华为昇腾社区鹏城实验室中国软件开源创新大赛·赛道二:任务挑战赛(模型王者挑战赛黄金赛段)
Posted 魏宝航
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华为昇腾社区鹏城实验室中国软件开源创新大赛·赛道二:任务挑战赛(模型王者挑战赛黄金赛段)相关的知识,希望对你有一定的参考价值。
中国软件开源创新大赛·赛道二:任务挑战赛(模型王者挑战赛黄金赛段)
【大赛简介】
人工智能作为一种通用目的技术,已经具备进入所有业务主流程的能力,人们的生产与生活必将发生巨大的改变。为了方便开发者们感受国产AI计算框架,认知体验全栈全场景的AI解决方案,头歌社区携手华为昇腾社区、鹏城实验室、启智社区,共同打造了“模型王者挑战赛”(简称“模王赛”)。
通过本次比赛,大家既可以学习AI领域的知识与技术,又可以通过模型迁移、调优任务提升个人开发能力并得到权威认证,还可以与AI领域的专家直接交流,感受千行百业的智能化升级。另外,大赛配备了免费的算力支撑、丰厚的现金激励,各路勇士们,还在犹豫什么,快快组队参赛吧!
【参赛要求】
每支队伍的人数上限为6人,1名队长;
特别注意:大赛主办、协办单位以及有机会接触赛题背景业务及数据的员工不得参赛。
【大赛时间】
1、青铜赛:即日起–2021年7月16日18:00,已结束。
2、白银赛:2021年7月29日–2021年8月27日18:00,已结束。
3、黄金赛:2021年9月15日–2021年11月26日,已结束。
4、最强王者(年度总决赛):2021年12月24–26日,已结束。
【大赛奖项】
一、基础奖项:
1、黄金赛启动至10月15日12:00,周榜PK,获得周榜“荣耀殿堂”榜主的队伍(共25支)可获得奖金:1000RMB/队;
2、黄金赛启动至11月26日18:00,25道赛题分25个赛道,MindSpore赛题采取竞速赛制,TensorFlow赛题采取性能优先赛制,具体赛制详见下方评分规则,符合赛题要求的队伍(共25支)可获得奖金:12000RMB/队;
3、获得“荣耀殿堂”榜主的队伍,可获得由中国软件开源创新大赛组委会颁发的黄金宝箱;
4、各赛题精度最高的队伍,可获得由中国软件开源创新大赛组委会颁发的黄金宝箱+荣誉证书;
二、赛事入围奖学金
黄金赛段限时开启【赛事入围奖学金】,所有按要求提交了作品的在校学生队伍,MindSpore赛题只要达到精度基线,TensorFlow赛题需同时达到精度和性能基线才能获得参选资格。
评选列表按照作品提交时间排序,每赛题不超过3支队伍,总计50支队伍,每支队伍可获得奖金:1000RMB/队。
注:已经获得基础奖励的同学不可参与奖学金评定,奖学金评审将在黄金赛段截止后统一核算。
【评分规则】
MindSpore黄金赛规则:分布式场景下,论文精度复现竞速赛
1.单卡训练时长>=1小时的,以8卡的精度排名做最终验收;
单卡训练时长<1小时的,以单卡精度排名做最终验收;
2.每支队伍最多可以获得2个题目冠军
3.竞速规则:对于同一道题目,最先提交作品且达到论文精度的队伍,获得冠军;
4.如果因题目难度过大或版本等不可抗因素,导致无团队达到精度基线,组委会重新评审后,设定新的精度基线,达到新基线且精度最高的团队夺冠
TensorFlow黄金赛规则:
1、同时达到精度和性能基线后,优先比对性能,如性能相同则最先提交作品者胜;
2、每支队伍最多可以获得2个题目冠军
赛题一:利用MindSpore实现EfficientNetV2-S图像分类网络
