带你整理面试过程中关于Innodb的相关知识点
Posted 南淮北安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你整理面试过程中关于Innodb的相关知识点相关的知识,希望对你有一定的参考价值。
文章目录
一、存储引擎
数据库的存储引擎是数据库的底层软件组织,数据库管理系统(DBMS)使用存储引擎创建、查询、更新和删除数据。不同的存储引擎提供了不同的存储机制、索引技巧、锁定水平等功能,都有其特定的功能。现在,许多数据库管理系统都支持多种存储引擎,常用的存储引擎主要有MyISAM、InnoDB、Memory、Archive和Federated。
二、InnoDB
InnoDB为mysql提供了事务(Transaction)支持、回滚(Rollback)、崩溃修复能力(Crash Recovery Capabilities)、多版本并发控制(Multi-versionedConcurrency Control)、事务安全(Transaction-safe)的操作。
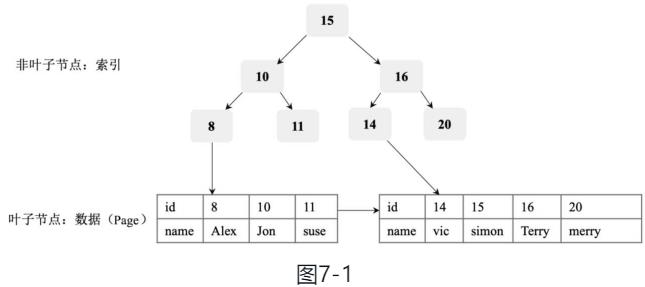
InnoDB的底层存储结构为B+树,B+树的每个节点都对应InnoDB的一个Page, Page大小是固定的,一般被设为16KB。其中,非叶子节点只有键值,叶子节点包含完整的数据。
InnoDB适用于有以下需求的场景:
经常有数据更新的表,适合处理多重并发更新请求。
支持事务。
支持灾难恢复(通过bin-log日志等)。
支持外键约束,只有InnoDB支持外键。
支持自动增加列属性 auto_increment。
