python数据分析基础004 -numpy读取数据以及切片,索引的使用
Posted 苏凉.py
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python数据分析基础004 -numpy读取数据以及切片,索引的使用相关的知识,希望对你有一定的参考价值。
💻目录
🐚作者简介:苏凉(在python路上)
🐳博客主页:苏凉.py的博客
👑名言警句:海阔凭鱼跃,天高任鸟飞。
📰要是觉得博主文章写的不错的话,还望大家三连支持一下呀!!!
👉关注✨点赞👍收藏📂

🍕前言
终于可以给大家更新啦,今天咱们接着来学习numpy的知识——读取本地数据和索引,在python中能够读取本地数据的方法有很多,其中numpy中也有读取本地数据的方法,接下来就让我们一起来看看吧!!
往期传送门:numpy的使用详解

🍔(一)numpy读取数据
🍇1. np.loadtxt方法
np.loadtxt(frame,dtype=np.float,delimiter=None,skiprows,usecols=None,unpack=False)
frame:文件,字符串或产生器,可以是.gz或bz2压缩文件。
dtype:数据类型,可选。默认np.float。
delimiter:分隔字符串,默认是任何空格。
skiprows:跳过前n行。
usecols:读取指定的列。索引,元组类型。
unpack:如果是True,读入属性将扽别写入不同数组变量。False读入数据只写入一个数组变量。即数组的转置。 默认为False。
import numpy as np
data_file_path = './Affairs.csv'
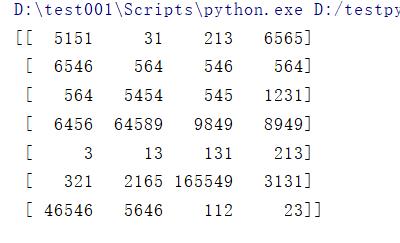
data = np.loadtxt(data_file_path,delimiter=',', dtype = 'int')
print(data)
结果:
当参数unpack=True时:
import numpy as np
data_file_path = './Affairs.csv'
data = np.loadtxt(data_file_path,delimiter=',', dtype = 'int')
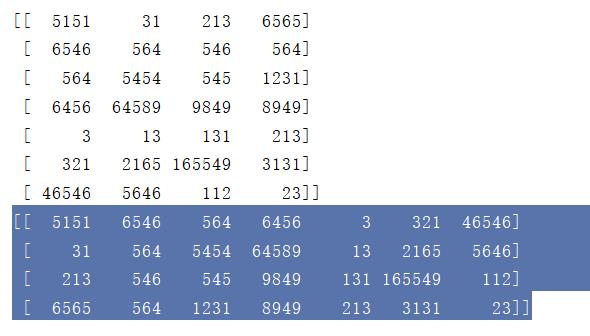
data1 = np.loadtxt(data_file_path,delimiter=',', dtype = 'int',unpack = True)
print(data)
print(data1)
结果:
🍟(二)numpy的索引和切片
对于加载出来的数据我们想要取某一行某一列又或者多行多列的值我们应该怎么做呢?下面我们一起来看一下!
🍈1. 取行
1.1 取一行
# 取某一行
print(data[2])
结果:

1.2 取连续多行
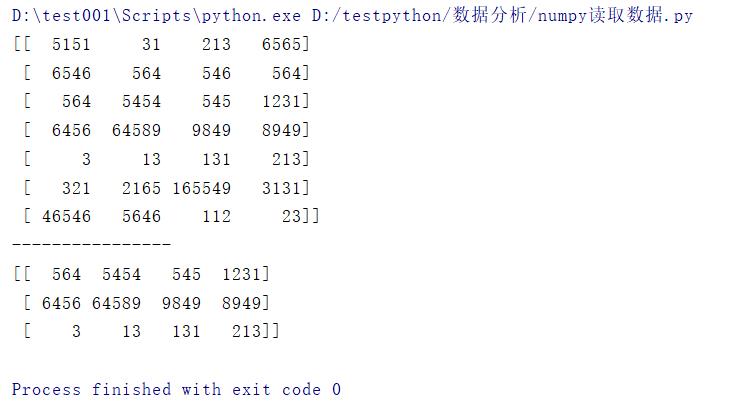
# 取连续多行
print(data[2:5])
结果:
1.3 取不连续的多行
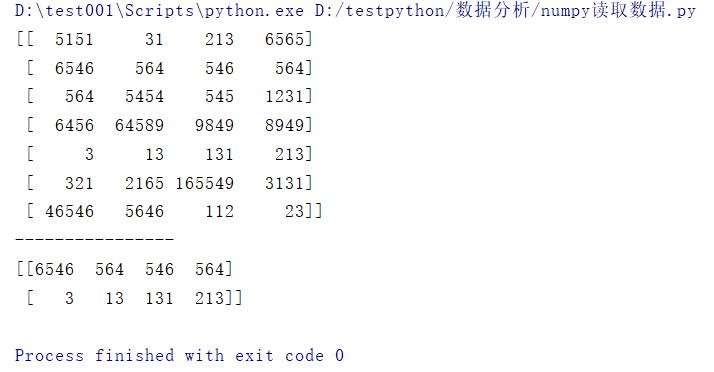
# 取不连续的多行
print(data[[1,4]])
结果:
🍉2. 取列
2.1 取一列
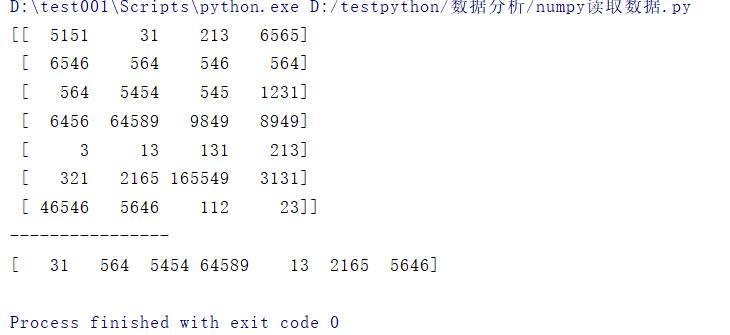
# 取某一列
print(data[:,1])
结果:
2.2 取连续多列
# 取连续多列
print(data[:,0:2])
结果:

