MixConv:混合深度卷积核
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MixConv:混合深度卷积核相关的知识,希望对你有一定的参考价值。
文章目录
摘要
论文链接:https://arxiv.org/abs/1907.09595
官方代码:https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet/mixnet
pytorch代码:https://github.com/romulus0914/MixNet-Pytorch
深度卷积在现代高效 ConvNets 中变得越来越流行,但它的内核大小经常被忽视。在本文中,我们系统地研究了不同内核大小的影响,并观察到结合多种内核大小的好处可以带来更好的准确性和效率。基于这一观察,我们提出了一种新的混合深度卷积(MixConv),它自然地将多个内核大小混合在一个卷积中。作为普通深度卷积的简单替代品,我们的 MixConv 提高了现有 MobileNets 在 ImageNet 分类和 COCO 对象检测上的准确性和效率。为了证明 MixConv 的有效性,我们将其集成到 AutoML 搜索空间中,并开发了一个名为 MixNets 的新模型系列,其性能优于以前的移动模型,包括 MobileNetV2 [23](ImageNet top-1 准确率 +4.2%)、ShuffleNetV2 [18 ] (+3.5%)、MnasNet [29] (+1.3%)、ProxylessNAS [2] (+2.2%) 和 FBNet [30] (+2.0%)。特别是,我们的 MixNet-L 在典型的移动设置(<600M FLOPS)下实现了最新的 78.9% ImageNet top-1 准确度。代码在 https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet/mixnet.
1 简介
卷积神经网络 (ConvNets) 已广泛应用于图像分类、检测、分割和许多其他应用。 ConvNets 设计的最新趋势是提高准确性和效率。随着这一趋势,深度卷积在现代 ConvNets 中变得越来越流行,例如 MobileNets [7, 23]、ShuffleNets [18, 33]、NASNet [35]、AmoebaNet [21]、MnasNet [29] 和 EfficientNet [28] ]。与常规卷积不同,深度卷积核分别应用于每个单独的通道,从而将计算成本降低了 C 倍,其中 C 是通道数。在使用深度卷积核设计 ConvNet 时,一个重要但经常被忽视的因素是核大小。虽然传统的做法是简单地使用 3x3 内核 [3, 7, 18, 23, 33, 35],但最近的研究结果表明,更大的内核大小,例如 5x5 内核 [29] 和 7x7 内核 [2] 可以潜在地提高模型的准确性和效率。
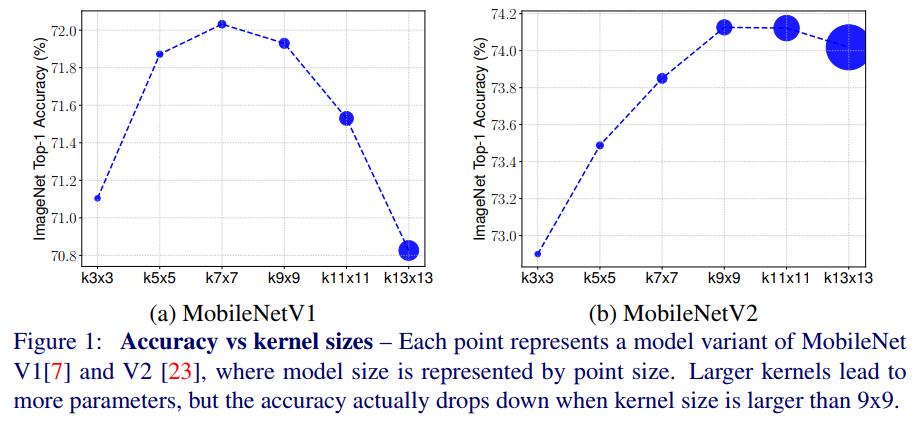
在本文中,我们重新审视了一个基本问题:更大的内核是否总是能获得更高的精度?自从在 AlexNet [14] 中首次观察到,众所周知,每个卷积核负责捕获局部图像模式,该模式在早期阶段可能是边缘,在后期阶段可能是对象。大内核倾向于以更多参数和计算为代价来捕获具有更多细节的高分辨率模式,但它们是否总能提高准确性?为了回答这个问题,我们系统地研究了基于 MobileNets [7, 23] 的内核大小的影响。图 1 显示了结果。正如预期的那样,较大的内核大小会显着增加模型大小,并提供更多参数;然而,模型精度首先从 3x3 上升到 7x7,然后在内核大小大于 9x9 时迅速下降,这表明非常大的内核大小可能会损害精度和效率。事实上,这一观察符合 ConvNet 的第一直觉:在内核大小等于输入分辨率的极端情况下,ConvNet 简单地变成了一个完全连接的网络,这是众所周知的劣势 [7]。这项研究表明了单核大小的局限性:我们既需要大核来捕获高分辨率模式,又需要小核来捕获低分辨率模式,以提高模型的准确性和效率。