三、InnoDB 的本质
1. 数据是如何存储的?
InnoDB行格式:一条数据是如何存储的
InnoDB定义了4中行格式:COMPACT行格式,Redundant行格式,Dynamic和Compressed行格式。这些行格式大同小异,都是用来便捷的表示一行数据。我们以COMPACT行格式为例。
在COMPACT行格式中,一条数据包括两部分信息:记录的额外信息和记录的真实数据
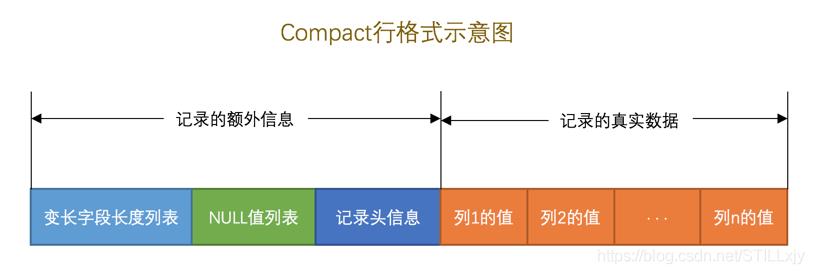
记录的真实数据就是我们插入的记录的每一列的数据,额外信息包括:
(1)变长字段长度列表:若某一个字段(列)的数据类型的长度数可变的,则记录它的真实长度值(字节数)。
(2)NULL值列表:若某一个字段(列)的数据可以为NULL,则用一个位表示它是否为NULL。
(3)记录头信息
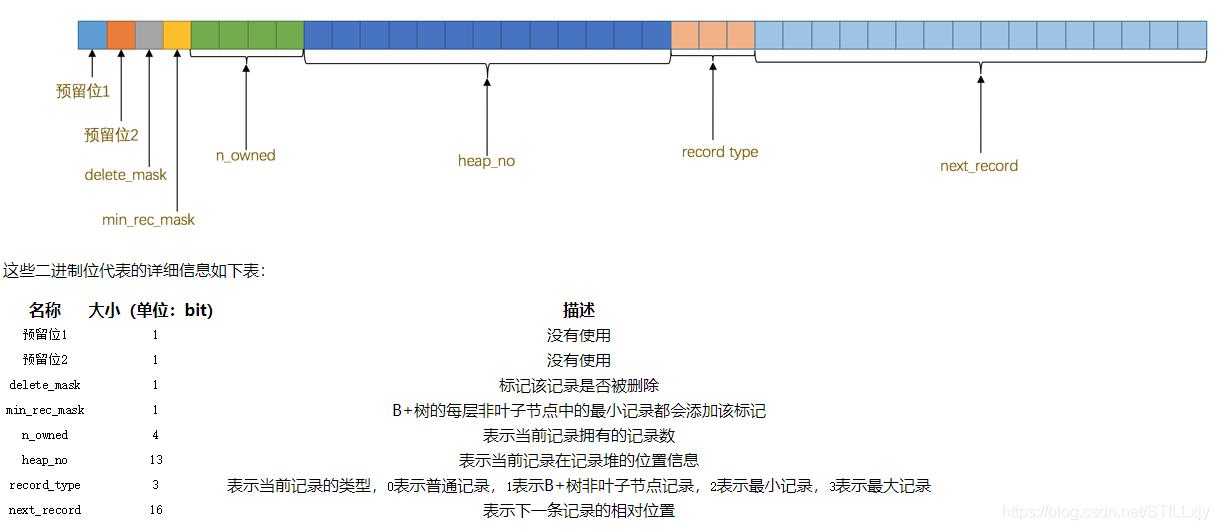
其中比较重要的有:
delete_mask:标记该数据是否被删除
n_owned:表示一组中有多少条记录(后面会说到组的概念)
record_type:该记录的类型
next_recod:下一条记录的相对位置,可以理解为指向下一条记录的指针
2. 页:InnoDB 管理存储空间的基本单位
当我们选用InnoDB作为数据库表的引擎时,我们创建表并向表中插入一些数据后,当我们关闭数据库,再打开,我们的数据是不会丢失的。这是因为MySql将我们的数据存储在了本地的文件系统中,可以进行持久化的保存。
而在进行数据库的操作时,我们对数据的增删改查操作都需要在内存中进行,所以我们首先需要将数据加载进内存,然后在将修改后的数据刷新到磁盘(文件)。在这个数据交互的过程中,数据量的最小单位为 页,一页的大小一般是16KB。