2.3 取不连续的多列
# 取不连续的多列
print(data[:,[0,2]])
结果:

🍊3. 取某行某列
取某行某列的值时,在前面写所取全部数字的行数,后面写索取全部数字的列数
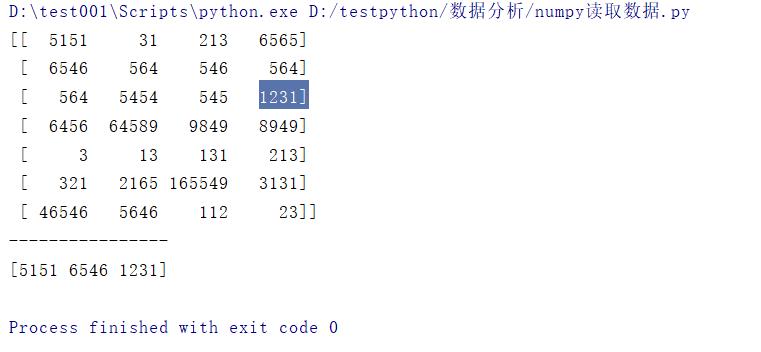
# 取某行某列(1,1),(2,1),(3,4)
print(data[[0,1,2],[0,0,3]])
结果:
🌭(三)numpy中数值的修改
🍌1. 利用切片定位修改数值
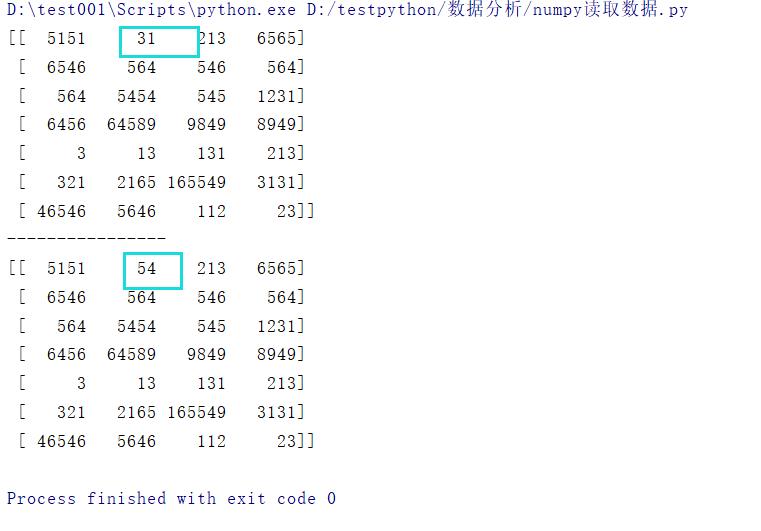
修改某个元素的值
# 修改某个元素的值
data[0,1]=54
print(data)
结果:
令小于1000的值等于0
data[data<1000]=0
print(data)
结果:
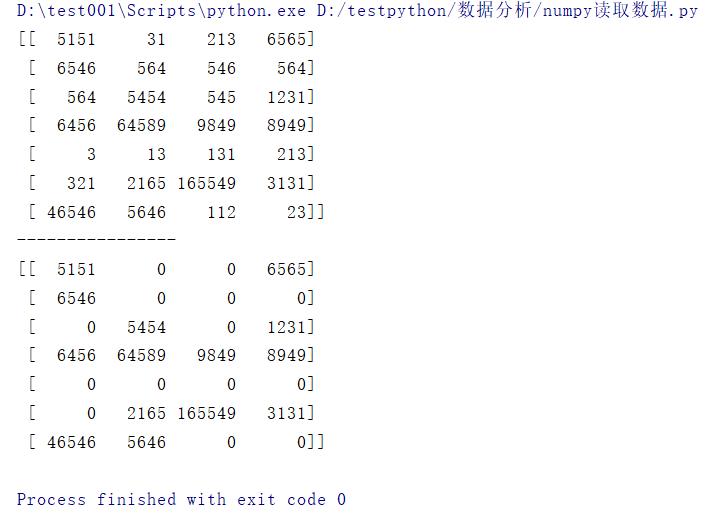
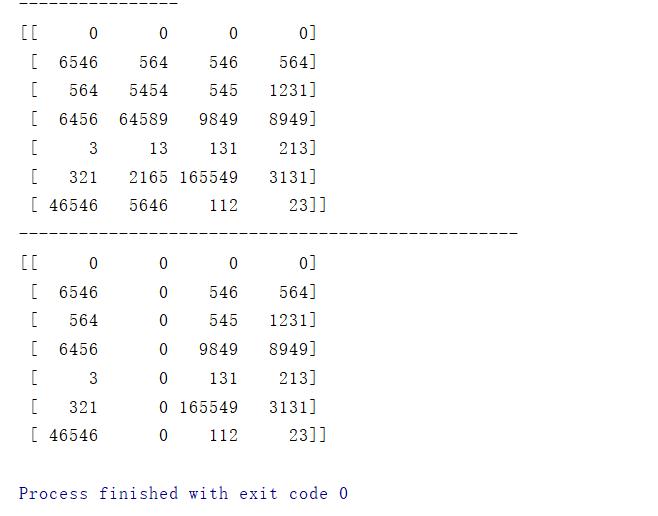
令某行或者某列为0
data[0] = 0