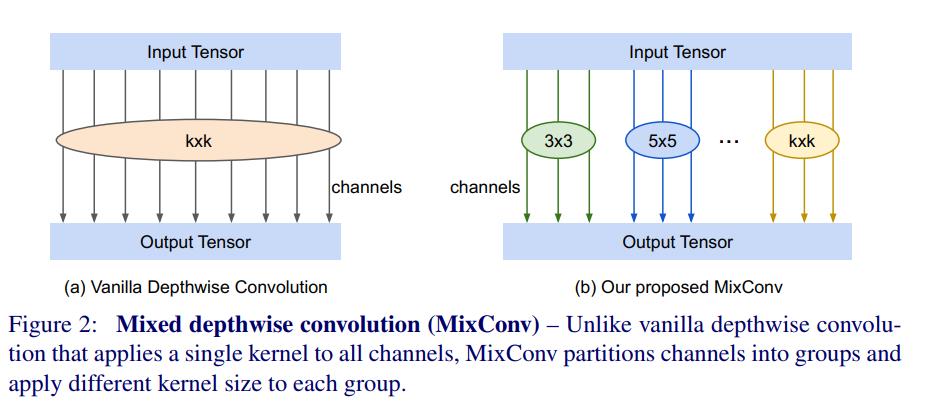
基于这一观察,我们提出了一种混合深度卷积(MixConv),它在单个卷积操作中混合不同的内核大小,以便它可以轻松地捕获具有各种分辨率的不同模式。 图 2 显示了 MixConv 的结构,它将通道划分为多个组,并对每组通道应用不同的内核大小。 我们表明,我们的 MixConv 是 vanilla depthwise 卷积的简单替代品,但它可以显着提高 MobileNets 在 ImageNet 分类和 COCO 对象检测上的准确性和效率。
为了进一步证明我们的 MixConv 的有效性,我们利用神经架构搜索 [29] 开发了一个名为 MixNets 的新模型系列。 实验结果表明,我们的 MixNet 模型明显优于所有以前的移动 ConvNet,例如 ShuffleNets [18, 33]、MnasNet [29]、FBNet [30] 和 ProxylessNAS [2]。 特别是,我们的大尺寸 MixNet-L 在典型模型尺寸和 FLOPS 设置下实现了最新的 78.9% ImageNet top-1 准确度。
2 相关工作
Efficient ConvNets:近年来,从更高效的卷积操作 [3, 7, 11]、瓶颈层 [23, 31] 到更高效的架构 [2, 29, 30],在提高 ConvNet 效率方面付出了巨大努力。 特别是,深度卷积在所有移动设备大小的 ConvNet 中越来越流行,例如 MobileNets [7, 23]、ShuffleNets [18, 33]、MnasNet [29] 和 [3, 21, 35]。 最近,EfficientNet [28] 甚至通过广泛使用深度卷积和逐点卷积实现了最先进的 ImageNet 精度和十倍的效率。 与常规卷积不同,depthwise convolution 对每个通道分别执行卷积核,从而减少参数大小和计算成本。 我们提出的 MixConv 概括了深度卷积的概念,可以被认为是普通深度卷积的替代品。
多尺度网络和特征:我们的想法与之前的多分支卷积网络有很多相似之处,例如 Inceptions [25, 27]、Inception-ResNet [26]、ResNeXt [31] 和 NASNet [35]。 通过在每一层使用多个分支,这些卷积网络能够利用 单个层中的不同操作(例如卷积和池化)。 同样,之前也有很多关于组合来自不同层的多尺度特征图的工作,例如 DenseNet [9, 10] 和特征金字塔网络 [15]。 然而,与这些先前的工作主要集中在改变神经网络的宏观架构以利用不同的卷积操作不同,我们的工作旨在设计一个替代单个深度卷积的直接替换,目标是轻松利用不同的内核 大小而不改变网络结构。
神经架构搜索:最近,神经架构搜索 [16、17、29、34、35] 通过自动化设计过程和学习更好的设计选择,取得了比手工模型更好的性能。 由于我们的 MixConv 是一种具有许多可能设计选择的灵活操作,我们采用类似于 [2, 29, 30] 的现有架构搜索方法,通过将 MixConv 添加到搜索空间中来开发新的 MixNet 系列。
3 MixConv
MixConv 的主要思想是在单个深度卷积操作中混合多个不同大小的内核,以便它可以轻松地从输入图像中捕获不同类型的模式。 在本节中,我们将讨论 MixConv 的特征图和设计选择。
3.1 MixConv 特征图
我们从普通的深度卷积开始。 令
X
(
h
,
w
,
c
)
X^(h,w,c)
X(h,w,c) 表示形状为 (h;w;c) 的输入张量,其中 c 是空间高度,w 是空间宽度,c 是通道大小。 令
W
(
k
,
k
,
c
,
m
)