它也是InnoDB管理存储空间的基本单位。我们插入的数据都存放在一个一个的页中
InnoDB数据页代表的16KB大小的存储空间被划分为多个部分:
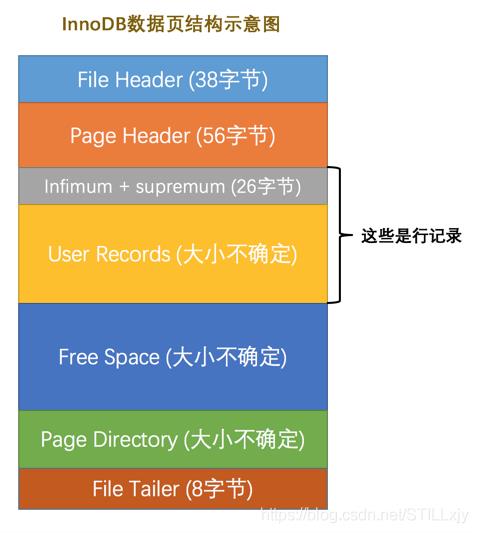
各个部分的功能如下:
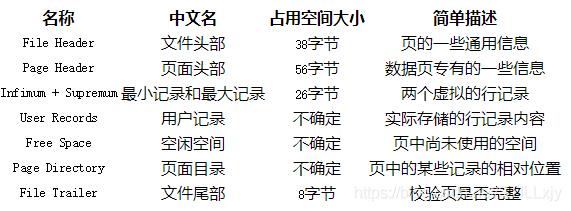
Infimum + supremum + User Records 是 页中的行记录, Infimum 和 supremum 行记录是系统创建的 最小记录行 和 最大记录行(类似于头结点和尾节点)。
行记录在页中是按照主键从大到小的顺序排列的,所以我们可以将页中的行记录看成是一个按照主键从小到大的顺序形成的单链表
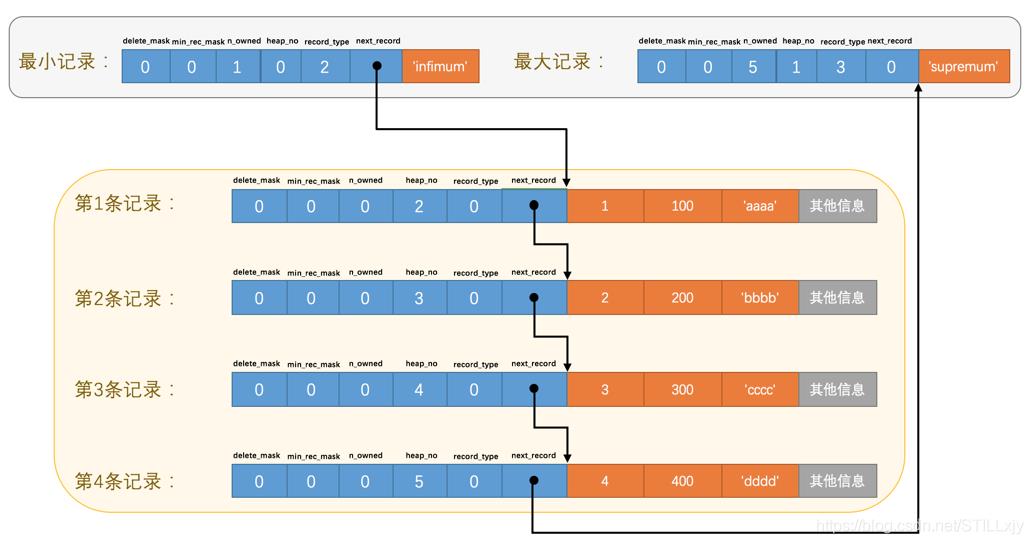
3. 页目录:Page Directory
当我们在递增的单链表中查找某条记录时,我们任然需要重头遍历一遍链表,速度很慢。那么我们如何才能对递增的单链表进行快速的查找呢? 单链表虽然是有序的但是由于地址空间不是连续的,因此无法进行二分查找。
我们可以将单链表上的记录分为若干组,将每组主键的最大值记录的偏移量(槽)提取出来,放在一个数组中。因此它们然后是有序的,所以我们可以在这个数组上进行二分查找,快速的找到我们需要的组。而这个数组就是 Page Directory 页目录
但表中有更多的数据后,它的结构如下:
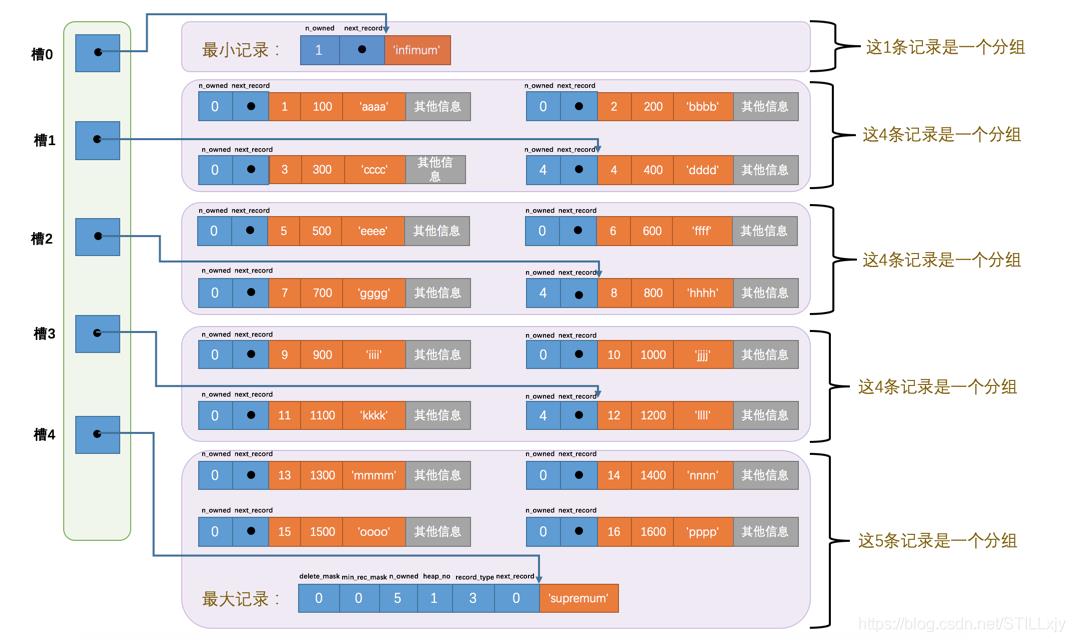
