二次开发Spark实现JDBC读取远程租户集群Hive数据并落地到本集群Hive的Hive2Hive数据集成Java
Posted 虎鲸不是鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二次开发Spark实现JDBC读取远程租户集群Hive数据并落地到本集群Hive的Hive2Hive数据集成Java相关的知识,希望对你有一定的参考价值。
背景
肤浅的SQL Boy们可能只知道pyspark构建出sparkSession对象【当然要enableHiveSupport】后,写一句SQL:
spark.sql(“这里写一句SQL字符串”);
然后spark就会根据此处的SQL,完成各种select查数据、insert overwrite灌数据到结果表的种种操作。对SQL Boy们来说,足够用了,毕竟搞数仓和ETL的可能只会SQL也只用得到SQL。
但是平台开发,这种程度显然是不够的。例如最常见的数据集成、数据入湖,一定会涉及跨集群、多集群、跨Kerberos域等问题。处理异构数据源的数据时,SQL还是很乏力的,举个栗子,我肯定是不能写一句SQL就把HDFS文件块的数据处理后写入FTP服务器。
正常的数据集成一般是Spark读取本集群Hive数据,推送到远程租户集群的Hive,但是CDP版本的Spark会自动根据集群配置文件读取数据,这种“方便”也就导致了想要读取远程集群Hive数据时有很多不便。本文就是为了解决这个问题。
原理分析
不要以为Java和pyspark可以构建多个sparkSession对象,编译前Idea不会报错,就可以构建多个sparkSession对象连接多个Hive。
Spark Session对象在全生命周期只能设置一个Thrift Server链接,换句话说,这种方式Spark Session只能同时连接一个Hive,不能跨集群读写Hive。
考虑到Hive有JDBC访问mysql的方式,尝试JDBC方式读写Hive。但是遇到了一些问题,扒源码,JdbcDialects.scala中找到:
package org.apache.spark.sql.jdbc
//222行
package org.apache.spark.sql.jdbc
#222行附近
/**
* :: DeveloperApi ::
* Registry of dialects that apply to every new jdbc `org.apache.spark.sql.DataFrame`.
*
* If multiple matching dialects are registered then all matching ones will be
* tried in reverse order. A user-added dialect will thus be applied first,
* overwriting the defaults.
*
* @note All new dialects are applied to new jdbc DataFrames only. Make
* sure to register your dialects first.
*/
@DeveloperApi
@InterfaceStability.Evolving
object JdbcDialects
/**
* Register a dialect for use on all new matching jdbc `org.apache.spark.sql.DataFrame`.
* Reading an existing dialect will cause a move-to-front.
*
* @param dialect The new dialect.
*/
def registerDialect(dialect: JdbcDialect) : Unit =
dialects = dialect :: dialects.filterNot(_ == dialect)
/**
* Unregister a dialect. Does nothing if the dialect is not registered.
*
* @param dialect The jdbc dialect.
*/
def unregisterDialect(dialect : JdbcDialect) : Unit =
dialects = dialects.filterNot(_ == dialect)
private[this] var dialects = List[JdbcDialect]()
registerDialect(MySQLDialect)
registerDialect(PostgresDialect)
registerDialect(DB2Dialect)
registerDialect(MsSqlServerDialect)
registerDialect(DerbyDialect)
registerDialect(OracleDialect)
registerDialect(TeradataDialect)
/**
* Fetch the JdbcDialect class corresponding to a given database url.
*/
def get(url: String): JdbcDialect =
val matchingDialects = dialects.filter(_.canHandle(url))
matchingDialects.length match
case 0 => NoopDialect
case 1 => matchingDialects.head
case _ => new AggregatedDialect(matchingDialects)
Spark的JDBC原生支持MySQL和SQL Server等7种DB,居然不支持Hive!!!那么,想要让Spark支持JDBC方式访问Hive、Kylin、Druid、Doris、ClickHouse这类组件,就要二开,自行实现相关功能。
二开Spark
Scala的解决方式:
case object HiveSqlDialect extends JdbcDialect
override def canHandle(url: String): Boolean = url.startsWith("jdbc:hive2")
override def quoteIdentifier(colName: String): String = colName.split('.').map(part => s"`$part`").mkString(".")
class RegisterHiveSqlDialect
def register(): Unit =
JdbcDialects.registerDialect(HiveSqlDialect)
但是,Scala在2018年可能还很流行,2020年用的人已经不多了,为了少出问题,使用Java方式重构:
package com.zhiyong.Hive2Hive;
import org.apache.spark.sql.jdbc.JdbcDialect;
public class HiveDialect extends JdbcDialect
@Override
public boolean canHandle(String url)
return url.startsWith("jdbc:hive2");
@Override
public String quoteIdentifier(String colName)
//需要返回colName.split('.').map(part => s"`$part`").mkString(".")