W^(k,k,c,m)
W(k,k,c,m)表示深度卷积核,其中 k × k 是核大小,c 是输入通道大小,m 是通道乘数。 为简单起见,这里我们假设内核宽度和高度是相同的 k,但可以直接推广到内核宽度和高度不同的情况。 s 输出张量
Y
h
,
w
,
c
,
m
Y^h,w,c,m
Yh,w,c,m 将具有相同的空间 形状 (h,w) 并乘以输出通道大小 m · c,每个输出特征图值计算为:
Y
x
,
y
,
z
=
∑
−
k
2
≤
i
≤
k
2
,
−
k
2
≤
j
≤
k
2
X
x
+
i
,
y
+
j
,
z
/
m
⋅
W
i
,
j
,
z
,
∀
z
=
1
,
…
,
m
⋅
c
(1)
Y_x, y, z=\\sum_-\\frack2 \\leq i \\leq \\frack2,-\\frack2 \\leq j \\leq \\frack2 X_x+i, y+j, z / m \\cdot W_i, j, z, \\quad \\forall z=1, \\ldots, m \\cdot c \\tag1
Yx,y,z=−2k≤i≤2k,−2k≤j≤2k∑Xx+i,y+j,z/m⋅Wi,j,z,∀z=1,…,m⋅c(1)
与普通深度卷积不同,MixConv 将通道划分为组并将不同的内核大小应用于每个组,如图 2 所示。更具体地说,输入张量被划分为 g 组虚拟张量
<
X
^
(
h
,
w
,
c
1
)
,
…
,
X
^
(
h
,
w
,
c
g
)
>
<\\hatX^\\left(h, w, c_1\\right), \\ldots, \\hatX^\\left(h, w, c_g\\right)>
<X^(h,w,c1),…,X^(h,w,cg)>,其中所有虚拟张量 X^ 具有相同的空间高度 h 和宽度 w,并且它们的总通道大小等于原始输入张量:
c
1
+
c
2
+
…
+
c
g
=
c
c1 + c2 +\\ldots +cg = c
c1+c2+…+cg=c。 类似地,我们也将卷积核划分为 g 组虚拟核
<
W
^
(
k
1
,
k
1
,
c
1
,
m
)
,
…
,
W
^
(
k
g
,
k
g
,
c
g
,
m
)
>
<\\hatW^\\left(k_1, k_1, c_1, m\\right), \\ldots, \\hatW^\\left(k_g, k_g, c_g, m\\right)>
<W^(k1,k1,c1,m),…,W^(kg,kg,cg,m)>。 对于第 t 组虚拟输入张量和核,对应的虚拟输出计算如下:
Y
^
x
,
y
,
z
t
=
∑
−
k
l
2
≤
i
≤
k
t
2
,
−
k
t
2
≤
j
≤
k
t
2
X
^
x
+
i
,
y
+
j
,
z
/
m
t
⋅
W
^
i
,
j
,
z
t
,
∀
z
=
1
,
…
,
m
⋅
c
t
(2)
\\hatY_x, y, z^t=\\sum_-\\frack_l2 \\leq i \\leq \\frack_t2,-\\frack_t2 \\leq j \\leq \\frack_t2 \\hatX_x+i, y+j, z / m^t \\cdot \\hatW_i, j, z^t, \\quad \\forall z=1, \\ldots, m \\cdot c_t \\tag2
Y^x,y,zt=−2kl≤i≤2kt,−2kt≤j≤2kt∑X^x+i,y+j,z/mt⋅W^i,j,zt,∀z=1,…,m⋅ct(2)
最终的输出张量是所有虚拟输出张量的串联
<
Y
^
x
,
y
,
z
1
1
,
…
,
Y
^
x
,
y
,
z
g
g
>
<\\hatY_x, y, z_1^1, \\ldots, \\hatY_x, y, z_g^g>
<Y^x,y,以上是关于MixConv:混合深度卷积核的主要内容,如果未能解决你的问题,请参考以下文章