+=3) var a=o.charAt(t+2); a=a>="a"?a.charCodeAt(0)-87:Number(a), a="+"===o.charAt(t+1)?r>>>a:r<<a, r="+"===o.charAt(t)?r+a&4294967295:r^a return r function e(r) var o=r.match(/[\\uD800-\\uDBFF][\\uDC00-\\uDFFF]/g); if(null===o)var t=r.length;t>30&&(r=""+r.substr(0,10)+r.substr(Math.floor(t/2)-5,10)+r.substr(-10,10)) elsefor(var e=r.split(/[\\uD800-\\uDBFF][\\uDC00-\\uDFFF]/),C=0,h=e.length,f=[];h>C;C++)""!==e[C]&&f.push.apply(f,a(e[C].split(""))),C!==h-1&&f.push(o[C]);var g=f.length;g>30&&(r=f.slice(0,10).join("")+f.slice(Math.floor(g/2)-5,Math.floor(g/2)+5).join("")+f.slice(-10).join("")) var u=void 0,l=""+String.fromCharCode(103)+String.fromCharCode(116)+String.fromCharCode(107); u=null!==i?i:(i=window[l]||"")||""; for(var d=u.split("."),m=Number(d[0])||0,s=Number(d[1])||0,S=[],c=0,v=0;v<r.length;v++) var A=r.charCodeAt(v); 128>A?S[c++]=A:(2048>A?S[c++]=A>>6|192:(55296===(64512&A)&&v+1<r.length&&56320===(64512&r.charCodeAt(v+1))?(A=65536+((1023&A)<<10)+(1023&r.charCodeAt(++v)), S[c++]=A>>18|240, S[c++]=A>>12&63|128):S[c++]=A>>12|224, S[c++]=A>>6&63|128), S[c++]=63&A|128) for(var p=m,F=""+String.fromCharCode(43)+String.fromCharCode(45)+String.fromCharCode(97)+(""+String.fromCharCode(94)+String.fromCharCode(43)+String.fromCharCode(54)),D=""+String.fromCharCode(43)+String.fromCharCode(45)+String.fromCharCode(51)+(""+String.fromCharCode(94)+String.fromCharCode(43)+String.fromCharCode(98))+(""+String.fromCharCode(43)+String.fromCharCode(45)+String.fromCharCode(102)),b=0;b<S.length;b++)p+=S[b],p=n(p,F); return p=n(p,D),p^=s,0>p&&(p=(2147483647<以上是关于日常爬虫学习进阶:百度翻译的秘密(2021版)的主要内容,如果未能解决你的问题,请参考以下文章