- 论文:
EfficientNetV2: Smaller Models and Faster Training
- Paper地址:
EfficientNetV2: Smaller Models and Faster Training
- 数据集:
CIFAR-10
- 精度基线:
Percentage correct:90%
文章目录
一、论文:EfficientNetV2: Smaller Models and Faster Training
新的卷积网络EfficientNetV2,它比以前的模型具有更快的训练速度和更好的参数效率。该模型结合训练感知神经结构搜索和缩放,共同优化训练速度和参数效率。这些模型是从搜索空间中搜索出来的,搜索空间中充满了新的操作,比如Fused MBConv。实验表明,EfficientNetV2模型的训练速度比最先进的模型快得多,同时体积小了6.8倍。
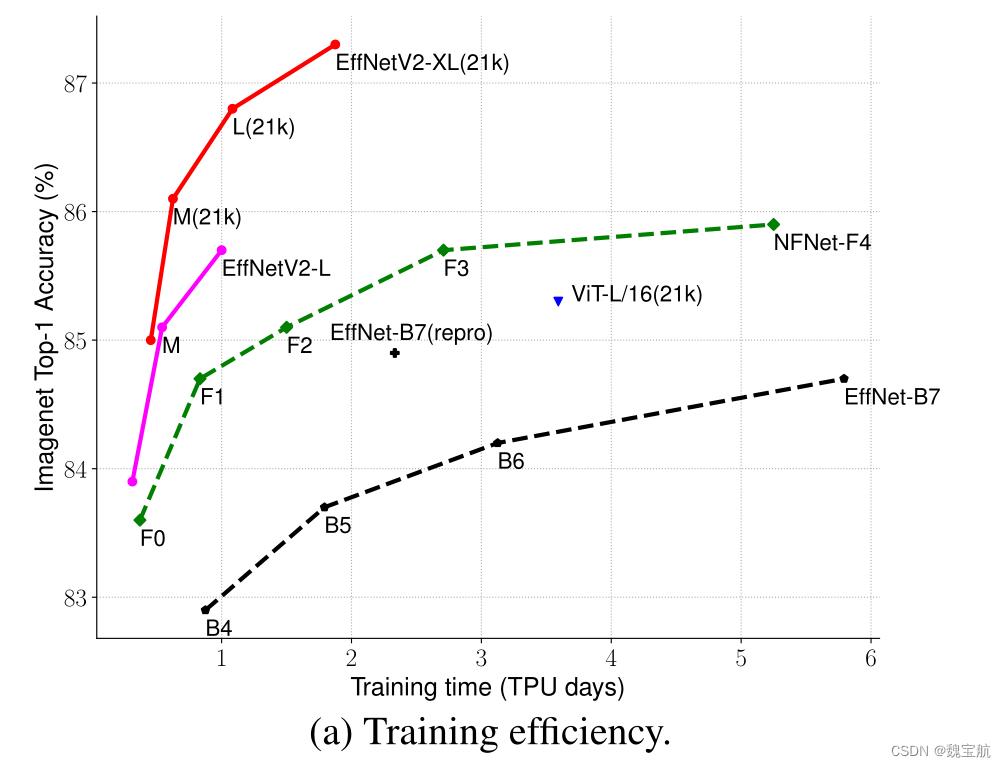
二、EfficientNetV2模型架构设计
EfficientNet(Tan&Le,2019a)是一系列针对触发器和参数效率进行优化的模型。它利用NAS搜索基线效率Net-B0,在准确性和失败率方面有更好的权衡。然后使用复合缩放策略放大基线模型,以获得模型B1-B7族。虽然最近的研究在训练或推理速度方面取得了巨大的进步,但在参数和FLOPs效率方面,它们往往比EfficientNet差(表1)。
2.1 提高训练效率
使用非常大的图像大小进行训练是很慢的:正如之前的工作(Radosavovic等人,2020年)所指出的,EfficientNet的大图像大小会导致大量内存使用。由于GPU/TPU上的总内存是固定的,我们必须以较小的批量来训练这些模型,这大大降低了训练速度。一个简单的改进是应用FixRes(Touvron et al.,2019),使用较小的图像大小进行训练,而不是进行推理。如表2所示,图像大小越小,计算量越少,批量越大,因此训练速度提高了2.2倍。值得注意的是,正如(Touvron et al.,2020;Brock et al.,2021)所指出的,使用较小的图像大小进行训练也会带来略好的准确性。
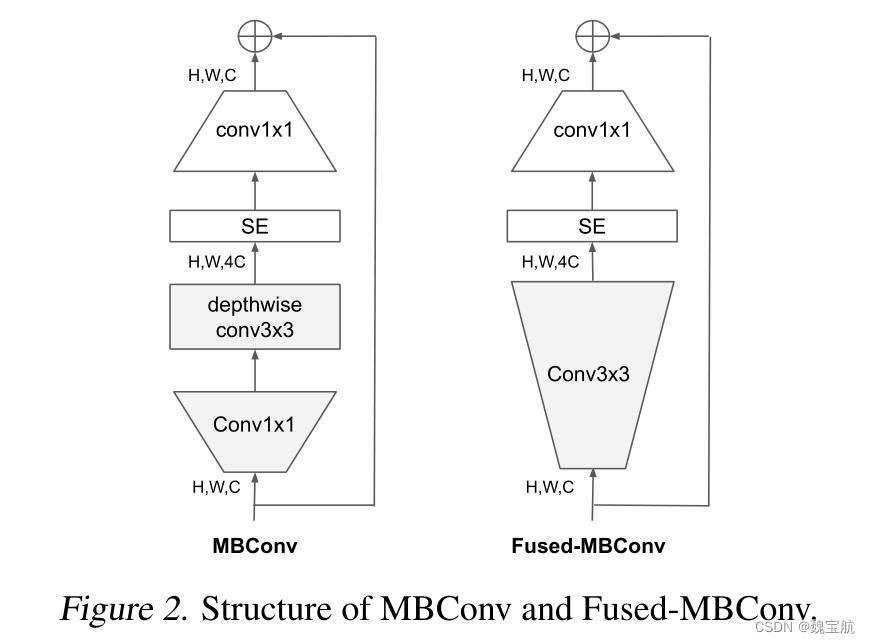
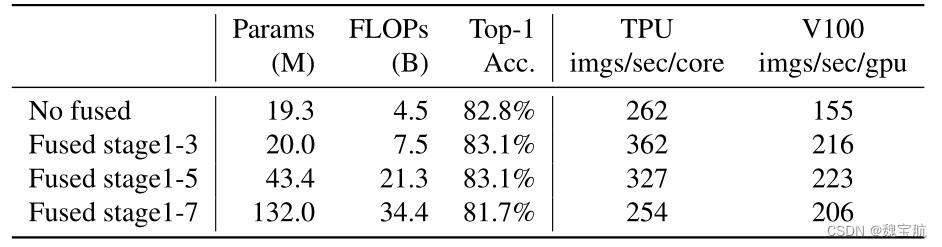
深度卷积在早期阶段较慢,但在后期阶段有效:EfficientNet的另一个训练瓶颈来自广泛的深度卷积(Sifre,2014)。深度卷积比常规卷积具有更少的参数和失败,但它们通常不能充分利用现代加速器。最近,Fused MBConv在(Gupta&Tan,2019)中提出,后来在(Gupta&Akin,2020;Xiong等人,2020;Li等人,2021)中使用,以更好地利用移动或服务器加速器。它将MBConv中的深度conv3x3和扩展conv1x1(Sandler等人,2018;Tan&Le,2019a)替换为单个常规conv3x3,如图2所示。为了系统地比较这两个构建块,我们逐渐用FusedDBCONV替换EfficientNet-B4中的原始MBConv(表3)。当在早期阶段1-3中应用时,FusedMBConv可以在参数和触发器上以较小的开销提高训练速度,但如果我们用Fused MBConv(阶段1-7)替换所有块,那么它会显著增加参数和触发器,同时也会减慢训练速度。找到这两个构建块MBConv和Fused MBConv的正确组合并非易事,这促使我们利用神经架构搜索来自动搜索最佳组合。