所以在一个数据页中查找指定主键值的记录的过程分为两步:
(1)通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录。
(2)通过记录的next_record属性遍历该槽所在的组中的各个记录。
4. 引入 B+ 树:索引
在实际开发过程中,我们数据表中的数据是非常非常多的,会被记录在很多的页中。这些页按照主键的递增排列,组成一个双向链表。如下图:橙色是主键字段,蓝色和红色是非主键字段。

因为这些16KB的页在物理存储上可能并不挨着,所以如果想从这么多页中根据主键值快速定位某些记录所在的页,我们需要给它们做个目录,每个页对应一个目录项,每个目录项包括下边两个部分:
(1)页的用户记录中最小的主键值,我们用key来表示
(2)页号,我们用page_no表示
所以我们为上边几个页做好的目录就像这样子:
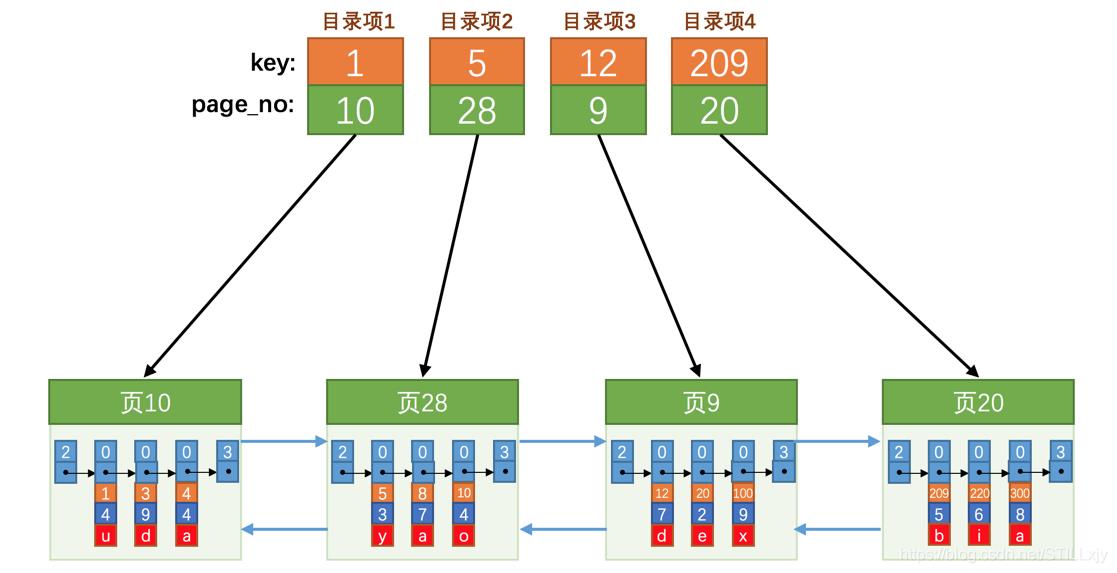
这个目录其实就是索引。InnoDB索引也是被存在页中的行记录,只是它的头信息的 record_type = 1。
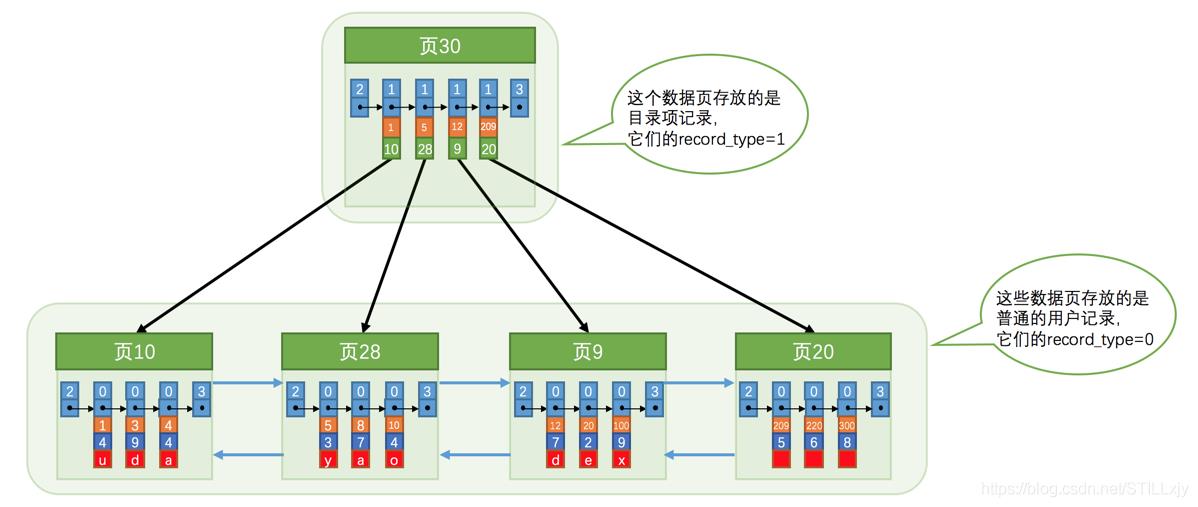
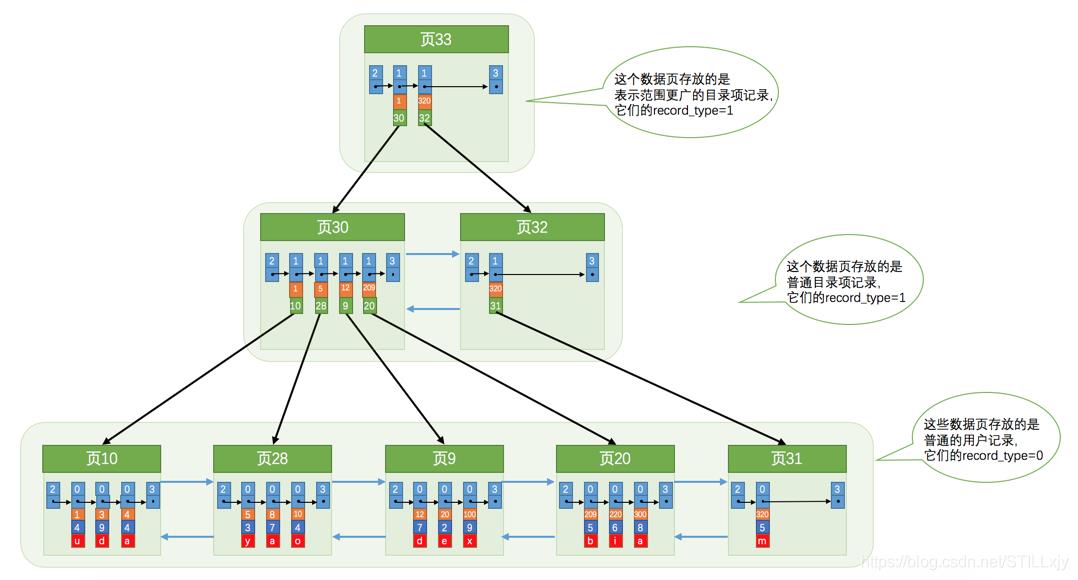
当数据非常非常多时,往往一层索引是不够的,最终会形成多层索引。最上层的索引页就是B+树的根节点,通过不断往上抽取,最上层的页节点一定为1。
根据主键信息,在索引中快速查询数据的过程:
(1)在根节点(页)中利用 页目录 信息,二分查找找到满足条件组,在组内链表上遍历找到满足条件的行记录。若行记录 record_type = 1表示行记录是目录记录,在根据该行记录的 页号 找到下层对应的页。