String[] split1 = colName.split("\\\\.");//先切分字符串
String[] split2 = new String[split1.length];
StringBuilder strb = new StringBuilder();
String result = null;
int index = 0;
//调用map映射读取到值
for (String part : split1)
//split2[index] = "`$" + part + "`";
split2[index] = "`" + part + "`";
index++;
//使用.拼接字符串
for (int i = 0; i < split2.length; i++)
String cell = split2[i];
if (i != 0) strb.append(".");
strb.append(cell);
result = strb.toString();
return result; //返回String str= colName.split(".").map(part => s"`$part`").mkString(".");
二开之后,在主类中即可使用:
JdbcDialect hiveDialect = new HiveDialect();
JdbcDialects.registerDialect(hiveDialect);//重编码,防止报错
Map<String, String> sourceMap = new LinkedHashMap<>();
sourceMap.put("url", "jdbc:hive2://192.168.88.11:10000");
sourceMap.put("driver", "org.apache.hive.jdbc.HiveDriver");
sourceMap.put("user", "root"); sourceMap.put("password", "123456");
sourceMap.put("dbtable", "aaa.test1");
SparkSession sc = SparkSession.builder()
.appName("aaaaa")
.master("local[*]")
.enableHiveSupport() //这里只是连接到了本集群的Hive
.getOrCreate();
Dataset<Row> jdbcReadDF = sc.read()
.format("jdbc")
.options(sourceMap)
.load();//使用JDBC读取到hive的数据
即可走JDBC读到Hive的数据。
测试效果
经测试,在云桌面也可以过Kerberos认证并且拿到数据。这种方式拿
到的DF表头有问题(自带了表名):

标准的Spark SQL(或者DSL方式)拿到的表头长这样:
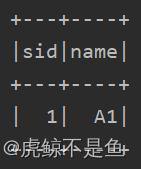
解决表头的问题
表头不同当然是没办法写数据的。
好在Spark有办法更换表头:
Map<String, String> targetSource = new LinkedHashMap<>();
targetSource.put("url", "jdbc:hive2://192.168.88.11:10000");
targetSource.put("driver", "org.apache.hive.jdbc.HiveDriver");
targetSource.put("user", "root");
targetSource.put("password", "123456");
targetSource.put("dbtable", "aaa.test4");
Dataset<Row> jdbcReadDF2 = sc.read()
.format("jdbc")
.options(targetSource)
.load();//使用JDBC读取到目标hive 的数据(用于获取表头)
Dataset<Row> proDF2 = sc
.createDataFrame(jdbcReadDF.rdd(), jdbcReadDF2.schema());//更换表头
再次走JDBC的方式读表,由于2个表结构相同,拿到的表头可以直接替换旧的DataFrame。那么直接spark.sql(“select * from db1.tb1 limit1”)的方式也可以拿到表头,这个问题就解决啦。
JDBC写入失败的问题
但是更换表头后,依旧不能以JDBC方式写入:
jdbcReadDF.write()
.format("jdbc")
.options(targetSource)
//.mode(SaveMode.Append)//不能有这行,会报错method not support
.save();
众所周知,mode共有4种,不设置默认调用的是已存在就报错(遇到的就是这种情况),还有ignore忽略且不处理,这2种都没什么用。但是切换成append或者overwrite模式后直接报错method not support。就很诡异。
不写mode时:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Table or view 'aaa.test4' already exists. SaveMode: ErrorIfExists.;
在JdbcRelationProvider.scala中:
package org.apache.spark.sql.execution.datasources.jdbc
#71行附近
case SaveMode.ErrorIfExists =>
throw new AnalysisException(
s"Table or view '$options.table' already exists. " +
s"SaveMode: ErrorIfExists.")
肯定是不能用默认模式。
使用.mode(SaveMode.Overwrite)后:目标表删没了(beeline中看到的),还会报错:
Exception in thread "main" org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: FAILED: ParseException line 1:31 cannot recognize input near '.' 'sid' 'INTEGER' in column type
at org.apache.hive.jdbc.Utils.verifySuccess(Utils.java:264)
at org.apache.hive.jdbc.Utils.verifySuccessWithInfo(Utils.java:250)
at org.apache.hive.jdbc.HiveStatement.runAsyncOnServer(HiveStatement.java:309)
at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:250)
at org.apache.hive.jdbc.HiveStatement.executeUpdate(HiveStatement.java:448)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.createTable(JdbcUtils.scala:863)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:62)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:83)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:81)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:80)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:127)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:75)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at com.zhiyong.Hive2Hive.Hive2HiveJDBCDemo.main(Hive2HiveJDBCDemo.java:133)
Caused by: org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: FAILED: ParseException line 1:31 cannot recognize input near '.' 'sid' 'INTEGER' in column type
at org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:387)
at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:186)
at org.apache.hive.service.cli.operation.SQLOperation.runInternal(SQLOperation.java:269)
at org.apache.hive.service.cli.operation.Operation.run(Operation.java:324)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementInternal(HiveSessionImpl.java:460)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementAsync(HiveSessionImpl.java:447)
at sun.reflect.GeneratedMethodAccessor11.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:78)
at org.apache.hive.service.cli.session.HiveSessionProxy.access$000(HiveSessionProxy.java:36)
at org.apache.hive.service.cli.session.HiveSessionProxy$1.run(HiveSessionProxy.java:63)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:59)
at com.sun.proxy.$Proxy33.executeStatementAsync(Unknown Source)
at org.apache.hive.service.cli.CLIService.executeStatementAsync(CLIService.java:294)
at org.apache.hive.service.cli.thrift.ThriftCLIService.ExecuteStatement(ThriftCLIService.java:497)
at org.apache.hive.以上是关于二次开发Spark实现JDBC读取远程租户集群Hive数据并落地到本集群Hive的Hive2Hive数据集成Java的主要内容,如果未能解决你的问题,请参考以下文章