平均放大每个阶段都是次优的:EfficientNet使用简单的复合缩放规则平均放大所有阶段。例如,当深度系数为2时,网络中的所有阶段都将使层数加倍。然而,这些阶段对训练速度和参数效率的贡献并不均等。在本文中,我们将使用一种非均匀缩放策略来逐步向后期添加更多层。此外,EfficientNets积极扩大图像大小,导致内存消耗大,训练速度慢。为了解决这个问题,我们稍微修改了缩放规则,并将最大图像大小限制为较小的值。
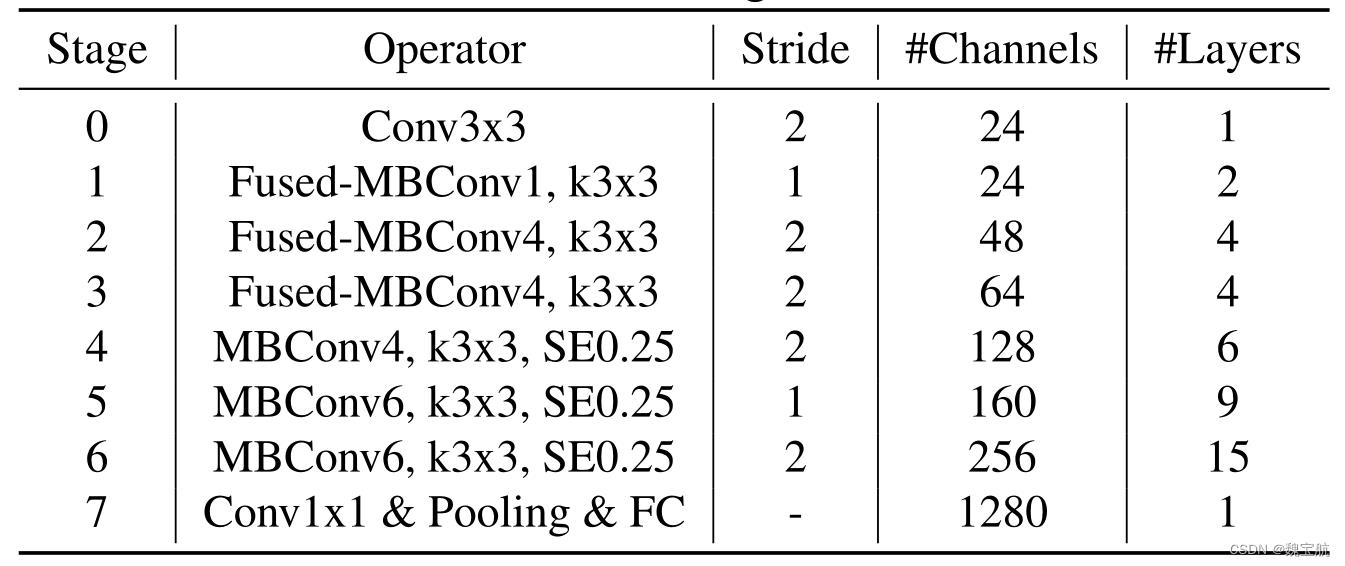
2.2 EfficientNetV2-S MB、Fused块结构设计
2.3 支持培训的NAS和扩展
NAS搜索:我们的支持培训的NAS框架主要基于之前的NAS工作(Tan等人,2019年;Tan&Le,2019a),但旨在联合优化现代加速器的准确性、参数效率和培训效率。具体来说,我们使用EfficientNet作为主干。我们的搜索空间是一个类似于(Tan等人,2019)的基于阶段的因式分解空间,包括卷积运算类型MBConv,融合MBConv,层数,内核大小3x3,5x5,扩展比1,4,6的设计选择。另一方面,我们通过(1)删除不必要的搜索选项(例如池跳过操作)来减少搜索空间大小,因为它们从未在原始效率网中使用;(2) 重复使用主干中已经搜索到的相同通道大小(Tan&Le,2019a)。由于搜索空间较小,我们可以应用强化学习(Tan et al.,2019)或简单地在更大的网络上进行随机搜索,这些网络的大小与EfficientNetB4相当。具体来说,我们对多达1000个模型进行了采样,并对每个模型进行了大约10个时期的训练,减少了图像大小,以便进行训练。我们的搜索奖励结合了模型精度A、标准化训练步长时间S和参数大小P,使用一个简单的加权积A·Sw·PV,其中w=-0.07和v=-0.05根据经验确定,以平衡类似于(Tan等人,2019年)的权衡。
2.4 自适应正则化的渐进学习
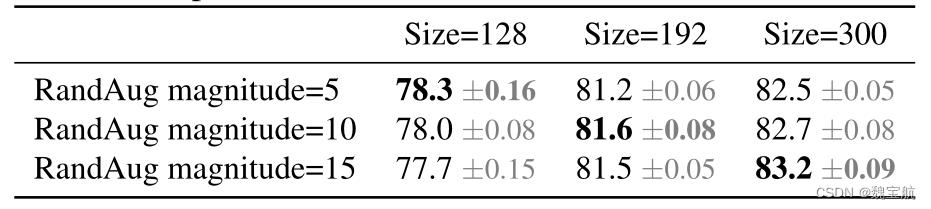
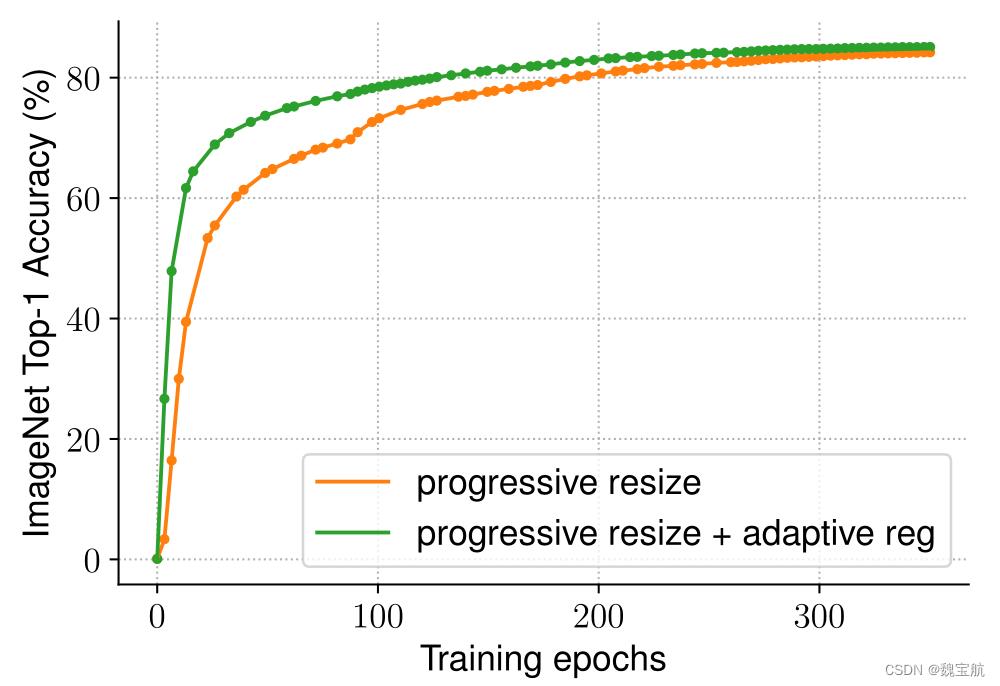
我们假设精度下降来自不平衡正则化:当使用不同图像大小进行训练时,我们还应该相应地调整正则化强度(而不是像以前的工作那样使用固定的正则化)。事实上,大型模型通常需要更强的正则化来对抗过度拟合:例如,EfficientNet-B7使用比B0更大的退出和更强的数据增强。在本文中,我们认为,即使对于相同的网络,较小的图像大小也会导致较小的网络容量,因此需要较弱的正则化;反之亦然,图像尺寸越大,计算量越大,越容易过度拟合。为了验证我们的假设,我们训练了一个从我们的搜索空间采样的模型,该模型具有不同的图像大小和数据增强(表5)。当图像尺寸较小时,在增强较弱的情况下,其精度最好;但对于更大的图像,增强效果更好。这种洞察力促使我们在训练期间自适应地调整正则化和图像大小,从而改进了渐进式学习方法。
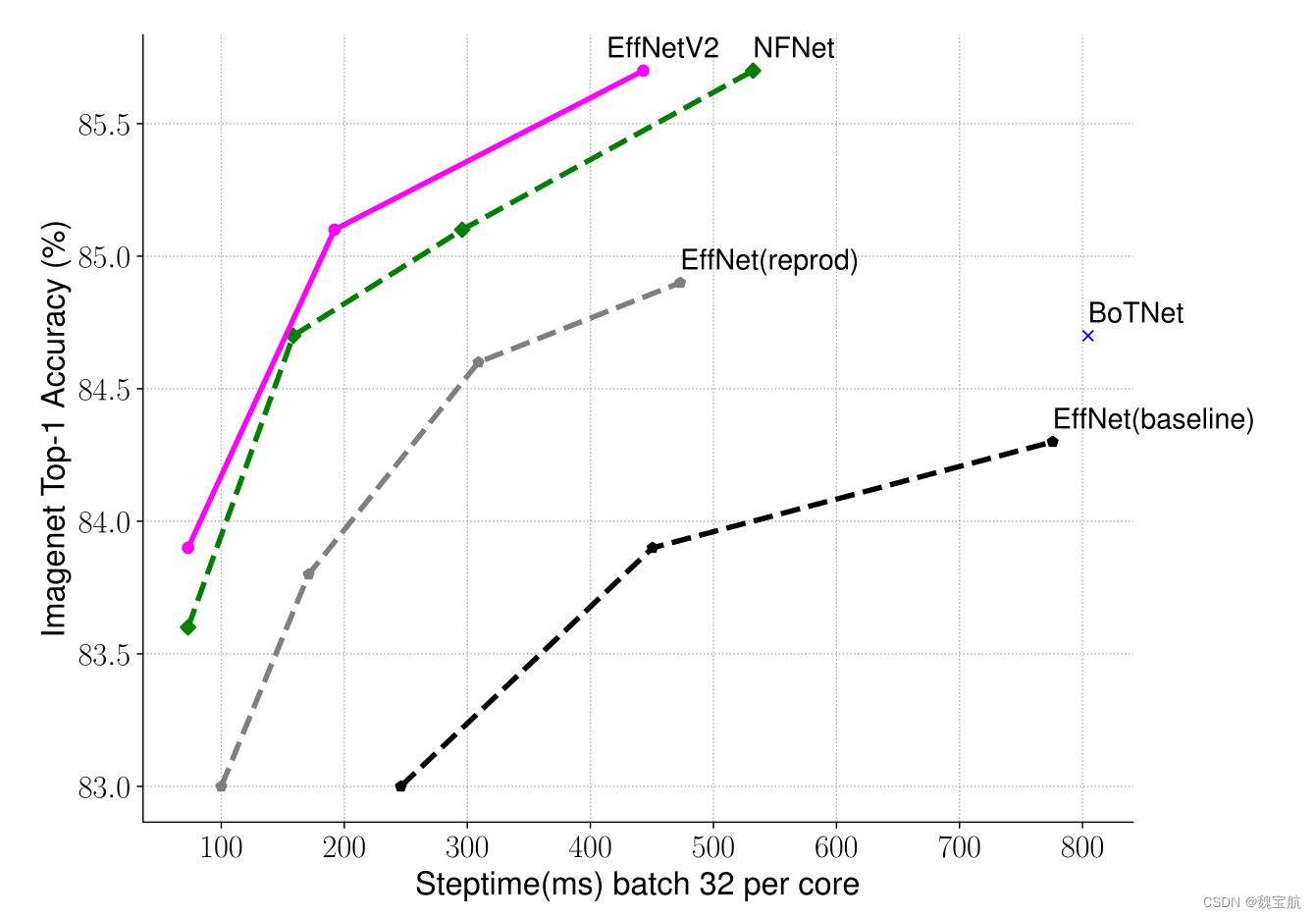
三、ImageNet上的EfficientNetV2性能结果
