RDD的处理过程
Posted 鄙人阿彬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RDD的处理过程相关的知识,希望对你有一定的参考价值。
Spark用scala语言实现了RDD的API,程序开发者可以通过调用API对RDD进行操作处理。
下图为RDD的处理过程:
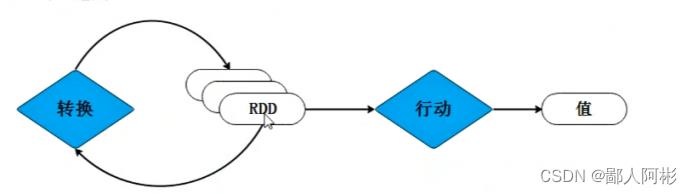
RDD经过一些列的“转换”操作,每一次转换都会产生不同的RDD,以供给下一次“转换”操作使用,直到最后一个RDD经过“行动”操作才会被真正计算处理,并输出到外部数据源中,若中间的数据结果需要复用,则可以进行缓存处理,将数据缓存到内存中。需要注意的是,RDD采用了惰性调用,即在RDD的处理过程中,真正的计算发生在 RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹(即RDD相互之间的依赖关系),而不会触发真正的计算处理。
接下来。将对“转换”操作和“行动”操作进行详细地讲解。
1.转换算子:
RDD处理过程中的“转换”操作主要用于根据已有的RDD创建新的RDD,每一次通过Transformation算子计算后都会返回一个新RDD,供给下一个转换算子使用。
(1)filter(func)
filter(func)操作会筛选处满足函数func的元素,并返回一个新的数据集。
从test.txt文件中加载数据的方式创建RDD,通过filter操作筛选出含Spark的数据,并组成一个新的RDD。
val lines = sc.textFile("file:///opt/test.txt") (注:路径自己创建即可。)
val lineWithSpark = lines.filter(line=>line.contains("spark"))
示例:

(2)map(func)
map(func)操作将每个元素传递到函数func中,并返回一个新的数据集。
示例:从test.txt文件中加载数据的方式创建RDD,通过map操作将文件的每一行内容都拆成一个个单词元素,并组成一个新的RDD。
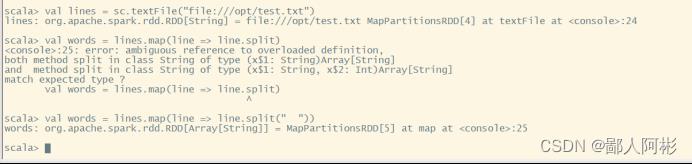
val lines = sc.textFile("file:///opt/test.txt")
val words = lines.map(line=>line.split(" "))
(3)flatMap(func)
flatMap(func)与map(func)相似,但每个输入的元素都可以映射到0或者多个输出的结果。
示例:从test.txt文件中加载数据的方式创建RDD,通过flatmap操作将文件的每一行内容都拆成一个个单词元素,并组成一个新的RDD。
val lines = sc.textFile("file:///opt/test.txt")
val words = lines.flatMap(line=>line.split(" "))

(4)groupByKey(func)
groupByKey(func)主要用于(Key,Value)键值对的数据集,将用有相同的Key的Value进行分组,返回一个新的(Key,Iterable)形式的数据集。
示例:从test.txt文件中加载数据的方式创建RDD,通过groupByKey操作把(Key,Value)键值对类型的RDD按单词出现次数进行分组,并组成一个新的RDD。
val lines = sc.textFile("file:///opt/test.txt")
val words = lines.flatMap(line=>line.split(" "))
words.collect
val groupWords = words.groupByKey()
groupWords.collect


(5)reduceByKey
reduceByKey()主要用于键值对的数据集,返回的是一个新的形式数据集,该数据集是每个Key传递给函数func进行聚合运算后得到的结果。

2 、行动算子
行动算子主要是将在数据集上运行计算后的数值返回到驱动程序,从而触发真正的计算。
(1)count():
count()主要用于返回数据集中的元素个数
示例:有一个arrRdd需要统计arrRdd元素个数
val arrRdd = sc.parallelize(Array(1,2,3,4,5))
arrRdd.count()

(2)first()
first()主要用于返回数组的第一个元素
示例:有一个arrRdd需要获取arrRdd第一个元素
val arrRdd = sc.parallelize(Array(1,2,3,4,5))
arrRdd.first()

(3)take(n)
take(n)主要用于以数组的形式返回数组集中的前n个元素(闭区间)
示例:有一个arrRdd需要获取arrRdd前3个元素
val arrRdd = sc.parallelize(Array(1,2,3,4,5))
arrRdd.take(3)

(4)reduce(func)
reduce(func)主要用于通过函数func(输入2个参数返回一个值)聚合数据集中的元素。
示例:有一个arrRdd需要对arrRdd元素进行聚合。
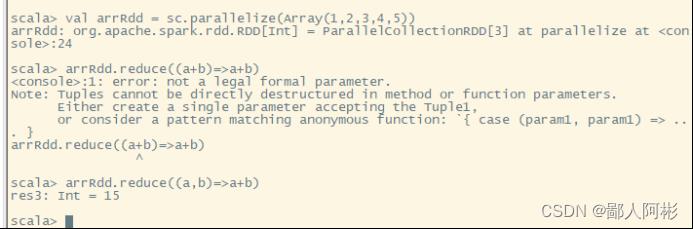
val arrRdd = sc.parallelize(Array(1,2,3,4,5))
arrRdd.reduce((a,b)=>a+b)
(5)collect()
collect()主要用于以数组的形式返回数据集中的所有元素。
示例:有一个arrRdd需要返回arrRdd的所有元素
val arrRdd = sc.parallelize(Array(1,2,3,4,5))
arrRdd.collect()

(6)foreach(func)
foreach(func)主要用于将数据集中的每个元素传递到函数func中运行。
示例:有一个arrRdd需要遍历出arrRdd元素
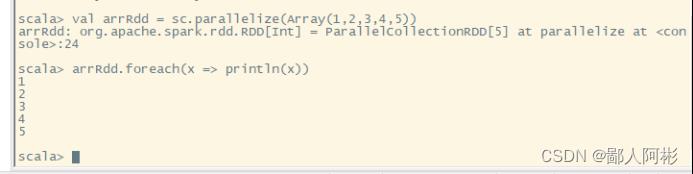
val arrRdd = sc.parallelize(Array(1,2,3,4,5))
arrRdd.foreach(x=>println(x))
好啦,关于RDD的“行动算子”和“转换算子”啊彬就讲到这里啦,谢谢大家!
以上是关于RDD的处理过程的主要内容,如果未能解决你的问题,请参考以下文章