print(data)
print('-'*50)
data[:,1] = 0
print(data)
结果:
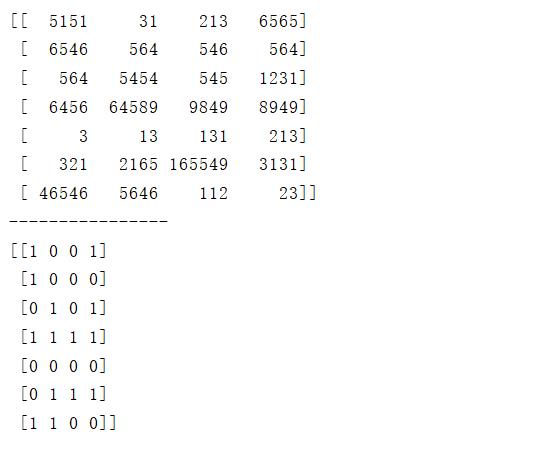
🍍2. 利用三元运算符修改数值(where)
三元运算符where(条件,成立时的结果,不成立时的结果)
例:
# 小于1000则替换为0,否则替换为1
a = np.where(data<1000,0,1)
print(a)
结果:
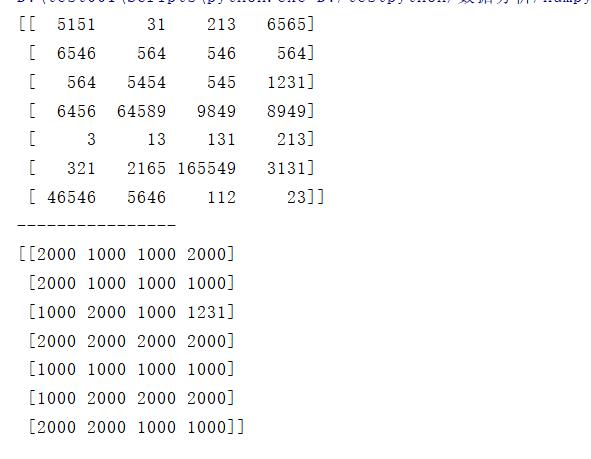
🍒3. numpy中的裁剪(clip)
clip(n.m) #小于n的值替换为n,大于m的值替换为m
例:
b = data.clip(1000,2000)
print(b)
结果:
🥞结语
今天的内容就这么多啦,又不足的地方欢迎指正,也希望看到此文的小伙伴也能有所收获!咱们下期再见啦!!

以上是关于python数据分析基础004 -numpy读取数据以及切片,索引的使用的主要内容,如果未能解决你的问题,请参考以下文章