推断时间是在批次大小为16的V100 GPU FP16上使用相同的代码基测量的(Wightman,2021);训练时间是32个TPU核心标准化的总训练时间。标记为21k的模型在ImageNet21k上进行预训练,获得13M图像,其他模型则直接在ImageNet ILSVRC2012上进行训练,从零开始获得128M图像。所有EfficientNetV2模型都使用我们改进的渐进学习方法进行训练。
算法1总结了这个过程。在每个阶段开始时,网络将继承前一阶段的所有权重。与变压器不同,变压器的权重(例如位置嵌入)可能取决于输入长度,而净权重与图像大小无关,因此很容易继承。

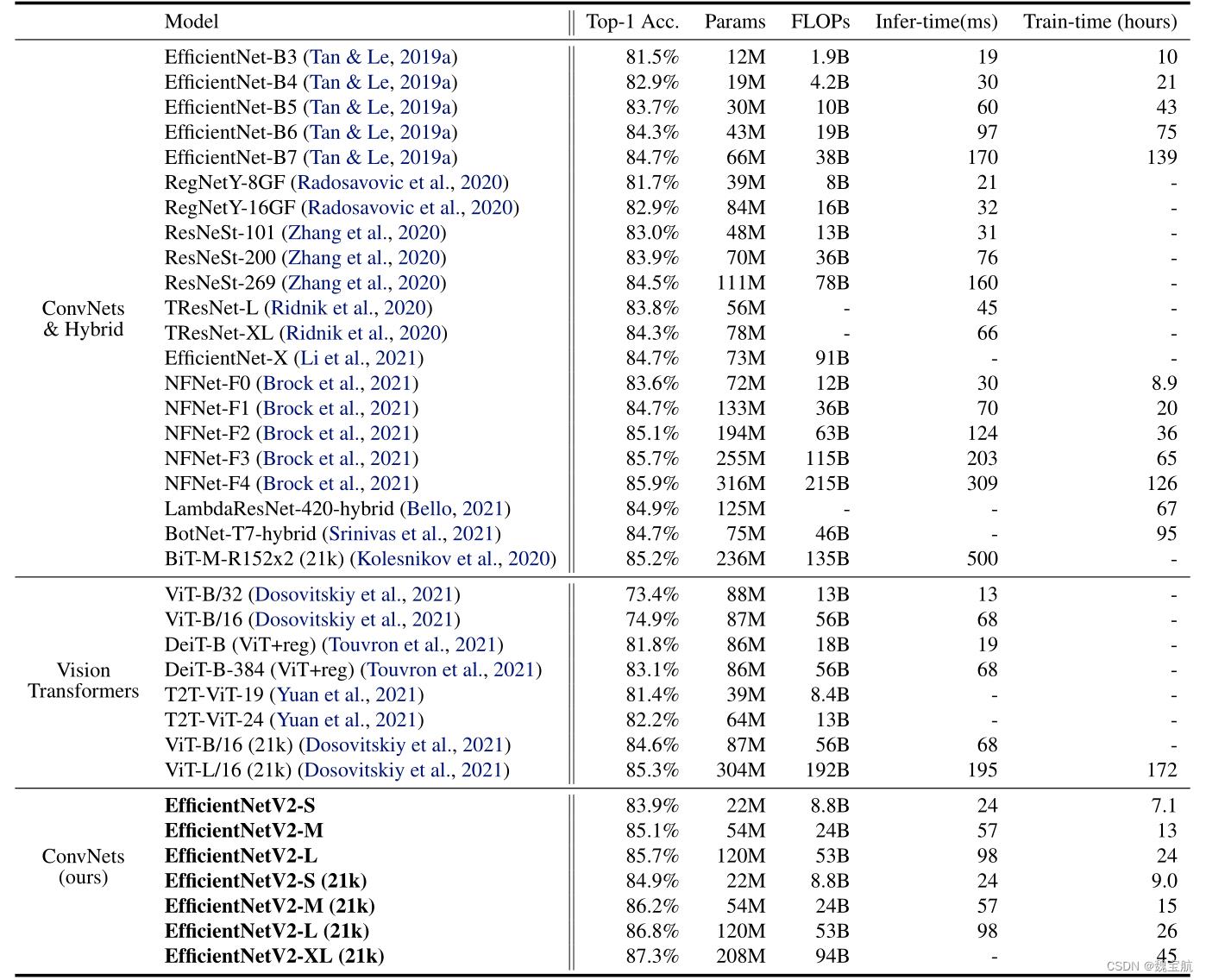
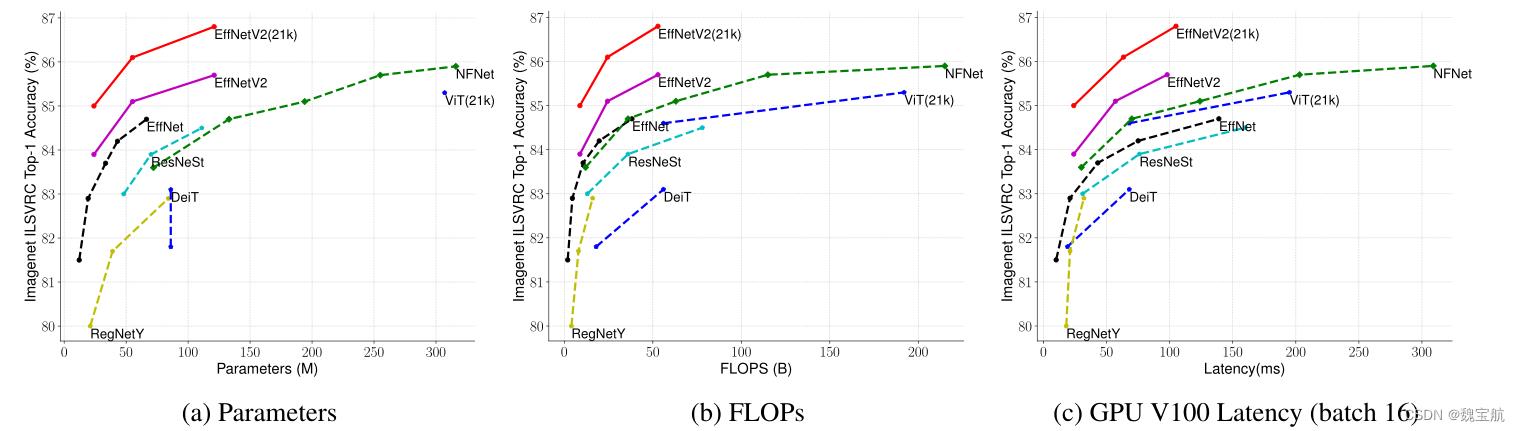
四、模型大小、失败次数和推断延迟
延迟在V100 GPU上以批量大小16进行测量。21k表示在ImageNet21k图像上进行了预训练,其他人只是在ImageNet ILSVRC2012上进行了训练。我们的EfficientNetV2在EfficientNet中的参数效率稍好一些,但推理速度要快3倍。
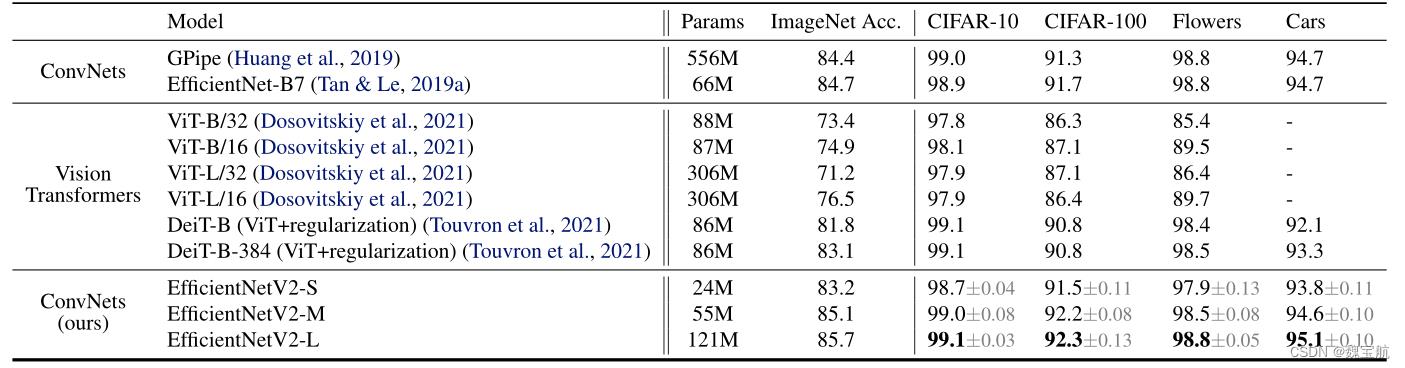
五、迁移学习绩效比较
所有模型都在ImageNet ILSVRC2012上进行了预训练,并在下游数据集上进行了微调。迁移学习的准确率平均为五次。
六、针对不同网络的渐进式学习
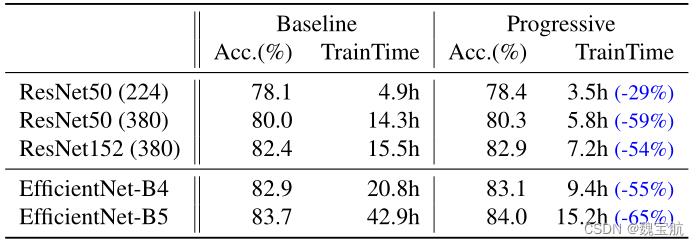
在不同的网络中消除了渐进式学习的表现。表12显示了渐进式培训和基线培训之间的性能比较,使用了相同的ResNet和EfficientNet模型。在这里,基线resnet比原始论文(He et al.,2016)具有更高的准确性,因为它们是使用改进的培训设置进行培训的,使用了更多的时间和更好的优化器。将resnet的图像大小从224增加到380,以进一步提高网络容量和准确性。
七、MindSpore复现EffcientV2-SNet
7.1 模型结构
"""
* Created with PyCharm
* 作者: 阿光
* 日期: 2021/8/8
* 时间: 22:27
* 描述:
"""
from collections import OrderedDict
from functools import partial
import mindspore.nn as nn
import mindspore.numpy as mnp
import mindspore.ops as ops
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
# random_tensor = keep_prob + Tensor(torch.rand(shape).numpy())
stdnormal = ops.StandardNormal(seed=1)
random_tensor = keep_prob + stdnormal(shape)
# random_tensor.floor_() # binarize
random_tensor = mnp.floor(random_tensor)
output = mnp.divide(x, keep_prob) * random_tensor