(2)在页中进行1 同样的操作,直到 record_type = 0,表示到达了叶子节点, 页中行记录为用户记录。
(3)在页节点页中利用页目录信息,二分查找找到满足条件组,在组内链表上遍历找到满足条件的行记录。
例子:我们在下面例子中找主键为20的记录,假设组的大小为1。
(1)首先在根节点(页30)中利用 页目录信息二分查找,找到主键值小于等于20的最大记录,即“1 1 30”的记录。record_type = 1 继续向下。
(2)在页30 中找到主键值小于等于20的最大记录,即“1 12 9”的记录。record_type = 1 继续向下。
(3)在页 9 中找到主键值小于等于20的最大记录,即“0 20 2 e”的记录。record_type = 0 已经到达叶子节点, 页找到了我们需要的记录。
四、面试题
- innodb数据库的查询流程
(1)首先在根节点页根据页目录信息,二分查找满足条件的组,在组内链表上遍历找到满足条件的行记录。如果行记录 record_type =1,表示这个行记录是目录记录,根据行记录的页号找到下层对应的页
(2)在页中进行和(1)同样的操作,直到 record_type=0,表示到达了叶子节点,页中行记录即为用户记录。
(3)在页节点中利用页目录信息,二分查找找到满足条件组,在组内链表上遍历找到满足条件的行记录
 创作打卡挑战赛
创作打卡挑战赛
 赢取流量/现金/CSDN周边激励大奖
赢取流量/现金/CSDN周边激励大奖
以上是关于带你整理面试过程中关于Innodb的相关知识点的主要内容,如果未能解决你的问题,请参考以下文章