Redis 基础 -- HyperLogLog概率算法(计算集合的近似基数)和HyperLogLog的常用命令
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis 基础 -- HyperLogLog概率算法(计算集合的近似基数)和HyperLogLog的常用命令相关的知识,希望对你有一定的参考价值。
文章目录
1. HyperLogLog
HyperLogLog是一个专门为了计算集合的基数而创建的概率算法,对于一个给定的集合,HyperLogLog可以计算出这个集合的近似基数:近似基数并非集合的实际基数,它可能会比实际的基数小一点或者大一点,但是估算基数和实际基数之间的误差会处于一个合理的范围之内,因此那些不需要知道实际基数或者因为条件限制而无法计算出实际基数的程序就可以把这个近似基数当作集合的基数来使用。
HyperLogLog的优点在于它计算近似基数所需的内存并不会因为集合的大小而改变,无论集合包含的元素有多少个,HyperLogLog进行计算所需的内存总是固定的,并且是非常少的。具体到实现上,Redis的每个HyperLogLog只需要使用12KB内存空间,就可以对接近:2⁶⁴个元素进行计数,而算法的标准误差仅为0.81%,因此它计算出的近似基数是相当可信的。
1.1 PFADD:对集合元素进行计数
用户可以通过执行PFADD命令,使用HyperLogLog对给定的一个或多个集合元素进行计数。
语法:
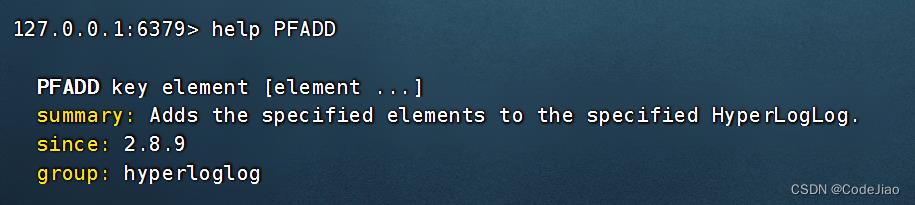
根据给定的元素是否已经进行过计数,PFADD命令可能返回0,也可能返回1:
- 如果给定的所有元素都已经进行过计数,那么PFADD命令将返回0,表示HyperLog-Log计算出的近似基数没有发生变化。
- 如果给定的元素中出现了至少一个之前没有进行过计数的元素,导致HyperLogLog计算出的近似基数发生了变化,那么PFADD命令将返回1。
示例:
通过执行以下命令,我们可以使用alphabets这个HyperLogLog对"a"、“b”、“c"这3个元素进行计数:
 因为这是alphabets第一次对元素"a”、“b”、"c"进行计数,所以alphabets计算的近似基数将发生变化,并使PFADD命令返回1。
因为这是alphabets第一次对元素"a”、“b”、"c"进行计数,所以alphabets计算的近似基数将发生变化,并使PFADD命令返回1。
但是如果我们再次要求alphabets对元素"a"进行计数,那么这次PFADD命令将返回0,这是因为已经计数过的元素"a"并不会对alphabets计算的近似基数产生影响:

说明:
复杂度:O(N),其中N为用户给定的元素数量。
1.2 PFCOUNT:返回集合的近似基数
在使用PFADD命令对元素进行计数之后,用户可以通过执行PFCOUNT命令来获取HyperLogLog为集合计算出的近似基数。
语法:

示例:
通过执行以下命令,我们可以获取到alphabets这个HyperLogLog计算出的近似基数:

另外,当用户给定的HyperLogLog不存在时,PFCOUNT命令将返回0作为结果:

1.2.1 返回并集的近似基数
当用户向PFCOUNT传入多个HyperLogLog时,PFCOUNT命令将对所有给定的Hyper-LogLog执行并集计算,然后返回并集HyperLogLog计算出的近似基数。
比如,我们可以创建两个HyperLogLog,并分别使用这两个HyperLogLog去对两组数字进行计数:

然后使用以下PFCOUNT命令获取这两个HyperLogLog进行并集计算之后得出的近似基数:

对多个HyperLogLog执行并集计算的效果与多个集合首先执行并集计算,然后再使用HyperLogLog去计算并集集合的近似基数的效果类似。比如,上面的PFCOUNT命令就类似于以下这两条命令:

1.2.2 时间复杂度说明
复杂度:O(N),其中N为用户给定的HyperLogLog数量。
1.3 PFMERGE:计算多个HyperLogLog的并集
PFMERGE命令可以对多个给定的HyperLogLog执行并集计算,然后把计算得出的并集HyperLogLog保存到指定的键中。
语法:
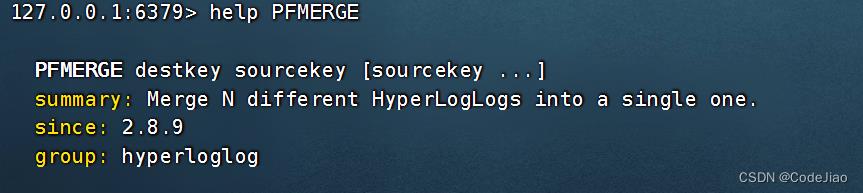
如果指定的键已经存在,那么PFMERGE命令将覆盖已有的键。PFMERGE命令在成功执行并集计算之后将返回OK作为结果。
示例:
以下代码展示了如何使用PFMERGE计算nums1、nums2和nums3这3个HyperLogLog的并集,并将其存储到union-numbers键中:

1.3.1 PFCOUNT与PFMERGE
PFCOUNT命令在计算多个HyperLogLog的近似基数时会执行以下操作:
- 在内部调用PFMERGE命令,计算所有给定HyperLogLog的并集,并将这个并集存储到一个临时的HyperLogLog中。
- 对临时HyperLogLog执行PFCOUNT命令,得到它的近似基数(因为这是针对单个HyperLogLog的PFCOUNT,所以这个操作不会引起循环调用)。
- 删除临时HyperLogLog。
- 向用户返回之前得到的近似基数。
举个例子,当我们执行以下命令的时候:

PFCOUNT将执行以下以下操作:
- 执行PFMERGE
<temp-hyperloglog>numbers1 numbers2 numbers3,把3个给定HyperLogLog的并集结果存储到临时HyperLogLog中。 - 执行PFCOUNT
<temp-hyperloglog>,取得并集HyperLogLog的近似基数4。 - 执行DEL
<temp-hyperloglog>,删除临时HyperLogLog。 - 向用户返回之前得到的近似基数4。
基于上述原因,当程序需要对多个HyperLogLog调用PFCOUNT命令,并且这个调用可能会重复执行多次时,我们可以考虑把这一调用替换成相应的PFMERGE命令调用:通过把并集的计算结果存储到指定的HyperLogLog中而不是每次都重新计算并集,程序可以最大程度地减少不必要的并集计算。
1.3.2 时间复杂度说明
复杂度:O(N),其中N为用户给定的HyperLogLog数量。
1.4 小结
- HyperLogLog是一个概率算法,它可以对大量元素进行计数,并计算出这些元素的近似基数。
- 无论被计数的元素有多少个,HyperLogLog只使用固定大小的内存,其内存占用不会因为被计数元素增多而增多。
- 在有需要的情况下,用户可以使用PFMERGE命令代替针对多个HyperLogLog的PFCOUNT命令调用,从而避免重复执行相同的并集计算。
- HyperLogLog不仅可以用于计数问题,还可以用于去重问题。
以上是关于Redis 基础 -- HyperLogLog概率算法(计算集合的近似基数)和HyperLogLog的常用命令的主要内容,如果未能解决你的问题,请参考以下文章