# output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Cell):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def construct(self, x):
return drop_path(x, self.drop_prob, self.training)
class ConvBNAct(nn.Cell):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer=None,
activation_layer=None):
super(ConvBNAct, self).__init__()
# self.activation=activation_layer
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU
self.conv = nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
# padding=padding,
group=groups,
has_bias=False)
self.bn = norm_layer(out_planes)
self.act = activation_layer()
def construct(self, x):
result = self.conv(x)
result = self.bn(result)
result = self.act(result)
return result
class SqueezeExcite(nn.Cell):
def __init__(self,
input_c: int,
expand_c: int,
se_ratio: float = 0.25):
super(SqueezeExcite, self).__init__()
squeeze_c = int(input_c * se_ratio)
self.conv_reduce = nn.Conv2d(expand_c, squeeze_c, 1, pad_mode='valid')
self.act1 = nn.ReLU()
self.conv_expand = nn.Conv2d(squeeze_c, expand_c, 1, pad_mode='valid')
self.act2 = nn.Sigmoid()
def construct(self, x):
scale = x.mean((2, 3), keep_dims=True)
scale = self.conv_reduce(scale)
scale = self.act1(scale)
scale = self.conv_expand(scale)
scale = self.act2(scale)
return scale * x
class MBConv(nn.Cell):
def __init__(self,
kernel_size: int,
input_c: int,
out_c: int,
expand_ratio: int,
stride: int,
se_ratio: float,
drop_rate: float,
norm_layer):
super(MBConv, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.has_shortcut = (stride == 1 and input_c == out_c)
activation_layer = nn.ReLU
expanded_c = input_c * expand_ratio
# 在EfficientNetV2中,MBConv中不存在expansion=1的情况所以conv_pw肯定存在
assert expand_ratio != 1
self.expand_conv = ConvBNAct(input_c,
expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)
self.dwconv = ConvBNAct(expanded_c,
expanded_c,
kernel_size=kernel_size,
stride=stride,
groups=expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)
# self.se = SqueezeExcite(input_c, expanded_c, se_ratio) if se_ratio > 0 else ops.Identity
self.se = SqueezeExcite(input_c, expanded_c, se_ratio) if se_ratio > 0 else None
self.project_conv = ConvBNAct(expanded_c,
out_planes=out_c,
kernel_size=1,
norm_layer=norm_layer,
# activation_layer=ops.Identity
) # 注意这里没有激活函数,所有传入Identity
self.out_channels = out_c
# 只有在使用shortcut连接时才使用dropout层
self.drop_rate = drop_rate
if self.has_shortcut and drop_rate > 0:
self.dropout = DropPath(drop_rate)
def construct(self, x):
result = self.expand_conv(x)
result = self.dwconv(result)
if self.se is not None:
result = self.se(result)
result = self.project_conv(result)
if self.has_shortcut:
if self.drop_rate > 0:
result = self.dropout(result)
result += x
return result
class FusedMBConv(nn.Cell):
def __init__(self,
kernel_size: int,
input_c: int,
out_c: int,
expand_ratio: int,
stride: int,
se_ratio: float,
drop_rate: float,
norm_layer):
super(FusedMBConv, self).__init__()
assert stride in [1, 2]
assert se_ratio == 0
self.has_shortcut = stride == 1 and input_c == out_c
self.drop_rate = drop_rate
self.has_expansion = expand_ratio != 1
activation_layer = nn.ReLU
expanded_c = input_c * expand_ratio
# 只有当expand ratio不等于1时才有expand conv
if self.has_expansion:
self.expand_conv = ConvBNAct(input_c,
expanded_c,
kernel_size=kernel_size,
stride=stride,
norm_layer=norm_layer,
activation_layer=activation_layer)
self.project_conv = ConvBNAct(expanded_c,
out_c,
kernel_size=1,
norm_layer=norm_layer,
# activation_layer=ops.Identity
) # 注意没有激活函数
else:
# 当只有project_conv时的情况
self.project_conv = ConvBNAct(input_c,
out_c,
kernel_size=kernel_size,
stride=stride,
norm_layer=norm_layer,
activation_layer=activation_layer) # 注意有激活函数
self.out_channels = out_c
# 只有在使用shortcut连接时才使用dropout层
self.drop_rate = drop_rate
if self.has_shortcut and drop_rate > 0:
self.dropout = DropPath(drop_rate)
def construct(self, x):
if self.has_expansion:
result = self.expand_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_rate > 0:
result = self.dropout(result)
result += x
return result
class EfficientNetV2(nn.Cell):
def __init__(self,
model_cnf: list,
num_classes: int = 1000,
num_features: int = 1280,
dropout_rate: float = 0.2,
drop_connect_rate: float = 0.2):
super(EfficientNetV2, self).__init__()
for cnf in model_cnf:
assert len(cnf) == 8
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
stem_filter_num = model_cnf[0][4]
self.stem = ConvBNAct(3,
stem_filter_num,
kernel_size=3,
stride=2,
norm_layer=norm_layer) # 激活函数默认是SiLU
total_blocks = sum([i[0] for i in model_cnf])
block_id = 0
blocks = []
for cnf in model_cnf:
repeats = cnf[0]
op = FusedMBConv if cnf[-2] == 0 else MBConv
for i in range(repeats):
blocks.append(op(kernel_size=cnf[1],
input_c=cnf[4] if i == 0 else cnf[5],
out_c=cnf[5],
expand_ratio=cnf[3],
stride=cnf[2] if i == 0 else 1,
se_ratio=cnf[-1],
drop_rate=drop_connect_rate * block_id / total_blocks,
norm_layer=norm_layer))
block_id += 1
self.blocks = nn.SequentialCell(*blocks)
head_input_c = model_cnf[-1][-3]
head = OrderedDict()
head.update("project_conv": ConvBNAct(head_input_c,
num_features,
kernel_size=1,
norm_layer=norm_layer)) # 激活函数默认是SiLU
# self.adaptive=ops.AdaptiveAvgPool2D((None,1))
# head.update("avgpool": ops.AdaptiveAvgPool2D(None,1))
head.update("flatten": nn.Flatten())
if dropout_rate > 0:
head.update("dropout": nn.Dropout(keep_prob=dropout_rate))
head.update("classifier": nn.Dense(num_features, num_classes))
self.head = nn.SequentialCell(head)
self.avgpool = nn.AvgPool2d(kernel_size=(10, 12), pad_mode='valid')
# # initial weights
# for m in self.modules():
# if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode="fan_out")
# if m.bias is not None:
# nn.init.zeros_(m.bias)
# elif isinstance(m, nn.BatchNorm2d):
# nn.init.ones_(m.weight)
# nn.init.zeros_(m.bias)
# elif isinstance(m, nn.Linear):
# nn.init.normal_(m.weight, 0, 0.01)
# nn.init.zeros_(m.bias)
def construct(self, x):
x = self.stem(x)
x = self.blocks(x)
x = self.avgpool(x)
# x = self.adaptive(x)
x = self.head(x)
return x
def efficientnetv2_s(num_classes: int = 1000):
model_config